目录
原理介绍:涉及yolov5 yoloX yolov7 yolov8
五 Yolov5、yolov7、yolov8各自己训练的模型的测试结果对比:
一 Title
原理介绍:涉及yolov5 yoloX yolov7 yolov8
【Yolov5】
预训练权重:Yolov5s.pt(14.1M)
Anchor Base
anchors(3个,对应Neck出来的那3个输出),初始anchor是由w,h宽高组成,用的是原图的像素尺寸,设置为每层3个,所以共有3 * 3 = 9个。
| - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 |
backbone
backone骨干网络的主要作用就是提取特征,并不断缩小特征图。backbone中的主要结构有Conv模块、C3模块、SPPF模块。
特征图进入C3后,将会分为两路,左路经过Conv和一个Bottleneck,右路只经过一个Conv,最后将两路concat,再经过一个Conv。C3中的3个Conv模块均为1*1卷积,起到降维或升维的作用,对于提取特征意义不大。Bottleneck在backbone中使用的是残差连接,Bottleneck中有两个Conv,第一个Conv为1*1卷积,将通道缩减为原来的一半,第二个为3*3卷积,将通道数翻倍。先降维有利于卷积核更好的理解特征信息,升维将有利于提取到更多更详细的特征。最后使用残差结构,将输入与输出相加,避免梯度消失的问题。
SPP是空间金字塔池化:是将三个并行的MaxPool和输入concat到一起,第一个MaxPool的kernel为5*5,第二个为9*9,第三个为13*13。
是将三个kernel为5*5的MaxPool做串行计算。
Neck
Neck结构就实现了浅层图形特征和深层语义特征的融合。
Neck结构其实是一个特征金字塔(FPN),把浅层的图形特征与浅层的语义特征结合在一起。
随着卷积的不断进行,神经网络提取到的特征越来越多,层次也越来越深。在卷积神经网络的浅层,网络提取到的特征也比较简单,例如颜色、轮廓、纹理、形状等,这些特征仅体现在图形上,因而叫做图形特征;而随着网络的不断加深,神经网络会对将这些特征不断融合、升维、产生新的特征,例如颜色与纹理怎么组合,图片中哪里是天空,哪里是陆地,甚至包含一些人类不能理解的特征,这就叫做语义特征。
head
head层为Detect模块,Detect模块的网络结构很简单,仅由三个1*1卷积构成,对应三个检测特征层。
由neck输出的三张特征图,三张特征图其实就是三个网格。第一个网格为80*80,第二个网格为40*40,第三个网格为20*20,通过1*1卷积,三张特征图的大小被改为80*80*3x(5+80),40*40*3x(5+80),20*20*3x(5+80)。3代表了每个网格中蕴含3个anchor,(5+80)代表每个anchor包含的信息。
上述ref: https://zhuanlan.zhihu.com/p/609264977
【Anchor_base && Anchor_base】
Anchor_base
(20*20 + 40*40 + 80*80) = 8400
8400*3 = 25200 由于
25200*(11+5) 每个单元格都有3个描框 11种类别+(x,y,w,h,conf)
Anchor_Free
(20*20 + 40*40 + 80*80) = 8400
400个预测框,所对应锚框的大小,为32*32。
1600个预测框,所对应锚框的大小,为16*16。
6400个预测框,所对应锚框的大小,为8*8。
8400*(11+5)
将YOLO转换为anchor-free形式非常简单,我们将每个位置的预测从3下降为1并直接预测四个值:即两个offset以及高宽。
-----------------------------------------------------
【yoloX】
Anchor_Free方式
基准模型:Yolov3_spp
在选择Yolox的基准模型时,作者考虑到:Yolov4和Yolov5系列,从基于锚框的算法角度来说,可能有一些过度优化,因此最终选择了Yolov3系列。没有直接选择Yolov3系列中标准的Yolov3算法,而是添加了SPP组件的Yolov3_spp版本。
YOLOv3 baseline基线模型采用了DarkNet53骨干+SPP层(即所谓的YOLOv3-SPP)。YOLOX添加了EMA权值更新、cosine学习率机制、IoU损失、IoU感知分支。采用BCE损失训练cls与obj分支,IoU损失训练reg分支。
Mosaic与Mixup两种数据增强。
Yolox的Backbone主干网络,和原本的Yolov3 baseline的主干网络一样。都是采用Darknet53的网络结构。
挑选正样本描框:初步筛选、SimOTA
初步筛选:models/yolo_head.py/get_in_boxes_info
Train
| conda create -n yoloX conda env list conda activate yoloX conda install pip pip3 install -r requirements.txt |
(1)把yolox/data/datasets/coco_classes.py中的标签信息,进行修改。改为
COCO_CLASSES = ( "pedes", "car", "bus", "truck", "bike", "elec", "tricycle", "coni", "warm", "tralight", "special_vehicle",)
(2)修改exps/example/yolox_voc/yolox_voc_s.py中的self.num_classes、depth、width
(3)接着按照自己的需求修改 yolox/exp/yolox_base.py中的self.num_classes、self.defth、self.width、input_size、max_epoch、print_interval、eval_interval等参数
(4)修改exps/example/custom/yolox_s.py
【Yolov7 】
Anchor_Base方式
整体来看下 YOLOV7,首先对输入的图片 resize 为 640x640 大小,输入到 backbone 网络中,然后经 head 层网络输出三层不同 size 大小的 **feature map**,经过 Rep 和 conv输出预测结果,这里以 coco 为例子,输出为 80 个类别,然后每个输出(x ,y, w, h, o) 即坐标位置和前后背景,3 是指的 anchor 数量,因此每一层的输出为 (80+5)x3 = 255再乘上 feature map 的大小就是最终的输出了。
backbone
整体来看下 backbone,经过 4 个 CBS(Conv + BN + SiLU) 后,接入例如一个 ELAN ,然后后面就是三个 MP + ELAN 的输出,对应的就是 C3/C4/C5 的输出,大小分别为 80 * 80 * 512 , 40 * 40 * 1024, 20 * 20 * 1024。 每一个 MP 由 5 层, ELAN 有 8 层, 所以整个 backbone 的层数为 4 + 8 + 13 * 3 = 51 层, 从 0 开始的话,最后一层就是第 50 层。
BN(Batch Normalization)
Silu(x) = x·sigmoid(x)

Neck:

说明:
1 FPN将高层特征与底层特征进行融合,从而同时利用低层特征的高分辨率和高层特征的丰富语义信息,并进行了多尺度特征的独立预测,对小物体的检测效果有明显的提升。
2 SPP(Spatial Pyramid Pooling),即空间金字塔池化。SPP的目的是解决了输入数据大小任意的问题。SPP网络用在YOLOv4中的目的是增加网络的感受野

4 PANet 在UpSample之后又加了DownSample的操作。PANet对不同层次的特征进行疯狂融合,其在FPN模块的基础上增加了自底向上的特征金字塔结构,保留了更多的浅层位置特征,将整体特征提取能力进一步提升。
5 PAN模块的优化: PAN模块在每个Concat层后面引入一个E-ELAN结构,使用expand、shuffle、merge cardinality等策略实现在不破坏原始梯度路径的情况下,提高网络的学习能力。
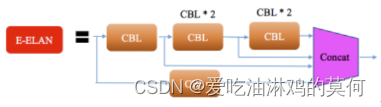
head
head层首先对backbone最后输出的32倍降采样特征图 C5,然后经过 SPPCSP,通道数从1024变为512。先按照 top down 和 C4、C3融合,得到 P3、P4 和 P5;再按 bottom-up 去和 P4、P5 做融合。这里基本和 YOLOV5 是一样的,区别在于将 YOLOV5 中的 CSP 模块换成了 ELAN-H 模块, 同时下采样变为了 MP2 层。
-----------------------------------------------------
【Yolov8】原理
Ref: https://zhuanlan.zhihu.com/p/628313867
Ref: https://zhuanlan.zhihu.com/p/628313867
Anchor_Free方式
和YOLOv5基本一致,都是backbone + PANet + Head的结构,且PANet部分都是先上采样融合再下采样融合;
YOLOv8的Backbone和Neck中采用的C2f结构,其参考了YOLOv7的ELAN的设计思想,用于替换YOLOv5中的CSP结构,由于C2f结构有着更多的残差连接,所以其有着更丰富的梯度流。(不过这个C2f模块中存在Split操作,对特定硬件部署并不友好)
Loss 计算方面采用了TaskAlignedAssigner正样本匹配策略,并引入了Distribution Focal Loss。
① 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
② 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
③ Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
④ Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
⑤ 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本
![]()
①s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
②对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics
对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
① 分类分支依然采用 BCE Loss
② 回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
3 个 Loss 采用一定权重比例加权即可。
二 自己的数据集介绍
表1
| ID |
描述 |
备注 |
| 0 |
行人(骑着平衡车 平板车也划到此类) |
|
| 1 |
轿车(包括SUV、 MPV、 VAN(面包车)、皮卡 ) |
|
| 2 |
大巴车、公交车 |
|
| 3 |
卡车、货车 |
|
| 4 |
自行车 |
|
| 5 |
摩托车(电摩托车) |
|
| 6 |
三轮车(电三轮车、油三轮车) |
|
| 7 |
锥桶 |
|
| 8 |
警示柱、警示标志 |
|
| 9 |
交通信号灯 |
|
| 10 |
紧急或特殊车辆 (救护车 消防车 工程车辆如吊车挖掘机渣土车等) |
|
| 备注 |
三角警示牌、遗撒、低矮等考虑实际并非每个项目都要求,暂不考虑 |
训练平台信息:
| 系统: |
Ubuntu20.04 |
|
| Driver Version: |
525.78.01 |
|
| CUDA Version: |
12.0 |
|
| Cpu |
Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz |
|
数据集数量:
图片分辨率均为1920*1080
数据集划分个数对比:
| 划分类别 |
Train |
val |
test |
备注 |
| 数量 |
9285 |
1985 |
1987 |
比例:9:2:2=7:1.5:1.5 |
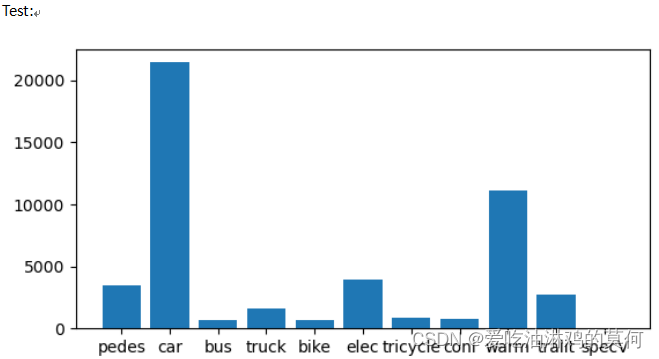
表2 当前数据集中对应目标分类及标签数量
| 作用 |
ID |
clsName |
Number |
| Train |
0 |
pedes |
16281 |
| 1 |
car |
100547 |
|
| 2 |
bus |
3268 |
|
| 3 |
truck |
7810 |
|
| 4 |
bike |
3333 |
|
| 5 |
elec |
18418 |
|
| 6 |
tricycle |
3834 |
|
| 7 |
coni |
3548 |
|
| 8 |
warm |
50835 |
|
| 9 |
tralight |
12982 |
|
| 10 |
specialVehicles |
200 |
|
| Val |
0 |
pedes |
3448 |
| 1 |
car |
21317 |
|
| 2 |
bus |
648 |
|
| 3 |
truck |
1573 |
|
| 4 |
bike |
704 |
|
| 5 |
elec |
3900 |
|
| 6 |
tricycle |
835 |
|
| 7 |
coni |
773 |
|
| 8 |
warm |
10527 |
|
| 9 |
tralight |
2781 |
|
| 10 |
specialVehicles |
44 |
|
| test |
0 |
pedes |
3444 |
| 1 |
car |
21432 |
|
| 2 |
bus |
675 |
|
| 3 |
truck |
1627 |
|
| 4 |
bike |
668 |
|
| 5 |
elec |
3929 |
|
| 6 |
tricycle |
871 |
|
| 7 |
coni |
786 |
|
| 8 |
warm |
11160 |
|
| 9 |
tralight |
2725 |
|
| 10 |
specialVehicles |
41 |
|
表2对应的柱状图如下 便于对比
Train:


三 自己的训练记录
Title
Yolo系列模型训练结果及测试结果对比:
yolov5 yoloX yolov7 yolov8各个yolo系列版本对应小模型训练及测试对比
Yolov5_6.2
预训练模型大小:yolov5s.pt (官方14.1M)


YolovX
Ⅰ 训练准备:模仿VOC格式排布数据集

——datasTrain3_More\images
————Annotations 与图片对应的xml文件
————JPEGImages 数据集图片
————ImageSets 数据集分为训练集和验证集,因此产生的train.txt和val.txt
——————Main
————————Train.txt
————————Val.txt
上述Annotations中的xml文件通过yolov5标注的数据集txt文件对应转换生成。
上述Main/train.txt文件生成的源码见:
Ⅱ 训练准备:修改训练配置参数
Ref: https://zhuanlan.zhihu.com/p/397499216
① yolox/data/datasets/voc_classes.py中的标签信息,修改为VOC_CLASSES = ("pedes","car", "bus", "truck", "bike", "elec", "tricycle", "coni", "warm", "tralight", "specialVehicle",)
② YOLOX_main/exps/example/yolox_voc/yolox_voc_s.py中的self.num_classes, data_dir, image_sets,
③ YOLOX_main/yolox/exp/yolox_base.py中的self.num_classes self.print_interval = 1
self.eval_interval = 1
④ yolox/data/datasets/voc.py中,VOCDection函数中的读取txt文件, 把 year 相关的路径去掉。
⑤ exps/default/yolox_s.py中,相关文件中 self.depth=0.33,self.width=0.50 保持一致。
⑥ tools/train.py中的参数
python3 tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 0 -b 64 -c yolox_s.pth
运行命令:python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 0 -b 32 -c yolox/yolox_s.pth
(一)
预训练权重文件:yolox_tiny.pth (39M)
【因为环境一直没配好,导致没跑起来,尴尬。。。。有优秀的同仁可以指导一下,万分感谢】


(二)
预训练权重文件:yolox_nano.pth (8M)
【因为环境一直没配好,导致没跑起来,尴尬。。。。】
Yolov7_main
预训练权重:Yolov7-tiny.pt(12.1M)

训练时显卡信息:Name: AD102 [GeForce RTX 4090]


yolov8_main
(一)预训练权重:yolov8n.pt(6M)


在yolov8_main/ultralytics路径下 使用命令运行程序
方法一:
yolo cfg=./yolo/cfg/default.yaml
方法二:
yolov8_main2307/ultralytics$yolo task=detect mode=train model=models/v8/yolov8n.yaml data=/home/user/hlj/MyTrain/yolov8_main2307/ultralytics/yolo/v8/detect/data/my_yolov8.yaml imgsz=960 batch=32 epochs=100 workers=2
上述命令参考:https://blog.csdn.net/retainenergy/article/details/129199116

(二)预训练权重:Yolov8s.pt(22M)
运行命令:/yolov8_main/ultralytics$ yolo cfg=./yolo/cfg/default.yaml
预训练权重:Yolov8s.pt(22M)


==================================================================
四 训练结果模型的测试集测试
训练结果模型的测试集测试:1987张1120*1080的jpg。
测试集:
Yolov5_6.2
运行命令: python val.py
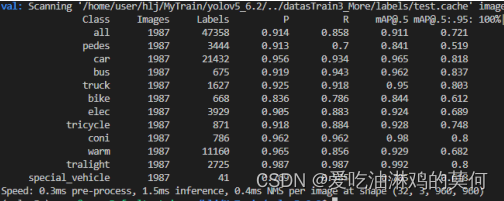
运行命令:python detect.py 生成所有图片的检测结果。
-----------------------------------------------------
Yolov7
验证模式验证模型,需运行命令如下:
python test.py --weights ./runs/train/base_yolov7tiny_pt12m/weights/best.pt --data ./data/my_yolov7.yaml
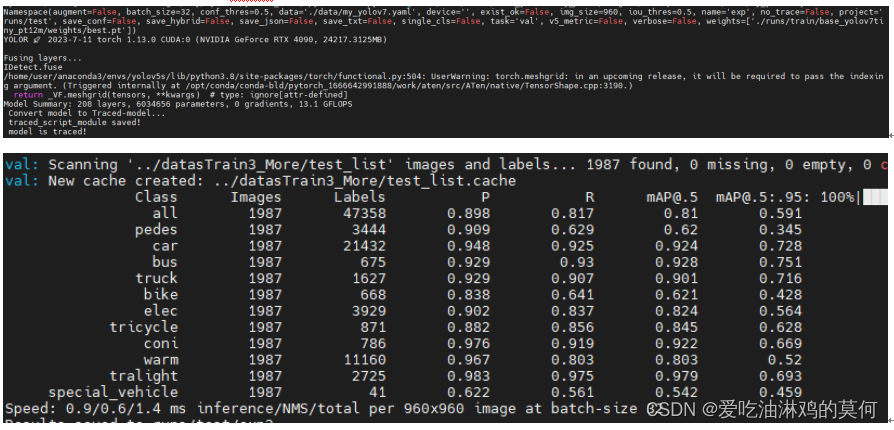
预测测试集图片(1987张),输入命令如下:
python detect.py --weights ./runs/train/base_yolov7tiny_pt12m/weights/best.pt --source /home/user/hlj/MyTrain/YOLOXDatas/test/


Yolov8
(一)base_yolov8n_pt6M
验证模式验证模型,需运行命令如下:
yolo task=detect mode=val model=./runs/detect/base_yolov8n_pt6M/weights/best.pt data=./yolo/v8/detect/data/my_yolov8.yaml batch=32 workers=0
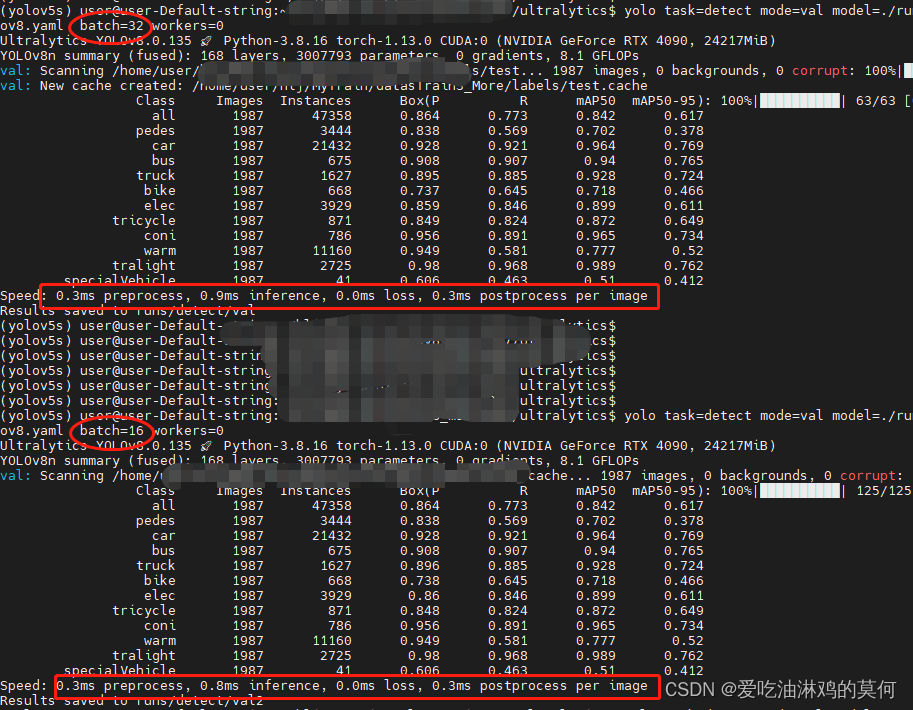
预测测试集图片(1987张),输入命令如下:
yolo task=detect mode=predict model=./runs/detect/base_yolov8n_pt6M/weights/best.pt source=/home/user/hlj/MyTrain/YOLOXDatas/test/ save_crop=True save_conf=True

Predict时的GPU状态


(二)base_yolov8s_pt22M
验证模式验证模型,需运行命令如下:
yolo task=detect mode=val model=./runs/detect/base_yolov8s_pt22M/weights/best.pt data=./yolo/v8/detect/data/my_yolov8.yaml batch=8 workers=0

预测测试集图片(1987张),输入命令如下:
yolo task=detect mode=predict model=./runs/detect/base_yolov8s_pt22M/weights/best.pt source=/home/user/hlj/MyTrain/YOLOXDatas/test/ save_conf = True



五 Yolov5、yolov7、yolov8各自己训练的模型的测试结果对比:
| 模型 |
Yolov5_6.2_s(14M) |
Yolov7_tiny(12M) |
Yolov8_n(6M) |
Yolov8_s(22M) |
备注 |
| val速度 |
0.3ms pre-process, 1.5ms inference, 0.4ms NMS per image at shape (32, 3, 960, 960) =0.3+1.5+0.4=2.2 |
0.9/0.6/1.4 ms inference/NMS/total per 960x960 image at batch-size 32 =0.9+0.6+ |
0.3ms preprocess, 0.8ms inference, 0.0ms loss, 0.3ms postprocess per image 0.3+0.8+0.3=1.4 |
0.3ms preprocess, 2.1ms inference, 0.0ms loss, 0.3ms postprocess per image =0.3+2.1+0.3=2.7 |
每张图片前处理、推理、后处理的平均耗时 |
| P |
0.914 |
0.898 |
0.864 |
0.928 |
|
| R |
0.858 |
0.817 |
0.773 |
0.871 |
|
| mAP50 |
0.911 |
0.81 |
0.842 |
0.925 |
|
| Predict 速度 |
0.4ms pre-process, 6.3ms inference, 0.6ms NMS per image at shape (1, 3, 960, 960) =0.4+6.3+0.6=7.3 |
(17.3ms) Inference, (0.7ms) NMS =18 |
2.0ms preprocess, 7.4ms inference, 0.8ms postprocess per image at shape (1, 3, 544, 960) 2+7.4+0.8 = 10.2 |
2.0ms preprocess, 7.9ms inference, 0.8ms postprocess per image at shape (1, 3, 544, 960) =2+7.9+0.8=10.7 |
细分类对应的P R mAP50对比
| 参数 |
类别 |
模型 |
备注 |
|||
| Yolov5_6.2_s(14M) |
Yolov7_tiny(12M) |
Yolov8_n(6M) |
Yolov8_s(22M) |
|||
| P |
ALL |
0.914 |
0.898 |
0.864 |
0.928 |
|
| pedes |
0.913 |
0.909 |
0.838 |
0.898 |
||
| car |
0.956 |
0.948 |
0.928 |
0.946 |
||
| bus |
0.919 |
0.929 |
0.908 |
0.936 |
||
| truck |
0.925 |
0.929 |
0.896 |
0.919 |
||
| bike |
0.836 |
0.838 |
0.738 |
0.855 |
||
| elec |
0.905 |
0.902 |
0.86 |
0.897 |
||
| tricycle |
0.918 |
0.882 |
0.848 |
0.917 |
||
| coni |
0.962 |
0.976 |
0.956 |
0.984 |
||
| warm |
0.965 |
0.967 |
0.949 |
0.97 |
||
| tralight |
0.987 |
0.983 |
0.98 |
0.986 |
||
| Special_vihicle |
0.769 |
0.622 |
0.606 |
0.9 |
||
| 参数 |
类别 |
模型 |
备注 |
|||
| Yolov5_6.2_s(14M) |
Yolov7_tiny(12M) |
Yolov8_n(6M) |
Yolov8_s(22M) |
|||
| R |
ALL |
0.858 |
0.817 |
0.773 |
0.871 |
|
| pedes |
0.7 |
0.629 |
0.569 |
0.709 |
||
| car |
0.934 |
0.925 |
0.921 |
0.946 |
||
| bus |
0.943 |
0.93 |
0.907 |
0.951 |
||
| truck |
0.918 |
0.907 |
0.885 |
0.928 |
||
| bike |
0.768 |
0.641 |
0.645 |
0.805 |
||
| elec |
0.883 |
0.837 |
0.846 |
0.901 |
||
| tricycle |
0.884 |
0.856 |
0.824 |
0.894 |
||
| coni |
0.962 |
0.919 |
0.891 |
0.927 |
||
| warm |
0.856 |
0.803 |
0.581 |
0.746 |
||
| tralight |
0.987 |
0.975 |
0.968 |
0.988 |
||
| Special_vihicle |
0.585 |
0.561 |
0.463 |
0.78 |
||
| 参数 |
类别 |
模型 |
备注 |
|||
| Yolov5_6.2_s(14M) |
Yolov7_tiny(12M) |
Yolov8_n(6M) |
Yolov8_s(22M) |
|||
| mAP50 |
ALL |
0.911 |
0.81 |
0.842 |
0.925 |
|
| pedes |
0.841 |
0.62 |
0.702 |
0.836 |
||
| car |
0.965 |
0.924 |
0.964 |
0.979 |
||
| bus |
0.962 |
0.928 |
0.94 |
0.967 |
||
| truck |
0.95 |
0.901 |
0.928 |
0.962 |
||
| bike |
0.844 |
0.621 |
0.718 |
0.883 |
||
| elec |
0.924 |
0.824 |
0.899 |
0.941 |
||
| tricycle |
0.928 |
0.845 |
0.872 |
0.931 |
||
| coni |
0.98 |
0.922 |
0.965 |
0.979 |
||
| warm |
0.929 |
0.803 |
0.777 |
0.889 |
||
| tralight |
0.992 |
0.979 |
0.989 |
0.994 |
||
| Special_vihicle |
0.705 |
0.542 |
0.51 |
0.813 |
||