概念
Hugging Face Hub和 Github 类似,都是Hub(社区)。Hugging Face可以说的上是机器学习界的Github。Hugging Face为用户提供了以下主要功能:
模型仓库(Model Repository):Git仓库可以让你管理代码版本、开源代码。而模型仓库可以让你管理模型版本、开源模型等。使用方式与Github类似。
模型(Models):Hugging Face为不同的机器学习任务提供了许多预训练好的机器学习模型供大家使用,这些模型就存储在模型仓库中。
数据集(Dataset):Hugging Face上有许多公开数据集。
hugging face在NLP领域最出名,其提供的模型大多都是基于Transformer的。为了易用性,Hugging Face还为用户提供了以下几个项目:
Transformers : Transformers提供了上千个预训练好的模型可以用于不同的任务,例如文本领域、音频领域和CV领域。该项目是HuggingFace的核心,可以说学习HuggingFace就是在学习该项目如何使用。
Datasets : 一个轻量级的数据集框架,主要有两个功能:①一行代码下载和预处理常用的公开数据集; ② 快速、易用的数据预处理类库。
Accelerate : 帮助Pytorch用户很方便的实现 multi-GPU/TPU/fp16。
Space :Space提供了许多好玩的深度学习应用,可以尝试玩一下。
Transforms
Hugging Face Transformer是Hugging Face最核心的项目,可以用它做以下事情:
- 直接使用预训练模型进行推理
- 提供了大量预训练模型可供使用
- 使用预训练模型进行迁移学习
安装
pip install git+https://github.com/huggingface/transformers 使用
from transformers import pipeline
translator = pipeline("translation_en_to_fr")
print(translator("How old are you?"))
对于部分特定任务,官方并没有提供相应的模型,但也可以到官网搜索模型,然后显示指定即可。在加载模型时,你有可能会因为缺少一些库而报错,这个时候,只需要安装对应的库,然后重启即可。
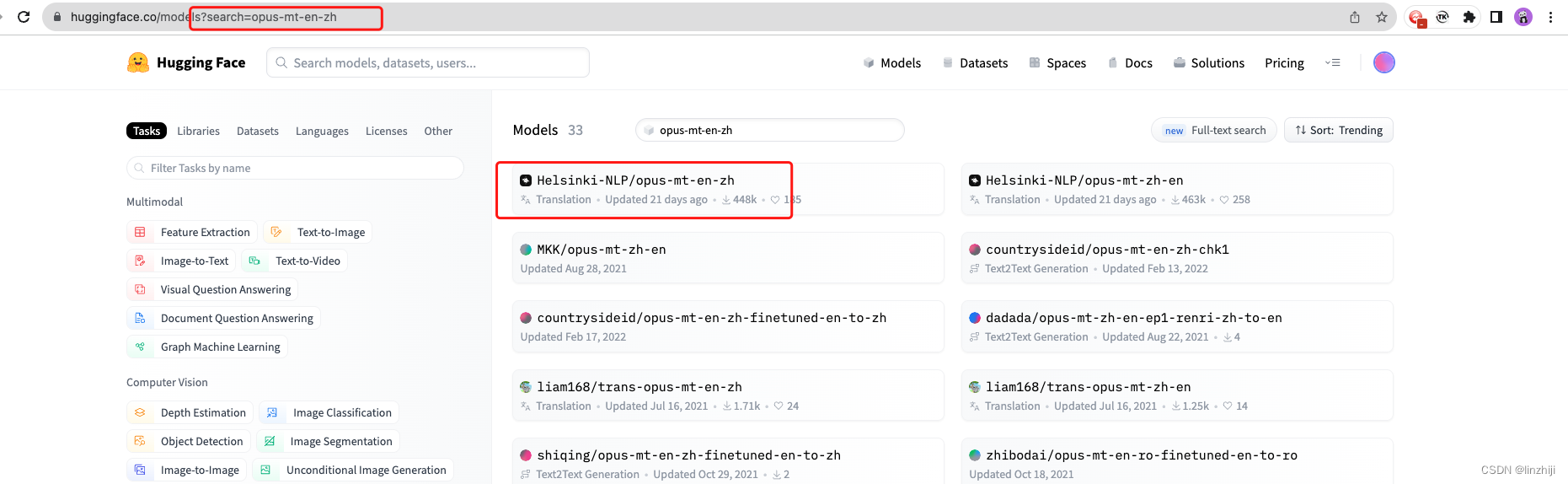
!pip install sentencepiece
translator = pipeline("translation_en_to_zh", model='Helsinki-NLP/opus-mt-en-zh')
translator("I'm learning deep learning.")Helsinki-NLP/opus-mt-en-zh · Hugging Face
diffusers
通用的模型训练框架 diffusers。diffusers 支持直接使用model或者训练model
- 只需要几行代码,就能够利用扩散diffusion模型生成图像,简直是广大手残党的福音
- 可以使用不同的“噪声调节器”,来平衡模型生成速度和质量之间的关系
- 更有多种不同类型的模型,能够端到端的构建diffusion模型
Pipelines: 高层类,以一种用户友好的方式,基于流行的扩散模型快速生成样本
Models:训练新扩散模型的流行架构,如UNet
Schedulers:推理场景下基于噪声生成图像或训练场景下基于噪声生成带噪图像的各种技术
pipeline
使用Hugging Face模型
Transformers项目提供了几个简单的API帮助用户使用Hugging Face模型,而这几个简单的API统称为AutoClass( 官方文档链接),包括:
- AutoTokenizer: 用于文本分词
- AutoFeatureExtractor: 用于特征提取
- AutoProcessor: 用于数据处理
- AutoModel: 用于加载模型
它们的使用方式均为: AutoClass.from_pretrain("模型名称"),然后就可以用了。例如:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokenizer("I'm learning deep learning.")通常一个模型会包含上述4个中的部分功能,例如,对于bert-base-uncased模型,就包含“分词”和“模型”两项功能,我们可以通过代码样例(Use in Transformers) 模块查看:

数据集
Datasets类库可以让你非常方便的访问和分享数据集,也可以用来对NLP、CV、语音等任务进行评价(Evaluation metrics).
pip install datasets
#使用语音(Audio)数据集
pip install datasets[audio]
#图片(Image)数据
pip install datasets[vision]
查找数据集
Hugging Face的数据集通常包括多个子集(subset),并且分成了train、validation和test三份。你可以通过预览区域查看你需要的子集。
from datasets import load_dataset
dataset = load_dataset("glue")
Hugging Face的数据集都是放在github上的,所以国内估计很难下载成功。这就要用到load_dataset的加载本地数据集。关于如何离线下载Hugging Face数据集,可参考 该篇文章
下载
import datasets
dataset = datasets.load_dataset("glue")
dataset.save_to_disk('your_path')加载离线
import datasets
dataset = load_from_disk("your_path")参考
Hugging Face快速入门(重点讲解模型(Transformers)和数据集部分(Datasets))_51CTO博客_hugging face transformers