文章目录
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
HDFS的Shell操作
进程启停管理
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
-
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群 -
由于前面已经配置环境变量,直接执行以下命令即可
# 使用hadoop用户身份
start-dfs.sh

执行原理:
- 在执行此脚本的机器上,启动SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动NameNode
- 读取workers内容,确认DataNode所在机器,启动全部DataNode
-
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群 -
由于前面已经配置环境变量,直接执行以下命令即可
# 使用hadoop用户身份
stop-dfs.sh
执行原理:
- 在执行此脚本的机器上,关闭SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,关闭NameNode
- 读取workers内容,确认DataNode所在机器,关闭全部NameNode
除了一键启停外,也可以单独控制进程的启停。
扫描二维码关注公众号,回复:
16758172 查看本文章

$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:
hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)

2. $HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:
hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)

HDFS文件系统操作
HDFS文件系统
- HDFS作为分布式存储的文件系统,其对数据的路径表达方式同Linux系统一样,均是以/作为根目录的组织形式
- HDFS和Linux文件系统通过不同的协议头进行区分。
- 在Linux中,文件系统访问通常使用标准的文件系统协议。Linux路径以
file://作为协议头。Linux文件系统的路径以斜杠(/)作为根目录起点。 - 而在HDFS中,文件系统访问使用的是Hadoop的特定协议。HDFS路径以"hdfs://“作为协议头,后面跟着主机名、端口和文件路径,例如"hdfs://namenode:8020/data/file.txt”。
- 在Linux中,文件系统访问通常使用标准的文件系统协议。Linux路径以
- 协议头file:/// 或 hdfs://node1:8020/可以省略
- 需要提供Linux路径的参数,会自动识别为file://
- 需要提供HDFS路径的参数,会自动识别为hdfs://
- 除非你明确需要写或不写会有BUG,否则一般不用写协议头
- 关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系。两者在文件系统操作上,用法完全一致
# 旧版
hadoop fs [generic options]
# 新版
hdfs dfs [generic options]
常用文件操作命令
Hadoop新旧版本的常用文件操作命令的对比表格:
| 命令 | 旧版本(Hadoop 1.x) | 新版本(Hadoop 2.x及更高版本) |
|---|---|---|
| 创建目录 | hadoop fs -mkdir <目录路径> |
hdfs dfs -mkdir <目录路径> |
| 删除目录 | hadoop fs -rm -r <目录路径> |
hdfs dfs -rm -r <目录路径> |
| 列出目录内容 | hadoop fs -ls <目录路径> |
hdfs dfs -ls <目录路径> |
| 上传文件 | hadoop fs -put <本地文件路径> <目标路径> |
hdfs dfs -put <本地文件路径> <目标路径> |
| 下载文件 | hadoop fs -get <HDFS文件路径> <本地路径> |
hdfs dfs -get <HDFS文件路径> <本地路径> |
| 复制文件 | hadoop fs -cp <源文件路径> <目标路径> |
hdfs dfs -cp <源文件路径> <目标路径> |
| 移动文件 | hadoop fs -mv <源文件路径> <目标路径> |
hdfs dfs -mv <源文件路径> <目标路径> |
| 查看文件内容 | hadoop fs -cat <文件路径> |
hdfs dfs -cat <文件路径> |
| 查看文件块信息 | hadoop fsck <文件路径> |
hdfs fsck <文件路径> |
| 修改文件权限 | hadoop fs -chmod <权限> <文件路径> |
hdfs dfs -chmod <权限> <文件路径> |
| 修改文件所有者 | hadoop fs -chown <所有者> <文件路径> |
hdfs dfs -chown <所有者> <文件路径> |
| 修改文件所属组 | hadoop fs -chgrp <组名> <文件路径> |
hdfs dfs -chgrp <组名> <文件路径> |
| 设置文件副本数 | hadoop fs -setrep -w <副本数> <文件路径> |
hdfs dfs -setrep -w <副本数> <文件路径> |
- HDFS并没有提供一个直接的命令来切换工作目录,因为HDFS并不是一个交互式的文件系统,而是一种分布式文件系统,不同于本地文件系统。您只能通过完整的HDFS路径来访问文件和目录
创建文件夹
新版本命令:
hdfs dfs -mkdir <目录路径>
例如
hdfs dfs -mkdir /myfolder
旧版本命令:
hadoop fs -mkdir <目录路径>
例如
hadoop fs -mkdir /myfolder

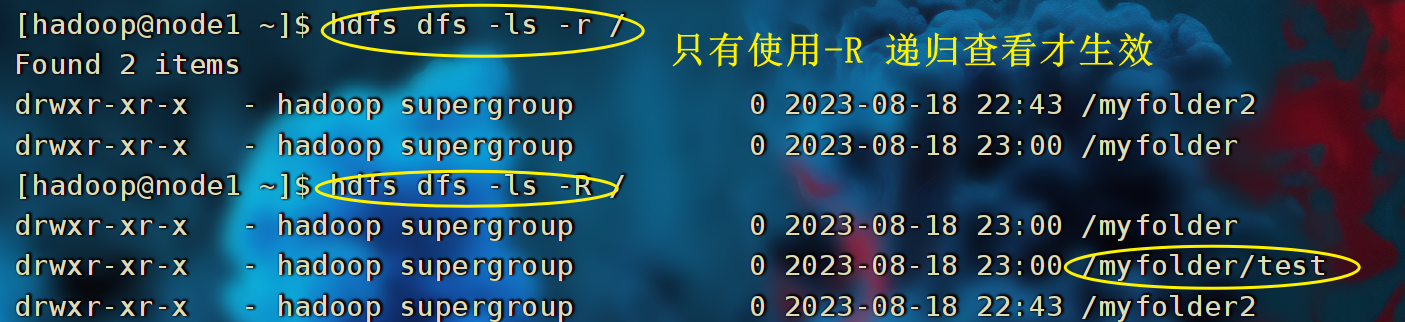
查看指定目录内容
# 旧版命令
hadoop fs -ls [-h] [-R] [<path> ...]
# 新版命令
hdfs dfs -ls [-h] [-R] [<path> ...]
- path 指定目录路径
- -h 人性化显示文件size
- -R 递归查看指定目录及其子目录
上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
-f:覆盖目标文件(已存在)-p:保留访问和修改时间,所有权和权限。localsrc:本地文件系统(客户端所在机器)dst:目标文件系统(HDFS)
查看HDFS文件内容
- 读取指定文件全部内容,显示在标准输出控制台
hadoop fs -cat <src> ... hdfs dfs -cat <src> ... - 读取大文件可以使用管道符配合more
hadoop fs -cat <src> | more hdfs dfs -cat <src> | more
下载HDFS文件
- 下载文件到本地文件系统指定目录,localdst必须是目录
hadoop fs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get [-f] [-p] <src> ... <localdst>
- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限。
拷贝HDFS文件
# -f 覆盖目标文件 顺便可以进行重命名
hadoop fs -cp [-f] <src> ... <dst>
hdfs dfs -cp [-f] <src> ... <dst>
追加数据到HDFS文件中
- 将所有给定本地文件的内容追加到给定dst文件
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>
- dst如果文件不存在,将创建该文件。
- 如果
<localSrc>为-,则输入为从标准输入中读取
HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>
- 移动文件到指定文件夹下
- 可以使用该命令移动数据,重命名文件的名称
HDFS数据删除操作
- 删除指定路径的文件或文件夹
# -skipTrash 跳过回收站,直接删除
hadoop fs -rm -r [-skipTrash] URI [URI ...]
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
- 回收站功能默认关闭,如果要开启需要在
core-site.xml内配置:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
- 无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。
- 回收站默认位置在:
/user/用户名(hadoop)/.Trash
HDFS WEB浏览
- 除了使用命令操作HDFS文件系统外,在HDFS的WEB UI上也可以查看HDFS文件系统的内容

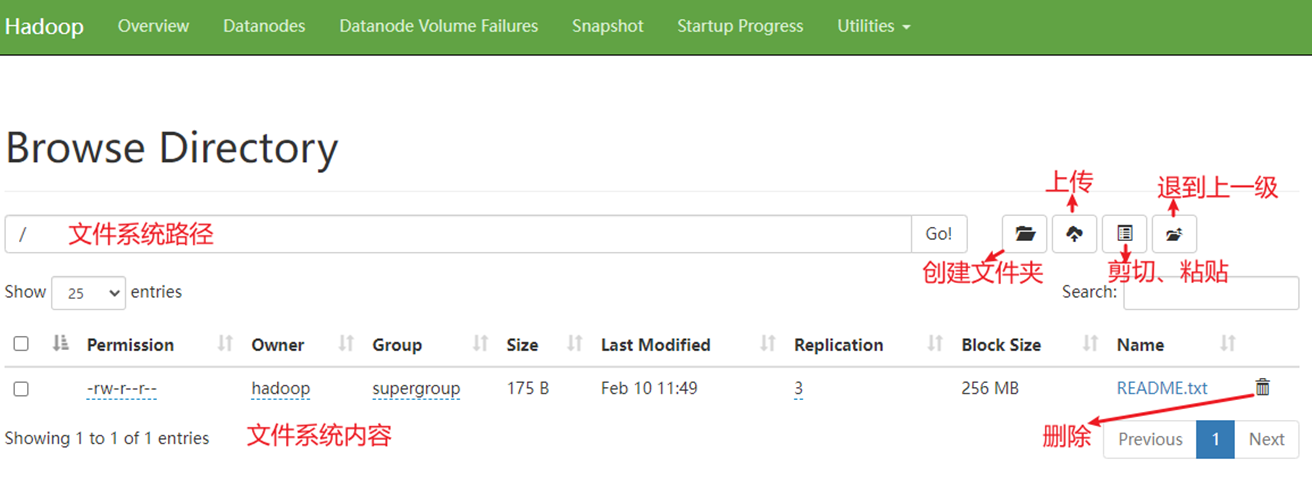
使用WEB浏览操作文件系统,一般会遇到权限问题

- 这是因为WEB浏览器中是以匿名用户(dr.who)登陆的,其只有只读权限,多数操作是做不了的。如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
- 但是,不推荐这样做。如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
HDFS权限
超级用户

- HDFS中,也是有权限控制的,其控制逻辑和Linux文件系统的完全一致。
- 但是不同的是,Superuser不同(超级用户不同).
- Linux的超级用户是root
- HDFS文件系统的超级用户:启动namenode的用户
修改权限
- 在HDFS中,可以使用和Linux一样的授权语句,即: chown和chmod。
- 修改所属用户和组:
hadoop fs -chown [-R] root:root /xxx.txt
hdfs dfs -chown [-R] root:root /xxx.txt
- 修改权限
hadoop fs -chmod [-R]777 /xxx.txt
hdfs dfs -chmod [-R]777 /xxx.txt
HDFS客户端
Big Data Tools插件
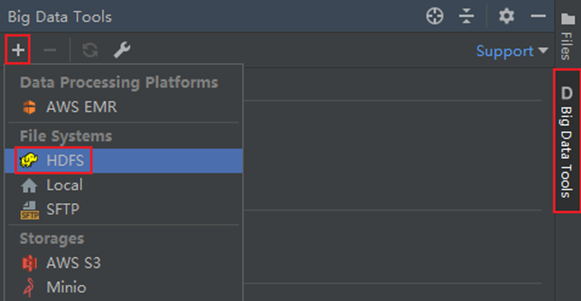
- 在Jetbrains的产品中,均可以安装插件,其中:Big Data Tools插件可以帮助我们方便的操作HDFS,比如:IntelliJ IDEA(Java IDE)、PyCharm(Python IDE)、DataGrip(SQL IDE)均可以支持Bigdata Tool插件。
- 在设置->Plugins(插件)-> Marketplace(市场),搜索Big Data Tools,点击Install安装即可
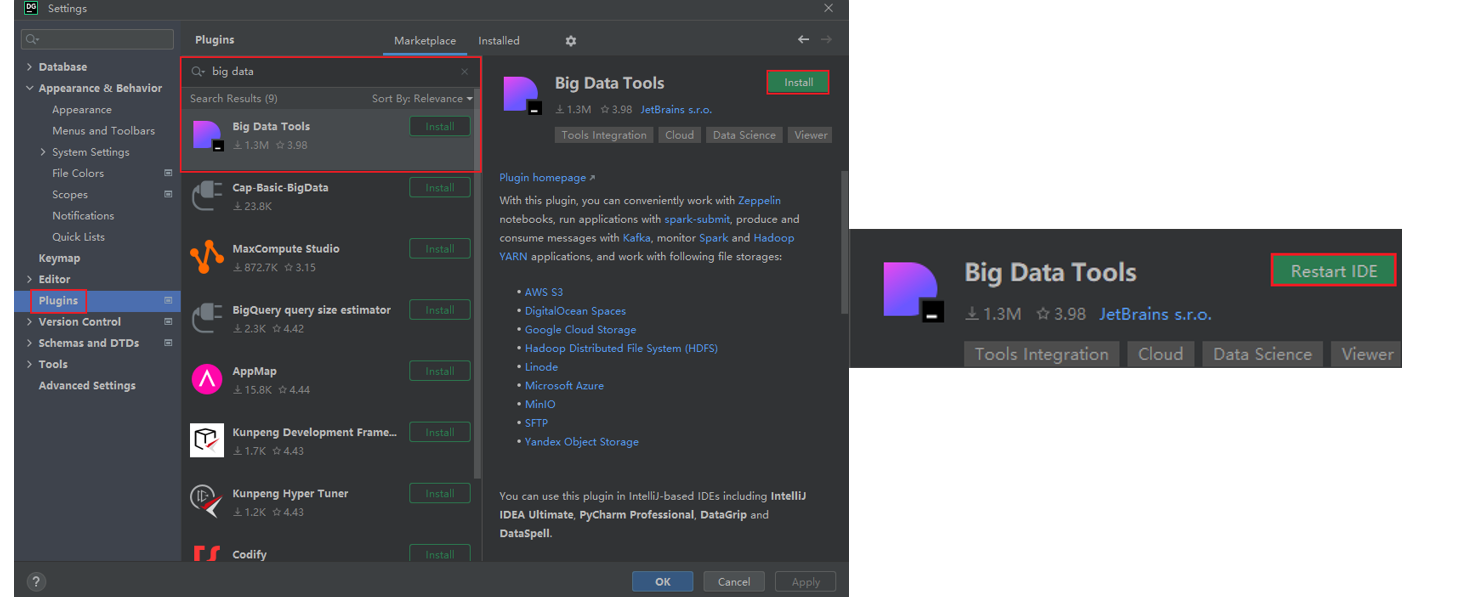
- 插件的使用
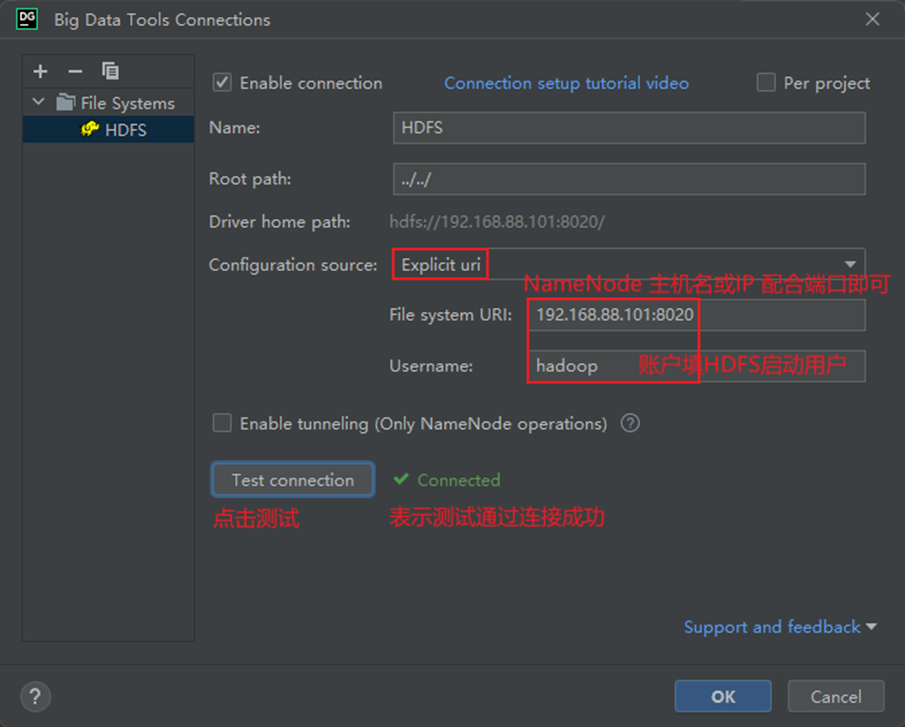
NFS
HDFS NFS Gateway
- HDFS提供了基于NFS(Network File System)的插件,可以对外提供NFS网关,供其它系统挂载使用。
- NFS 网关支持 NFSv3,并允许将 HDFS 作为客户机本地文件系统的一部分挂载,现在支持:上传、下载、删除、追加内容
配置NFS
配置HDFS需要配置如下内容:
- core-site.xml,新增配置项 以及 hdfs-site.xml,新增配置项
- 开启portmap、nfs3两个新进程
在node1进行如下操作
- 在core-site.xml 内新增如下两项
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
-
项目: hadoop.proxyuser.hadoop.groups
-
值:* 允许hadoop用户代理任何其它用户组
-
项目:hadoop.proxyuser.hadoop.hosts
-
值:* 允许代理任意服务器的请求
- 在hdfs-site.xml中新增如下项
<property>
<name>nfs.superuser</name>
<value>hadoop</value>
</property>
<property>
<name>nfs.dump.dir</name>
<value>/tmp/.hdfs-nfs</value>
</property>
<property>
<name>nfs.exports.allowed.hosts</name>
<value>192.168.28.1 rw</value>
</property>
- nfs.suerpser:NFS操作HDFS系统,所使用的超级用户(hdfs的启动用户为超级用户)
- nfs.dump.dir:NFS接收数据上传时使用的临时目录
- nfs.exports.allowed.hosts:NFS允许连接的客户端IP和权限,rw表示读写,IP整体或部分可以以*代替
启动NFS功能
- 将配置好的core-site.xml和hdfs-site.xml分发到node2和node3
- 重启Hadoop HDFS集群(先stop-dfs.sh,后start-dfs.sh)
- 停止系统的NFS相关进程
a.systemctl stop nfs; systemctl disable nfs关闭系统nfs并关闭其开机自启
b.yum remove -y rpcbind卸载系统自带rpcbind - 启动portmap(HDFS自带的rpcbind功能)(必须以root执行):
hdfs --daemon start portmap - 启动nfs(HDFS自带的nfs功能)(必须以hadoop用户执行):
hdfs --daemon start nfs3
检查NFS是否正常
以下操作在node2或node3执行(因为node1卸载了rpcbind,缺少了必要的2个命令)
- 执行:
rpcinfo -p node1有mountd和nfs出现 - 执行:
showmount -e node1
在Windows挂载HDFS文件系统
- 开启Windows的NFS功能
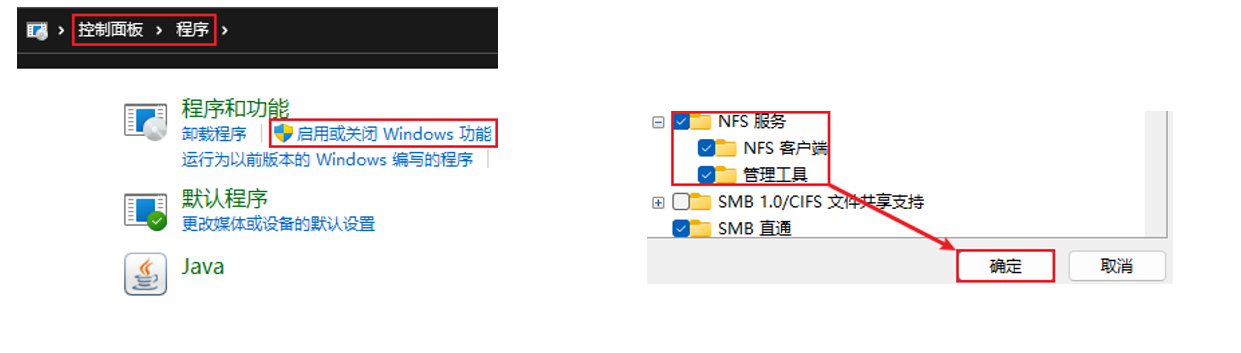
- 在Windows命令提示符(CMD)内输入:
net use X: \\192.168.28.101\! - 完成后即可在文件管理器中看到盘符为X的网络位置
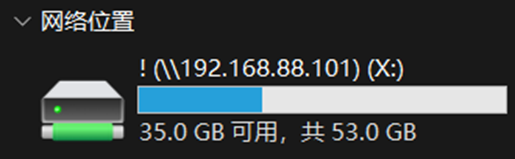
- 点击右键客户断开连接