个人复习用
一、进程的内存布局
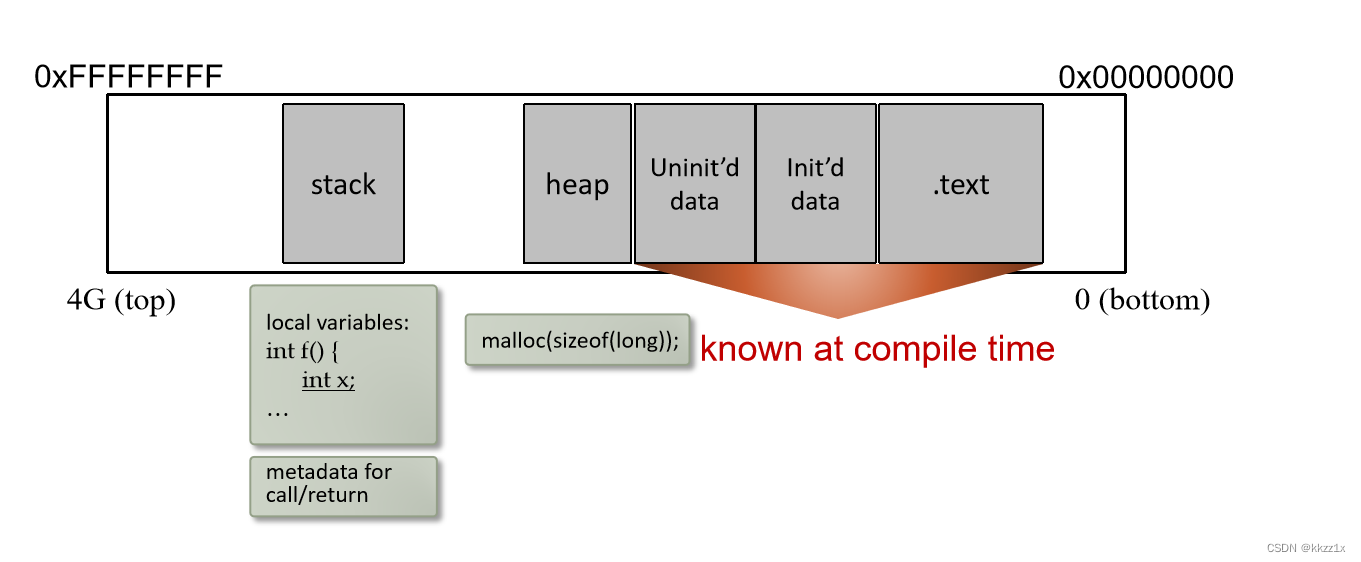
代码段、初始化的变量和未初始化的变量在编译时就已经确定空间。
而栈和堆区则在程序运行时才确定。
堆:从低地址空间到高地址空间增长
栈:从高地址空间到低地址空间增长。
二、栈的工作原理
esp:帧指针,始终指向栈帧顶部
eip:指令执行的地方
ebp:栈基指针,指向当前栈帧的底部。

栈的作用:为函数的调用和执行维护存储结构

EBP存放当前栈的栈基地址,减可以访问当前函数的一些局部变量,加可以访问foo(某)函数局部变量
三、栈溢出
从缓冲区开始
缓冲区是内存的一部分空间,用来缓冲输入输出的数据。目的是提高CPU效率。
很多时候,函数执行中需要局部分配较大的线性内存空间(比如分给数组)

缓冲区应该足够大,且写入数据前应该先检查是否仍有剩余空间可用。但是设计足够大缓冲区的思想是不可取的,不可能无限大。
一旦缓冲区数据超过边界,就会产生缓冲区溢出。

缓冲区溢出,会让比如说EBP这样的信息丢失。


四、栈溢出防护技术
1. 执行保护

2. 栈帧上的“金丝雀”( stack canaries )

执行到了,去检查一次。
3. 影子栈


4. 分离的控制/数据栈
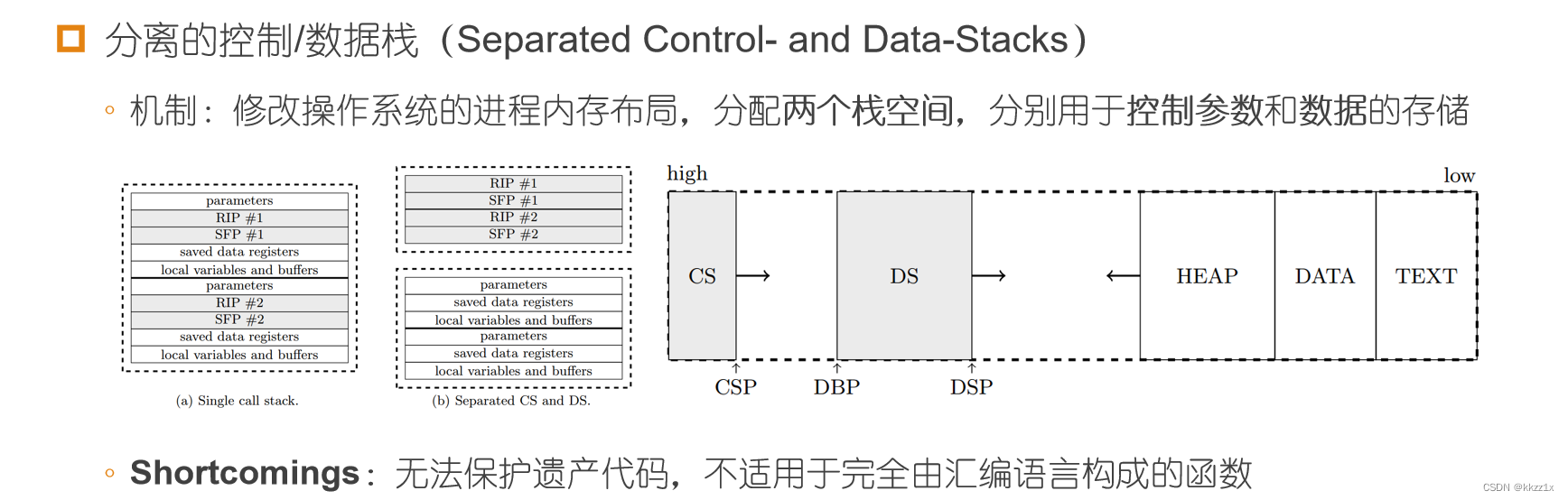
一个栈变两个栈。。分离数据栈和控制栈
5. 内存布局随机化
内存布局随机化就是将程序的加载位置、堆栈位置以及动态链接库的映射位置随机化,这样攻击者就无法知道程序的运行代码和堆栈上变量的地址。以上一节的攻击方法为例,如果程序的堆栈位置是随机的,那么攻击者就无法知道name数组的起始地址,也就无法将main函数的返回地址改写为shellcode中攻击指令的起始地址从而实施他的攻击了。
内存布局随机化需要操作系统和编译器的密切配合,而全局的随机化是非常难实现的。堆栈位置随机化和动态链接库映射位置随机化的实现的代价比较小,Linux系统一般都是默认开启的。而程序加载位置随机化则要求编译器生成的代码被加载到任意位置都可以正常运行,在Linux系统下,会引起较大的性能开销,因此Linux系统下一般的用户程序都是加载到固定位置运行的。
作者:pandolia