
一、说明
进化算法是一系列搜索算法,其灵感来自自然界(达尔文主义)进化过程。所有不同家庭成员的共同点是,通过应用受自然遗传学和自然选择启发的
- 算子,通过进化出最初
- 随机的候选解决方案群体来解决问题,以便及时出现更合适(即更好)的问题解决方案。
该领域的起源可以追溯到 1950 年代和 1960 年代,在过去的二十年中已经独树一帜,证明成功地解决了来自高度多样化领域的众多问题,包括(仅举几例):优化、自动编程、电子电路设计、电信、网络、金融、经济学、图像分析、信号处理、音乐和艺术。
有趣的是,研究人员——包括我自己——发现进化算法可以以有益的方式与机器学习和深度学习相结合。稍后会详细介绍。
二、遗传算法的结构
以下是基本的进化算法的样子:
- 产生最初的个体群体,后者是手头问题的候选解决方案
- 根据寻求解决方案的问题评估每个人的适合性
- 当终止条件未满足时,选择
更合适的个体进行繁殖
- 重组(交叉)个体 - 突变个体
- 评估修改个体的适应性
让我们盘点一下进化算法的主要成分:
基因组(染色体)。进化算法本质上是基于群体的。群体中的个体被称为基因组或染色体。它可以采用多种形式,包括位串、实值向量、基于字符的编码、计算机程序等。设计适合手头问题的表示对于进化算法的成功至关重要。
健身,或健身功能。总体中候选解决方案质量的度量。正确定义此函数对于进化算法的成功也至关重要。
一代。上面 while 循环的单次迭代。
选择。进化算法选择(通常是概率上)高适应性个体为下一代贡献遗传(嗯,“遗传”)物质的运算符。
交叉。两种主要遗传算子之一,其中两个(或多个)候选溶液(亲本)以某种预定义的方式组合以形成后代。
突变。第二主要遗传算子,其中一种候选溶液被随机改变。
是时候举一个简单的例子了。让我们考虑一个由 4 个个体组成的群体,它们是长度为 10 的位串(基因组)。适应度值等于
位字符串中的 1 个数。当然,在实际应用中,种群规模和基因组长度更大。
在这种情况下,适应度计算非常简单:只需计算一个人的 1 数量。对于现实世界的问题,我们通常必须执行一些繁重的计算来获得适应度值。
初始随机总体可能如下所示(适应度值在括号中):0000011011 (4)、1110111101 (8)、0010000010 (2)、0011010000 (3)。
然后,选择可以选择作为父对:1110111101 (8) 与0011010000 (3),0000011011 (4) 与1110111101 (8)。请注意,有些人比其他人更容易被选中,而有些人可能根本没有——选择是概率性的,这取决于健康状况。适合度越高,被选为父母的概率就越高。
交叉运算符在一对父级之间交换随机块,然后是随机翻转少量位的突变运算符。
一旦我们完成了选择-交叉-突变,我们就有了新一代。在我们的例子中,它可能看起来像这样:1111010000 (5)、0010101101 (5)、0000011011 (4)、1110111111 (9)。是的,有点这个父母,有点那个父母,有点改变,瞧——一个改进的解决方案,健身 9(而以前最好的是 8)。
现在怎么办?只要继续循环几代人——选择-交叉-突变-适应——直到你得到一个足够好的解决方案。甚至可能是最佳的。
三、遗传算法编程。
现在让我们让事情变得更有趣。为什么要发展简单的位串?进化算法中的主要子领域之一称为遗传编程,它专注于使用更复杂的表示。传统上,这些是计算树,但多年来已经提出了许多其他表示。
计算树如下所示:
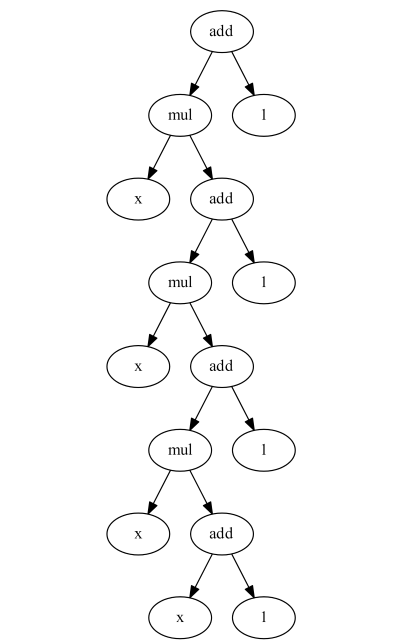
我通过遗传编程进化了这棵树,它实际上计算(递归)等效的数学表达式:x⁴ + x³ + x² + x + 1。有时进化会产生更复杂的树,例如:
四、机器学习和深度学习。
正如我和其他人在过去几年中发现的那样,进化算法的主要优势之一是它们如何“玩”机器学习和深度学习——如果使用得当的话。
例如,在机器学习环境中,我设计了许多基于进化的分类器,它们与XGBoost,LightGBM和深度神经网络竞争。以下是全文。
在深度学习环境中,我们使用了一种所谓的协同进化算法,其中多个种群协同进化,为深度网络进化激活函数。我们没有使用标准的ReLU,sigmoid等,而是将进化的激活函数插入深度网络,并表明它们的性能提高了。以下是全文。
在对抗性深度学习领域,研究人员调查了深度模型对攻击的脆弱性,既试图改进模型防御,又设计新的攻击。输入图像中的微小变化,我们无法检测到,可能会导致网络出错。
在一项工作中,我们使用进化来生成物理上合理的对抗性补丁,这些补丁是高性能的,看起来很逼真——没有使用梯度。我们使用了GAN(生成对抗网络)生成器。给定一个预训练的生成器,我们寻找一个输入潜在向量,对应于生成的图像,这会导致对象检测器出错。我们利用潜在空间的(相对)小维度,使用进化策略算法近似梯度,通过查询目标对象检测器反复更新输入潜在向量,直到发现适当的对抗补丁。
下面见证我才华横溢的研究生拉兹·拉皮德(Raz Lapid)站在他的另一半旁边,展示进化的补丁(打印的,即物理的)如何将他隐藏在深度学习模型(没有边界框)之外。全文在这里。

欢迎您仔细阅读我的网站以获取更多详细信息和完整论文。
开始使用进化算法有多难? 好吧,我会从众多优秀的软件包之一开始。毫不掩饰地,我想推荐我发起的项目 - 以及我出色的合作者和研究生 - EC-KitY:
我们对这个项目有多个目标,因此EC-KitY是:
- 运行进化算法的综合工具包;
- 用蟒蛇编写;
- 可以在有或没有scikit-learn的情况下工作,也就是说,它同时支持sklearn和非sklearn模式;
- 设计时考虑了现代软件工程;
- 旨在支持所有流行的进化算法范式。
您只需 3 行代码即可运行进化算法:
algo = SimpleEvolution(Subpopulation(SymbolicRegressionEvaluator()))algo.evolve()print(f'algo.execute(x=2,y=3,z=4): {algo.execute(x=2, y=3, z=4)
}')EC-KitY也与scikit-learn兼容,如以下代码片段所示:
X, y = make_regression(n_samples=100, n_features=3)terminal_set = create_terminal_set(X)algo = SimpleEvolution(Subpopulation(creators=FullCreator(terminal_set=terminal_set),
evaluator=RegressionEvaluator()))regressor = SKRegressor(algo)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)regressor.fit(X_train, y_train)
print('MAE on test set:', mean_absolute_error(y_test, regressor.predict(X_test)))让我以查尔斯·达尔文(Charles Darwin)的一句名言来结束——《物种起源》的结束语:
这种生命观是宏伟的,它有几种力量,最初被呼吸成几种形式或一种形式;而且,虽然这个星球按照固定的万有引力定律循环,但从如此简单的开始,最美丽和最美妙的形式已经并且正在进化。摩西·西珀博士