摘 要: 利用R语言优秀的统计计算和统计制图特点,对多元统计模型进行分析。本文建立的模型主要是讨论上海人均生产总值问题。考虑到上海GDP数据始于1998年,且可供查找的数据截止到2020年,故本文的数据来源于1978-2020年的上海的《统计年鉴》和国家统计局。本文主要从第一产业、第二产业、第三产业和工业四个方面来考虑对于上海人均生产总值的影响。结果发现,第三产业是影响上海人均生产总值的最显著因素。
1 研究背景
人均国内生产总值是人们了解和把握一个国家或地区的宏观经济运行状况的有效工具,也就是人均GDP,常作为发展经济学中衡量经济发展状况的指标,是最重要的宏观经济指标之一,随着第七次人口普查数据的公布,我国各城市人均GDP数据得到进一步完善。其中,上海2021年实现GDP43214.9亿元,实际增速8.1%,常住人口达到2489.43万人,比去年增加1.07万人,实现人均GDP17.36万元(2.72万美元)。本文将基于R语言研究在此之后的上海人均生产总值是的影响因素。
本文的主要内容:
本文在建立回归模型时,先通过R软件利用四个自变量与因变量上海人均生产总值多元线性关系,然后检查多重共线的问题,得到最优回归模型。评价模型的好坏。并按照连续型因变量上海人均生产总值的中位数进行划分,将连续型因变量转化为0-1因变量,小于中位数记为0,大于等于中位数记为1, 可以逻辑回归做5-Fold交又验证分类, 并给出混淆矩阵,以及 TPR,TNR,FPR、FNR和精确度(Accuracy) ,最后给出在经济学或管理学视角给出分类结果的解读。
2 数据来源
本文从研究影响上海人均生产总值的因素入手,鉴于上海在1978年之前出台停止相关数据的整理,故数据始于1978年,且统计年鉴可查的到2020年年鉴,故通过综合国家统计局与市年鉴1978年——2020年的上海人均生产总值相关数据,最后筛选出如下可能上海人均生产总值走势的变量,本文取定四个因素:第一产业;第二产业;第三产业和工业。 因变量人均生产总值(万元)
数据如下表2.1所示:
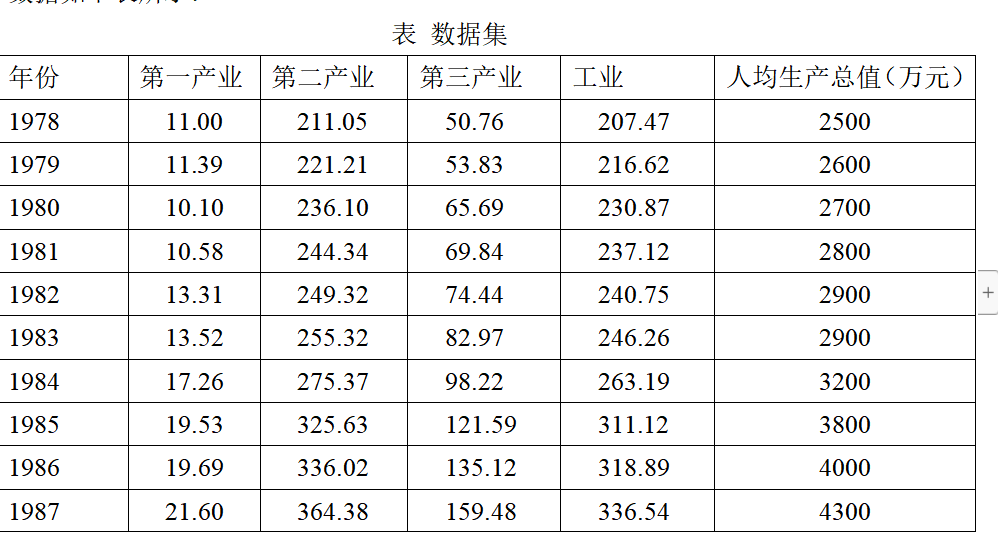
根据搜集的数据,为了更加全面的了解人口增长率的影响因素,选择人均生产总值(万元)为解释变量。选择第一产业 ,第二产业,第三产业,工业指标。鉴于收集到的数据,暂且考虑这些影响因素。根据以上数据,建立上海人均生产总值(万元)的多元线性回归模型。
数据可以在下面网址查询和下载:
http://tjj.sh.gov.cn/tjnj/nj21.htm?d1=2021tjnj/C0301.htm
http://tjj.sh.gov.cn/tjnj/nj21.htm?d1=2021tjnj/C0305.htm
3 描述性分析
3.1统计分析
基于收集到的数据,通过R语言的psych包中的describe进行统计分析,它可以计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误差,如表3.1 所示。

图3.1 统计分析表
基于上表可以得出1978-2020年的上海的人均生产总值平均值是4.57,标准差是4.75,最小值是0.25、最大值15.58等相关信息。
3.2 趋势可视化
基于第一产业 ,第二产业,第三产业,工业指标和人均生产总值都是不同年份的指标,因此可以绘制对应的趋势图来查看近几年的变化趋势。上述指标的变化趋势绘制的图形在表3.2整理而出。
图3.2变量趋势表

从表3.2得出,第一产业 ,第二产业,第三产业,工业指标和人均生产总值的趋势相同
3.3散点图矩阵
基于上面的趋势分析,绘制了相关的散点图矩阵,通过PerformanceAnalytics包中的 chart.Correlation函数就可以绘制出来。
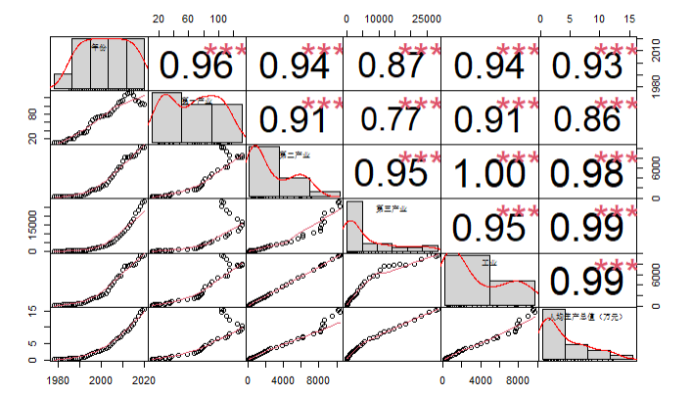
图3.1 散点相关图
通过图3.1,可以分析得出第一产业 ,第二产业,第三产业,工业指标和人均生产总值的相关程度非常的大。
4回归分析
4.1 线性回归
回归通指那些用一个 或多个预测变量(也称自变量或解释变量)来预测响应变量(也称因变量、效标变量或结果变量) 的方法。通常,回归分析可以用来挑选与响应变量相关的解释变量。下图4.1和表4.1是基于多元线性回归模型的结果
表4.1 多元线性回归

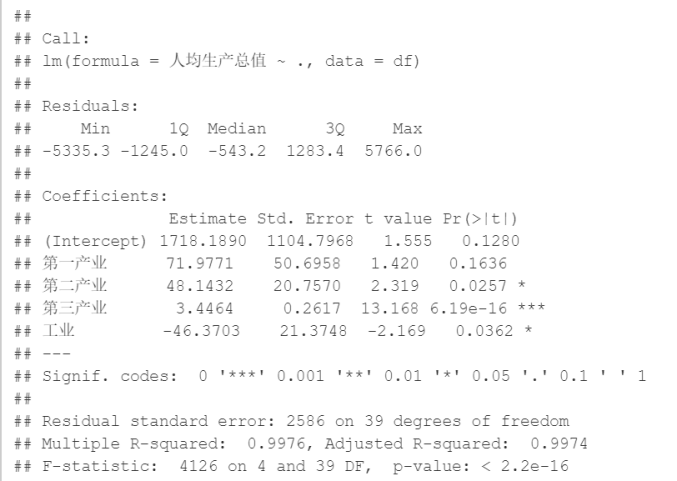
图4.1 线性模型结果
当预测变量不止一个时,回归系数的含义为:一个预测变量增加一个单位,其他预测变量保持不变时,因变量将要增加的数量。例如本例中,第三产业上升1个单位,人均生产总值预计将会增加0.0003471,它的系数系数p是显著不为0(p=7.7e-16)。总体来看,所有的预测变量解释了人均生产总值99.71%的方差。线性模型结果告诉了,显著的因素是第三产业.
4.2多重共线性
首先对模型中自变量的多重共线性进行分析,通过方差膨胀因子(Variance Inflation Factor, VIF)对多重共线性程度进行度量。利用car包的vif()函数实现,一般原则下, vif >4就表明存在多重共线性问题。理想的线性模型其自变量的VIF值非常接近1,当10≤VIF<100,存在较强的多重共线性,当VIF>=100,多重共线性非常严重。图4.2是共线性检验的结果

图4.2共线性检验
由计算结果可以知道,方差膨胀因子远远大于10,可以确定存在明显的多重共线性问题。发现有存在明显共线性,需要将该变量从模型中删除,重新建立新的模型。
因为第二产业主要是工业,因此在第二产业和工业两个变量进行选择
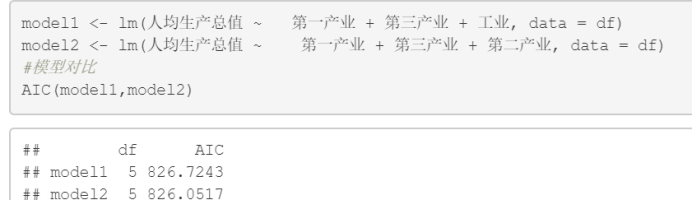
图5.3 模型比较
此处AIC值表明第一产业 + 第三产业 + 第二产业 的模型更佳基于处理多重共线性的模型具体的结果如下图5.4所示。

图5.4 处理多重共线性的模型
基于模型的结果表明了显著的因素是第一产业 , 第三产业 和 第二产业。其中最显著的因素是第三产业。