一、准备数据
二、标注
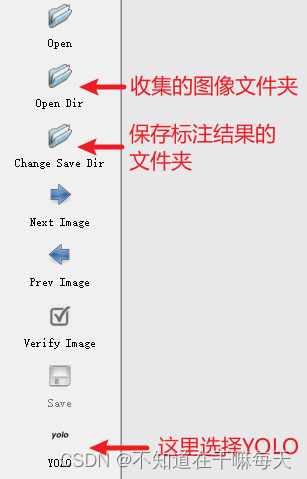
这里使用labelimg进行数据标注(labelimg的使用这里不做说明)
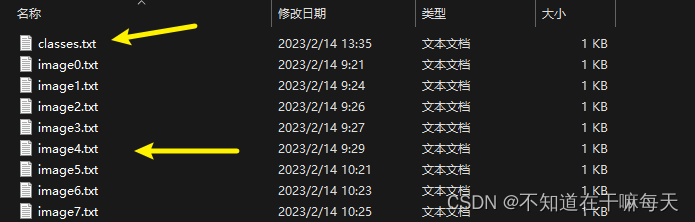
标注完成之后得到标注的结果,一个classes.txt和多个图像的标注信息txt
三、划分数据集
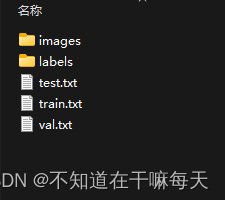
先随便新建一些文件夹和文件,如下
先把classes.txt单独拿出来,再用Python脚本快速划分数据集
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
# 原始路径
image_original_path = "图像文件夹路径"
label_original_path = "标注结果的路径" // 该路径下不要有classes.txt
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "images/train/")
train_label_path = os.path.join(cur_path, "labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "images/val/")
val_label_path = os.path.join(cur_path, "labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "images/test/")
test_label_path = os.path.join(cur_path, "labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "train.txt")
list_val = os.path.join(cur_path, "val.txt")
list_test = os.path.join(cur_path, "test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpg'
srcLabel = label_original_path + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()
划分完成之后的数据集应该是这样
- images文件夹下
有三个文件夹,每个文件夹中都有对应的图像
- labels文件夹下
有三个文件夹,每个文件夹中都有对应的标注数据
- train.txt文件
保存了训练图像的路径
数据集制作完成。