VIT流程:
图片划分patch,加上class_token,加上位置编码,传到transformer,分类预测。
ViT绘制Grad-CAM热力图时要注意:
(1)在代码得到CAM图时,由于VIT最后得到的是patch的梯度,要reshape成二维图。
所以,去掉class_token序列,拿到所有组成原图的token,将它们reshape回原图的大小。
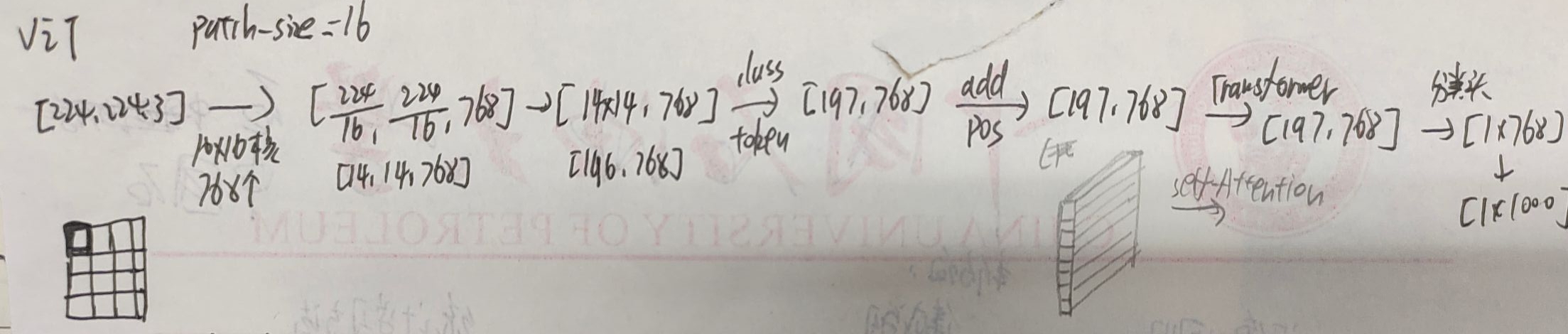
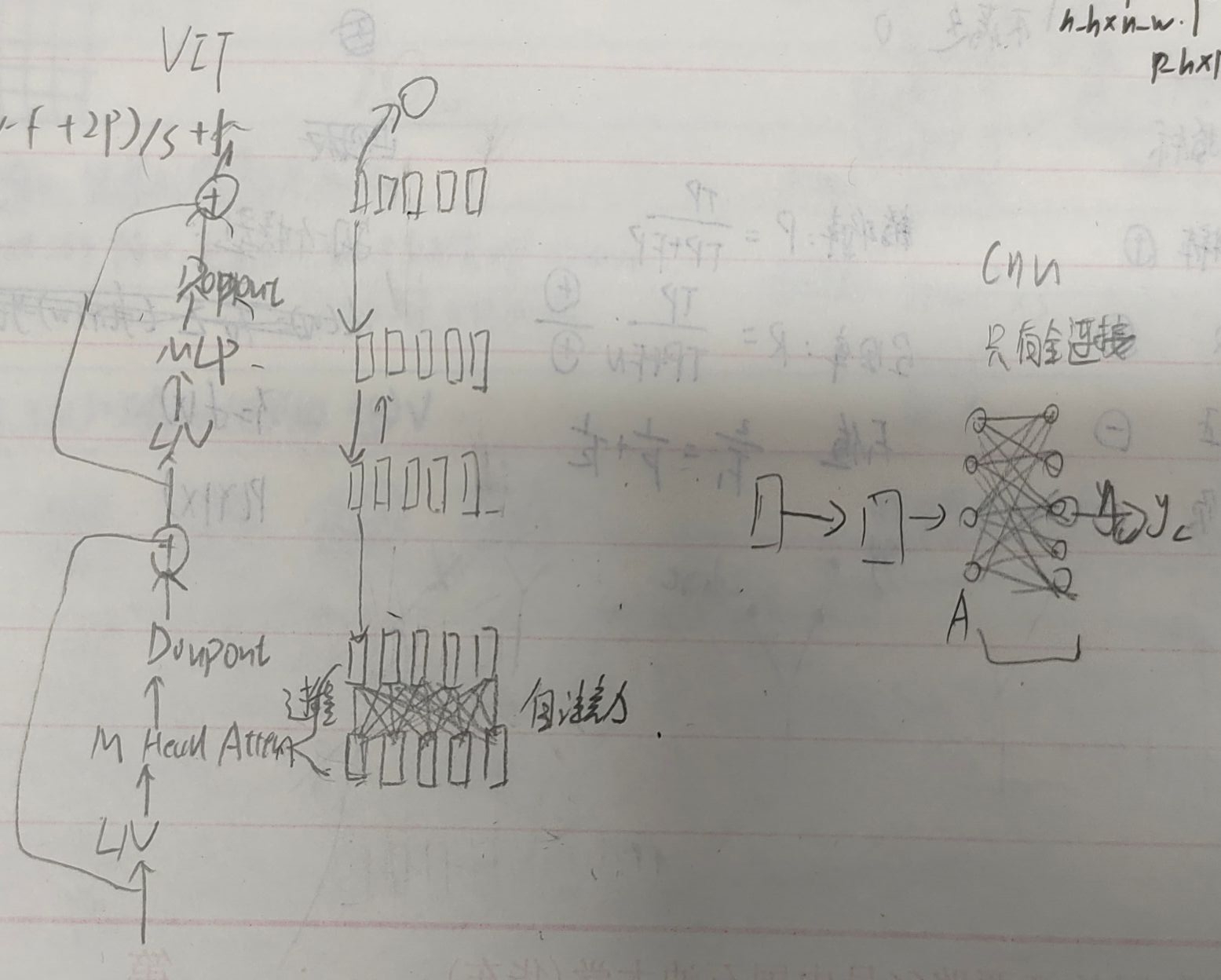
经过最后一个transformer block得到预测输出的示意图如下。
(2)反向梯度传播是从最后预测开始,逆着经过整个模型,而Dropout和MLP都是单个token做的,不能将最后y_c结果梯度传给所有token,只有在倒推回自注意力后才能将梯度返传给所有token。
而CNN最后一层全连接层,可以直接将梯度传给所有点。
import os
import numpy as np
import torch
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms
from utils import GradCAM, show_cam_on_image, center_crop_img
from vit_model import vit_base_patch16_224
class ReshapeTransform:
def __init__(self, model):
input_size = model.patch_embed.img_size
patch_size = model.patch_embed.patch_size
self.h = input_size[0] // patch_size[0]
self.w = input_size[1] // patch_size[1]
def __call__(self, x):# x是个token序列
# remove cls token and reshape
# [batch_size, num_tokens, token_dim]
#拿到所有组成原图的token,将它们reshape回原图的大小
result = x[:, 1:, :].reshape(x.size(0),#从1开始,忽略掉class_token
self.h,
self.w,
x.size(2))
# Bring the channels to the first dimension,
# like in CNNs.
# [batch_size, H, W, C] -> [batch, C, H, W]
result = result.permute(0, 3, 1, 2)
return result
def main():
model = vit_base_patch16_224()
# 链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
weights_path = "./vit_base_patch16_224.pth"
model.load_state_dict(torch.load(weights_path, map_location="cpu"))
target_layers = [model.blocks[-1].norm1] #最后一个block的norm1-
#---vit最后只对class_token做预测,只用它对结果有贡献,也就只有它有梯度,再将最后预测的结果进行反向传播,后面那几层都只是token自己的MLP,LN只有在多头注意力才将class_token与其余token关联起来
#反向梯度传播是从最后预测开始,经过整个模型。target_layers只是表示记录这些layers的梯度信息而已
data_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# load image
img_path = "both.png"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path).convert('RGB')
img = np.array(img, dtype=np.uint8)
img = center_crop_img(img, 224)
# [C, H, W]
img_tensor = data_transform(img)
# expand batch dimension
# [C, H, W] -> [N, C, H, W]
input_tensor = torch.unsqueeze(img_tensor, dim=0)
cam = GradCAM(model=model,
target_layers=target_layers,
use_cuda=False,
reshape_transform=ReshapeTransform(model))
target_category = 281 # tabby, tabby cat
# target_category = 254 # pug, pug-dog
grayscale_cam = cam(input_tensor=input_tensor, target_category=target_category)
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(img / 255., grayscale_cam, use_rgb=True)
plt.imshow(visualization)
plt.show()
if __name__ == '__main__':
main()