注:小蚊子团队KEN主讲,共分6章。第一章,python与数据分析概况;第二章,python安装和使用;第三章,数据准备; 第四章 数据处理;第五章 数据分析;第六章,数据可视化
4.1、数据导入
1)、通过文件导入
CSV
语法:read_csv(file,encoding)
from pandas import read_csv
df = read_csv(
'D://dataloop//python_work//DataAnalysis//4.1//1.csv'
)
df
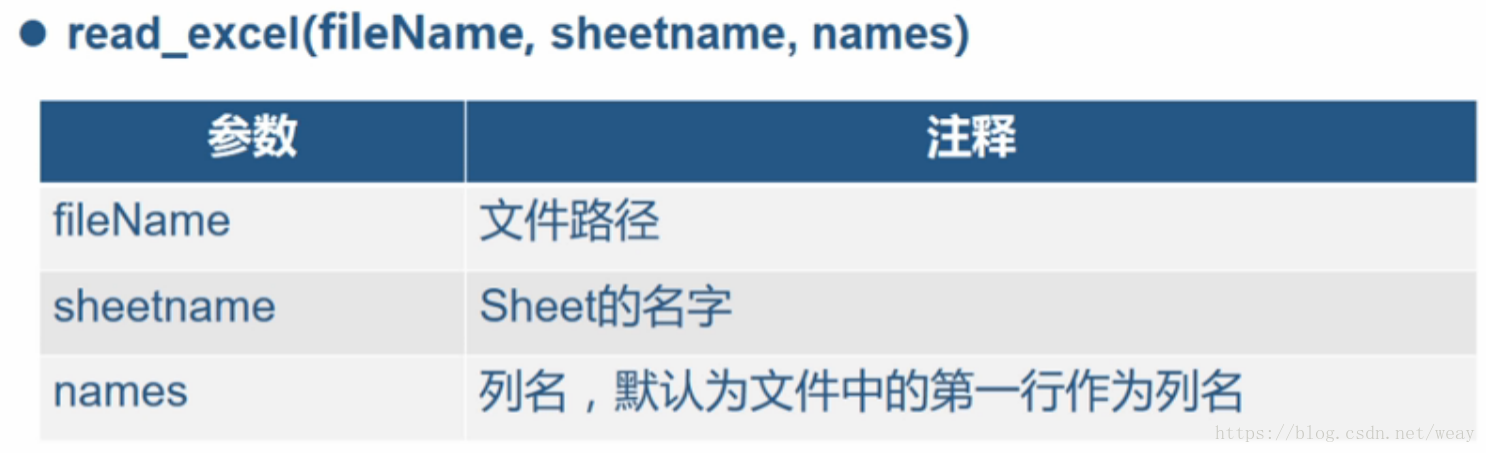
EXCEL语法:read_excel(fileName,sheetname,names)
from pandas import read_excel;
df = read_excel(
'D://dataloop//python_work//DataAnalysis//4.1//3.xlsx',
sheetname='data'
)
TXT语法:read_table(file,names=[列名1,列名2,...],sep="",encoding,...)

from pandas import read_table
df = read_table(
'D://dataloop//python_work//DataAnalysis//4.1//2.txt',
names=['age', 'name'],
sep=','
)
df
中文问题encoding='UTF-8',
engine='python'
df = read_table(
filePath,
sep=',',
encoding='UTF-8',
engine='python'
)
2)、通过数据库导入MySQL
Access
SQL Server
等等
4.2数据导出
导出文本文件
csv
to_csv函数语法:to_csv(filePath,sep=",",index=True,header=Ture)
默认sep=",",index=True,header=Ture
from pandas import DataFrame;
df = DataFrame({
'age': [21, 22, 23],
'name': ['KEN', 'John', 'JIMI']
})
df.to_csv(
"D://dataloop//python_work//DataAnalysis//4.2//df.csv"
)
df.to_csv(
"D://dataloop//python_work//DataAnalysis//4.2//df.csv",
index=False
)
4.3重复值处理把数据结构中,行相同的数据只保留一行
函数语法:drop_duplicates()
from pandas import read_csv
df = read_csv('D://dataloop//python_work//DataAnalysis//4.3//data.csv')
df
#找出行重复的位置
dIndex = df.duplicated()
#根据某些列,找出重复的位置
dIndex = df.duplicated('id')
dIndex = df.duplicated(['id', 'key'])
#根据返回值,把重复数据提取出来
df[dIndex]
#直接删除重复值
#默认根据所有的列,进行删除
newDF = df.drop_duplicates()
#当然也可以指定某一列,进行重复值处理
newDF = df.drop_duplicates('id')
4.4缺失值处理1)、缺失值得产生:
有些信息暂时无法获取
有些信息被遗漏或者错误处理了
2)、缺失值处理方式:
a、数据补齐
如平均值填充
b、删除对应缺失行
避免缺失值对整体数据的影响
数据量较少时谨慎使用
c、不处理
有时候缺失数据是正常的,如单身人士的配偶
3)、缺失值处理函数:
去除数据结构中值为空的数据
函数语法:dropna()
from pandas import read_csv
df = read_csv(
'D://dataloop//python_work//DataAnalysis//4.4//data.csv'
)
df = read_csv(
'D://dataloop//python_work//DataAnalysis//4.4//data2.csv',
na_values=['a','b']
)
#找出空值的位置
isNA = df.isnull()
#获取出空值所在的行
df[isNA.any(axis=1)]
df[isNA[['key']].any(axis=1)]
df[isNA[['key', 'value']].any(axis=1)]
df.fillna('未知')
#直接删除空值
newDF = df.dropna()
4.5空格值处理清除字符型数据左右的空格
语法:strip()
from pandas import read_csv
df = read_csv(
'D://dataloop//python_work//DataAnalysis\\4.5\\data.csv'
)
newName = df['name'].str.lstrip()
newName = df['name'].str.rstrip()
newName = df['name'].str.strip()
df['name'] = newName
4.6字段抽取是根据已知列数据的开始和结束位置,抽取出新的列
函数:slice(start,stop)
from pandas import read_csv
df = read_csv(
'D://dataloop//python_work//DataAnalysis\\4.6\\data.csv'
)
df['tel'] = df['tel'].astype(str)
#运营商
bands = df['tel'].str.slice(0, 3)
#地区
areas = df['tel'].str.slice(3, 7)
#号码段
nums = df['tel'].str.slice(7, 11)
#赋值回去
df['bands'] = bands
df['areas'] = areas
df['nums'] = nums
4.7字段拆分是指按照固定的字段,拆分已有的字符集
分割函数:split(sep,n,expand=False)
sep--用于分割的字符串,n--分割为几列(1为2列,2为3列,...),expand--是否展开为数据框,默认为False
返回值:
如果expand为True,则返回为DataFrame;
如果expand为False,则返回为Series。
from pandas import read_csv
df = read_csv(
'D://dataloop//python_work//DataAnalysis//4.7//data.csv'
)
newDF = df['name'].str.split(' ', 1, True)
newDF.columns = ['band', 'name']
4.8记录抽取是指根据一定的条件,对数据进行抽取
记录抽取函数:dataframe[condition]
condition--过滤的条件
返回值:DataFrame
过滤条件
比较运算:>,<,>=
子主题 2
范围运算:between(left,right)
空值匹配:pandas.isnull(column)
字符匹配:str.contains(patten,na=False)
逻辑运算:与&,或|,取反not
import pandas
df = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\4.8\\data.csv', sep="|"
)
#单条件,返回符合条件的数据框
df[df.comments>10000]
#多条件
df[df.comments.between(1000, 10000)]
#过滤空值所在行
df[pandas.isnull(df.title)]
#根据关键字过滤
df[df.title.str.contains('台电', na=False)]
#~为取反
df[~df.title.str.contains('台电', na=False)]
#组合逻辑条件
df[(df.comments>=1000) & (df.comments<=10000)]
4.9随机抽样是指随机从数据中按照一定的行数或者比例抽取数据
函数:DataFrame.sample(n,frac,replace=False)
n--按个数抽样,frac--按百分比抽样,replace--是否可放回抽样,默认False不可放回
返回值:抽样后的数据框
seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任 何参数都不会被传递,kwargs是一个包含关键字参数的字典。
分层抽样法,也叫类型抽样法。就是将总体单位按其属性特征分成若干类型或层,然后在类型或层中随机抽取样本单位。
# -*- coding: utf-8 -*-
import numpy
import pandas
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\4.9\\data.csv'
)
#设置随机种子
numpy.random.seed(seed=2)
#按照个数抽样
data.sample(n=10)
#按照百分比抽样
data.sample(frac=0.02)
#是否可放回抽样,
#replace=True,可放回,
#replace=False,不可放回
data.sample(n=10, replace=True)
#典型抽样,分层抽样
gbr = data.groupby("class")
gbr.groups
typicalNDict = {
1: 2,
2: 4,
3: 6
}
def typicalSampling(group, typicalNDict):
name = group.name
n = typicalNDict[name]
return group.sample(n=n)
result = data.groupby(
'class', group_keys=False
).apply(typicalSampling, typicalNDict)
typicalFracDict = {
1: 0.2,
2: 0.4,
3: 0.6
}
def typicalSampling(group, typicalFracDict):
name = group.name
frac = typicalFracDict[name]
return group.sample(frac=frac)
result = data.groupby(
'class', group_keys=False
).apply(typicalSampling, typicalFracDict)
4.10记录合并是指将两个结构相同的数据框合并成一个数据框
函数:concat([dataFrame1,dataFrame2,...])
返回值:dataFrame
import pandas
from pandas import read_csv
data1 = read_csv(
'D://dataloop//python_work//DataAnalysis\\4.10\\data1.csv', sep="|"
)
data2 = read_csv(
'D://dataloop//python_work//DataAnalysis\\4.10\\data2.csv', sep="|"
)
data3 = read_csv(
'D://dataloop//python_work//DataAnalysis\\4.10\\data3.csv', sep="|"
)
data = pandas.concat([data1, data2, data3])
data = pandas.concat([
data1[[0, 1]],
data2[[1, 2]],
data3[[0, 2]]
])
4.11字段合并是指将将同一个数据框中的不同列进行合并,形成新的列
方法:x=x1+x2+x3+...
注意:x1位数据列1,必须为字符型
返回值:Series
from pandas import read_csv
df = read_csv(
'D://dataloop//python_work//DataAnalysis\\4.11\\data.csv',
sep=" ",
names=['band', 'area', 'num']
)
df = df.astype(str)
tel = df['band'] + df['area'] + df['num']
df['tel'] = tel
4.12字段匹配根据各表共有的关键字段,把各表所需的记录一一对应起来
函数:merge(x,y,left_on,right_on)
x--第一个数据框,y--第二个数据框
left_on:第一个数据框用于匹配的列
right_on:第二个数据框用于匹配的列
注:left_on和right_on类型要相同
返回值:DataFrame
import pandas
items = pandas.read_csv(
'D:\\PDA\\4.12\\data1.csv',
sep='|',
names=['id', 'comments', 'title']
)
prices = pandas.read_csv(
'D:\\PDA\\4.12\\data2.csv',
sep='|',
names=['id', 'oldPrice', 'nowPrice']
)
#默认只是保留连接上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id'
)
#即使连接不上,也保留左边没连上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id',
how='left'
)
#即使连接不上,也保留右边没连上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id',
how='right'
)
#即使连接不上,也保留所有没连上的部分
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id',
how='outer'
)
4.13简单计算是指通过对已有字段进行加减乘除等运算,得出新的字段
data['total'] = data.price*data.num
import pandas
data = pandas.read_csv(
'D:\\PDA\\4.13\\data.csv',
sep="|"
)
data['total'] = data.price*data.num
#注意,用点的方式,虽然可以访问,但是并没有组合进数据框中
data = pandas.read_csv(
'D:\\PDA\\4.13\\data.csv',
sep="|"
)
data.total = data.price*data.num
4.14数据标准化是指将数据按比例缩放,使之落入到特定区间
消除不同数据间量当的影响
主要用于
综合评价分析
聚类分析
因子分析
主成分分析
0-1标准化公式:X*=(x-min)/(max-min)
import pandas
data = pandas.read_csv(
'D:\\PDA\\4.14\\data.csv'
)
data['scale'] = round(
(
data.score-data.score.min()
)/(
data.score.max()-data.score.min()
)
, 2
)
4.15数组分组是根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间进行研究,以揭示其内在的联系和规律性
函数:cut(series,bins,right=True,labels=NULL)
series--需要分组的数据,bins--分组的划分数组
right--分组的时候,右边是否闭合
labels--分组的自定义标签,可以不自定义
import pandas
data = pandas.read_csv(
'D:\\PDA\\4.15\\data.csv',
sep='|'
)
bins = [
min(data.cost)-1, 20, 40, 60,
80, 100, max(data.cost)+1
]
data['cut'] = pandas.cut(
data.cost,
bins
)
data['cut'] = pandas.cut(
data.cost,
bins,
right=False
)
labels = [
'20以下', '20到40', '40到60',
'60到80', '80到100', '100以上'
]
data['cut'] = pandas.cut(
data.cost, bins,
right=False, labels=labels
)
4.16时间处理1)、时间转换
时间转换,指将字符型的时间格式数据转换成时间型数据的过程
转换函数:datatime=pandas.to_datatime(dataString,format)
%Y--年份,%m--月份,%d--日期,%H--小时,%M--分钟,%S--秒。注意大小写。
data['时间'] = pandas.to_datetime(
data.注册时间,
format='%Y/%m/%d'
)
data['格式化时间'] = data.时间.dt.strftime('%Y-%m-%d')
2)、时间格式化
是指将时间型数据,按照指定格式,转换为字符型数据
函数:dateTimeFormat = datetime.dt.strftime(format)
3)、时间属性抽取
日期抽取,是指从日期格式里面,抽取出需要的部分属性
语法:datatime.dt.property
second--1-60秒,minute--1-60分钟,hour--1-24小时,day--1-31天,month--1-12月,year--年份,weekday--1-7一周中的第几天
data['时间.年'] = data['时间'].dt.year
data['时间.月'] = data['时间'].dt.month
data['时间.周'] = data['时间'].dt.weekday
import pandas
data = pandas.read_csv(
'D:\\PDA\\4.16\\data.csv',
encoding='utf8'
)
data['时间'] = pandas.to_datetime(
data.注册时间,
format='%Y/%m/%d'
)
data['格式化时间'] = data.时间.dt.strftime('%Y-%m-%d')
data['时间.年'] = data['时间'].dt.year
data['时间.月'] = data['时间'].dt.month
data['时间.周'] = data['时间'].dt.weekday
data['时间.日'] = data['时间'].dt.day
data['时间.时'] = data['时间'].dt.hour
data['时间.分'] = data['时间'].dt.minute
data['时间.秒'] = data['时间'].dt.second
4.17时间抽取是指根据一定的条件,对时间格式的数据进行抽取
根据索引进行抽取:
DataFrame.ix[start:end]
DataFrame.ix[dataes]
根据时间列进行抽取:
DataFrame[condition]
# -*- coding: utf-8 -*-
import pandas
data = pandas.read_csv(
'D:\\PDA\\4.17\\data.csv',
encoding='utf8'
)
dateparse = lambda dates: pandas.datetime.strptime(
dates, '%Y%m%d'
)
data = pandas.read_csv(
'D:\\PDA\\4.17\\data.csv',
encoding='utf8',
parse_dates=['date'],
date_parser=dateparse,
index_col='date'
)
#根据索引进行抽取
import datetime
dt1 = datetime.date(year=2016,month=2,day=1);
dt2 = datetime.date(year=2016,month=2,day=5);
data.ix[dt1: dt2]
data.ix[[dt1,dt2]]
#根据时间列进行抽取
data = pandas.read_csv(
'D:\\PDA\\4.17\\data.csv',
encoding='utf8',
parse_dates=['date'],
date_parser=dateparse,
)
data[(data.date>=dt1) & (data.date<=dt2)]
4.18虚拟变量也叫哑变量和离散特征编码,可用来表示分类变量、非数量因素可能产生的影响
1、离散特征的数值之间有大小的意义,如尺寸(L、XL、XXL)
2、离散特征的取值之间没有大小的意义,如颜色
1)、有大小意义的处理函数:pandas.Series.map(dict)
2)、没有大小意义的处理函数:
pandas.get._dummies(data,prefix=None,prefix_sep='_',dummy_na=False,columns=None,drop_first=False)
data--要处理的DataFram
prefix--列名的前缀,在多个列有相同的离散项时使用
prefix_sep--前缀和离散值的分隔符,默认为下划线
dummy_na--是否把NA值作为一个离散值来处理,默认不处理
columns--要处理的列名,如果不指定该列,那么默认处理所有列
drop_first--是否从备选项中删第一个,建模的时候为避免共线性使用
# -*- coding: utf-8 -*-
import pandas
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\4.18\\data.csv',
encoding='utf8'
)
data['Education Level'].drop_duplicates()
"""
博士后 Post-Doc
博士 Doctorate
硕士 Master's Degree
学士 Bachelor's Degree
副学士 Associate's Degree
专业院校 Some College
职业学校 Trade School
高中 High School
小学 Grade School
"""
educationLevelDict = {
'Post-Doc': 9,
'Doctorate': 8,
'Master\'s Degree': 7,
'Bachelor\'s Degree': 6,
'Associate\'s Degree': 5,
'Some College': 4,
'Trade School': 3,
'High School': 2,
'Grade School': 1
}
data['Education Level Map'] = data[
'Education Level'
].map(
educationLevelDict
)
data['Gender'].drop_duplicates()
dummies = pandas.get_dummies(
data,
columns=['Gender'],
prefix=['Gender'],
prefix_sep="_",
dummy_na=False,
drop_first=False
)
dummies['Gender'] = data['Gender']