GoogLeNet网络(2014年提出)
1.GoogLeNet网络详解
1.GoogLeNet在2014年由Google团队提出,斩获当年ImageNet竞赛中Classification Task(分类任务)第一名。
VGG在2014年由牛津大学著名研究组VGG(Visual Geometry Group,视觉几何组)提出,斩获该年ImageNet竞赛(ILSVRC)中Localization Task(定位任务)第一名和Classification Task(分类任务)第二名。(VGGNet详情见:https://blog.csdn.net/seasonsyy/article/details/132676351)
原论文:Going deeper with convolutions
2.GoogLeNet网络中的亮点
-
引入了Inception结构(融合不同尺度的特征信息),可以较为灵活地选择和配置网络
原因:一个高效的网络在输入和输出之间的关联应该是稀疏的。(在深度神经网络中的响应中,不仅存在很多响应值接近0的值,而且存在大量与其他响应高度相关的冗余值,这些响应并不能带来有价值的信息)
原理:使用密集结构来近似一个稀疏的卷积神经网络
特点:在同一层中用不同尺寸的卷积核从多个感受野上对输入图像进行卷积,同时,通过1×1卷积来大幅压缩输入图像的通道数量,以此来减少网络冗余,控制网络参数数量。
优点:
- 进一步提升模型整体性能
- 使卷积神经网络模型的搭建实现了模块化
- 如果想要改变GoogLeNet模型的深度,则只需要增添或者减少响应的Inception单元就可以了。
AlexNet和VGGNet网络中的各层之间都是串行结构(将一系列的卷积层和最大池化下采样层串联起来),这里GoogLeNet的Inception结构采用了并行结构。
如图2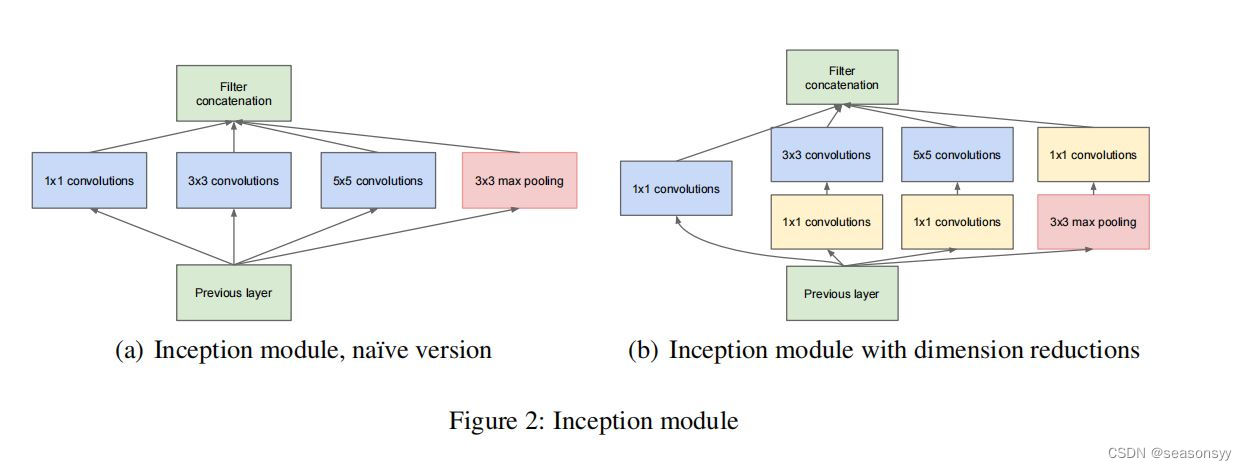
图2 注意:每个分支所得到的特征矩阵高和宽必须相同,否则无法沿深度方向进行拼接并行结构发展尝试:卷积分解、降低特征图尺寸,最终选用并行结构,即inception最终的结构。
-
1.卷积分解:将n×n的卷积核分解为n×1或1×n的卷积核,以便进一步减少网络参数数量,提高网络运算效率。 (在网络的前部使用这种分解效果不好,在中度尺寸(经验数据为12到20之间)的特征图上使用效果更好)
-
2.降低特征图尺寸:
两种方式:
先池化再inception:先池化会导致特征缺失
先Inception再池化:先Inception卷积再池化则计算量较大
为了同时保持特征表示且降低计算量,使用两个并行化的模块来降低计算量。
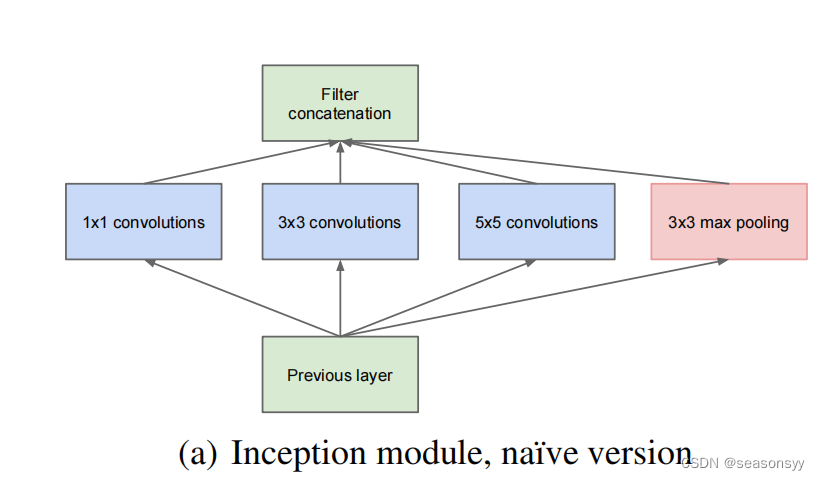
(a) Naive Inception结构:在上一层输出所得到的特征矩阵同时输入到四个分支当中进行处理,然后将这四个分支所得到的特征矩阵按照深度进行拼接,得到输出特征矩阵。
特点:这样的结构实质是通过增加网络的宽度,增强了网络对不同尺度特征的提取能力,但是这明显增加了计算量,并且输出的特征图通道数量巨大。
例子:
layer_name input kernel_size stride padding output 参数量 Previous Layer 32×32×256 1×1Conv 32×32×256 1×1×128 1 0 32×32×128 128×(1×1×256)=32768 3×3Conv 32×32×256 3×3×192 1 1 32×32×192 192×(3×3×256)=442368 5×5Conv 32×32×256 5×5×96 1 2 32×32×96 96×(5×5×256)=614400 3×3MaxPool 32×32×256 3×3 1 1 32×32×256 256×(3×3×256)=589824 总共参数量1679360 缺陷:
- 所有卷积层和前一层输入的数据对接,因此卷积层中的计算量会很大
- 在这个单元中使用的最大汇聚层保留了输入数据的特征图深度,因此,在最后进行合并时,总的输出的特征图深度只会增加,这就增加了该单元之后的网络结构的计算量。
改进:Inception结构,图2的(b)部分,如下图
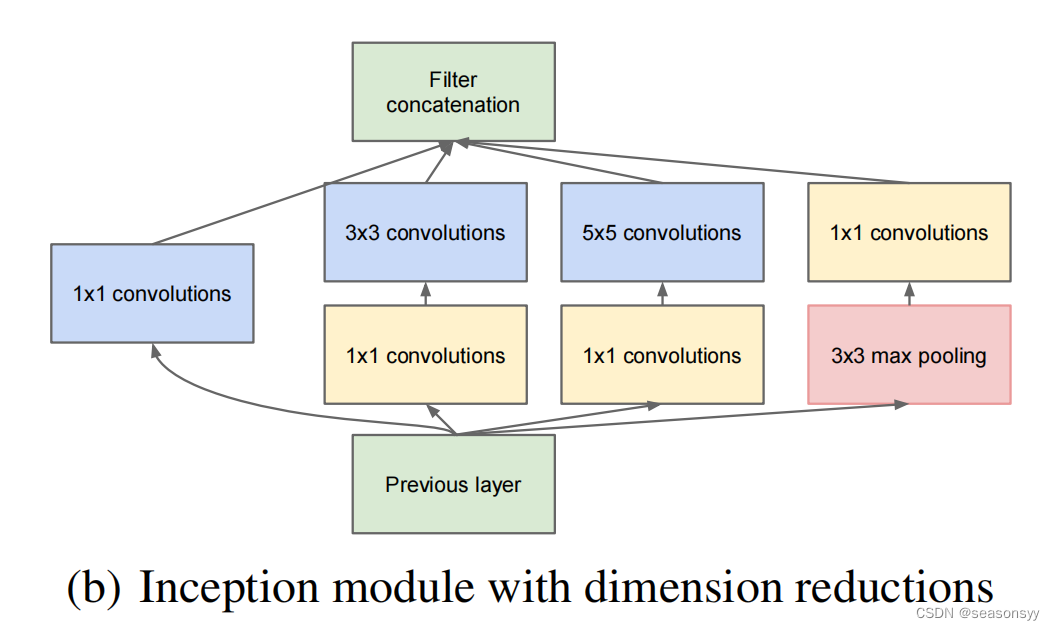
Inception结构:
(b) Inception结构加上降维的功能。比a图多了三个1×1的卷积层,起到降维的作用
这种用来压缩和扩展数据通道的1×1卷积层称为瓶颈层(BottleNeck Later)
作用:通过压缩通道数量,GoogLeNet可以将网络结构做的更深,而计算量却更少;并且与VGGNet相比,其多个尺寸的卷积核增加了网络宽度,增强了对图像特征的提取能力,取得了更好的网络性能。
例子:
input layer_name kernel_size stride padding output 参数量 Previous Layer 32×32×256 32×32×256 ①1×1Conv 1×1×128 1 0 32×32×128 128×(1×1×256)=32768 32×32×256 ②1×1Conv 1×1×64 1 0 32×32×64 64×(1×1×256)=16384 32×32×64 ②3×3Conv 3×3×192 1 1 32×32×192 192×(3×3×64)= 110592 32×32×256 ③1×1Conv 1×1×64 1 0 32×32×64 64×(1×1×256)= 16384 32×32×64 ③5×5Conv 5×5×96 1 2 32×32×96 96×(5×5×64)=153600 32×32×256 ④3×3MaxPool 3×3 1 1 32×32×256 256×(3×3×256)=589824 32×32×256 ④1×1Conv 1×1×64 1 0 32×32×64 64×(1×1×256)=16384 总共参数量935936 32×32×128、32×32×192、32×32×96与之前的Naive Inceptiond单元的输出结果是一样的,但其实这三部分因为1×1卷积层的加入,
Inceptiond总卷积参数935936<Naive Inceptiond总卷积参数1679360,
并且,因为在最大汇聚层之前也加入了1×1卷积层,所以最终输出的特征图的深度也减少了。
卷积是用来做数据特征提取的,最常使用的卷积滑动窗口的高度和宽度一般为3×3或5×5。
1×1卷积核的作用:
-
主要是用来完成特征图通道的聚合或发散的
- 特征图通道的聚合:输出特征图的深度比输入特征图的深度小
- 特征图通道的发散:输出特征图的深度比输入特征图的深度大
-
减少输出特征矩阵的深度,从而减少卷积参数,减少计算量
-
通过1×1卷积层来控制特征图最后输出的深度,从而间接影响了与其相关联的层的卷积参数数量。
我的发现:使用1×1的卷积核来进行降维过程中,1×1卷积完成的操作必须是特征图的聚合,然后再进行下面一个卷积层,才能实现减少参数量的效果。
-
证明:
如图3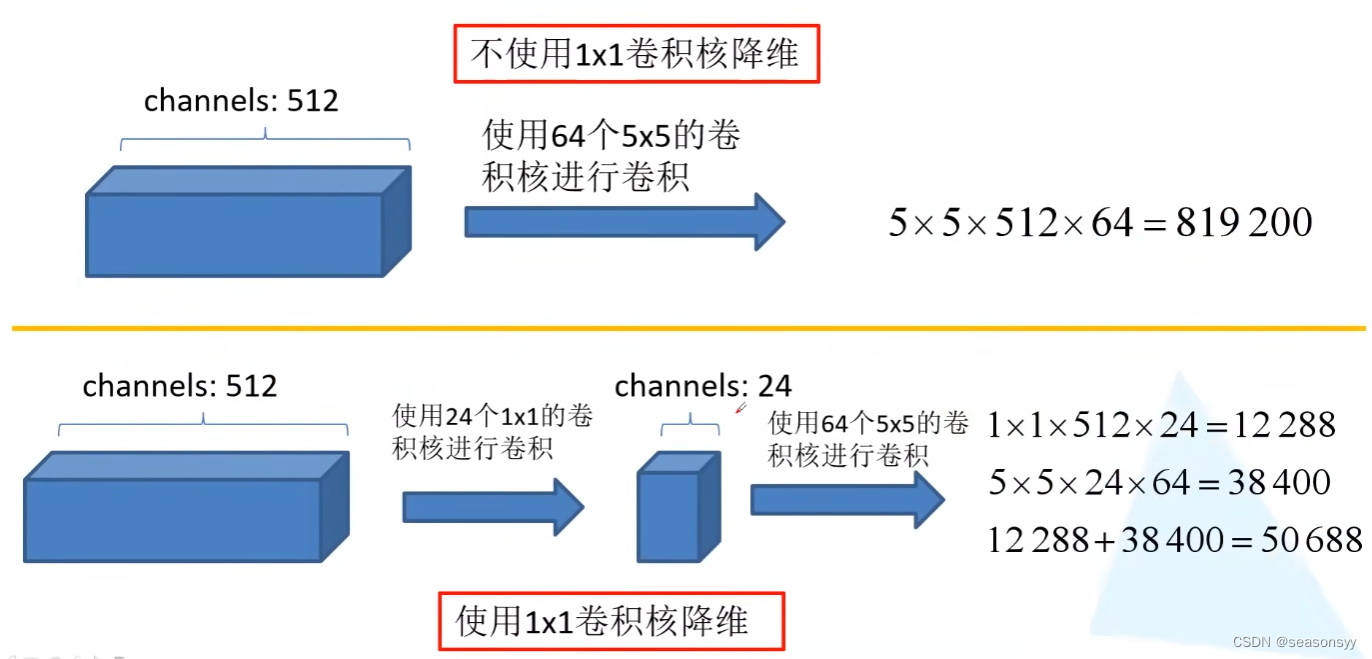
图3CNN中每个卷积层的参数量:

卷积神经网络中的参数量怎么计算?参考链接:https://zhuanlan.zhihu.com/p/366184485?utm_id=0
-
使用1×1卷积核进行降维以及映射处理
-
添加两个辅助分类器(Auxiliary Classifier)帮助训练(两个辅助分类器结构一样)
- (为了避免出现深层次模型中的梯度消失问题,使用两个额外的辅助Softmax激活函数,用于前向传导梯度)
两个辅助分类器只有训练的时候用得到,真正推理的时候会把两个辅助分类器给删除掉
辅助分类器(Auxiliary Classifier):
如图4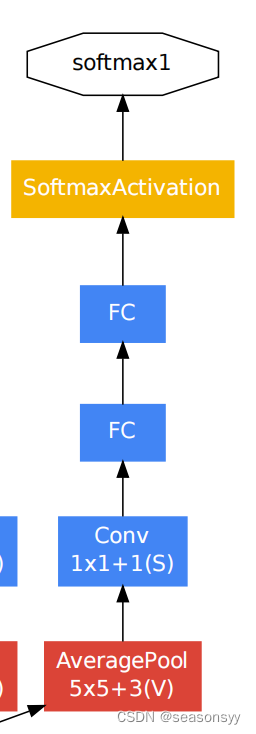
图4原论文中对辅助分类器的描述:


第一个分类器,来自Inception(4a)的输出,inception(4a)的输出特征矩阵是14×14×512
第二个分类器,来自Inception(4d)的输出,inception(4d)的输出特征矩阵是14×14×528
layer_name input kernel_size stride padding output AveragePool 14×14×512 5×5 3 0 4×4×512 Conv(ReLU) 4×4×512 1×1×128 1 0 4×4×128 flatten展平处理 4×4×128 2048 dropout层 70%随机失活节点,减少过拟合 (实验50%效果更好) FC(ReLU) 2048 1024 两个FC之间是dropout层 70%随机失活节点,减少过拟合 (实验50%效果更好) FC 1024 1000 Softmax 1000 AlexNet和VGG都只有一个输出层
GoogLeNet有三个输出层(其中两个辅助分类层)
-
丢弃全连接层,使用平均池化层(大大减少模型参数)
受NIN(Network in Network)的启发,GoogLeNet用平均池化代替全连接层,这样可以进一步减少计算量,同时实验证明这样的操作还可以提升网络任务性能;
-
GoogLeNet采用了随机失活来增强网络的泛化能力
2.GoogLeNet网络结构
GoogleNet网络结构如图0所示
GoogLeNet网络模型的深度已经达到22层

图0
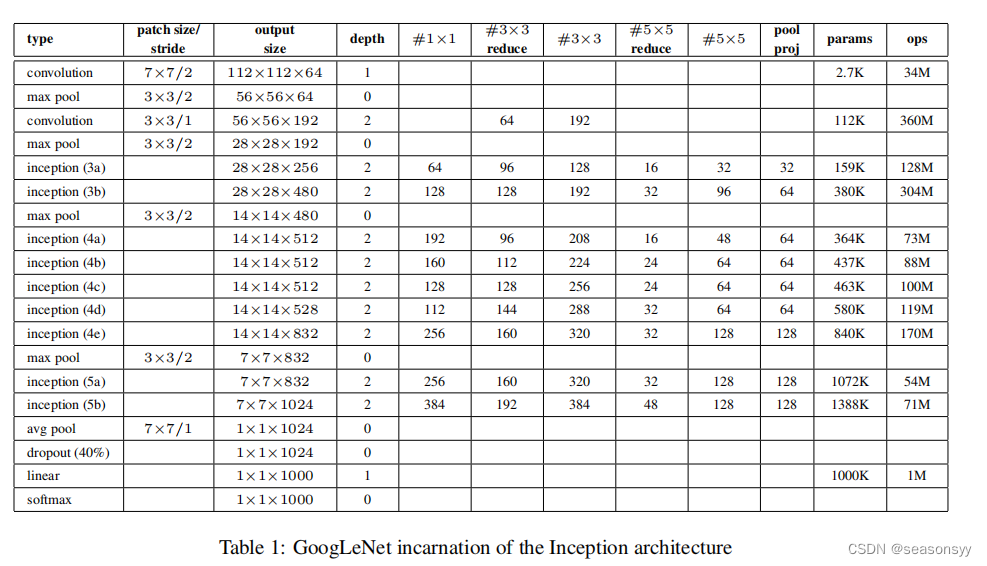
各层参数如表1所示
输入图像大小是224×224×3
表格中有一部分参数是Inception结构配置参数,如图7

图7
对应inception结构图如图8
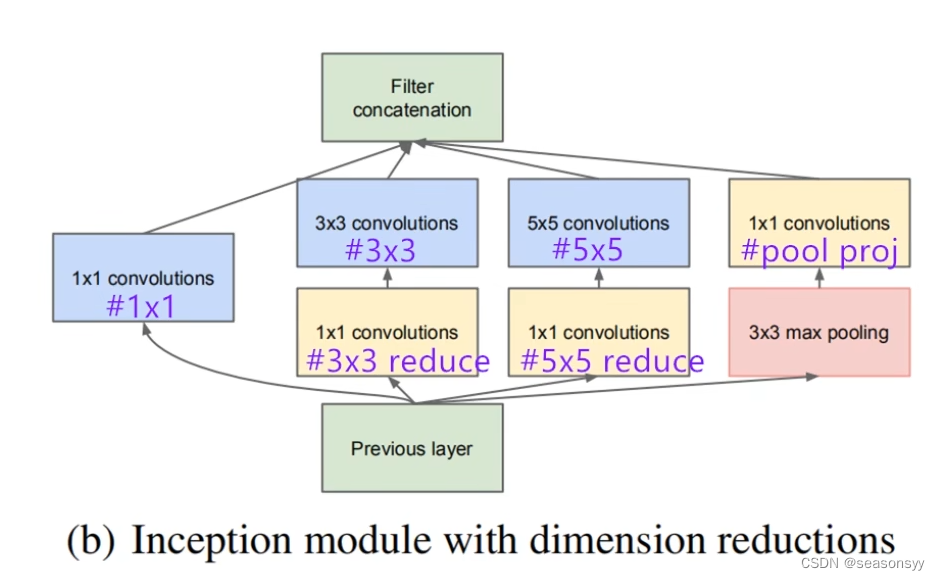
图8
LocalRespNorm层:在AlexNet中出现过,这个函数起到的作用并不大,所以后面搭建过程中可以把这个层舍弃掉
Convolution:depth=2,有两个卷积层,如图0中最下方的方框
代码运行结果
代码参考:
b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV1r7411T7M5/?spm_id_from=333.999.0.0&vd_source=647760d93691c99109dee33aad004b62
github:https://gitcode.net/mirrors/wzmiaomiao/deep-learning-for-image-processing?utm_source=csdn_github_accelerator
代码位置:\deep-learning-for-image-processing-master\pytorch_classification\Test4_googlenet
代码使用数据集:花分类数据集
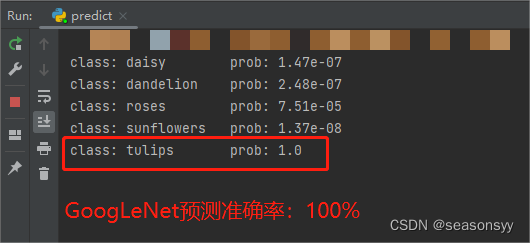
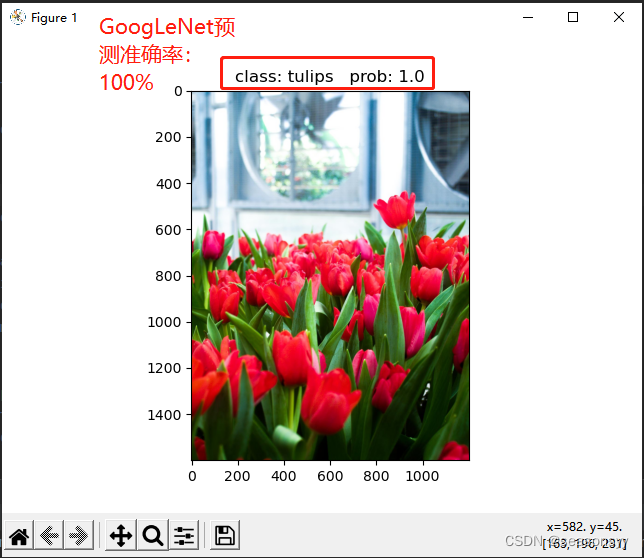
训练准确度81.3%
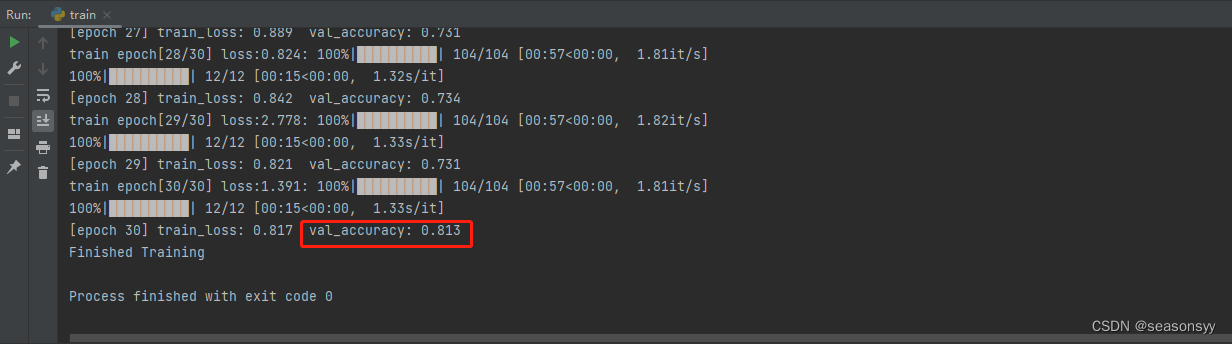
预测准确度:100%
参考文献
- 《深度学习与神经网络》 赵眸光 编著
出版社:电子工业出版社 2023年1月第一版
ISBN: 978-7-121-44429-6
- 《深度卷积神经网络 原理与实践》周浦城 李从利 王勇 韦哲 编著
出版社:北京:电子工业出版社,2020.10
ISBN: 978-7-121-39663-2
- b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV1z7411T7ie/?spm_id_from=333.999.0.0&vd_source=647760d93691c99109dee33aad004b62