多数据源典型使用场景
- 业务复杂(数据量大):业务复杂就需要拆分,伴随着的数据库也进行拆分,就涉及到了多个数据库
- 读写分离:为了解决数据库读性能平静(都比写性能更高,写锁会影响读阻塞,从而影响读的性能)
多数据源配置的大体思路
单个数据源的情况下直接getConnection拿到连接就可以了
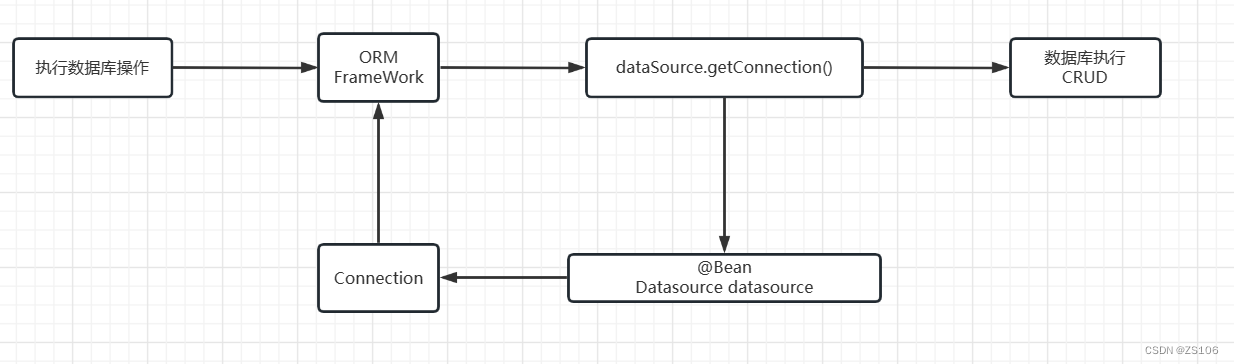
而配置多个数据源的思路就是在拿连接的时候进行一个判断,要拿哪一个数据库的Connection
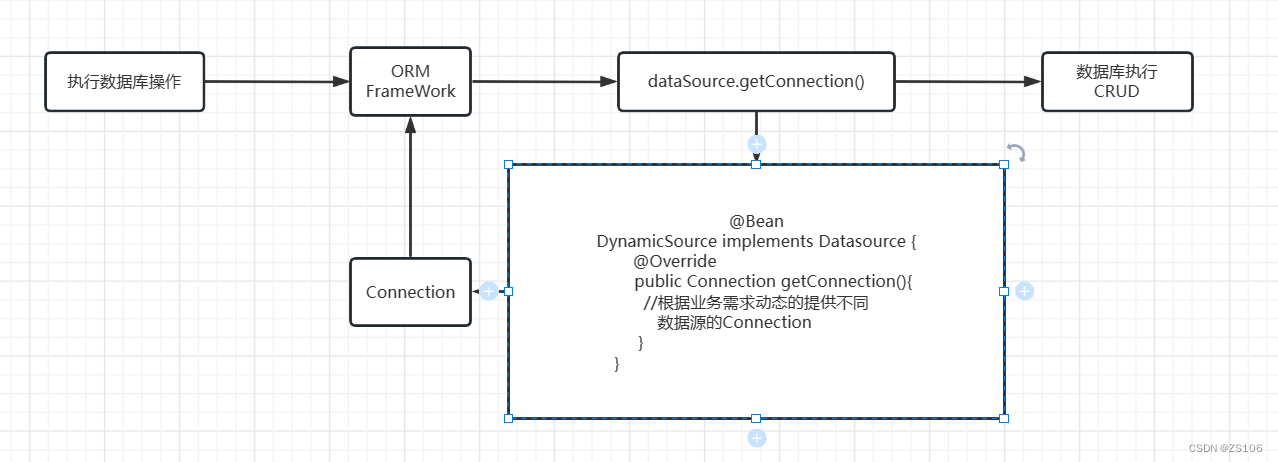
简单实例
主要是为了展示多数据源拿取切换的思路逻辑
- 首先导入依赖(就是正常的springboot,mybatis的依赖),配置yml/properties
spring:
datasource1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/xxx_database1?serverTimezone=Asia/Shanghai
username: xxx
password: xxx
datasource2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/xxx_database2?serverTimezone=Asia/Shanghai
username: xxx
password: xxx
然后向spring里面注册所连数据库的datasource
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.datasource1")
public DataSource dataSource1(){
//底层会自动拿spring.datasource.datasource1的配置,然后创建一个DataSource
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.datasource2")
public DataSource dataSource2(){
return DruidDataSourceBuilder.create().build();
}
}
最后写一个写一个DynamicDataSource ,继承DataSource
重写DataSource要重写很多方法,这里只给出了一个
@Component
@Primary //因为注册了很多DataSource,spring不知道要找哪个dataSource,所以用primary注解告诉服务器,主要进这个DataSource
public class DynamicDataSource implements DataSource {
@Resource
private DataSource dataSource1;
@Resource
private DataSource dataSource2;
@Override
public Connection getConnection() throws SQLException {
/*
这里写判断进入哪个数据库的逻辑,比如说dataSource1是写库,dataSource2是读库
可以在Controller里进行判断是读还是写,然后把他存到ThreadLocal里
然后在这里拿出ThreadLocal的值,做if else判断,从而拿到不同的数据库
*/
if(xxx){
return dataSource1.getConnection();
}else{
return dataSource2.getConnection();
}
}
}
这就是配置多数据源并且拿去数据库的大致思路,不是最终实现
Spring配置访问不同数据库的接口 - AbstractRoutingDataSource()
这个接口的作用就是告诉它我要访问哪个数据库,然后他会从数据库源中选择正确的那个出来,来直接进行访问
大致逻辑为:
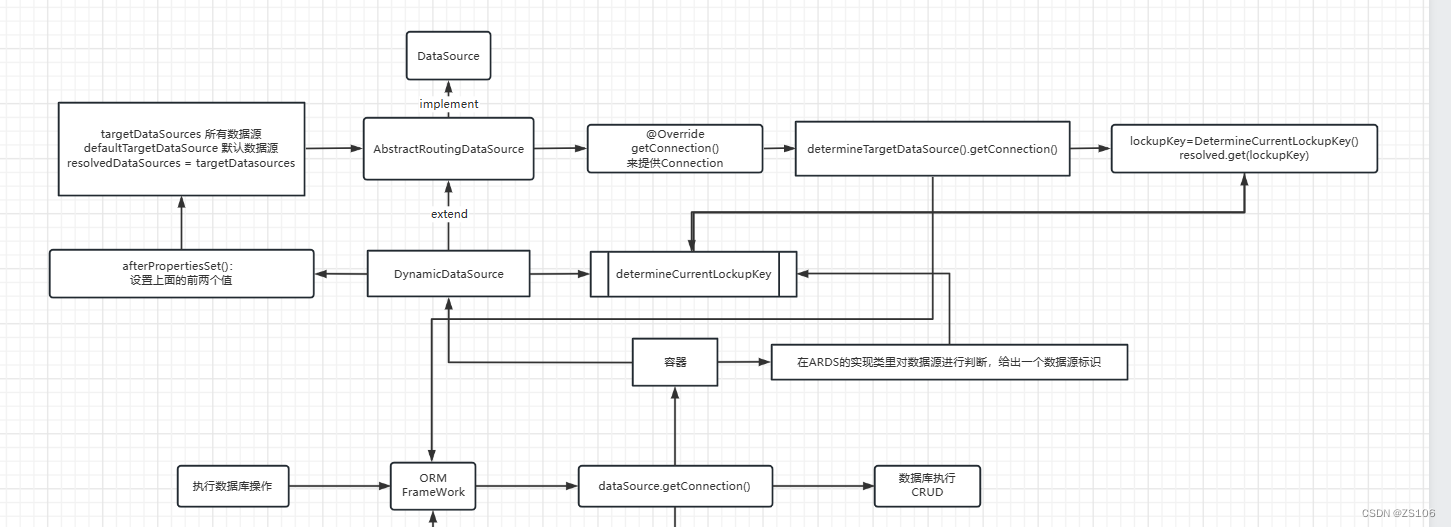
其实和上面咱们字节写的demo逻辑差不多,它在里面配置了所有数据源和默认数据源,然后咱们在调用的时候给出一个对数据源标识,他就会在所有数据源中找到我们需要的datasource,然后getConnection返回给我们进行使用
重写出的之后就是这样:
@Component
@Primary //将该bean设置为主要返回bean
public class DynamicDataSource extends AbstractRoutingDataSource {
public static ThreadLocal<String> name = new ThreadLocal<>();
@Resource
private DataSource dataSource1;
@Resource
private DataSource dataSource2;
/**
* 用于返回当前数据源标识
* @return {@link Object}
*/
@Override
protected Object determineCurrentLookupKey() {
return name.get();
}
/**
* 给
* targetDataSources 所有数据源
* defaultTargetDataSource 默认数据源
* 赋值
*/
@Override
public void afterPropertiesSet() {
//为targetDataSource附上所有数据源
Map<Object,Object> targetDataSources = new HashMap<>();
targetDataSources.put("main",dataSource1);
targetDataSources.put("plus",dataSource2);
super.setTargetDataSources(targetDataSources);
//为defaultDataSource附上默认数据源
super.setDefaultTargetDataSource(dataSource1);
super.afterPropertiesSet();
}
}
这时候我们直接给DynamicDataSource的name赋值就可以了完成对数据库的切换了
@GetMapping("test")
public void test(){
DynamicDataSource.name.set("main");
//数据库操作
}
这就是基于AOP实现的多数据源切换的基本使用方法了!