写该篇的来由是因为翻阅到了TriCache: A User-Transparent Block Cache Enabling High-Performance Out-of-Core Processing with In-Memory Programs文章,其中对SPDK的运用的炉火纯青,将I/O性能提升到了一个新的档次
SPDK基础知识
SPDK Storage Performance Development Kit,存储性能开发工具包,提供了一组工具和库,用于编写高性能,可伸缩的用户模式存储应用程序
相关资料:
| 链接 |
|---|
| Introduction to the Storage Performance Development Kit (SPDK) |
| spdk 官网 文档 |
| spdk 源码 GitHub spdk/spdk |
| spdk 技术文章 |
还有一个技术名为
DPDK,架构和SPDK类似,想学习该书的推荐看《深入浅出DPDK》
优点:
- 将所有必需的驱动程序移动到用户空间,这样可以避免系统调用并启用应用程序的零拷贝访问
- 轮询硬件在于是否完成而非依赖中断抢占,这降低了总延迟和延迟差异
- 避免I / O路径中的所有锁定,而是依赖于消息传递(使用了无锁消息队列)
编译和安装
git clone https://github.com/spdk/spdk
cd spdk
git submodule update --init # 拉取子模块
sudo scripts/pkgdep.sh # 安装依赖性
./configure
make
运行单元测试,以下表示测试成功
(base) root@nizai8a-desktop:~/tt/spdk# ./test/unit/unittest.sh
=====================
All unit tests passed
=====================
WARN: lcov not installed or SPDK built without coverage!
WARN: neither valgrind nor ASAN is enabled!
分配大页面并且从本机内核驱动程序中取消绑定任何NVMe设备
此处是常见的错误,表示
/dev/nvme1n1是使用中,因此,如果想取绑设备,必须要将其umount并格式化
用户驱动程序利用uio/vfio中的功能将设备的PCI BAR映射到当前进程,从而允许驱动程序直接执行MMIO(默认采用uio)
(base) root@nizai8a-desktop:~/tt/spdk# sudo scripts/setup.sh
0000:81:00.0 (144d a808): Active mountpoints on nvme1n1:nvme1n1, so not binding PCI dev
0000:01:00.0 (15b7 5009): nvme -> uio_pci_generi
为什么要分配大页?
原理:dpdk大页内存原理
- 所有大页以及大页表都以共享内存存放在共享内存中,永远都不会因为内存不足而导致被交换到磁盘swap分区中
- 由于所有进程都共享一个大页表,减少了页表的开销,无形中减少了内存空间的占用, 使得系统支持更多的进程同时运行
- 减轻TLB的压力
- 减轻查内存的压力
默认情况下,脚本分配2048MB的大页面。要更改此数字,请指定HUGEMEM
sudo HUGEMEM = 4096 scripts/setup.sh
查看系统支持的大页类型
(base) root@nizai8a-desktop:/sys/kernel/mm/hugepages# ls
hugepages-1048576kB hugepages-2048kB
SPDK架构
本节主要是针对SPDK的三个优点展开的
用户态驱动程序
在VVMe的出现后,软件成为了I/O密集型的场景下的瓶颈,有两种方法对内核进行优化
io_ring:提供一套新的系统调用,基于系统调用路径的优化- 绕过内核
kernel bypass,整个I/O操作不需要陷入到内核中,SPDK即该存储加速方案
Intel对其定义是利用用户态、异步、轮询方式的NVMe驱动,用于加速NVMe SSD作为后端存储使用的应用软件的加速库
NVMe协议是一种为了SSD固态硬盘和主机通信的速度更快而定义的规范,将其本地存储性能推广到网络有NVMe-oF协议,用来支持InfiniBand、光纤或者以太网等。在针对网络存储解决方案中,当前主要有DAS、NAS以及SAN
SPDK基于UIO或VFIO的支持直接将存储设备的的地址空间映射到应用空间的方式,并利用NVMe规范来初始化NVMe SSD设备,实现基本的I/O操作,从而构筑用户态驱动,所以整个过程不需要陷入到内核中
在SPDK用户态驱动的方案中,这一行为被异步轮询所取代,通过CPU不断轮询的方式,一旦查询到操作完成,则立马触发回调函数,给到上层用户程序,这样用户程序可以按需发送多个请求,以此提升性能
移除系统中断另一个显而易见的好处是避免了上下文的切换
除此之外,SPDK利用CPU的亲和性,将线程和CPU核做绑定,设计了线程模型,应用程序从收到这个核的I/O操作到运行结束,都在该核上完成,这样可以更高效的利用缓存,同时也避免多核之间的内存同步问题
与此同时,在单核上的内存资源的管理,利用了大页存储来加速
线程
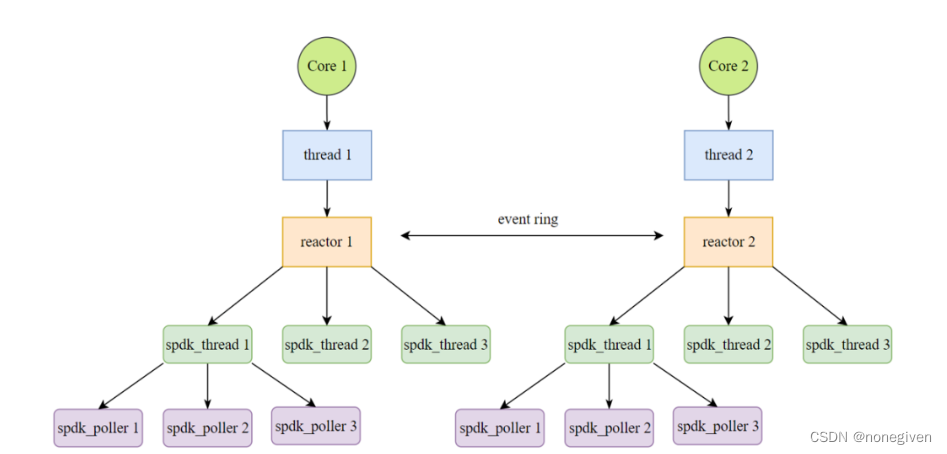
在SPDK中的线程模型架构上,每一个CPU核中拥有一个内核线程,会初始化一个reactor
每一个reactor下可持有零到多个SPDK抽象出的轻量用户态线程spdk_thread,为了提高在reactor间通信与同步的效率,SPDK放弃了传统加锁的方式,而是通过向每个reactor的spdk_ring来发送消息,在抽象得到的spdk_thread下拥有poller,用来注册用户函数
SPDK使用
rpc后台启动
SPDK从v20.x的版本开始已经切换为json配置文件的格式,行可执行程序时可以通过 --json 参数来传递json配置文件。当启动SPDK的应用程序时指定了json文件,那在SPDK的初始化流程中就会以rpc的模式来执行其中subsystems的初始化并执行json文件中指定的操作
rpc是一种为大家所熟知在程序启动后动态灵活地执行操作的方法。其主要使用了unix socket来在客户端和服务端之间传递消息数据
SPDK也集成或者实现了rpc的交互通道,可以支持动态的操作
服务端
SPDK中的rpc服务端在函数 spdk_rpc_initialize中完成初始化。如果没有指定用于监听的地址,那就会使用默认的监听地址/var/tmp/spdk.sock。rpc客户端访问时使用的默认监听地址就是这个。每个需要提供rpc调用的模块或者功能都可以通过SPDK_RPC_REGISTER 来注册其提供服务的函数到g_rpc_methods链表中。函数 jsonrpc_handler是处理所有从客户端过来的请求的入口,其中就会从g_rpc_methods链表中来根据请求匹配具体的处理函数
客户端
SPDK的rpc客户端提供的功能大部分是以 ./spdk/scripts/rpc.py脚本为入口来进行调用的。该脚本会包含./spdk/python/spdk/rpc目录下的python脚本,各个rpc功能的客户端处理,以及公共的用于和服务端进行交互的函数就定义在这些被包含的脚本中。每个模块提供的rpc功能中客户端的相应处理逻辑都归集在以模块名字作为名字的python文件中
如果想查询有哪些已经支持的rpc调用功能,则可以直接执行
./rpc.py -h查询
如果想要添加新的
rpc的功能,那就需要通过SPDK_RPC_REGISTER注册新的功能,并在rpc客户端添加相应的python脚本逻辑
基础机制分析
SPDK中的分核并行、免锁及Run to completion 的编程特性,主要是由reactor、events、poller和io channel的机制构成
Reactors
当DPDK中rte_eal_init函数被执行时,其会在除当前运行的CPU main cpu核外的各个指定可用的CPU核上创建线程
并通过修改线程的亲和参数将其绑定在对应的CPU核上运行。每个线程的执行函数是eal_thread_loop,一直在等待从pipe中接收数据并执行
/* Launch threads, called at application init(). */
int
rte_eal_init(int argc, char **argv)
{
// ...
RTE_LCORE_FOREACH_WORKER(i) {
/*
* create communication pipes between main thread
* and children
*/
if (pipe(lcore_config[i].pipe_main2worker) < 0)
rte_panic("Cannot create pipe\n");
if (pipe(lcore_config[i].pipe_worker2main) < 0)
rte_panic("Cannot create pipe\n");
lcore_config[i].state = WAIT;
/* create a thread for each lcore */
// 创建线程,执行函数为eal_thread_loop
ret = pthread_create(&lcore_config[i].thread_id, NULL,
eal_thread_loop, NULL);
if (ret != 0)
rte_panic("Cannot create thread\n");
/* Set thread_name for aid in debugging. */
snprintf(thread_name, sizeof(thread_name),
"lcore-worker-%d", i);
rte_thread_setname(lcore_config[i].thread_id, thread_name);
// 增加线程亲和性
ret = pthread_setaffinity_np(lcore_config[i].thread_id,
sizeof(rte_cpuset_t), &lcore_config[i].cpuset);
if (ret != 0)
rte_panic("Cannot set affinity\n");
}
// ...
}
DPDK中提供了 rte_mempool 和 rte_ring 的机制来支持针对内存方面的需求
每个rte_mempool实例都是一个些由大页内存组成的内存池,并且以特定的数据结构进行组织,其中支持的每个分配和使用的单元可以用于存储调用者的数据
当创建rte_mempool时会同时在各个可用的CPU创建cache buffers,以便当调用rte_mem_get时直接从cache buffer中获取,加速分配的过程(有点像per-cpu cache)
/**
* The RTE mempool structure.
*/
struct rte_mempool {
/*
* Note: this field kept the RTE_MEMZONE_NAMESIZE size due to ABI
* compatibility requirements, it could be changed to
* RTE_MEMPOOL_NAMESIZE next time the ABI changes
*/
char name[RTE_MEMZONE_NAMESIZE]; /**< Name of mempool. */
RTE_STD_C11
union {
void *pool_data; /**< Ring or pool to store objects. */
uint64_t pool_id; /**< External mempool identifier. */
};
void *pool_config; /**< optional args for ops alloc. */
const struct rte_memzone *mz; /**< Memzone where pool is alloc'd. */
unsigned int flags; /**< Flags of the mempool. */
int socket_id; /**< Socket id passed at create. */
uint32_t size; /**< Max size of the mempool. */
uint32_t cache_size;
/**< Size of per-lcore default local cache. */
uint32_t elt_size; /**< Size of an element. */
uint32_t header_size; /**< Size of header (before elt). */
uint32_t trailer_size; /**< Size of trailer (after elt). */
unsigned private_data_size; /**< Size of private data. */
/**
* Index into rte_mempool_ops_table array of mempool ops
* structs, which contain callback function pointers.
* We're using an index here rather than pointers to the callbacks
* to facilitate any secondary processes that may want to use
* this mempool.
*/
int32_t ops_index;
struct rte_mempool_cache *local_cache; /**< Per-lcore local cache */
uint32_t populated_size; /**< Number of populated objects. */
struct rte_mempool_objhdr_list elt_list; /**< List of objects in pool */
uint32_t nb_mem_chunks; /**< Number of memory chunks */
// 内存池
struct rte_mempool_memhdr_list mem_list; /**< List of memory chunks */
} __rte_cache_aligned;
rte_ring则是用于传递消息的队列,每个在rte_ring中传递的单元是一个内存指针,可以参见 spdk_thread_send_msg函数中的使用
rte_ring使用了无锁的队列模型,支持多生产者多消费者的模式,当前SPDK中使用的是多生产者单消费者的模式
SPDK启动后,在每个指定可用的CPU核上均会运行一个reactor,且在除主核外的CPU核上,SPDK的reactor 和 eal_thread_loop有一一对应的关系
reactor->events是基于rte_ring来实现的,可以用于在reactors之间传递消息,通过调用spdk_event_allocate和spdk_event_call可以向任一spdk使用的CPU核来发送需消息,以便运行私有的逻辑操作
该操作的使用场景
- 需要在当前
CPU核上延迟地做某个动作,但还有没有对应的spdk_thread可使用- 需要在其他
SPDK使用地CPU核上做某个动作,但还没有关联的spdk_thread可用
DEFINE_STUB(spdk_event_allocate, struct spdk_event *, (uint32_t core, spdk_event_fn fn, void *arg1,
void *arg2), NULL);
/* DEFINE_STUB is for defining the implmentation of stubs for SPDK funcs. */
#define DEFINE_STUB(fn, ret, dargs, val) \
bool ut_ ## fn ## _mocked = true; \
ret ut_ ## fn = val; \
ret fn dargs; \
ret fn dargs \
{
\
return MOCK_GET(fn); \
}
DEFINE_STUB_V(spdk_event_call, (struct spdk_event *event));
/* DEFINE_STUB_V macro is for stubs that don't have a return value */
#define DEFINE_STUB_V(fn, dargs) \
void fn dargs; \
void fn dargs \
{
\
}
SPDK默认的调度策略是static类型,即reactor和thread都运行在polling模式
SPDK的线程模型
spdk_thread 不是常规意义下的线程,实际是个逻辑上的概念,它没有具体的执行函数,其所有相关的操作均在reactor的执行函数中来执行
spdk_thread和reactor的关系是N:1的对应关系,即每个reactor上可以有很多的spdk_thread,但每个spdk_thread需要属于且只能属于一个具体的reactor
Poll
每个注册的spdk_poller存放于spdk_thread->timed_pollers的红黑树结构或者spdk_thread->active_pollers链表中。所以如果想要使用poller,那首先需要创建一个spdk_thread
有了spdk_thread后就可以通过注册spdk_poller来重复或者周期性的运行某个函数。如果注册poller时的周期指定为0,那么poller对应的执行函数就会在每个reactor的循环中均进行调用;如果周期不为0,那各次reactor的循环中就会检查是否满足执行的周期时才执行
struct spdk_poller {
TAILQ_ENTRY(spdk_poller) tailq;
/* Current state of the poller; should only be accessed from the poller's thread. */
enum spdk_poller_state state;
uint64_t period_ticks;
uint64_t next_run_tick;
uint64_t run_count;
uint64_t busy_count;
spdk_poller_fn fn;
void *arg;
struct spdk_thread *thread;
int interruptfd;
spdk_poller_set_interrupt_mode_cb set_intr_cb_fn;
void *set_intr_cb_arg;
char name[SPDK_MAX_POLLER_NAME_LEN + 1];
};
当创建了spdk_thread后,就可以使用spdk_thread_send_msg函数来执行具体的函数,通过选择合适的spdk_thread可以实现在当前CPU核或其他SPDK使用的CPU核上去执行操作
这个函数中传递的msg就是从g_spdk_msg_mempool (一个rte_mempool实例) 中分配的,传递时就使用了rte_ring的无锁队列
总的来说就是Reactor之间通过event(rte_ring)通信,不同cpu核的spdk_thread或者同一cpu核的spdk_thread通过Message(rte_ring)来协调无锁队列的
io_channel
IO channel 是一个用于在每个可用的CPU核上分别单独执行相同操作的抽象机制,不做概述
后端vhost
设备查找
扫描设备并将设备和控制器绑定以及数据的读写操作
probe_cb:找到NVMe controller之后进行回调attach_cb:一旦NVMe控制器已连接到用户空间驱动程序后调用
查找设备和绑定驱动的过程均在spdk_nvme_probe函数中实现
在代码中,我们通过指定transport id来对PCI总线上的设备进行扫描,通过两个全局链表来保存驱动和设备,遍历驱动,将找到的设备和驱动进行匹配
int
spdk_nvme_probe(const struct spdk_nvme_transport_id *trid, void *cb_ctx,
spdk_nvme_probe_cb probe_cb, spdk_nvme_attach_cb attach_cb,
spdk_nvme_remove_cb remove_cb)
{
struct spdk_nvme_transport_id trid_pcie;
struct spdk_nvme_probe_ctx *probe_ctx;
if (trid == NULL) {
memset(&trid_pcie, 0, sizeof(trid_pcie));
spdk_nvme_trid_populate_transport(&trid_pcie, SPDK_NVME_TRANSPORT_PCIE);
trid = &trid_pcie;
}
probe_ctx = spdk_nvme_probe_async(trid, cb_ctx, probe_cb,
attach_cb, remove_cb);
if (!probe_ctx) {
SPDK_ERRLOG("Create probe context failed\n");
return -1;
}
/*
* Keep going even if one or more nvme_attach() calls failed,
* but maintain the value of rc to signal errors when we return.
*/
return nvme_init_controllers(probe_ctx);
}
重点看一下读写过程
HOST 就是NVMe卡所插入的系统,·HOST·和·Controller·之间的交互通过·Qpair·进行
pair分为IO Qpair和Admin Qpair,顾名思义,Admin Qpair用于控制命令的传输,而IO Qpair用于IO命令的传输
Qpair对由提交队列(Submission Queue, SQ)和完成队列(Completion Queue, CQ)组成的固定元素数量的环形队列,提交队列是由固定元素数量的64字节的命令组成的数组,加上2个整数(头和尾索引)。完成队列由固定元素数量的16字节命令加上2个整数(头和尾索引)所组成的环形队列。另外还有两个32位寄存器(Doorbell),Head Doorbell和Tail Doorbell
HOST需要向NVMe写入数据时,需要指明数据在内存中的地址,以及写入到NVMe中的位置,HOST从NVMe读数据也是一样的,需要指明NVMe地址和内存地址,这样HOST和NVMe才知道去哪里取数据,取完后数据放到哪里,两种数据地址表示的方式,一种是PRP,还有一种是SGL
PRP指向一个物理内存页。PRP和正常的寻址方式相似,基地址加上偏移地址。PRP指向一个物理地址页
SPDK将I/O提交到本地PCIe设备过程
通过构造一个64字节的命令,将I/O提交到NVMe设备,将其放入提交队列尾部索引当前位置的提交队列中,然后将提交队列尾部的新索引写入提交队列Tail Doorbell。也可以写多条命令到SQ,然后只写一次Doorbell就可以提交所有命令。
命令本身描述了操作,还描述了主机内存中包含与命令关联的主机内存数据的位置,也就是我们要写入数据的位置,或将读取的数据放置到内存中的位置。通过DMA的方式将数据传输到该地址或从该地址传输数据
完成队列的工作方式类似,设备将命令的响应消息写入到CQ中。CQ中的每个元素包含一个相位Phase Tag,在整个环的每个循环上在0和1之间切换。设备通过中断通知HOST CQ的更新,但是SPDK不启用中断,而是轮询相位位以检测CQ的更新
有点像
io_uring的机制了
异步I/O
此处大量使用了异步I/O,在Linux中一般默认使用的是AIO和io_uring
其中,io_uring弥补了aio的一些不足之处
io_uring有时也称为aio_ring,io_ring,ring_io
一个小example
/**
* 读取文件
**/
#include <bits/stdc++.h>
#include <liburing.h>
#include <unistd.h>
char buf[1024] = {
0};
int main() {
int fd = open("1.txt", O_RDONLY, 0);
io_uring ring;
io_uring_queue_init(32, &ring, 0); // 初始化
auto sqe = io_uring_get_sqe(&ring); // 从环中得到一块空位
io_uring_prep_read(sqe, fd, buf, sizeof(buf), 0); // 为这块空位准备好操作
io_uring_submit(&ring); // 提交任务
io_uring_cqe* res; // 完成队列指针
io_uring_wait_cqe(&ring, &res); // 阻塞等待一项完成的任务
assert(res);
std::cout << "read bytes: " << res->res << " \n";
std::cout << buf << std::endl;
io_uring_cqe_seen(&ring, res); // 将任务移出完成队列
io_uring_queue_exit(&ring); // 退出
return 0;
}
Io_uring 有三个东西:提交队列、完成队列、任务实体
参考文章: