1.基本概念(香农熵,信息增益)
2.决策树代码步骤
一.基本概念
1.香农熵(又名信息熵)(Entropy)
一件事情的发生几率越高,它携带的信息熵越低(信息熵为非负数)
香农熵的公式:

其中 U 事件有 n 种可能结果,Pi 为[ 可能结果i ]的发生几率 (i<=n)
例如输入一种数据,判断这个人的性别,即 n = 2,因为性别只有 男 或 女 两种可能结果。
再举一个例子:对一个游戏的活跃用户进行分层,分为很活跃,较活跃,不活跃,用户比例分别为:20%,30%,50%,则以这种方式划分的熵为:
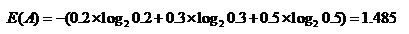
2.信息增益(Information Gain)
某个条件对某个事件的决定因素越大,此条件的信息增益越高。如今天阴天这个条件对今天会否下雨这个事件影响很大,因为阴天就意味着有很大机会下雨,所以阴天的信息增益会比较高。

H为原始数据集信息熵。
T为划分之后的分支集合
p(t)为该分支集合在原本的父集合中出现的概率
H(t)为该子集合的信息熵
某个特征类别X的[信息增益] 为:父数据集的香农熵 减去 各分支集合的香浓熵*该分支在父数据集中的出现的几率 之和
3.决策树作用
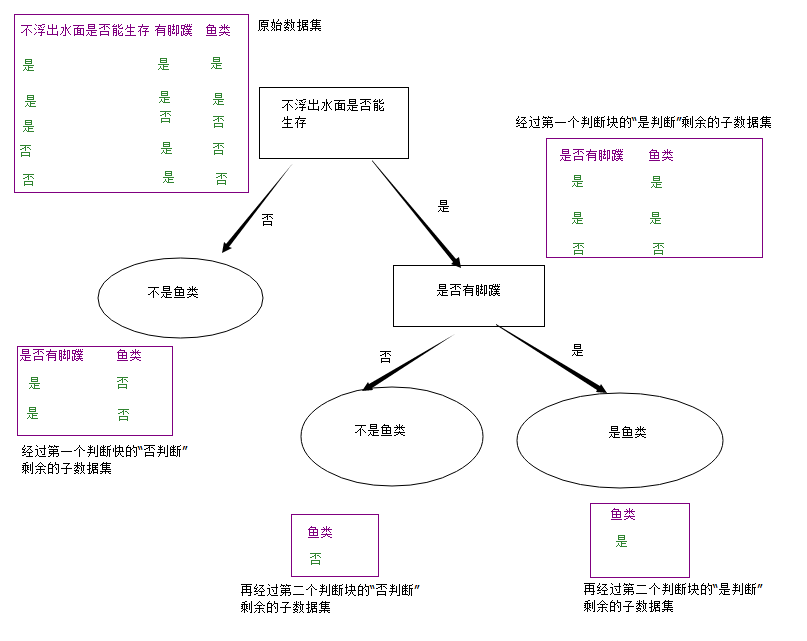
通过调查所得的一个数据集,形成决策树。形成决策树后,决策树可以通过一组新数据来判定这组数据属于哪个范畴
如有:
其中:“不浮出水面是否可以生存” 和 “是否有脚蹼” 为数据集的特征类别。
而“是否属于鱼类” 是 通过 “不浮出水面是否可以生存” 和 “是否有脚蹼” 而判断的得出的[结论]

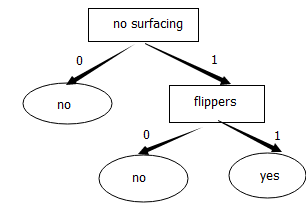
形成决策树后,若输入一组数据,如 [否,否],则可以判断这组数据是否鱼类
形成的决策树:
二.决策树代码步骤
1.构造数据集(当作调查数据)
如有上面一组调查数据,把是写成1,否写成0.,并把[特征类别]用一列表(labels)装载。
def creatDataSet():
labels = ['no surfacing', 'flippers']
dataSet=[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
return dataSet,labels
2.计算信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #计算出数据集有多少组数据
labelCount ={} #用于记录当前数据集最后一列各个取值的出现次数
for featVec in dataSet: #依次取出数据集的每组数据
CurrentLabel = featVec[-1] #获取每组数据最后一列数据(即数据集最后一列的数据)
if CurrentLabel not in labelCount.keys(): #记录最后一列数据各个取值的出现次数
labelCount[CurrentLabel]=0 #若某取值第一次出现,则加入到labelCount中,并设置次数为0
labelCount[CurrentLabel]+=1 #若某取值已经出现过,则次数加1
#计算香农熵
shannonEnt = 0.0 #香农熵初始设置为0
for key in labelCount: #取出数据集最后一列的各个取值
prob = float(labelCount[key])/numEntries #某个取值在数据集中的出现概率
shannonEnt -= prob*log(prob,2) #通过公式计算香农熵
print(shannonEnt)
return shannonEnt
如一数据集为:
[1,1,'YES']
[1,1,'YES']
[1,0,'NO' ]
[0,1,'NO ']
[0,1,'NO ']
取出最后一列数据,并统计最后一列的取值出现次数(YES 和 NO 的出现次数):
labelCount={‘YES’:2,'NO':3}
YES出现的概率 Py = 2/5 = 0.4
NO出现的概率Pn = 3/5 = 0.6
通过公式,香农熵 E = -(0.4*log(0.4,2) + 06*log(0.6,2) )=0.9709505944546686
3. 数据集 按照某个特征类别进行划分 成子数据集
def splitDataSet(dataSet,axis,value): #3个参数分别是[要划分的数据集],[特定特征类别],[特定特征类别的某个取值] retDataSet=[] #要返回的子数据集 for featVec in dataSet: #依此取出要划分数据集的每组数据 if featVec[axis]==value: #若某组数据的[特定特征类别]的取值与 value相等 reduceFeatVec = featVec[:axis] #则该组数据舍弃[特定特征类别] 那一列数据 reduceFeatVec.extend(featVec[axis+1:]) # retDataSet.append(reduceFeatVec) # return retDataSet如要划分的数据集dataSet为:
[1,1,'YES']
[1,1,'YES']
[1,0,'NO' ]
[0,1,'NO ']
[0,1,'NO ']
而 axi参数 为“是否有脚蹼”(即第二列数据),value参数 为 1,则返回的数据集为:[1,'YES']
[1,'YES']
[0,'NO']
[0,'NO']
4.找出最大[信息增益] 的特征类别
作用:找出最大[信息增益] 的特征类别后,可以按照该特征类别来调用[上一步的函数splitDataSet] 来对数据集进行划分
def chooseBestFeatureToSplit(dataSet): numFeature = len(dataSet[0])-1 #得出数据集的[特征类别个数],-1是因为最后一列是数据的结论 baseEntropy = calcShannonEnt(dataSet) #计算当前数据集的信息熵 bestInfoGain = 0 #初始信息增益 设为0 bestFeature = -1 #信息增益最大的 [特征类别] 初始设为 -1 for i in range(numFeature): #遍历各个[特征类别] featList=[number[i] for number in dataSet] #取出序号为i列 的[特征类别]的值 uniqueVals = set(featList) #集合set中的值不能相同 newEntropy = 0 for value in uniqueVals: #依次用序号为i的[特征类别]的值(value)来划分数据集 subDataSet = splitDataSet(dataSet,i,value)#返回{用序号为i的[特征类别] 的取值=value}这条件来划分的子数据集 prob = len(subDataSet)/float(len(dataSet))#{序号为i的[特征类别] 的取值=value}的子数据集的数据占父数据集的比例 newEntropy +=prob*calcShannonEnt(subDataSet)#各个子数据集的[香农熵*子集合在父集合中的出现几率]之和 InfoGain = baseEntropy - newEntropy #序号为i的特征类别的[信息增益] # 为父数据集的香农熵 减去 (以序号为i的特征类别划分的# #各个子数据集的香农熵之和) #最大信息增益 if(InfoGain > bestInfoGain): #选出拥有最大[信息增益]的特征类别 bestInfoGain = InfoGain bestFeature = i return bestFeature #返回拥有最大[信息增益]的特征类别的序号
如要划分的数据集dataSet为:
[1,1,'YES']
[1,1,'YES']
[1,0,'NO' ]
[0,1,'NO ']
[0,1,'NO ']
该数据的特征类别为 “不浮出水面是否能生存”(第一列) 和 “是否有脚蹼”(第二列),下面分别计算两个特征类别的 [信息增益]:dataSet的香农熵 E = -(0.4*log(0.4,2) + 06*log(0.6,2) )=0.9709505944546686
2.把 1 的数据形成一个set集合,名为uniqueVals = ([1,0])
2.1.遍历uniqueVals,取出 1(即value = 1)
2.2.以 dataSet,axi = 0,value = 1 为参数,划分dataSet数据集,返回 subDataSet得 subDataSet = [1,'YES']
[1.'YES']
[0,‘NO’]
2.3计算 axi = 0,value=1,在dataSet 中出现的几率
prop = 3/5 = 0.6
2.4. axi = 0,value = 1 这个子数据集的香农熵 乘 prop1 = N1
2.5.同理,当 value = 0,计算出axi = 0,value=0 这子数据集的香农熵 乘 其prop2 = N2
2.6.最后 axi = 0的[信息增益] 为 E - (N1+N2)
3.同理也可以计算出第二列特征类别(即axi = 1) 的信息增益
4.比较哪个特征类别的信息增益大,信息增益较大的特征类别意味着对 数据判定起的作用越大。(即该特征类别对 ”是否鱼类“这结论 起到的预测作用越强)
5.创建决策树的树形算法
构造决策树时,会对 [类别]进行遍历,(类别=所有特征类别+最后一列的结论),用到递归的方法,停止递归的条件有两个:
1.输入数据集的最后一列类别 的 值完全相同
例如有数据:
[1,1,'YES']
[1,0,'YES']
[0,0,'YES']
其最后一列都是YES,所以可以返回,返回YES
2.遍历完所有类别
例如初始有数据集:

注意:剩下的最后一项,一定是 [结论](即 ”是否鱼类“)
代码:
#计算classList中出现最多的特征类别 def majorityCnt(classList): classCount={} for vote in classList: if vote not in classCount.keys():classCount[vote]=0 classCount[vote]+=1 sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return classCount[0][0] def createTree(dataSet,labels): #传入的数据为 dataSet 数据集 和 特征类别 labels labels_copy = labels[:] #拷贝一份 labels classList=[example[-1] for example in dataSet] #记录dataSet最后一列的数据 #类别完全相同则停止划分 if classList.count(classList[-1]) == len(classList): return classList[-1] #剩余类别个数为1,即遍历完所有类别,返回classList中出现次数最多的结果 if len(dataSet[0]) == 1: return majorityCnt(classList) #按照信息增益最高选取分类特征属性 bestFeat = chooseBestFeatureToSplit(dataSet) #返回[信息增益]最高的特征类别序号 bestFeatLable = labels_copy[bestFeat] #该特征类别 myTree = {bestFeatLable:{}} del(labels_copy[bestFeat]) #用某个特征类别划分数据集后,把这个特征类别从labels中删除 featValues = [example[bestFeat] for example in dataSet] #返回dataSet中bestFeat特征的那一列数据 uniqueVals = set(featValues) for value in uniqueVals: subLables = labels_copy[:] newDataSet = splitDataSet(dataSet,bestFeat,value) #用[信息增益]最高的特征类别来划分数据集 myTree[bestFeatLable][value] = createTree(newDataSet,subLables) #递归创建决策树 return myTree
6.测试代码:
def classify(inputTree,featLables,testVec): #三个参数:决策树,特征类别列表,测试数据 firstStr = list(inputTree.keys())[0] #获取树的第一个判断块(即根节点) secondDict = inputTree[firstStr] #第一个判断块的子树 featIndex = featLables.index(firstStr) for key in secondDict.keys(): #key 是数据里的 是或否 if testVec[featIndex] == key: if type(secondDict[key]).__name__== 'dict': #若还有dict字典变量(即若还有子树) classLable = classify(secondDict[key],featLables,testVec) #递归,从上往下遍历决策树 else:classLable = secondDict[key] return classLable dataSet, labels = creatDataSet() #先获取数据集(实际应用中,可以导入样本数据作为数据集) tree = createTree(dataSet, labels) #形成决策树 print(tree) #打印决策树 ret = classify(tree,labels,[1,1]) #输入新数据 [1,1] ,看它是否“鱼类” print(ret) #打印数据[1,1]的结果,为YES,即是鱼类打印出的决策树为:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
即: