知乎上的面试题:https://zhuanlan.zhihu.com/p/546032003
一、Topk问题以及变种,各种解法
微博的热门排行就属于 TopK 问题 TopK 一般是要求在 N 个数的集合中找到最小或者最大的 K 个值,通常 N 都非常得大。

算法的优点是不用在内存中读入全部的元素,能够适用于非常大的数据集
TopK 变种问题
TopK 变种的问题,就是从 N 个有序队列中,找到最小或者最大的 K 个值。这个问题的不同点在于,是对多个数据集进行排序。由于初始的数据集是有序的,因此不需要遍历完 N 个队列中所有的元素。因此,解题思路是如何减少要遍历的元素。
解题思路如下图所示。

堆排序必须构建成完全二叉树(处理数组类型)
二叉树中的父节点的值必须大于子节点的值
知道某个节点的下标,那么它的父节点,左右子节点都能计算出来,i为当前节点的下标。

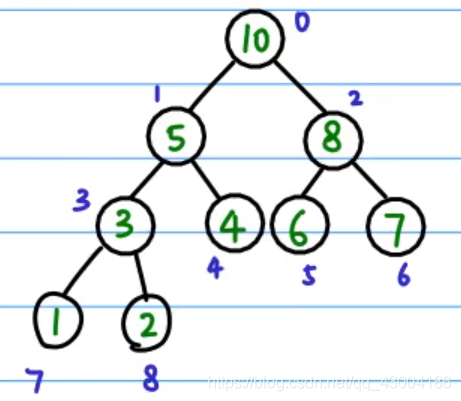
一、对某个节点(以及其左右子节点这颗子树)进行堆构造,即比较parent,leftChild,rightChild这个三个节点的值,将最大的值与parent节点交换,同时再对交换的子节点进行一次堆构造
void Heapify(int[] tree, int length, int heapIndex)
{
if (heapIndex >= length)
return;
// 计算左子节点的下标
int leftChildIndex = 2 * heapIndex + 1;
// 计算右子节点下标
int rightChildIndex = 2 * heapIndex + 2;
// 最大节点的下标
int maxIndex = heapIndex;
// 比较最大节点的下标
if (leftChildIndex < length && tree[leftChildIndex] > tree[maxIndex])
maxIndex = leftChildIndex;
if (rightChildIndex < length && tree[rightChildIndex] > tree[maxIndex])
maxIndex = rightChildIndex;
// 如果最大节点不是父节点才处理
if (maxIndex != heapIndex)
{
// 交换值
Swap(tree, maxIndex, heapIndex);
// 对处理的节点再次进行Heapify
Heapify(tree, length, maxIndex);
}
}
二、BuildHeap
构造整个堆,Heapify一般只能构造单个节点的堆,如果要构造整个二叉树堆,只需要找到最后一个节点的父节点,再对小于等于这个父节点下标的节点进行Heapify。
找到最后一个节点(下标为8)的父节点(下标为3),然后对[3, 2, 1, 0]这几个节点进行Heapify,就能得到一颗构造完成的堆的二叉树
void BuildHeap(int[] tree, int length)
{
// 获取最后一个节点下标
int lastIndex = length - 1;
// 获取其父节点下标
int parentIndex = (lastIndex - 1) / 2;
// 对这些节点heapify
for(int i = parentIndex; i >= 0; i--)
{
Heapify(tree, length, i);
}
}三、HeapSort
经过构造堆,那么二叉树的根节点一定是最大的值,排序时,只需要将根节点与最后一个节点进行替换,再次Heapify根节点,注意,这个时候构造就不需要再次算上最后一个节点了,因为它已经是最大的值了。
void HeapSort(int[] tree)
{
BuildHeap(tree, tree.Length); // 构造堆
for(int i = tree.Length - 1; i >= 0; i--)
{
Swap(tree, i, 0); // 交换根节点跟最后一个节点
Heapify(tree, i, 0); // 去掉最后一个值
}
}二、100万个数据快速插入删除和随机
三、1小时燃烧完的绳子,任意根,衡量出15分钟
1. 度量30分钟:
取一根绳子,从两端燃尽所欲要的时间就是半个小时。
2. 度量15分钟:
取两根绳子,第一根从一段燃烧,另二根从两端同时燃烧。当第二根燃尽的时候,将第一根剩余绳子从两端燃烧,第一根绳子剩余从两端燃烧耗尽所需要的时间就是15分钟。
3. 度量45分钟:
取两根绳子,采用上述方法所需的总时间就是45分钟(30+15)
4. 度量75分钟
取三根绳子,其中两根采用上述方法得到燃尽需要半个小时的绳子,然后从两端烧燃尽需要15分钟,取第三根绳子从一段烧,总共需要75分钟(15+60).
四、Unity资源相关问题,内存分布,是否copy等
https://blog.csdn.net/qq_27880427/article/details/79231315
Unity中的内存种类
实际上Unity游戏使用的内存一共有三种:程序代码、托管堆(Managed Heap)以及本机堆(Native Heap)。
程序代码包括了所有的Unity引擎,使用的库,以及你所写的所有的游戏代码。在编译后,得到的运行文件将会被加载到设备中执行,并占用一定内存。
托管堆是被Mono使用的一部分内存。Mono项目一个开源的.net框架的一种实现,对于Unity开发,其实充当了基本类库的角色。托管堆用来存放类的实例(比如用new生成的列表,实例中的各种声明的变量等)。“托管”的意思是Mono“应该”自动地改变堆的大小来适应你所需要的内存,并且定时地使用垃圾回收(Garbage Collect)来释放已经不需要的内存。关键在于,有时候你会忘记清除对已经不需要再使用的内存的引用。
本机堆是Unity引擎进行申请和操作的地方,比如贴图,音效,关卡数据等。Unity使用了自己的一套内存管理机制来使这块内存具有和托管堆类似的功能。
WWW的assetBundle就是内部数据读取完后自动创建了一个assetBundle而已
Create完以后,等于把硬盘或者网络的一个文件读到内存一个区域,这时候只是个AssetBundle内存镜像数据块,还没有Assets的概念。
用AssetBundle.Load(同Resources.Load) 这才会从AssetBundle的内存镜像里读取并创建一个Asset对象,创建Asset对象同时也会分配相应内存用于存放(反序列化),异步读取用AssetBundle.LoadAsync
AssetBundle.Unload(flase)是释放AssetBundle文件的内存镜像,不包含Load创建的Asset内存对象。
AssetBundle.Unload(true)是释放那个AssetBundle文件内存镜像和并销毁所有用Load创建的Asset内存对象。
你 Instaniate一个Prefab,是一个对Assets进行Clone(复制)+引用结合的过程,GameObject transform 是Clone是新生成的。其他mesh / texture / material / shader 等,这其中些是纯引用的关系的,包括:Texture和TerrainData,还有引用和复制同时存在的,包括:Mesh/material /PhysicMaterial。引用的Asset对象不会被复制,只是一个简单的指针指向已经Load的Asset对象。
所以你Load出来的Assets其实就是个数据源,用于生成新对象或者被引用,生成的过程可能是复制(clone)也可能是引用(指针)
当你Destroy一个实例时,只是释放那些Clone对象,并不会释放引用对象和Clone的数据源对象,Destroy并不知道是否还有别的object在引用那些对象。
等到没有任何 游戏场景物体在用这些Assets以后,这些assets就成了没有引用的游离数据块了,是UnusedAssets了,这时候就可以通过Resources.UnloadUnusedAssets来释放,Destroy不能完成这个任 务,AssetBundle.Unload(false)也不行,AssetBundle.Unload(true)可以但不安全,除非你很清楚没有任何 对象在用这些Assets了。
先建立一个AssetBundle,无论是从www还是文件还是memory,用AssetBundle.load加载需要的asset,加载完后立即AssetBundle.Unload(false),释放AssetBundle文件本身的内存镜像,但不销毁加载的Asset对象。(这样你不用保存AssetBundle的引用并且可以立即释放一部分内存)
释放时:如果有Instantiate的对象,用Destroy进行销毁,在合适的地方调用 Resources.UnloadUnusedAssets,释放已经没有引用的Asset.
为什么第一次Instaniate 一个Prefab的时候都会卡一下?
因为在你第一次Instaniate之前,相应的Asset对象还没有被创建,要加载系统内置的 AssetBundle并创建Assets,第一次以后你虽然Destroy了,但Prefab的Assets对象都还在内存里,所以就很快了。
AssetBundle.Load(name): 从AssetBundle读取一个指定名称的Asset并生成Asset内存对象,如果多次Load同名对象,除第一次外都只会返回已经生成的Asset对象,也就是说多次Load一个Asset并不会生成多个副本(singleton)。
AssetBundle.Unload(false):释放AssetBundle文件内存镜像
AssetBundle.Unload(true):释放AssetBundle文件内存镜像同时销毁所有已经Load的Assets内存对象
Reources.UnloadAsset(Object):显式的释放已加载的Asset对象,只能卸载磁盘文件加载的Asset对象
Resources.UnloadUnusedAssets:用于释放所有没有引用的Asset对象
从磁盘读取一个1.unity3d文件到内存并建立一个AssetBundle1对象
AssetBundle AssetBundle1 = AssetBundle.CreateFromFile("1.unity3d");
从AssetBundle1里读取并创建一个Texture Asset,把obj1的主贴图指向它
obj1.renderer.material.mainTexture = AssetBundle1.Load("wall") as Texture;
把obj2的主贴图也指向同一个Texture Asset
obj2.renderer.material.mainTexture =obj1.renderer.material.mainTexture;
Texture是引用对象,永远不会有自动复制的情况出现(除非你真需要,用代码自己实现copy),只会是创建和添加引用
如果继续:
AssetBundle1.Unload(true) 那obj1和obj2都变成黑的了,因为指向的Texture Asset没了
如果:
AssetBundle1.Unload(false) 那obj1和obj2不变,只是AssetBundle1的内存镜像释放了
继续:
Destroy(obj1),//obj1被释放,但并不会释放刚才Load的Texture
如果这时候:
Resources.UnloadUnusedAssets();
不会有任何内存释放 因为Texture asset还被obj2用着
如果
Destroy(obj2)
obj2被释放,但也不会释放刚才Load的Texture
继续
Resources.UnloadUnusedAssets();
这时候刚才load的Texture Asset释放了,因为没有任何引用了。
优化程序代码的内存占用:
默认的Mono包含库可以说大部分用不上,在Player Setting(Edit->Project Setting->Player或者Shift+Ctrl(Command)+B里的Player Setting按钮)
面板里,将最下方的Optimization栏目中“Api Compatibility Level”选为.NET 2.0 Subset,表示你只会使用到部分的.NET 2.0 Subset,不需要Unity将全部.NET的Api包含进去。
托管堆优化:
托管堆中存储的是你在你的代码中申请的内存(不论是用js,C#还是Boo写的)。
一般来说,无非是new或者Instantiate两种生成object的方法(事实上Instantiate中也是调用了new)。用对象池创建对象。
本机堆的优化
在 Resource.UnloadAsset()和Resources.UnloadUnusedAssets()时,只有那些真正没有任何引用指向的资源 会被回收,因此请确保在资源不再使用时,将所有对该资源的引用设置为null或者Destroy。这两个Unload方法仅仅对Resource.Load拿到的资源有效,而不能回收任何场景开始时自动加载的资源。
Unity会在Asset文件夹相同位置生成资源的.meta文件,用以记录资源设置参数与GUID 。
Unity 2020之后的版本,会在Library下生成ArtifactDB和SourceAssetDB文件。
SourceAssetDB包含.meta相关数据(上次修改日期、文件内容哈希、GUID和其他元数据信息),由此判断是否需要重新导入资源。
ArtifactDB包含每个源资源的导入结果的信息。每个Artifact都包含导入依赖项信息、Artifact元数据信息和 Artifact文件列表。
项目中经常遇到资源引用丢失:(1)美术资源与meta没有一起上传,导致prefab无法通过guid找到资源。(2)美术替换资源时,先删除原有资源,再导入创建新资源,导致原有的prefab引用的guid失效。
1.CPU访问内存是一个慢速过程,因此会使用cache来加速访问,PU如果在Cache中没有找到数据,称为一次Cache Missing,如果内存数据 指令是不连续的,会导致大量的Cache Missing。
Unity的ECS和DOTS的目的之一就是提高内存的连续性,减少Cache Missing。
Native内存最佳实践
scene中GameObject的数量是否过多,数量过多会导致native内存显著增涨,在创建一个GameObject的时候,Unity会在C++中构建一个或者多个的Object来保存相关信息,因此,当发现Native内存过大时,优先检查Scene中的GameObject数量 。
Audio Android设备上常常出现声音延迟过大,优先看这选项DSP buffer。左右声道完全一致 的开启Force to mono,
code size,模板泛型的滥用,编译C++时,会把所有的泛型展开为静态类,如果一个类使用了四个泛型,编译出来的cpp文件可能高达25M,这对il2cpp的编译速度造成很大影响,因为一个单一的cpp文件,是无法并行编译的
AssetBundle
(1)TypeTree
用于不同版本构建的AssetBundle可以在不同版本的Unity上保持兼容,防止序列化出错,如果Build AssetBundle的Unity版本和运行时的版本一致,可以关闭这个功能,关闭之后有三个好处
a.减少内存占用
b.减小包体大小
c.build和运行时会变快,因为当需要序列化有TypeTree的AssetBundle时,会序列化两次,先序列化TypeTree信息,再序列化数据,反序列化也需要两次
(2)LZ4&Lzma
LZ4是一种trunk-base的压缩技术,速度几乎是Lzma的10倍,但是压缩的体积会高出30%,trunk-base的压缩方式,在解压时可以减少内存占用,因为不需要解压整个文件,解压每个trunk的时候,可以复用buffer(在中国增强版中会推出一个基于LZ4的AssetBundle加密功能)
(3)Size&Count
就是AssetBundle的颗粒度控制,尽量减少AssetBundle的数量,可以减少AssetBundle头文件的内存和包体大小占用,有的资源的头文件甚至比数据还大,官方建议一个AssetBundle的大小在1-2M之间,不过这个建议是考虑网络带宽的影响,实际使用可以根据自身的环境设置。
Texture (1)upload buffer,和DSP buffer类似,就是填满多少Texture数据时,向GPU push一次。
(2)没必要不开启read/write,Texture正常的加载流程为加载进内存 -> 解析 -> upload buffer -> 从内存中delete,开启选项后,不会从内存delete,导致内存和显存中都存在一份。
(3)不开启mip maps
mesh
(1),read/write,非必要不开
(2),compression,有些版本中开了不如不开。
Managed内存最佳实践
Don’t Null it,but Destroy it
不要置空就完事了,记得显式调用Destroy
Class VS Struct
可以关注Unity的DOTS和ECS
Closures and anonymous methods(闭包和匿名函数)
Coroutines(协程)
协程可以看作闭包和匿名函数的特例,在il2cpp中,每一个闭包和匿名函数,都会new一个对象出来,只是无法访问,里面的数据,即使是你认为用完就丢的局部变量,在你用完了之后,也不会立即释放,而是等到这个对象释放才释放,有的项目在游戏一开始就开启一个协程,一直到游戏结束,这样使用是错误的,会导致闭包中的数据一直占用内存,正确的做法是用到的时候生成一个协程,不用的时候就扔掉,协程的设计不是当作线程使用的。
ingleton(单例)
一定要慎用,在C++的年代,这就是万恶之源,不要什么都往这里面扔,会导致内存无法释放,注意单例的引用关系,当引用关系变得复杂时,很难确定哪些东西没有及时释放
五、Unity动画相关问题
https://zhuanlan.zhihu.com/p/492136094?utm_id=0
动画 (Animation) 组件和 Animator 组件之间有何差异?
Animation需要通过代码手动控制动画的播放和迁移。而Animator拥有动画状态机,可以通过动画状态机来设置动画之间的状态,并且可以为单个动画设置脚本代码来控制事件。
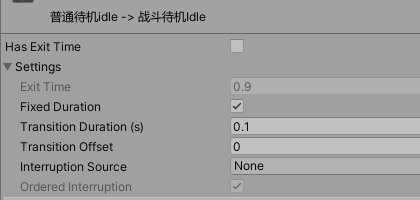
(1)Exit Time 如果勾选了Has Exit Time,该参数是可以设置的,设置动画退出的单位化时间。例如设置为0.75,代表动画播放到75%时为true,如果没有其他条件,会直接切换到下一个State。
如果exit time小于1,那么state每次循环到对应位置的时候(不管动画是否设置为循环,state总是循环的),该条件都会为true。比如第一次播放到75%,第二次播放到75%……时退出条件都会为true。
如果exit time大于1,该条件只会检测一次。比如exit time为3.5,state的动画会在循环3次后,在播放到第4次的50%时为true。
(2)Fixed Duration (s)勾选时,下方Transition Duration参数的单位是秒,不勾选时,参数会作为一个百分比。
(3)Transition Duration 的两个动画转换的过渡时间。
(4)Transition Offset 下一个状态开始播放的时间偏移。比如设置为0.5,则转换到下一个State时,会从50%的位置开始播放。
六、 帧同步和状态同步区别等一系列问题
帧同步(Lock Step):同步的是客户端的操作指令。客户端上传操作到服务器,并且服务器并不做过多的处理,然后将当前帧间隔内收集到的操作指令广播给每一个客户端,各个客户端在一致环境下,处理同样的操作输入,则会得到同样的结果。
状态同步(State Synchronization):同步的是游戏中的各种状态。一般的流程是客户端上传操作到服务器,服务器收到后计算游戏行为的结果,然后以广播的方式下发游戏中各种状态,客户端收到状态后再根据状态显示内容。
逻辑计算
战斗逻辑在帧同步中是在客户端计算,在状态同步中是由服务端计算的。
帧同步下服务端只进行转发操作,不进行逻辑处理。大型多人游戏(MMO)就必须交给服务端计算,因为远距离的单位以及场景都不显示,客户端没有足够信息计算全图的行为。
状态同步下,客户端只是对服务器传来的数据进行显示而已,并不能改变它。具体场景中:空护短检测到玩家开枪发射子弹 —— 服务端通知子弹的发射方向和模型数据 —— 客户端根据信息创建游戏物体,本地计算子弹接下来的位置 —— 碰撞检测后服务端通知客户端 —— 客户端播放敌人受击效果等视觉效果
因此,状态同步流量消耗更大,因为他每次都要同步并通知所有的属性,帧同步只需要转发就够。
https://blog.csdn.net/u012861978/article/details/123172134
https://zhuanlan.zhihu.com/p/357973435
实现帧同步的流程一般是:
1、同步随机数种子。(一般游戏中都设计随机数的使用, 通过同步随机数种子,可以保持随机数一致性)
2、客户端上传操作指令。(指令包括游戏操作和当前帧索引)
3、服务器广播所有客户端的操作。(如果没有操作, 也要广播空指令来驱动游戏帧前进)。
服务器的实现:服务器基于帧的概念,在每一帧内收集客户端发过来的操作,这一帧时间到就广播给所有客户端。(每隔一段时间(一帧)向所有客户端发送所有玩家操作)。即:收集操作—>发送操作—>收集操作—>发送操作...
客户端的实现:收到服务器的操作----》计算游戏逻辑----》上报下一帧的操作给服务器。因为所有客户端代码相同,并且每个客户端收到到的操作参数也相同,所以每个客户端计算结果也是相同的,从而达到同步。这样会导致一个问题:每一帧同步的玩家太多,服务器收集和发送的消息体积会很大。比如玩家数量为n的话,每一帧每个玩家操作a次,这一帧需要上传的操作有a*n次,玩一局游戏只有少数玩家的情况下,才使用帧同步,比如Moba:守望先锋,王者荣耀。
实现状态同步的一般流程是:
1、客户端上传操作到服务器,
2、服务器收到后计算游戏行为的结果,然后以广播的方式下发游戏中各种状态,
3、客户端收到状态后再根据状态显示内容。
七、帧同步要注意的问题
帧同步的基础,是不同的客户端,基于相同的操作指令顺序,各自执行逻辑,能得到相同的效果。就如大家所知道的,在Unity引擎中,不同的调用顺序,时序,浮点数计算的偏差,容器的排序不确定性,Coroutine内写逻辑带来的不确定性,物理浮点数,随机数值带来的不确定性等等。
浮点数:用定点数数学库。用到了Physics.Raycast来检测地面和围墙,让人物可以上下坡,走楼梯等高低不平的路,也可以有形状不规则的墙。 网络协议:用UDP;
逻辑和显示完全分离;
游戏逻辑的回滚:
客户端的时间,领先服务器,客户端不需要服务器确认帧返回才执行指令,而是玩家输入,立刻执行(其他玩家的输入,按照其最近一个输入做预测,或者其他更优化的预测方案),然后将指令发送给服务器,服务器收到后给客户端确认,客户端收到确认后,如果服务确认的操作,和之前执行的一样(自己和其他玩家预测的操作),将不做任何改变,如果不一样(预测错误),就会将游戏整体逻辑回滚到最后一次服务器确认的正确帧,然后再追上当前客户端的帧。
例子:
当前客户端(A,B)执行到100帧,服务器执行到97帧。在100帧的时候,A执行了移动,B执行了攻击,A和B都通知服务器:我已经执行到100帧,我的操作是移动(A),攻击(B)。服务器在自己的98帧或99帧收到了A,B的消息,存在对应帧的操作数据中,等服务器执行到100帧的时候(或提前),将这个数据广播给AB。
然后A和B立刻开始执行100帧,A执行移动,预测B不执行操作。而B执行攻击,预测A执行攻击(可能A的99帧也是攻击),A和B各自预测对方的操作。
在A和B执行完100帧后,他们会各自保存100帧的状态快照,以及100帧各自的操作(包括预测的操作),以备万一预测错误,做逻辑回滚。
执行几帧后,A和B来到了103帧,服务器到了100帧,他开始广播数据给AB,在一定延迟后,AB收到了服务器确认的100帧的数据,这时候,AB可能已经执行到104了。A和B各自去核对服务器的数据和自己预测的数据是否相同。例如A核对后,100帧的操作,和自己预测的一样,A不做任何处理,继续往前。而B核对后,发现在100帧,B对A的预测,和服务器确认的A的操作,是不一样的(B预测的是攻击,而实际A的操作是移动),B就回滚到上一个确认一样的帧,即99帧,然后根据确认的100帧操作去执行100帧,然后快速执行101~103的帧逻辑,之后继续执行104帧,其中(101~104)还是预测的逻辑帧。
原文链接:https://blog.csdn.net/yptianma/article/details/103268503
https://blog.csdn.net/yptianma/article/details/103268503
八、随机数如何保证同步
电脑中的随机数都是伪随机数,要设置一个随机种子,根据随机种子生成随机的序列。伪随随机数有个特点,随机种子一样,产生的随机序列一样,所以帧同步用随机数,让每个客户端设置相同的随机种子就可以产生相同的随机结果。
使用相同的伪随机生成算法,然后同步一下随机序列种子,后面只要逻辑代码和调用顺序严格一致就可以了。
十、数组第k大的数
(1)、快速排序
利用快速排序的思想,只需找到第k大的数,不必把所有的数排好序。
思路分析:先任取一个数(找到基准值),把比它大的数移动到它的右边,比它小的数移动到它的左边。移动完成一轮后,看该数的下标(从0计数),如果刚好为length-k,则它就是第k大的数(因为移动后的基准值左边都是比它小的数,右边都是比他大的数,右边若没有元素,则说明当前基准值是第1大元素,若右边有1个元素,则说明当前基准值是第2大元素,若右边有2个元素,则说明当前基准值是第3大元素......即当前基准值右边有k-1个元素,或当前基准值的下标为length-k,则说明当前基准值是第k大元素),如果小于length-k,说明第k大的数在它右边,如果大于length-k,则说明第k大的数在它左边,取左边或者右边继续进行移动,直到找到。
package com.csu.marden;
public class Demo6 {
public static void main(String[] args) {
int [] arr={3,1,2,5,4,7,6};
int k=2;
System.out.println(quickSort(arr, 0, arr.length-1, k));
}
//使用快速排序的原理,寻找第k大的数
public static int quickSort(int [] arr,int start,int end,int k){
//递归结束条件
if(start>end){
return -1;
}
int i=start;
int j=end;
int base=arr[start];
while(i<j){
while(i<j && arr[j]>=base){
j--;
}
while(i<j && arr[i]<=base){
i++;
}
if(i<j){
int temp=arr[j];
arr[j]=arr[i];
arr[i]=temp;
}
}
//此时i=j,交换base元素的位置
arr[start]=arr[i];
arr[i]=base;
if(i==arr.length-k){
//查找到第k大的数字
return arr[i];
}
else if(i<arr.length-k){
//在基准值右边寻找
return quickSort(arr, i+1, end, k);
}else{
//在基准值左边寻找
return quickSort(arr, start, i-1, k);
}
}
}(2)、堆排序解决方案:因为我们只需要求第k大的数字,而排序是把每个数字都排序,所以直接对数组进行排序的话时间复杂度就会很高。 用堆排序,首先把数组变 成大顶堆数组(把数组看成一个堆,依次根据数组下标排成二叉树,再对二叉树进行大顶堆化,这样这个数组就是一个大顶堆啦),变成之后,数组第一个位置就是最大的位置,我们把这个位置和数组最后一个位置进行交换,再对第一个位置进行大顶堆化。
class Solution {
public int findKthLargest(int[] nums, int k) {
int len=nums.length;
//先构造大顶堆
for(int i=len/2;i>0;i--){
heapSort(nums,i,len);
}
//找出第k大的数字
for(int i=0;i<k;i++){
if(i+1==k) return nums[0];
int temp=nums[0];
nums[0]=nums[len-1-i];
nums[len-1-i]=temp;
heapSort(nums,1,len-1-i);
}
return -1;
}
//这个函数的意思就是对二叉树中的位置i
//依次和它的左孩子和右孩子比较,孩子大的话就和孩子交换顺序
//交换完之后,还需要对这个位置递归,因为要保证每一个节点都是大顶堆
//左孩子:2*i;右孩子:2*i+1 重点理解 ======》》》》》(数组会-1)
public void heapSort(int[] nums,int i,int n){
int j=2*i;//左孩子
if(j<=n)
{
if(j+1<=n)
{
if(nums[j-1]<nums[j]) j+=1;
}
if(nums[j-1]>nums[i-1])
{
int temp=nums[j-1];
nums[j-1]=nums[i-1];
nums[i-1]=temp;
heapSort(nums,j,n);
}
}
}
}
————————————————
版权声明:本文为CSDN博主「干干淦干干」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_46228051/article/details/124837732十一、1~n有一个数字没有,找到这个数
(1)、1~n一共n个数的和是n*(n+1)/2,然后减去数组中这n-1个数的和,得到的数即是要找的那个数。
public int find_Miss_Number_By_Sum(int array[], int n) {
int sum = 0;
if (array.length != n - 1)
throw new IllegalArgumentException("数组内的自然数目少于n-1");
for (int i : array) {
sum += i;
}
return n * (n + 1) / 2 - sum;
} (2)、用快排的思想,在1-N中选取游标X对数组快排一次,如果X被放在a[X-1]的位置上那么,要找的数字在X-N之间
否则X被放在a[X-2]的位置上 要找的数字在1-X-1之间 递归求解,直到找的要找的数字。
扩展:少K个数。
(3)、用时间移动-排序
FindMissNum(new int[] { 1, 3, 2, 5, 7, 6, 9 }, 9);
public void FindMissNum(int[] arrayA,int n)
{
int[] ArrayB = new int[n];
for(int i = 0; i < arrayA.Length; i++)
{
ArrayB[arrayA[i]-1] = arrayA[i];
}
for(int j = 0; j < ArrayB.Length; j++)
{
if (ArrayB[j] == 0)
{
Debug.LogError("输出的数字 " + (j+1));
}
}
}十二. 如何分析程序运行效率瓶颈,log分析
https://www.bilibili.com/read/cv12044128/
http://www.taodudu.cc/news/show-4588931.html
十三、背包优化
没有优化过的背包,最大的消耗在于物品的销毁与实例化。
A2:以下是我想到的一些点,期待其他大神补充更多的内容。项目中实际遇到的具体问题还需要具体分析,通过性能工具进行定位消耗过高的地方,然后有针对性地进行合理优化。
1.对于未优化的背包,列表滚动过程中,Cell的加载和销毁会造成卡顿。
解决办法:使用无限循环滚动列表UILoopScrollRect这种控件,使Cell可以进行复用,避免物体的频繁实例化和销毁。
2.背包打开一瞬间,加载了很多个格子物品进来,造成卡顿和内存冲高,GC等问题。
解决办法:分帧加载,控制一帧实例化的Cell个数,避免在同一帧内大量创建格子物品。针对资源Load过程中的卡顿,可以采用提前预加载资源到内存的方式。
3.背包刷新时卡顿,大量的格子监听某个事件,刷新时可能造成卡顿。
解决办法:用脏标志的方式去刷新,不该刷新的部分不刷新。
4.Cell上的图片,粒子特效显示等设计不合理造成DrawCall过高。
解决办法:这个需要结合具体的项目和设计方案进行分析和优化。
十四、 Unity ui如何自适应
Canvas Scaler选项中的UI Scale Mode有3个选项:恒定像素、随屏幕尺寸缩放、恒定物理大小。这里我推荐用第二项随屏幕尺寸缩放。这样在大小不同的分辨率中ui可以自动变大变小。
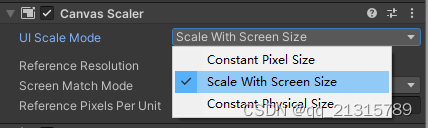
选择第二项之后需要填入我们使用的标准分辨率。填我们制作时主要考虑的分辨率即可。 之后制作时也是先在这个分辨率下制作和观察效果,之后再切换其它分辨率看有没有问题。
下面的Screen Match Mode选项有三个选项:匹配宽和高、扩展、收缩。分别解释:
匹配宽和高:会根据权重随宽高进行调整。 下方会出现一个滑竿用于调整权重。一般直接取中间即可。

扩展:当屏幕比例不是标准比例时,扩展画布长宽之一以达到比例。能使ui完整显示出来。但也可能在屏幕边缘出现无内容的区域。我感觉比起上一项,这个选项更利于保持ui间的位置不变。

收缩:当屏幕比例不是标准比例时,收缩画布长宽之一以达到比例。有可能使ui部分处在屏幕外。


相机的三种模式:
(1)Overlay—覆盖模式,所有UI都会显示在场景中2D,3D物体的上层,多个Canvas下可以调整Canvas组件的Sort Order属性调整渲染顺序,数值越小的画布越先被渲染。
(2)Camera—相机模式,指定相机渲染,Canvas只会在指定相机下被渲染,通过Canvas组件的Plane Distance属性可以调节指定相机与Canvas的距离(本质其实就是改变Canvas的z轴坐标),Plane Distance的最小最大值就是指定相机上Camera组件的Near和Far的数值
这种模式下的渲染顺序作用大小:Camera的Depth\u003eSorting Layer\u003eOrder in Layer\u003ePlane Distance
这种模式经常应用于指定一个相机b只渲染一张游戏背景图片,相机a是要跟随人物移动的,相机b只渲染游戏背景图片的Canvas
Camera模式下,Canvas的x轴和y轴坐标就是指定Camera的x和y坐标,z轴坐标是指定Camera的z坐标+Canvas组件的Plane Distance数值
(3)、World Space—世界空间模式
前两种模式的Rect Transform都是不可修改的,而世界空间模式可以自定义Rect Transform的数值
这种模式经常应用于人物血条的显示
画布和世界空间的比例是100:1,使用世界空间模式时一般将Canvas的Scale设置为0.01,就和世界空间的比例一致了
十五、A*寻路实现
A星寻路
https://mp.csdn.net/mp_blog/creation/editor/93427079
6边形寻路
https://mp.csdn.net/mp_blog/creation/editor/121537418