点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在CVer微信公众号后台回复:FaceChain,可以下载本论文pdf和代码
本文简要介绍最新arxiv文章 “FaceChain: A Playground for Identity-Preserving Portrait Generation”。在AIGC的实际应用中,往往会遇到真人生成不好的case。更困难的是无法指定生成给定ID的人物图像,无论是SD还是mj在这方面的鲁棒性都不好,这几乎是AIGC中公认的难题之一。为了克服保ID人物AIGC的技术难题,FaceChain文章提出了相应数字孪生的技术框架,该框架可以兼容SD1.5的风格lora生态,能让相应的风格plugin进来生成指定ID的个人写真图片。该应用已在github开源,目前1个月内star数近5K,FaceChain的热度已触达国内外的用户与AIGC的创业者群体。
一、资料

在CVer微信公众号后台回复:FaceChain,可以下载本论文pdf和代码
FaceChain:A Playground for Identity-Preserving Portrait Generation
论文:https://arxiv.org/abs/2308.14256
代码(已开源):
https://github.com/modelscope/facechain
二、背景
近期图像生成技术取得了突飞猛进的发展。这得益于StableDiffusion技术,它使用深度学习算法来生成具有高质量、稳定性的图像和视频。与传统的图像生成技术不同,Stable Diffusion能够在生成图像和视频时保持图像和视频的稳定性,避免出现闪烁和抖动等现象。这种技术通常用于设计、虚拟现实、视频游戏等领域。虽然Stable Diffusion是一种部分条件可控的技术。它的生成过程可以由用户根据特定的prompt进行控制,这种可控性使得Stable Diffusion能够更加灵活地应用于不同的场景。但在指定ID人像生成方面,它往往不尽如人意,无法生成用户指定ID的人像图生成,这很大程度上限制了相应的学术跟应用的发展。
三、方法
框架图如下图所示:
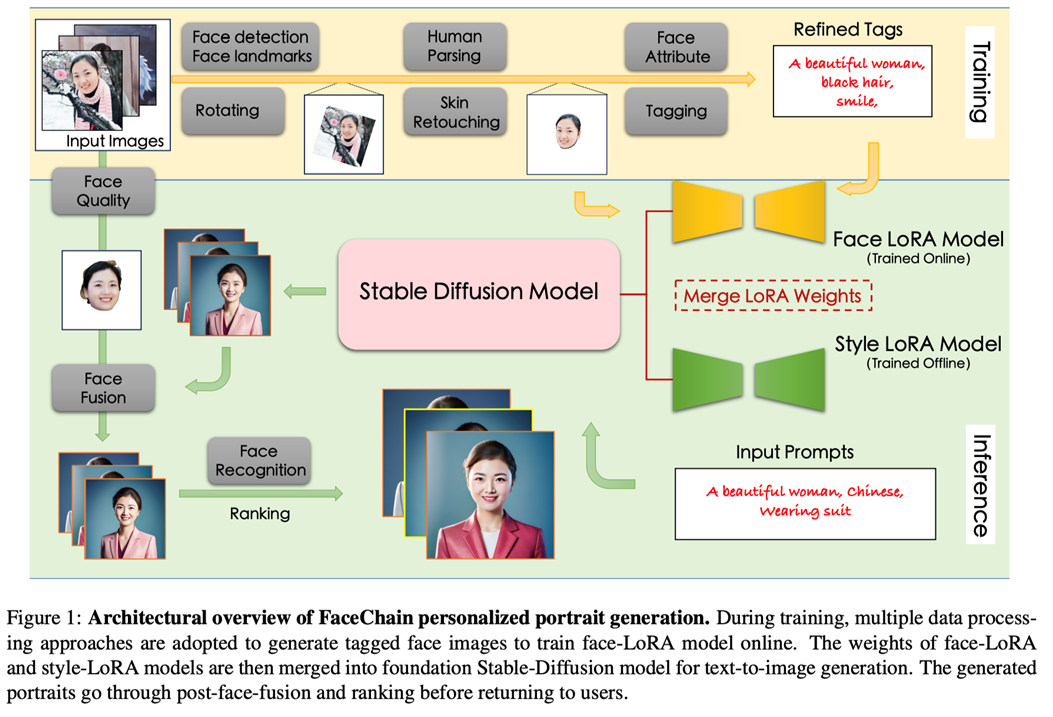
从该框架图中,我们可以看到目前该框架的巨大优势在于其可以使用SD1.5生态中的各种现有的stylelora model来做风格的尝试。该FaceChain保人物ID的AIGC技术框架可用于非常多的有趣应用的探索,比如虚拟试衣、人物插画故事、talking head、人物视频、人物表情包等等。目前该开源项目正在高速发展的阶段,短短一个月已经有213次的commit,近期也更新了非常多的feature,比如:1.)支持pose control、2.)风格lora即插即用、3.)自定义prompt换衣、4.)支持指定模版inpainting(beta版本,暂时效果不佳)等。接下来还会继续支持:1.)SDXL、2.)高清分辨率、3.)多人场景、4.)应用界面简化、美化、5.)兼容windows等。
四、结果
以下是部分结果展示:


更多结果的长期跟踪,见如下链接:
https://www.xiaohongshu.com/user/profile/5c0f2d43000000000701e3dc?xhsshare=CopyLink&appuid=5c0f2d43000000000701e3dc&apptime=1693992641
在CVer微信公众号后台回复:FaceChain,可以下载本论文pdf和代码
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看