Seg4Reg Networks for Automated Spinal Curvature Estimation
用于自动脊柱曲率估计的 Seg4Reg 网络
【论文阅读】
Abstract
提出pipeline来进行准确脊柱侧弯评估
framework:
Seg4Reg,首先经过分割网络得到mask,然后回归网络直接基于此进行cobb角预测。
+a domain adaptation module来缓解domain shift问题
输出:集成ensemble不同模型的预测结果
Intro
评估bobb两方法:
①预测landmark然后计算角:高精度但是过于依赖landmark,小误差导致大错误
②直接回归cobb:方法稳定但预测精确不够(本文证明该方法更优)
本文:MICCAI AASCE 2019 challenge

Method
seg:与PSPNet相似、reg:传统分类模型
预处理:
- train/test区域不同⇒直方图均衡化使它们视觉相似(因为test不多就手工crop,并数据增强)
- 再seg之前额外加一个”gap~bones”可提高分割模型性能(正则化训练过程)


使用ImageNet预训练的分类网络(?用在谁上面)可以提升有限的训练样本;
train/test之间domain gap用[3]加一个判别器分支,并在反传时反转梯度(loss如下,本文 λ=1)

网络训练参数及配置:
 实验结果
实验结果
- Local Validation
L1 loss:
表1:input类型和尺寸的消融实验
⇒segmentation mask is the best input type and (512, 256) is the best input size
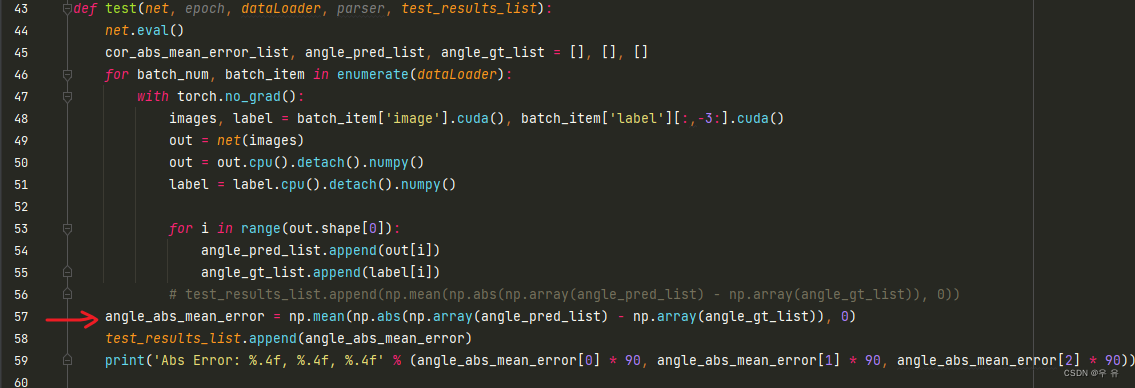
表2:不同分割网络性能
⇒adding a dilation pyramid thus improves the performance of previous PSPNet
目的:选择最合适的(也是进一步说明我们选择图片尺寸、网络的合理性)
- Online test
相关知识
domain shift
dilated convolution作用
Adam optimizer
词汇积累
alleviate减轻、缓解mitigate
【实验复现】
1、mat2csvQA
import os.path
import pandas as pd
import scipy
from scipy import io
# 'data/labels/train/sunhl-1th-02-Jan-2017-162 A AP.jpg.mat'
def mat2csv(mat_file_path):
features_struct = scipy.io.loadmat(mat_file_path)
# print(features_struct)
features = features_struct['p2']
dfdata = pd.DataFrame(features)
datapath1 = mat_file_path[:-4]+'.csv'
dfdata.to_csv(datapath1, index=False, header=False)
if __name__ == '__main__':
# data_root = 'data/labels/val'
# mat_files =[os.path.join(data_root,filename) for filename in os.listdir(data_root) if filename.endswith('.mat')]
# print(mat_files)
# for item in mat_files:
# mat2csv(item)
labels = pd.read_csv('data/labels/train/sunhl-1th-02-Jan-2017-162 A AP.jpg.csv', header=None).values
print(labels)
(1)refer:python读取mat转换为csv
(2)输出的csv文件里第一行是0,1导致69行>68点
Pandas DataFrame DataFrame.to_csv() 函数里面header=False注释,行index=False
(3)发现拷贝的数据没有landmark.csv和angle.csv,拿到的数据不对=>这一步骤不需要了
和之前yolo一样,os.py系统文件不修改
2、文件 visual_dir给一个输出文件位置,data_dir也是


3、ModuleNotFoundError: No module named 'libs.black_list'里面没写啥,直接注释,新报错
A:“只能用大招了”![]() 这个文件夹标记成【源根】 Done
这个文件夹标记成【源根】 Done


4、IndexError: index 131 is out of bounds for axis 0 with size 128 索引超出长度

最后找到原因是其中有个点的值>1,导致出现131;改成了0.99999试一下
5、TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first. 原因
用排除法只能是这个loss.list出问题,加了float报错 
参考train.py里面本来就有的部分,应该↓:tensor转numpy-√、detach()、
a.detach().numpy()
a.cpu().detach().numpy() 
6、IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed

![]()
解决:debug之后发现这一步test_results_list里面是空的(点进去test函数,这个参数无效)
![]()