Whisper
仓库地址:
https://github.com/openai/whisper
可用模型信息:
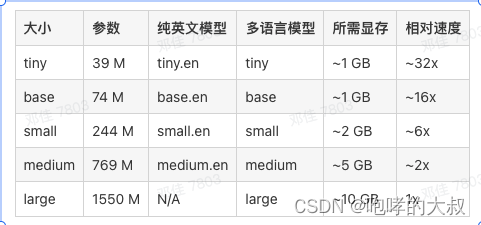
测试视频:18段,总共447S视频(11段前:有11段开头有停顿的视频)
Tiny: 跑完:142S ,11段前,对0段,18段中,对10段,5段后,对5段。
Large:跑完:941S,11段前,对0段,18段中,对2段,5段后,对4段。
WhisperX:跑完:143S ,11段前,对10段,18段中,对17段,5段后,对5段。
开口说话到,发出音,大概有13,14,12,20,帧左右的误差,也就是说有0.8S左右的误差,所以建议,如果取无声音频,end要往前挪10帧。
有的人,在静默的时候还咧嘴笑一笑
一句话说完,从没有声音到完全闭上嘴,大概有5帧,8帧,10帧左右,大概有0.4S左右的误差。
WhisperX误差统计(单位:秒):
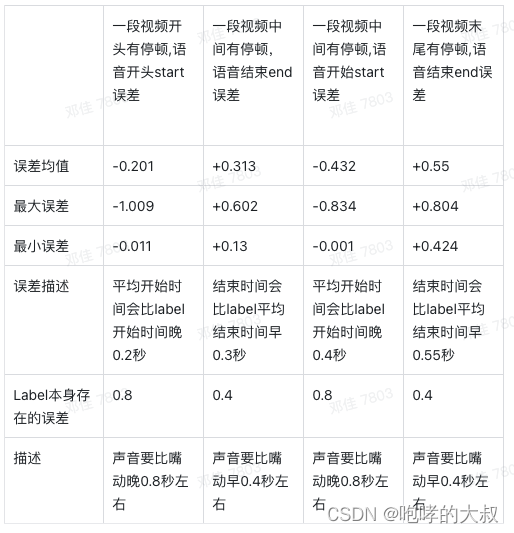
总结:1)WhisperX会在视频停顿空语音前,比label都早停顿。缺点:一句话后几个字可能被裁减掉,对我们的影响是浪费不到1秒的原数据。优点:没语音了,嘴没闭的情况可以解决;
2)WhisperX会在视频停顿空语音后,比label都晚停顿。缺点:一句话开头几个字可能被裁减掉,对我们的影响是浪费不到1秒的原数据。优点:说话前,嘴动了,却还没发出声的情况,过滤掉。
whisperX
牛津大学的博士生Max Bain开源的模型
https://github.com/m-bain/whisperX
效果如上表所示,很好。
WhisperX accepted at INTERSPEECH 2023
达摩院语音团队Paraformer
https://github.com/alibaba-damo-academy/FunASR
效果:

即:每个字都有start 和end时间戳,没有断句的功能
飞书秒记
https://www.feishu.cn/product/minutes
只有字幕,没有时间戳
FSMN语音端点检测-中文-通用-16k
https://www.modelscope.cn/models/damo/speech_fsmn_vad_zh-cn-16k-common-pytorch/summary