Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method

- 这是南京大学在AAAI 2023发表的一篇AAAI2023 超高清图像暗图增强的工作。提出了一个超高清暗图增强数据集,提供了4K和8K的图片,同时提出了一个可用于暗图增强的transformer网络结构。
- 数据集4K的有5999对训练和2100对测试。
- 提出了一个称为LLFormer的网络结构,使用axis-based self-attention和dual gated mehcanism。
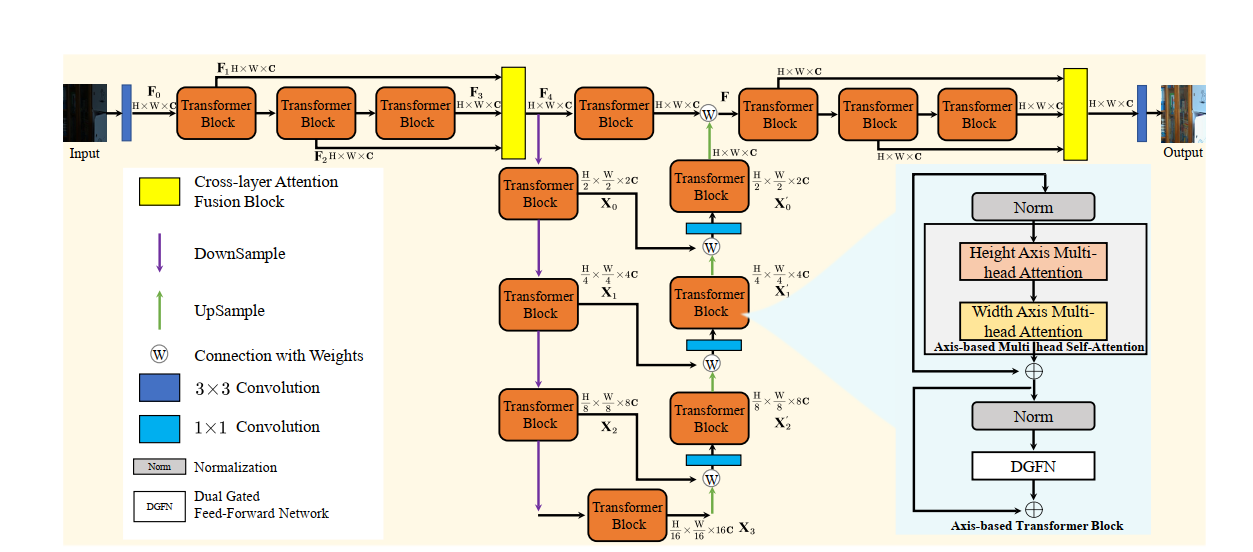
- axis-based transformer block其实就是先对行向量之间做注意力,再对列向量间做注意力,可以把时间复杂度从 W × H W\times H W×H变成 W + H W+H W+H
- dual gated attention block 是如下公式,其中 ϕ \phi ϕ是GELU
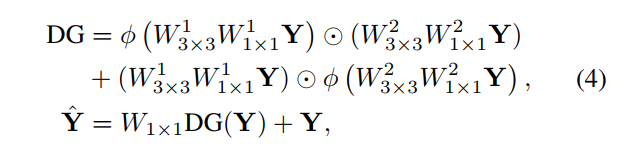
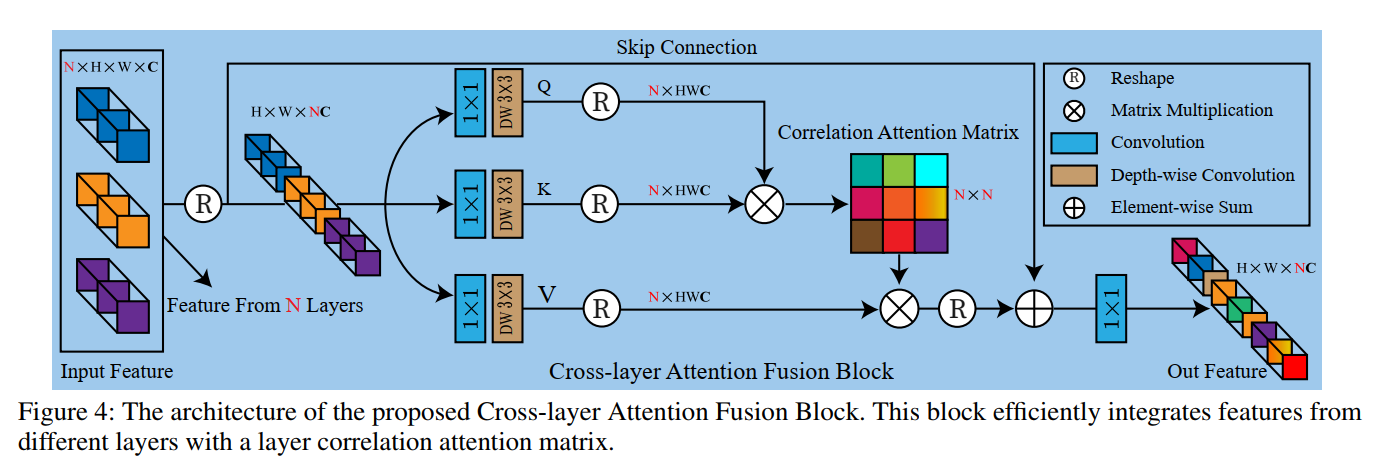
- 而Cross-layer Attention Fusion Block如下:
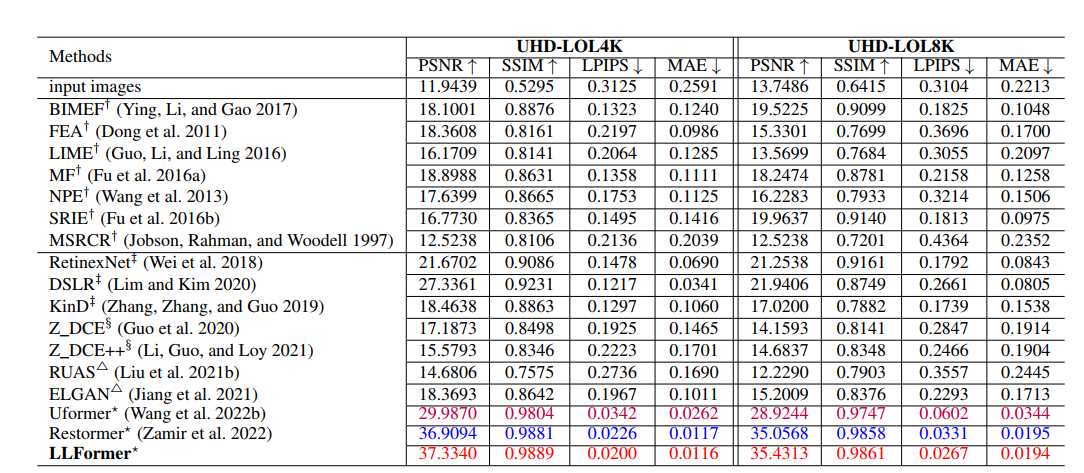
- 在自己数据集上的实验结果:
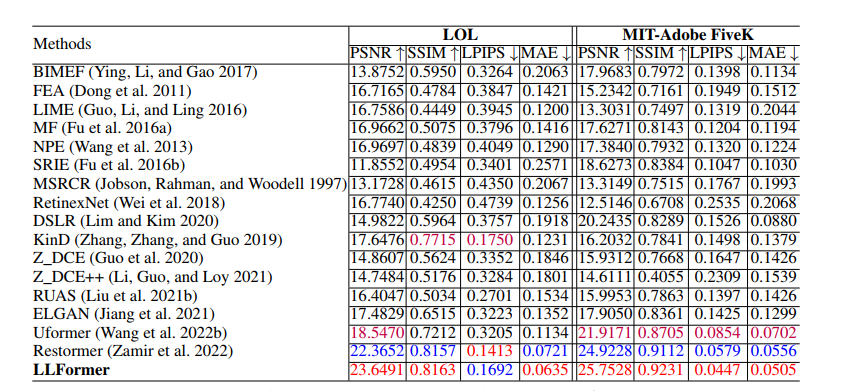
- 在LOL和fivek上的实验结果:
- 新的数据集和benchmark挺好的,新方法就一般,堆网络,也没有针对LLIE做出什么特殊的设计