一、mkv的文件组织
1. EBML基本单元
EBML组成mkv文件最基本的单元, 也是解析文件最小的一个粒度。EBML基本元素结构:
-
ID:标志着这个EMBL 是一个什么类型的,类型决定了后面data中存储的是什么类型的数据如是int,string,utf8,str,nest等。ID在mkv标准的文档中都有定义,其后面跟的数据也都是有标准的。是什么类型的元素取决于ID的值。
-
size:ID标志的data 数据的大小。
-
data:ID标志的数据,可以理解成是一个键值对,键是ID,值是data,data可能是另外一个EMBL单元,也有可能是一个int,string等等。
2. ID\size\data读取规则
ID, size, data是怎么从二进制的数据中读出来的?总体的规则是首先读取二进制获取vint的字节数,根据字节数读取存储的信息。具体vint如何解码 参考下面的文章
这个EBML元素就解析出来了, 这个解码的流程可以不用关注,在ffmpeg中会有标准的解析函数,也可以用embl tree帮忙解析这个层次的数据。
3. LEVEL等级
MKV 整体结构是level0嵌套level1 然后level2 嵌套level3. 这样一级一级下去的。level 0的embl 单元ID 主要有两个EBML Header和Segment。EBML Header由EBMLVersion、DocType等子元素组成,包含了文件的版本、文档类型等相关信息。
Segment部分保存了媒体文件的视频和音频的实际数据,其data部分又可以分为SeekHead、Tracks、Cluster等若干子元素。
具体参考下面的文章
【多媒体封装格式详解】---MKV【1】-mandagod-ChinaUnix博客
4. 解析一个多个level等级嵌套的embl单元 以cue为例
Cueing Data 这部分内容其实是关键帧的index,如果没有关键帧的index的话,在做seek、快进快退的时候是十分困难的。需要逐个包去找。
下面是结构图和对应的embl的id等相关信息。id很重要,只有iD 才能知道这是什么embl。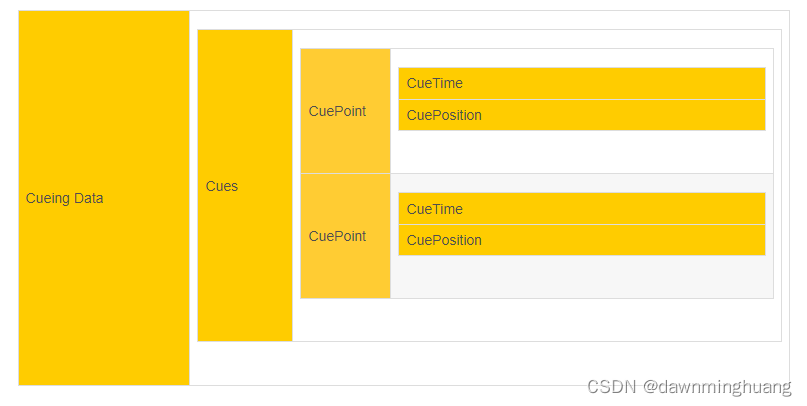
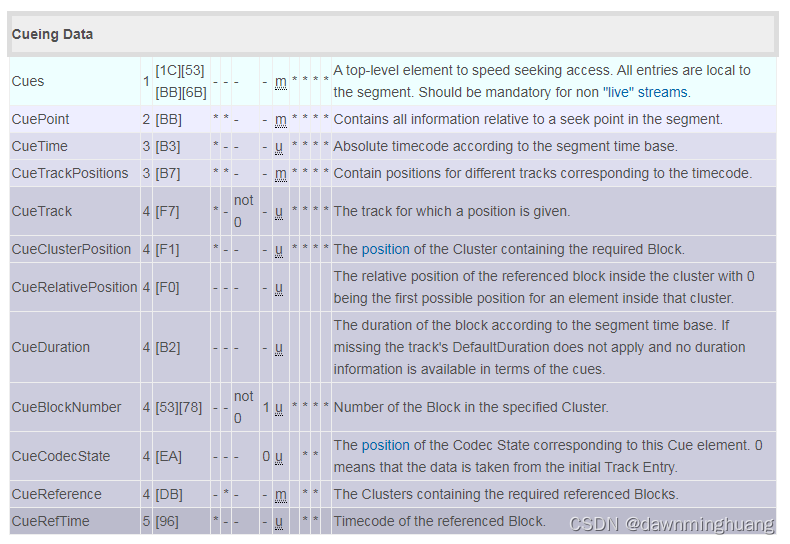
最外部的是level 0的segment,segment 解析到cue。 cue解析到id, 然后整个cue的size 解析出来, 这个size 包括的是cue中所有数据的大小。
cue的数据解析,cue可能包含多个cuepoint,解析到第一个cuepoint。cuepoint又嵌套cuetime。这样一次次嵌套解析到最后。
二、 ffmpeg 相关的解析
1. ffmpeg 读取流程
通过递归解析到方式进行,首先read_seek的时候才会去解析cue的消息, cue的位置通过之前解析segment的信息可以获取到。通过avio_seek跳到文件对应的位置。
cue是level 1的embl,所有的embl id中嵌套的embl id 都通过结构体已经定义好在代码前面了 现在的任务就是解析文件然后将解析出来的数据填充到一个嵌套的结构体中。
- 首先从level1_elems 中找到id 为 MATROSKA_ID_CUES,这边存储在cue数据在文件中的位置然后seek到对应位置。
- 开始解析,传递进去的是segment的结构体数组matroska_segment(这里面存放在的是协议定义的所有可能的segment的类型)、根据之前的规则。解析到ebml的id,从matroska_segment结构体数组中进一步取到cue的结构体matroska_index。通过解析size,知道这个cue数据多大。
- matroska_index 这个结构定义了id 和 所包含的数据是什么类型。 从结构体知道,下一级是一个nest,也就是它是嵌套的,下一级里面没有具体的数据。
- 递归的读,然后它的下一级 是一个matroska_index_entry。然后继续看matroska_index_entry 这个结构体。这一一级一级解析。直到后面不是一个nest,而是一个int string等等。
2. ffmpeg level 层级的抽象
typedef const struct EbmlSyntax {
uint32_t id;
EbmlType type;
int list_elem_size;
int data_offset;
union {
int64_t i;
uint64_t u;
double f;
const char *s;
const struct EbmlSyntax *n;
} def;
} EbmlSyntax;
重要的结构体, 这个结构体是前面level层级的抽象。 mkv的解析流程就是递归的将这个结构体填充完整。 id就是前面所述的embl的id。 type 包含int sting nest 等等。
list_elem_size:这个就表示当前这个embl中存储的数据需要的空间的大小。
比如matroska_index它的list_elem_size 是sizeof(MatroskaIndex)。
typedef struct MatroskaIndex {
uint64_t time;
EbmlList pos;
} MatroskaIndex;
三、 mkv 问题调试分析
1. mkv cue 过多
- 问题分析:首先文件 有40多G。然后seek的cue point很多大概有接近10万个。 在mkv 的parse 里面, 会需要把解析到所有这些cuepoint保存在EbmlList里面。
- 问题原因:EBML list是存储在level 1的list里面。解析到一个cuepoint 申请sizeof(MatroskaIndex)*(list->nb_elem + 1)。 因为原始的是realloc,所以每解析到一个cuepoint就会realloc一次 就会realloc 9万多次。
- 解决方法:使用了fast_realloc, 不会每一次realloc,不够的话 会多申请一些出来。申请的是size + size / 16 + 32。这样realloc会大大减少。解析的时间就少了很多,相当于用空间换时间。同时还需注意 MatroskaIndex的下一级MatroskaIndexPos也会申请内存,申请的大小是 sizeof(MatroskaIndexPos)这个内存是没办法避免。
2、mkv 缺失cue信息
- 问题分析:mkv seek没有找到关键帧
- 问题原因:首先ffmpeg从文件中是如何读到seekcue的位置信息, 首先根据层级的关系,读取0级的ebml, 然后这里面去递归找ebml 1层的数据。找到seekhead 可能就会停止了。 seekhead 里面包含其他ebml元素的位置,通过解析seekhead 的信息 可以seek的track cue等位置。
- 如果在seekhead 这边解析出错的话,比如embl的type是非标准的,那么可能无法解析到cue。也就是level 1的cue 没有存储起来、在后面进行seek的时候就有I帧的准确位置信息,无法快速的定位到相应的I帧位置。而要seek到对应的位置,ffmpeg 就得从当前位置一个个去解析block,解析到keyframe的时候 然后确认是不是要seek的timestape。
3. mkv 问题分析流程
- 首先使用mkv 的工具 ebml tree来看mkv 中各个数据是怎么分布。 然后根据这个分布来看ffmpeg 是怎么解析的。 然后根据解析查找问题。 可以在最新的ffmpeg确认是不是有这个问题。