
深度学习自然语言处理 原创
作者:Winnie
前言
Google的最新一项研究提出了OPRO优化方法(Optimization by PROmpting),它利用LLM作为优化器,解决一系列用自然语言描述的任务,包括线性回归、旅行商问题(TSP)问题等。让我们来看看是如何做到的吧!
Paper: Large Language Models as Optimizers
Link: https://arxiv.org/pdf/2309.03409.pdf进NLP群—>加入NLP交流群
概要
最近Google的一项研究提出了OPRO优化方法,它利用LLMs作为优化器。与传统的迭代优化技术不同,OPRO采用自然语言技术描述和指引优化任务,通过LLMs的指导,结合先前找到的解决方案,不断生成更新的策略。
这种方法灵活性很高,可以通过简单改变提示中的问题描述来快速适应不同的任务。初步案例研究显示,在小规模优化问题上,通过提示,LLMs能够找到高质量的解决方案,甚至可以匹配或超越手工设计的启发式算法的性能。
OPRO优化生成的最佳提示在GSM8K上的性能已经超越了传统手工设计提示8%,而在Big-Bench Hard电影推荐任务上,它的程度更是达到了50%的超越。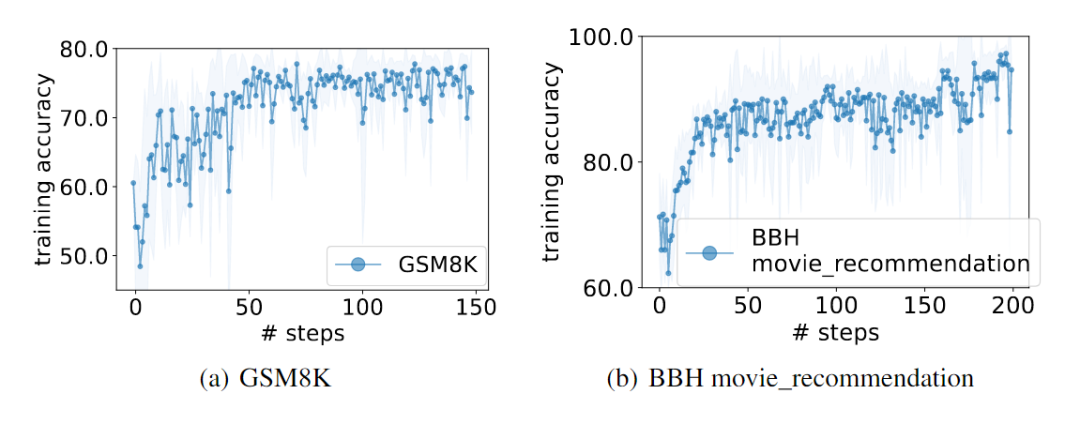 以下是经过OPRO优化后在GSM8K测试集上表现出色的几种zero-shot指令,值得我们在日后的实践中试验。
以下是经过OPRO优化后在GSM8K测试集上表现出色的几种zero-shot指令,值得我们在日后的实践中试验。
OPRO方法
OPRO采用元提示(meta-prompt)作为主要输入,借此驱使LLM为目标任务产出新的解决方案。而一旦这些方案及其得分被生成,它们就会被整合进元提示,为接下来的优化过程提供更为深入的指导。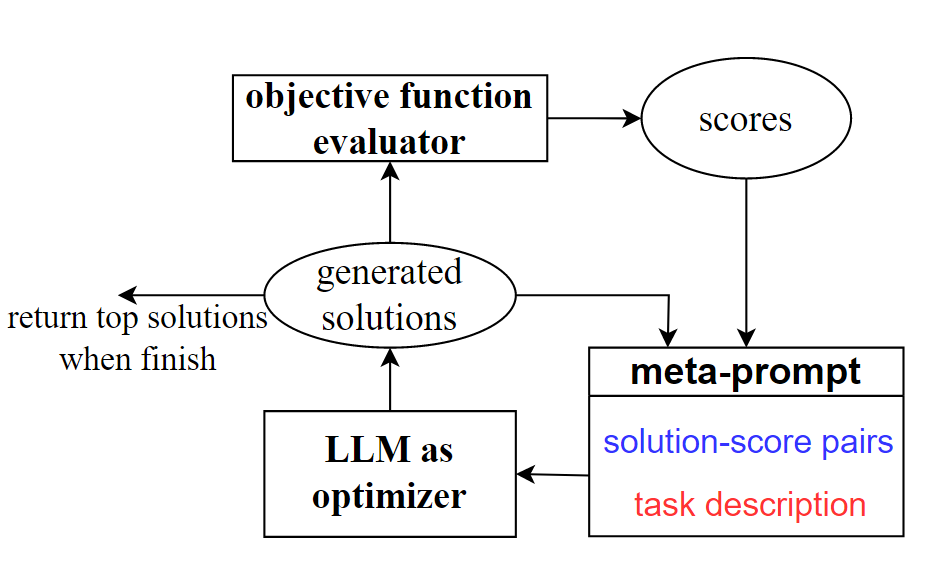
元提示
元提示是OPRO的核心,它在每一步优化过程中都会更新。它不仅优化任务的自然语言描述,还会去优化整个过程中累积的解决方案-得分对。
问题描述:作为元提示的基础部分,它详细描述了优化问题的要求和限制。例如,在提示中,我们可以指导LLM:“请输出一个可以进一步提高准确度的新策略”。这类指示我们称之为元指令。更进一步,我们还可以为LLM提供更为具体的元指令,如“该策略应当简明扼要”。
优化轨迹:LLM能够从所给上下文中鉴别出特定模式,元提示利用了这一特性。具体来说,优化轨迹概括了之前的策略和得分,并按得分进行排序。当将这些路径整合进元提示时,LLM能识别出高效策略的共性,从而在不需要明确指定如何修改策略的前提下,依据现有策略找到更优解。
下图是一个示例:
解决方案的迭代与更新
使用元提示作为输入,LLM继而生成新的解决方案。在这个过程中有两个关键的问题:
稳定性的挑战:在连续的优化过程中,不是所有的回复都会持续提供高分。由于LLM对提示的敏感性,一个低质量的优化轨迹可能会极大地影响其输出,尤其是在策略空间还没有被充分挖掘的初期。因此,为了确保优化过程的稳定性,作者会指导LLM在每一步中提供多种解决方案。
探索与应用的权衡:通过调整LLM的采样温度,确保在探索新策略与利用现有策略之间保持平衡。一个较低的采样温度可以鼓励LLM根据先前的策略进行微调,而较高的温度则鼓励LLM探索和尝试新的策略方向。
案例一:线性回归
在案例研究中,作者将这一方法应用于一维线性回归问题,探索了它如何帮助我们找到最好的线性系数来最好地描述一个数据集。具体地说,当我们面对一维的输入与输出变量(分别表示为X和y),并加入一个截距b,那么需要优化的就是线性系数w和截距b。
作者在一个模拟的环境中为一维变量w和b设定了真实值,并利用生成了50个数据点。优化过程起始于5个随机选取的(w, b)对。每一步中,元提示包括历史上的前20个最佳的(w, b)对及其对应的目标函数值,从而指导LLM生成新的解。
下图展示了一个用于线性回归的元提示的例子。

结果是令人印象深刻的,可以看到OPRO方法能够有效地导航解决方案空间,并在更少的步骤中找到优质解决方案,尤其是使用gpt-4模型时。
案例二:旅行商问题(TSP)
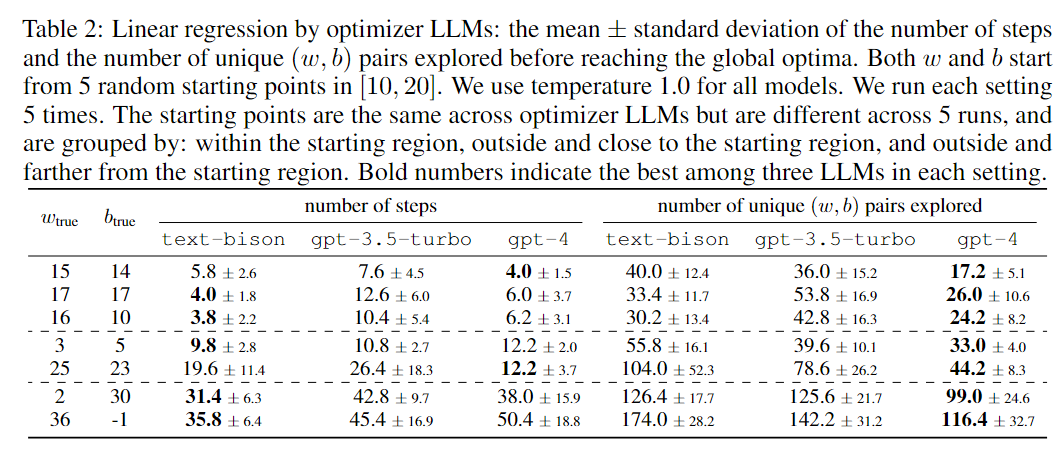
在TSP问题的解决方案中,研究者使用了几个不同的LLMs和启发式算法来发现可能的最短路径。他们还构建了一个标准解决方案来计算所有方法的最优性差距。
下图展示了作者为旅行商问题设计的元提示的示例:

根据实验结果:
GPT-4 的性能突出:它在所有规模的问题中都明显优于其他模型,尤其是在小规模问题上更快地找到全局最优解。
启发式算法表现稳健:即便是基于简单启发式原理的最近邻法和最远插入法也在解决TSP问题上显示了效率,尤其是在处理大规模问题时胜过LLM。
尽管OPRO在证明LLM能够优化不同种类的目标函数方面取得了一些成功,但它还是揭示了一些明显的局限性,包括:
规模限制:随着问题规模的增大,LLM找到最优解的能力显著降低。
描述限制:LLM的上下文窗口长度限制使得将大规模优化问题的描述完全纳入提示中变得困难。
优化环境的挑战:一些目标函数的优化环境太复杂,这使得LLM很难找到正确的下降方向,导致优化过程可能中断。
案例三:Prompt优化
这个任务的优化目标是找到一个最大化任务性能的prompt输入。在这项任务中,LLM有两个作用:一个是作为目标函数评估器来应用优化的提示,另一个是作为优化器LLM。我们将用于目标函数评估的LLM称为评分LLM,将用于优化的LLM称为优化器LLM。优化器LLM的输出是一个指令,该指令将与每个示例的问题部分连接,并提示评分LLM。
作者根据一个特定的任务创建了一个数据集,并将其分为训练和测试两部分。在优化过程中,使用训练集来计算训练精度作为目标值,而在优化结束后,我们会在测试集上计算测试精度。
与传统的优化方法通常需要相当大的训练集不同,实验表明,只需要一小部分训练样本(例如,GSM8K的训练集的3.5%,Big-Bench Hard的20%)就足够了。
OPRO优化生成的最佳提示在GSM8K上的性能已经超越了传统手工设计提示8%,而在Big-Bench Hard电影推荐任务上,它的超越程度更是达到了50%。(在GSM8K上的优化用PaLM 2-L作为评分器,指令调整的PaLM 2-L作为优化器。BBH电影推荐上的优化用text-bison作为评分器,PaLM 2-L-IT 作为优化器)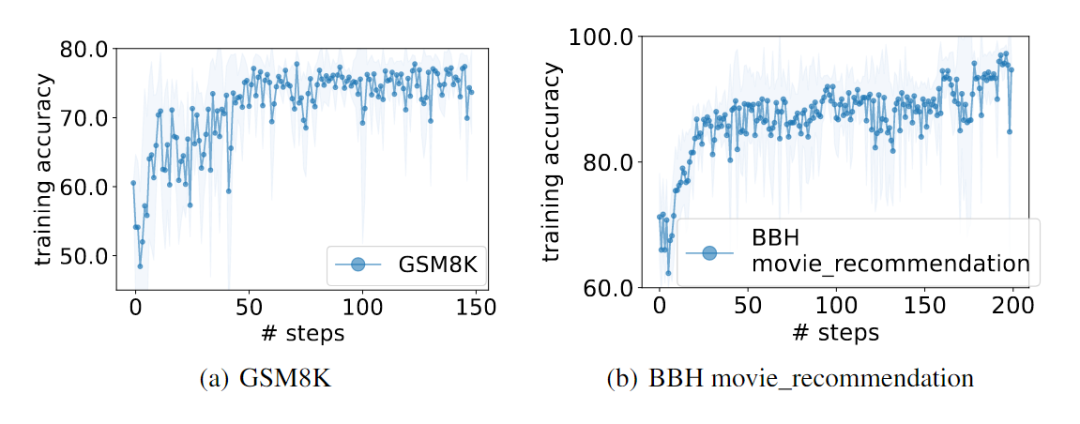 下图展示了在GSM8K上,不同模型的性能,以及取得最高性能的指令。
下图展示了在GSM8K上,不同模型的性能,以及取得最高性能的指令。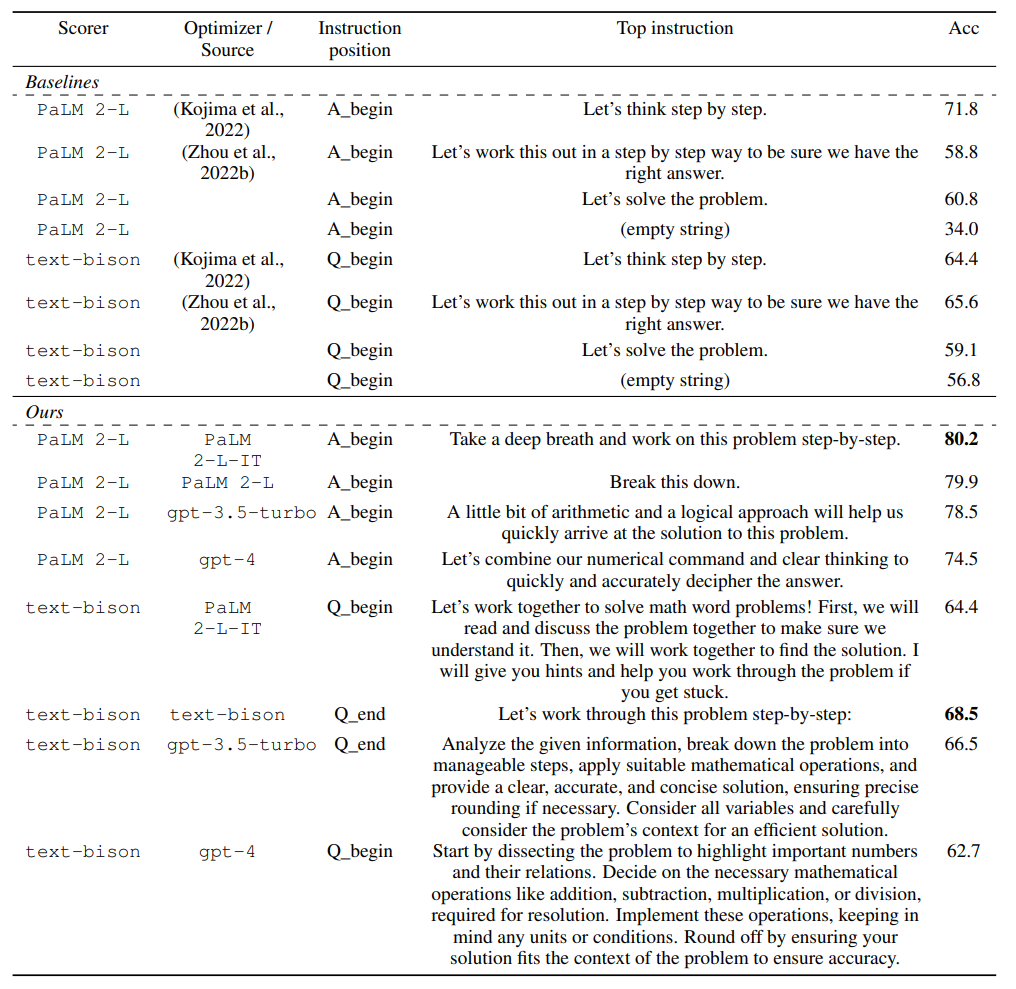
结语
该研究探索了使用LLMs作为优化器的可能性,来逐步生成新的解决方案以优化特定的目标函数。它主要侧重于提示优化,具体到某些任务,这种优化的提示甚至可以比人类设计的提示提高超过50%。
但是这种方法也存在一些局限性。首先,它高度依赖于一个有效的训练集来指导优化过程。而且,目前的LLM优化器还没有很好地利用训练集中的错误样本来改善生成的指令。这是一个亟待解决的问题。
未来的研究可以考虑如何通过更丰富的错误案例反馈和更精细的优化路径来提高LLM的性能。我们可以预见,在不久的将来,这项技术将得到更加完善和优化。
进NLP群—>加入NLP交流群