0X0-1求链式表的表长
本题要求实现一个函数,求链式表的表长。
函数接口定义:
int Length( List L );
其中List结构定义如下:
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode List;
L是给定单链表,函数Length要返回链式表的长度。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
typedef int ElementType;
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode List;
List Read(); /* 细节在此不表 */
int Length( List L );
int main()
{
List L = Read();
printf("%d\n", Length(L));
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
1 3 4 5 2 -1
输出样例:
5
代码实现:
int Length( List L )
{
int n = 0;
if (L==NULL) return 0;
while (L!=NULL)
{
L = L->Next;
n++;
}
return n;
}
0X0-2建立学生信息链表
本题要求实现一个将输入的学生成绩组织成单向链表的简单函数。
函数接口定义:
void input();
该函数利用scanf从输入中获取学生的信息,并将其组织成单向链表。链表节点结构定义如下:
struct stud_node {
int num; /*学号*/
char name[20]; /*姓名*/
int score; /*成绩*/
struct stud_node *next; /*指向下个结点的指针*/
};
单向链表的头尾指针保存在全局变量head和tail中。
输入为若干个学生的信息(学号、姓名、成绩),当输入学号为0时结束。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct stud_node {
int num;
char name[20];
int score;
struct stud_node *next;
};
struct stud_node *head, *tail;
void input();
int main()
{
struct stud_node *p;
head = tail = NULL;
input();
for ( p = head; p != NULL; p = p->next )
printf("%d %s %d\n", p->num, p->name, p->score);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
1 zhang 78
2 wang 80
3 li 75
4 zhao 85
0
输出样例:
1 zhang 78
2 wang 80
3 li 75
4 zhao 85
代码实现:
void input()
{
struct stud_node *q;
q = (struct stud_node *)malloc(sizeof(struct stud_node));
scanf("%d",&q->num);
while (q->num != 0)
{
scanf("%s %d",q->name,&q->score);
if (head == NULL)
{
head = q;
head->next = NULL;
}
if (tail != NULL)
{
tail->next = q;
}
tail = q;
tail->next = NULL;
q = (struct stud_node *)malloc(sizeof(struct stud_node));
scanf("%d",&q->num);
}
}
0X0-3统计专业人数
本题要求实现一个函数,统计学生学号链表中专业为计算机的学生人数。链表结点定义如下:
struct ListNode {
char code[8];
struct ListNode *next;
};
这里学生的学号共7位数字,其中第2、3位是专业编号。计算机专业的编号为02。
函数接口定义:
int countcs( struct ListNode *head );
其中head是用户传入的学生学号链表的头指针;函数countcs统计并返回head链表中专业为计算机的学生人数。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct ListNode {
char code[8];
struct ListNode *next; };
struct ListNode *createlist(); /*裁判实现,细节不表*/ int countcs( struct ListNode *head );
int main() {
struct ListNode *head;
head = createlist();
printf("%d\n", countcs(head));
return 0; }
/* 你的代码将被嵌在这里 */
输入样例:
1021202
2022310
8102134
1030912
3110203
4021205
#
输出样例:
3
代码实现:
int countcs( struct ListNode *head )
{
int num = 0;
while (head)
{
if(head->code[1]=='0'&&head->code[2]=='2')
num++;
head = head->next;
}
return num;
}
0X0-4链表拼接
本题要求实现一个合并两个有序链表的简单函数。链表结点定义如下:
struct ListNode {
int data;
struct ListNode *next;
};
函数接口定义:
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2);
其中list1和list2是用户传入的两个按data升序链接的链表的头指针;函数mergelists将两个链表合并成一个按data升序链接的链表,并返回结果链表的头指针。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
struct ListNode {
int data;
struct ListNode *next;
};
struct ListNode *createlist(); /*裁判实现,细节不表*/
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2);
void printlist( struct ListNode *head )
{
struct ListNode *p = head;
while (p) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
int main()
{
struct ListNode *list1, *list2;
list1 = createlist();
list2 = createlist();
list1 = mergelists(list1, list2);
printlist(list1);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
1 3 5 7 -1
2 4 6 -1
输出样例:
1 2 3 4 5 6 7
代码实现:
struct ListNode *mergelists(struct ListNode *list1, struct ListNode *list2)
{
int num = 0; //把两个链表连接成一个数组再排序
int temp[100];
struct ListNode *p = list1;
while(p != NULL)
{
temp[num] = p->data;
num++;
p = p->next;
}
p = list2;
while(p != NULL)
{
temp[num] = p->data;
num++;
p = p->next;
}
int i,j;
for(i = 0; i < num; i++)
for(j = i + 1; j < num; j++)
{
if(temp[i] > temp[j])
{
int t;
t = temp[i];
temp[i] = temp[j];
temp[j] = t;
}
}
struct ListNode *newlist = NULL;
struct ListNode *endlist = NULL;
struct ListNode *q;
for(i = 0; i < num; i++)
{
q = (struct ListNode *)malloc(sizeof(struct ListNode));
q->data = temp[i];
if(newlist == NULL)
{
newlist = q;
newlist->next = NULL;
}
if(endlist != NULL)
{
endlist->next = q;
}
endlist = q;
endlist->next = NULL;
}
return newlist;
}
0X0-5 顺序表基本操作
本题要求实现顺序表元素的增、删、查找以及顺序表输出共4个基本操作函数。L是一个顺序表,函数Status ListInsert_Sq(SqList &L, int pos, ElemType e)是在顺序表的pos位置插入一个元素e(pos应该从1开始),函数Status ListDelete_Sq(SqList &L, int pos, ElemType &e)是删除顺序表的pos位置的元素并用引用型参数e带回(pos应该从1开始),函数int ListLocate_Sq(SqList L, ElemType e)是查询元素e在顺序表的位次并返回(如有多个取第一个位置,返回的是位次,从1开始,不存在则返回0),函数void ListPrint_Sq(SqList L)是输出顺序表元素。实现时需考虑表满扩容的问题。
函数接口定义:
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
其中 L 是顺序表。 pos 是位置; e 代表元素。当插入与删除操作中的pos参数非法时,函数返回ERROR,否则返回OK。
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
//结构初始化与销毁操作
Status InitList_Sq(SqList &L){
//初始化L为一个空的有序顺序表
L.elem=(ElemType *)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem)exit(OVERFLOW);
L.listsize=LIST_INIT_SIZE;
L.length=0;
return OK;
}
int main() {
SqList L;
if(InitList_Sq(L)!= OK) {
printf("InitList_Sq: 初始化失败!!!\n");
return -1;
}
for(int i = 1; i <= 10; ++ i)
ListInsert_Sq(L, i, i);
int operationNumber; //操作次数
scanf("%d", &operationNumber);
while(operationNumber != 0) {
int operationType; //操作种类
scanf("%d", & operationType);
if(operationType == 1) { //增加操作
int pos, elem;
scanf("%d%d", &pos, &elem);
ListInsert_Sq(L, pos, elem);
} else if(operationType == 2) { //删除操作
int pos; ElemType elem;
scanf("%d", &pos);
ListDelete_Sq(L, pos, elem);
printf("%d\n", elem);
} else if(operationType == 3) { //查找定位操作
ElemType elem;
scanf("%d", &elem);
int pos = ListLocate_Sq(L, elem);
if(pos >= 1 && pos <= L.length)
printf("%d\n", pos);
else
printf("NOT FIND!\n");
} else if(operationType == 4) { //输出操作
ListPrint_Sq(L);
}
operationNumber--;
}
return 0;
}
/* 请在这里填写答案 */
输入格式: 第一行输入一个整数operationNumber,表示操作数,接下来operationNumber行,每行表示一个操作信息(含“操作种类编号 操作内容”)。 编号为1表示插入操作,后面两个参数表示插入的位置和插入的元素值 编号为2表示删除操作,后面一个参数表示删除的位置 编号为3表示查找操作,后面一个参数表示查找的值 编号为4表示顺序表输出操作 输出格式: 对于操作2,输出删除的元素的值 对于操作3,输出该元素的位置,如果不存在该元素,输出“NOT FOUND”; 对于操作4,顺序输出整个顺序表的元素,两个元素之间用空格隔开,最后一个元素后面没有空格。
输入样例:
4
1 1 11
2 2
3 3
4
输出样例:
1
3
11 2 3 4 5 6 7 8 9 10
代码实现:
//pos位置之后的元素都往后挪一位,给pos让位
//注意:存储可能不够
Status ListInsert_Sq(SqList &L, int pos, ElemType e)
{
if(L.length + 1 < pos || pos<1)
return OVERFLOW;
else
{
if(L.length >= L.listsize)
{
ElemType* newelem;
newelem = (ElemType *)realloc(L.elem,(L.listsize+LISTINCREMENT) * sizeof(ElemType));
if(!newelem)
return ERROR;
L.elem = newelem;
L.listsize += LISTINCREMENT;
}
ElemType *temp, *p;
temp = &(L.elem[pos-1]);
for(p = &(L.elem[L.length-1]); p >= temp; p--)
*(p+1) = *p;
*temp = e;
L.length = L.length + 1;
return OK;
}
}
//将pos位置的元素赋值给e,然后后边的一次覆盖前边的元素
//注意:pos可能不合法
Status ListDelete_Sq(SqList &L, int pos, ElemType &e)
{
if(L.length < pos || pos<1)
return OVERFLOW;
else
{
e = L.elem[pos-1];
ElemType* temp;
for(temp = &(L.elem[pos-1]); temp <= &(L.elem[L.length-1]); temp++)
*temp = *(temp+1);
L.length = L.length - 1;
//return OK;
}
}
//遍历,只要有相同的就标记并结束
int ListLocate_Sq(SqList L, ElemType e)
{
int i;
for(i = 0; i < L.length; i++)
{
if(L.elem[i] == e)
{
//break;
return i+1;
}
}
return ERROR;
}
void ListPrint_Sq(SqList L)
{
int i;
for (i=0;i<L.length;i++)
{
if (i==0) printf("%d",L.elem[i]);
else printf(" %d",L.elem[i]);
}
}
1X1-1顺序表基本操作
本题要求实现顺序表元素的增、删、查找以及顺序表输出共4个基本操作函数。L是一个顺序表,函数Status ListInsert_Sq(SqList &L, int pos, ElemType e)是在顺序表的pos位置插入一个元素e(pos应该从1开始),函数Status ListDelete_Sq(SqList &L, int pos, ElemType &e)是删除顺序表的pos位置的元素并用引用型参数e带回(pos应该从1开始),函数int ListLocate_Sq(SqList L, ElemType e)是查询元素e在顺序表的位次并返回(如有多个取第一个位置,返回的是位次,从1开始,不存在则返回0),函数void ListPrint_Sq(SqList L)是输出顺序表元素。实现时需考虑表满扩容的问题。
函数接口定义:
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
其中 L 是顺序表。 pos 是位置; e 代表元素。当插入与删除操作中的pos参数非法时,函数返回ERROR,否则返回OK。
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
Status ListInsert_Sq(SqList &L, int pos, ElemType e);
Status ListDelete_Sq(SqList &L, int pos, ElemType &e);
int ListLocate_Sq(SqList L, ElemType e);
void ListPrint_Sq(SqList L);
//结构初始化与销毁操作
Status InitList_Sq(SqList &L){
//初始化L为一个空的有序顺序表
L.elem=(ElemType *)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem)exit(OVERFLOW);
L.listsize=LIST_INIT_SIZE;
L.length=0;
return OK;
}
int main() {
SqList L;
if(InitList_Sq(L)!= OK) {
printf("InitList_Sq: 初始化失败!!!\n");
return -1;
}
for(int i = 1; i <= 10; ++ i)
ListInsert_Sq(L, i, i);
int operationNumber; //操作次数
scanf("%d", &operationNumber);
while(operationNumber != 0) {
int operationType; //操作种类
scanf("%d", & operationType);
if(operationType == 1) { //增加操作
int pos, elem;
scanf("%d%d", &pos, &elem);
ListInsert_Sq(L, pos, elem);
} else if(operationType == 2) { //删除操作
int pos; ElemType elem;
scanf("%d", &pos);
ListDelete_Sq(L, pos, elem);
printf("%d\n", elem);
} else if(operationType == 3) { //查找定位操作
ElemType elem;
scanf("%d", &elem);
int pos = ListLocate_Sq(L, elem);
if(pos >= 1 && pos <= L.length)
printf("%d\n", pos);
else
printf("NOT FIND!\n");
} else if(operationType == 4) { //输出操作
ListPrint_Sq(L);
}
operationNumber--;
}
return 0;
}
/* 请在这里填写答案 */
输入格式: 第一行输入一个整数operationNumber,表示操作数,接下来operationNumber行,每行表示一个操作信息(含“操作种类编号 操作内容”)。 编号为1表示插入操作,后面两个参数表示插入的位置和插入的元素值 编号为2表示删除操作,后面一个参数表示删除的位置 编号为3表示查找操作,后面一个参数表示查找的值 编号为4表示顺序表输出操作 输出格式: 对于操作2,输出删除的元素的值 对于操作3,输出该元素的位置,如果不存在该元素,输出“NOT FOUND”; 对于操作4,顺序输出整个顺序表的元素,两个元素之间用空格隔开,最后一个元素后面没有空格。
输入样例:
4
1 1 11
2 2
3 3
4
输出样例:
1
3
11 2 3 4 5 6 7 8 9 10
代码实现:
//添加元素
//pos位置之后的元素都往后挪一位,给pos让位
//注意:存储可能不够
Status ListInsert_Sq(SqList &L, int pos, ElemType e)
{
if (pos<1 || pos>L.length+1) return OVERFLOW; //注意判断条件限制的临界值
if (L.length >= L.listsize)
{
L.elem = (ElemType *)realloc(L.elem,(L.listsize + LISTINCREMENT)*sizeof(ElemType));
if (!L.elem) exit(OVERFLOW);
L.listsize += LISTINCREMENT;
}
ElemType*p;
for(p = L.elem+L.length-1; p >= L.elem+pos-1; p--)
*(p+1) = *p;
*(L.elem+pos-1) = e;
L.length++;
return OK;
}
//删除元素
//将pos位置的元素赋值给e,然后后边的一次覆盖前边的元素
//注意:pos可能不合法
Status ListDelete_Sq(SqList &L, int pos, ElemType &e)
{
if (pos<1 || pos>L.length)
return OVERFLOW;
e = L.elem[pos-1];
ElemType *p;
for (p = L.elem+pos-1;p<=L.elem+L.length-1;p++)
*p = *(p+1);
L.length--;
return OK;
}
//查询元素
//遍历,只要有相同的就标记并结束
int ListLocate_Sq(SqList L, ElemType e)
{
for (int i=0;i<L.length;i++)
if (e==L.elem[i]) return i+1;
return ERROR;
}
//输出元素
void ListPrint_Sq(SqList L)
{
ElemType *p;
for (p = L.elem;p<L.elem+L.length;p++)
{
if (p==L.elem) printf("%d",*p);
else printf(" %d",*p);
}
}
2X2-1爆内存函数实例
本题要求实现一个递归函数,用户传入非负整型参数n,用户依次输出1到n之间的整数。所谓递归函数就是指自己调用自己的函数。
说明:
- 递归函数求解问题的基本思想是把一个大规模问题的求解归结为一个相对较小规模问题的求解,
小规模归结为小小规模,以此类推,直至问题规模小至边界(边界问题可直接求解)。递归函数由两
部分组成,一部分为递归边界,另一部分为递归关系式。以求阶乘函数为例,递归边界Factorial(1)=1;递归公式:Factorial(n)=n*Factorial(n-1),它对应的递归函数如下:
int GetFactorial(int n)
{
int result;
if(n==1) result = 1; //递归边界,此时问题答案易知,可直接求解
else result =n* GetFactorial(n-1); //递归关系,大问题求解归结为小问题求解
return result;
}
- 发生函数递归调用(自己调用自己)或者普通函数调用时,系统需要保存调用发生前的执行场景信
息(包括调用发生前的各个变量取值信息以及函数执行位置等),以便被调函数执行完毕后可以顺利返
回并继续执行后续操作。每次调用都需要保存一个场景信息,保存这些场景信息需要的辅助空间的大小
与函数调用的次数呈正比,或者说其空间复杂度是O(n),当中n为调用次数。 - 本例的目的是让学生编写一个递归函数,并在自己的机器上测试递归调用次数达到多少时会发生内存
被爆而出现内存溢出的错误(我办公室机器上设置参数为66000时会溢出)。同样的这个问题,如果不
用递归函数而改用普通的循环语句解决问题,则不会出现内存溢出!
函数接口定义:
void PrintN (long n);
其中n为用户传入的参数。
裁判测试程序样例:
在这里给出函数被调用进行测试的例子。例如:
#include <stdio.h>
void PrintN(long n);
int main()
{
PrintN(66000L);
return 0;
}
/* 请在这里填写答案 */
输入样例:
5
输出样例:
12345
代码实现:
//找递归的结束条件:到1时结束就好
void PrintN(long n)
{
if(n==1)
printf("%d",n);
else
{
PrintN(n-1);
printf("%d",n);
}
}
3X3-1顺序表创建和就地逆置
本题要求实现顺序表的创建和就地逆置操作函数。L是一个顺序表,函数ListCreate_Sq(SqList &L)用于创建一个顺序表,函数ListReverse_Sq(SqList &L)是在不引入辅助数组的前提下将顺序表中的元素进行逆置,如原顺序表元素依次为1,2,3,4,则逆置后为4,3,2,1。
函数接口定义:
Status ListCreate_Sq(SqList &L);
void ListReverse_Sq(SqList &L);
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
Status ListCreate_Sq(SqList &L);
void ListReverse_Sq(SqList &L);
int main() {
SqList L;
ElemType *p;
if(ListCreate_Sq(L)!= OK) {
printf("ListCreate_Sq: 创建失败!!!\n");
return -1;
}
ListReverse_Sq(L);
if(L.length){
for(p=L.elem;p<L.elem+L.length-1;++p){
printf("%d ",*p);
}
printf("%d",*p);
}
return 0;
}
/* 请在这里填写答案 */
输入格式: 第一行输入一个整数n,表示顺序表中元素个数,接下来n个整数为表元素,中间用空格隔开。 输出格式: 输出逆置后顺序表的各个元素,两个元素之间用空格隔开,最后一个元素后面没有空格。
输入样例:
4
1 2 3 4
输出样例:
4 3 2 1
代码实现:
//思路:动态分配空间,设置表长,设置指针p,通过p++来输入元素,表容量为100
//注意:有可能分配空间会失败
Status ListCreate_Sq(SqList &L)
{
int n;
ElemType *p;
L.elem = (ElemType *)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if (!L.elem) exit(OVERFLOW);
L.listsize = LIST_INIT_SIZE;
scanf("%d",&n);
L.length = n;
for (p = L.elem;p<L.elem + L.length; p++)
scanf("%d",p);
return OK;
}
//思路:定义两个指针First和last分别指向顺序表的首地址和最后元素的地址,First和Last的元素交换,Frist和Last自增,一直到中间元素结束
//注意:
void ListReverse_Sq(SqList &L)
{
ElemType* First;
ElemType* Last;
ElemType temp;
for (First = L.elem,Last = L.elem + L.length - 1 ;First<=(L.elem + L.length/2),Last>=(L.elem + L.length/2);First++,Last--)
{
temp = *First;
*First = *Last;
*Last = temp;
}
}
3X3-2有序顺序表的插入
本题要求实现递增顺序表的有序插入函数。L是一个递增的有序顺序表,函数Status ListInsert_SortedSq(SqList &L, ElemType e)用于向顺序表中按递增的顺序插入一个数据。 比如:原数据有:2 5,要插入一个元素3,那么插入后顺序表为2 3 5。 要考虑扩容的问题。
函数接口定义:
Status ListInsert_SortedSq(SqList &L, ElemType e);
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
//顺序表的存储结构定义
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct{
ElemType* elem; //存储空间基地址
int length; //表中元素的个数
int listsize; //表容量大小
}SqList; //顺序表类型定义
//函数声明
Status ListInsert_SortedSq(SqList &L, ElemType e);
//顺序表初始化函数
Status InitList_Sq(SqList &L)
{
//开辟一段空间
L.elem = (ElemType*)malloc(LIST_INIT_SIZE * sizeof(ElemType));
//检测开辟是否成功
if(!L.elem){
exit(OVERFLOW);
}
//赋值
L.length = 0;
L.listsize = LIST_INIT_SIZE;
return OK;
}
//顺序表输出函数
void ListPrint_Sq(SqList L)
{
ElemType *p = L.elem;//遍历元素用的指针
for(int i = 0; i < L.length; ++i){
if(i == L.length - 1){
printf("%d", *(p+i));
}
else{
printf("%d ", *(p+i));
}
}
}
int main()
{
//声明一个顺序表
SqList L;
//初始化顺序表
InitList_Sq(L);
int number = 0;
ElemType e;
scanf("%d", &number);//插入数据的个数
for(int i = 0; i < number; ++i)
{
scanf("%d", &e);//输入数据
ListInsert_SortedSq(L, e);
}
ListPrint_Sq(L);
return 0;
}
/* 请在这里填写答案 */
输入格式: 第一行输入接下来要插入的数字的个数 第二行输入数字 输出格式: 输出插入之后的数字
输入样例:
5
2 3 9 8 4
输出样例:
2 3 4 8 9
代码实现:
//设置指针p,从最后一位开始如果待插入的元素比当前元素小,就把当前元素后移一位,一直到当前元素比待插入元素小
//注意:有可能表满,需要扩容
Status ListInsert_SortedSq(SqList &L, ElemType e)
{
//对表满情况的处理
if (L.length>=L.listsize)
{
L.elem = (ElemType *)realloc(L.elem,(L.listsize + LISTINCREMENT)*sizeof(ElemType));//注意每次扩容的基础
if (!L.elem) exit(OVERFLOW);
L.listsize += LISTINCREMENT;
}
ElemType *p = L.elem + L.length -1;
while (p>=L.elem && *p>e) //定位以及移动
{
*(p+1) = *p;
p--;
}
*(p+1) = e; //插入
L.length++;
return OK;
}
3X3-3数组循环左移
本题要求实现一个对数组进行循环左移的简单函数:一个数组a中存有n(>0)个整数,在不允许使用另外数组的前提下,将每个整数循环向左移m(≥0)个位置,即将a中的数据由(a0a1⋯an−1)变换为(am⋯an−1a0a1⋯am−1)(最前面的m个数循环移至最后面的m个位置)。如果还需要考虑程序移动数据的次数尽量少,要如何设计移动的方法?
输入格式:
输入第1行给出正整数n(≤100)和整数m(≥0);第2行给出n个整数,其间以空格分隔。
输出格式:
在一行中输出循环左移m位以后的整数序列,之间用空格分隔,序列结尾不能有多余空格。
输入样例:
8 3
1 2 3 4 5 6 7 8
输出样例:
4 5 6 7 8 1 2 3
代码实现:
//思路:需要左移的串逆转,需要右移的串逆转,将两个串拼接起来,再逆转就会得到结果
#include <stdio.h>
//实现字符串的逆转
void Reverse(int *s,int left,int right)
{
int temp;
while (left<right)
{
temp = s[left];
s[left] = s[right];
s[right] = temp;
left++;
right--;
}
}
//输出数组
void Print(int *s,int len)
{
int i;
for (i=0;i<len;i++)
{
if (i==0) printf("%d",s[i]);
else printf(" %d",s[i]);
}
}
int main()
{
int s[110];
int n,m;
int i;
scanf("%d %d",&n,&m);
m = m%n;
for (i=0;i<n;i++)
scanf("%d",&s[i]);
Reverse(s,0,m-1); //逆转前半部分需要左移的
Reverse(s,m,n-1); //逆转后半部分需要右移的
Reverse(s,0,n-1); //逆转整个字符串
Print(s,n);
}
4X4-1线性表元素的区间删除
给定一个顺序存储的线性表,请设计一个函数删除所有值大于min而且小于max的元素。删除后表中剩余元素保持顺序存储,并且相对位置不能改变。
函数接口定义:
List Delete( List L, ElementType minD, ElementType maxD );
其中List结构定义如下:
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
L是用户传入的一个线性表,其中ElementType元素可以通过>、==、<进行比较;minD和maxD分别为待删除元素的值域的下、上界。函数Delete应将Data[]中所有值大于minD而且小于maxD的元素删除,同时保证表中剩余元素保持顺序存储,并且相对位置不变,最后返回删除后的表。
裁判测试程序样例:
#include <stdio.h>
#define MAXSIZE 20
typedef int ElementType;
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
List ReadInput(); /* 裁判实现,细节不表。元素从下标0开始存储 */
void PrintList( List L ); /* 裁判实现,细节不表 */
List Delete( List L, ElementType minD, ElementType maxD );
int main()
{
List L;
ElementType minD, maxD;
int i;
L = ReadInput();
scanf("%d %d", &minD, &maxD);
L = Delete( L, minD, maxD );
PrintList( L );
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
10
4 -8 2 12 1 5 9 3 3 10
0 4
输出样例:
4 -8 12 5 9 10
代码实现:
//思路:遍历数组元素,将每一个元素需要前移的位数找出来,再分别将元素前移多少位数即可
//注意:L.length需要变化;有可能会有minD和maxD不合理的请求
List Delete( List L, ElementType minD, ElementType maxD )
{
if(minD >= maxD) return L;
int i;
int num = 0;
for (i = 0;i<=L->Last;i++) //注意L->Last是最后一个元素
{
if (L->Data[i]>minD && L->Data[i]<maxD) num++;
else L->Data[i-num] = L->Data[i];
}
L->Last -= num;
return L;
}
//补充:在移动元素的时候,不是使用覆盖的方法,只需要把当前元素直接向前移动num就行,不用使用while
4X4-2最长连续递增子序列
给定一个顺序存储的线性表,请设计一个算法查找该线性表中最长的连续递增子序列。例如,(1,9,2,5,7,3,4,6,8,0)中最长的递增子序列为(3,4,6,8)。
输入格式:
输入第1行给出正整数n(≤105);第2行给出n个整数,其间以空格分隔。
输出格式:
在一行中输出第一次出现的最长连续递增子序列,数字之间用空格分隔,序列结尾不能有多余空格。
输入样例:
15
1 9 2 5 7 3 4 6 8 0 11 15 17 17 10
输出样例:
3 4 6 8
代码实现:
/*思路:首先,创建一个结构体,定义一个maxIncSeq,用来记录最长连续递增子序列,再定义一个curIncSeq,用来记录当前连续递增子序列的信息
只要后一位的数比前一位要大,就更新curIncSeq的信息。
如果,当前长度大于最长的,就把maxIncSeq的信息更新。
注意:最后一个连续递增子序列需要单独处理*/
#include <stdio.h>
typedef struct IncSeq
{
int *p; //记录序列的开始位置
int length; //记录序列的长度
} IncSeq;
int main()
{
IncSeq maxIncSeq;
IncSeq curIncSeq;
int n;
int num = 0;
int a[100001];
int *q = a;
scanf("%d",&n);
for (int i=0;i<n;i++)
a[i] = 0;
maxIncSeq.p = a; //初始化连续递增子序列的信息
maxIncSeq.length = 0;
curIncSeq.p = a;
curIncSeq.length = 0;
scanf("%d",&a[0]);
for (q = a+1;q<a+n;q++)
{
scanf("%d",q);
num++;
if (*(q-1) >= *q)
{
curIncSeq.p = q-num; //更新curIncSeq的信息
curIncSeq.length = num;
if ( maxIncSeq.length < curIncSeq.length) //更新maxIncSeq的信息
{
maxIncSeq.p = curIncSeq.p;
maxIncSeq.length = curIncSeq.length;
}
num = 0;
}
}
//对最后一个递增子序列的单独处理
int lastLen = (a+n)-(curIncSeq.p + curIncSeq.length);
if (lastLen > maxIncSeq.length)
{
maxIncSeq.p = curIncSeq.p + curIncSeq.length;
maxIncSeq.length = lastLen;
}
for (q = maxIncSeq.p;q<maxIncSeq.p + maxIncSeq.length;q++) //输出最长连续递增子序列
{
if (q == maxIncSeq.p) printf("%d",*q);
else printf(" %d",*q);
}
}
/*补充:(1)比较连续递增子序列是否结束时,必须使用前一位和当前位的比较
(2)最后一位的单独处理注意开始位置和长度
(3)使用num计数,更新最大序列的信息时,不要忘记把num清0,而且注意num=0放的位置
*/
5X5-1单链表元素定位
本题要求在链表中查找第一个数据域取值为x的节点,返回节点的位序。L是一个带头结点的单链表,函数ListLocate_L(LinkList L, ElemType x)要求在链表中查找第一个数据域取值为x的节点,返回其位序(从1开始),查找不到则返回0。例如,原单链表各个元素节点的元素依次为1,2,3,4,则ListLocate_L(L, 1)返回1,ListLocate_L(L, 3)返回3,而ListLocate_L(L, 100)返回0。
函数接口定义:
int ListLocate_L(LinkList L, ElemType x);
其中 L 是一个带头节点的单链表。 x 是一个给定的值。函数须在链表中查找第一个数据域取值为x的节点。若找到则返回其位序(从1开始),找不到则返回0。
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
Status ListCreate_L(LinkList &L,int n)
{
LNode *rearPtr,*curPtr; //一个尾指针,一个指向新节点的指针
L=(LNode*)malloc(sizeof (LNode));
if(!L)exit(OVERFLOW);
L->next=NULL; //先建立一个带头结点的单链表
rearPtr=L; //初始时头结点为尾节点,rearPtr指向尾巴节点
for (int i=1;i<=n;i++){ //每次循环都开辟一个新节点,并把新节点拼到尾节点后
curPtr=(LNode*)malloc(sizeof(LNode));//生成新结点
if(!curPtr)exit(OVERFLOW);
scanf("%d",&curPtr->data);//输入元素值
curPtr->next=NULL; //最后一个节点的next赋空
rearPtr->next=curPtr;
rearPtr=curPtr;
}
return OK;
}
//下面是需要实现的函数的声明
int ListLocate_L(LinkList L, ElemType x);
int main()
{
LinkList L;
int n;
int x,k;
scanf("%d",&n); //输入链表中元素个数
if(ListCreate_L(L,n)!= OK) {
printf("表创建失败!!!\n");
return -1;
}
scanf("%d",&x); //输入待查找元素
k=ListLocate_L(L,x);
printf("%d\n",k);
return 0;
}
/* 请在这里填写答案 */
输入样例:
4
1 2 3 4
1
输出样例:
1
代码实现:
/*
思路:遍历链表,使用count计数的同时比较L->data和x,只要相等就返回count,否则返回0
注意:如果x不存在于链表中,那么最后指针p为NULL
*/
int ListLocate_L(LinkList L, ElemType x)
{
LNode *p=L;
int count=1;
while(p->next != NULL)
{
p = p->next;
if(p->data == x) return count;
count++;
}
return 0;
}
5X5-2 删除单链表中最后一个与给定值相等的结点
本题要求在链表中删除最后一个数据域取值为x的节点。L是一个带头结点的单链表,函数ListLocateAndDel_L(LinkList L, ElemType x)要求在链表中查找最后一个数据域取值为x的节点并将其删除。例如,原单链表各个节点的数据域依次为1 3 1 4 3 5,则ListLocateAndDel_L(L,3)执行后,链表中剩余各个节点的数据域取值依次为1 3 1 4 5。
函数接口定义:
void ListLocateAndDel_L(LinkList L, ElemType x);
其中 L 是一个带头节点的单链表。 x 是一个给定的值。函数须在链表中定位最后一个数据域取值为x的节点并删除之。
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define NULL 0
typedef int Status;
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
//链表创建函数
Status ListCreate_L(LinkList &L,int n)
{
LNode *rearPtr,*curPtr;
L=(LNode*)malloc(sizeof (LNode));
if(!L)exit(OVERFLOW);
L->next=NULL;
rearPtr=L;
for (int i=1;i<=n;i++){
curPtr=(LNode*)malloc(sizeof(LNode));
if(!curPtr)exit(OVERFLOW);
scanf("%d",&curPtr->data);
curPtr->next=NULL;
rearPtr->next=curPtr;
rearPtr=curPtr;
}
return OK;
}
//链表输出函数
void ListPrint_L(LinkList L)
{
LNode *p=L->next;
if(!p){
printf("空表");
return;
}
while(p!=NULL)
{
if(p->next!=NULL)
printf("%d ",p->data);
else
printf("%d",p->data);
p=p->next;
}
}
//下面是需要实现的函数的声明
void ListLocateAndDel_L(LinkList L, ElemType x);
int main()
{
LinkList L;
int n;
int x;
scanf("%d",&n); //输入链表中元素个数
if(ListCreate_L(L,n)!= OK) {
printf("表创建失败!!!\n");
return -1;
}
scanf("%d",&x); //输入待查找元素
ListLocateAndDel_L(L,x);
ListPrint_L(L);
return 0;
}
/* 请在这里填写答案 */
输入样例:
6
1 3 1 4 3 5
3
输出样例:
1 3 1 4 5
代码实现:
/*
思路:先遍历一遍链表,把与x相等的值的个数num找出来,然后再遍历一遍链表,使用count计数器,只要遇到x,count就自增。
当count与num相等时,就把对应的x值删除
注意:x有可能不存在于链表中,那么此时的num==0;当x位于最后一位时需要特殊处理
*/
void ListLocateAndDel_L(LinkList L, ElemType x)
{
//遍历链表找出与x相等的个数
LNode *p = L;
int num = 0;
while (p->next != NULL)
{
if (p->data == x) num++;
p = p->next;
}
if (p->data == x) num++;
//删除最后一个与x相等的值
LNode *q = L;
int count = 0;
while (q->next != NULL)
{
if (q->next->data == x) count++;
if (count == num && num != 0) //注意元素不存在的判断
{
q->next = q->next->next;
break;
}
q = q->next;
}
}
5X5-3两个有序链表序列的合并
已知两个非降序链表序列S1与S2,设计函数构造出S1与S2合并后的新的非降序链表S3。
输入格式:
输入分两行,分别在每行给出由若干个正整数构成的非降序序列,用−1表示序列的结尾(−1不属于这个序列)。数字用空格间隔。
输出格式:
在一行中输出合并后新的非降序链表,数字间用空格分开,结尾不能有多余空格;若新链表为空,输出NULL。
输入样例:
1 3 5 -1
2 4 6 8 10 -1
输出样例:
1 2 3 4 5 6 8 10
代码实现:
/*
思路:定义两个指针p、q分别指向s1和s2,从第一个元素开始比较,如果p->data大于q->data的话,就把q->next放入新的链表中。
然后,q = q->next,p不动,继续和下一个比较,以此类推
注意:总有一个链表要先遍历完,直接把剩余链表的元素接上就行
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define NULL 0
typedef int Status;
typedef struct LNode
{
int data;
struct LNode *next;
}LNode,*LinkList;
//函数实现
Status CreatList(LinkList &L); //创建一个链表
LinkList InsertList(); //往链表里插入元素
LinkList Merge(LinkList s1,LinkList s2); //合并两个链表
void Print(LinkList L); //输出链表的元素
int main()
{
LinkList s1,s2,L;
CreatList(s1);
CreatList(s2);
CreatList(L);
s1 = InsertList();
s2 = InsertList();
L = Merge(s1,s2);
Print(L);
}
//创建链表
Status CreatList(LinkList &L)
{
L = (LNode*)malloc(sizeof(LNode));
if (!L) exit(OVERFLOW);
L->next = NULL;
return OK;
}
//向链表中插入元素
LinkList InsertList()
{
int n;
LinkList L;
CreatList(L);
LNode *p = L;
scanf("%d",&n);
while (n != -1)
{
LNode *temp;
temp = (LNode*)malloc(sizeof(LNode));
temp->data = n;
p->next = temp;
p = temp;
scanf("%d",&n);
p->next = NULL;
}
return L;
}
//合并链表
LinkList Merge(LinkList s1,LinkList s2)
{
LNode *p = s1->next; //用来遍历s1
LNode *q = s2->next; //用来遍历s2
LinkList L; //不要忘记初始化
L = (LNode *)malloc(sizeof(LNode));
LNode *temp = L;
while (p && q)
{
if (p->data < q->data)
{
temp->next = p; //连接元素
temp = p; //新表移动
p = p->next; //原来的表移动
}
else
{
temp->next = q;
temp = q;
q = q->next;
}
}
//将剩余元素接上
temp->next = p?p:q;
s1->next = NULL;
s2->next = NULL;
return L;
}
//输出元素
//注意与顺序表不同的是要在循环里边加上L = L->next
void Print(LinkList L)
{
L = L->next;
int num = 0;
if (L==NULL) printf("NULL");
else
{
while (L)
{
if (!num) printf("%d",L->data);
else printf(" %d",L->data);
num++;
L = L->next;
}
printf("\n");
}
}
6X6-1带头结点的单链表就地逆置
本题要求编写函数实现带头结点的单链线性表的就地逆置操作函数。L是一个带头结点的单链表,函数ListReverse_L(LinkList &L)要求在不新开辟节点的前提下将单链表中的元素进行逆置,如原单链表元素依次为1,2,3,4,则逆置后为4,3,2,1。
函数接口定义:
void ListReverse_L(LinkList &L);
其中 L 是一个带头结点的单链表。
裁判测试程序样例:
//库函数头文件包含
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef int ElemType; //假设线性表中的元素均为整型
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
Status ListCreate_L(LinkList &L,int n)
{
LNode *rearPtr,*curPtr; //一个尾指针,一个指向新节点的指针
L=(LNode*)malloc(sizeof (LNode));
if(!L)exit(OVERFLOW);
L->next=NULL; //先建立一个带头结点的单链表
rearPtr=L; //初始时头结点为尾节点,rearPtr指向尾巴节点
for (int i=1;i<=n;i++){ //每次循环都开辟一个新节点,并把新节点拼到尾节点后
curPtr=(LNode*)malloc(sizeof(LNode));//生成新结点
if(!curPtr)exit(OVERFLOW);
scanf("%d",&curPtr->data);//输入元素值
curPtr->next=NULL; //最后一个节点的next赋空
rearPtr->next=curPtr;
rearPtr=curPtr;
}
return OK;
}
void ListReverse_L(LinkList &L);
void ListPrint_L(LinkList &L){
//输出单链表
LNode *p=L->next; //p指向第一个元素结点
while(p!=NULL)
{
if(p->next!=NULL)
printf("%d ",p->data);
else
printf("%d",p->data);
p=p->next;
}
}
int main()
{
LinkList L;
int n;
scanf("%d",&n);
if(ListCreate_L(L,n)!= OK) {
printf("表创建失败!!!\n");
return -1;
}
ListReverse_L(L);
ListPrint_L(L);
return 0;
}
/* 请在这里填写答案 */
输入格式:
第一行输入一个整数n,表示单链表中元素个数,接下来一行共n个整数,中间用空格隔开。
输出格式:
输出逆置后顺序表的各个元素,两个元素之间用空格隔开,最后一个元素后面没有空格。
输入样例:
4
1 2 3 4
输出样例:
4 3 2 1
代码实现:
/*思路:使用指针p来指向当前元素,另一个指针q赋值为当前元素的next成员,p的next成员赋值为q的next成员,这就实现把链表中的元素取出来。
取出来的元素用q来表示,把q添加到头结点的后边,q的next成员赋值为第一个元素即可。以此类推,直至链表为NULL。
注意:有可能链表为空或者链表只有一个元素
*/
void ListReverse_L(LinkList &L)
{
LNode *p; //用于指向当前元素
LNode *q; //用于取出元素
p = L->next;
while (p->next != NULL)
{
//取出当前元素
q = p->next;
p->next = q->next;
//添加到头结点后边
q->next = L->next;
L->next = q;
}
}
6X6-2一元多项式求导
设计函数求一元多项式的导数。
输入格式:
以指数递降方式输入多项式非零项系数和指数(绝对值均为不超过1000的整数)。数字间以空格分隔。
输出格式:
以与输入相同的格式输出导数多项式非零项的系数和指数。数字间以空格分隔,但结尾不能有多余空格。
输入样例:
3 4 -5 2 6 1 -2 0
输出样例:
12 3 -10 1 6 0
代码实现:
/*思路:多项式的求导就是系数变成指数和原来系数相同,指数减一。由于该多项式是一元多项式而且指数按照递降顺序排列,所以不需要求导以后的合并。
求导过程:指数乘以系数,然后指数减一
注意:创造结构体时data的类型是Elemtype,而此时的data包括两个内容,系数和指数,又是结构体类型
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct Elemtype
{
int coef; //系数
int index; //指数
}Elemtype;
typedef struct LNode
{
Elemtype data;
struct LNode *next;
}LNode,*LinkList;
//函数实现
Status CreatList(LinkList &L); //创建链表
LinkList InputList(); //输入多项式
void Deri_List(LinkList &L); //求导
void Print_L(LinkList L); //输出多项式
int Flag1 = 0;
int Flag2 = 0;
int Flag3 = 0;
int main()
{
LinkList L;
CreatList(L);
L = InputList();
Deri_List(L);
Print_L(L);
}
Status CreatList(LinkList &L)
{
L = (LNode*)malloc(sizeof(LNode));
if (!L) exit(OVERFLOW);
L->next = NULL;
return OK;
}
LinkList InputList()
{
int m,n = 1;
LinkList L;
CreatList(L);
LNode *p = L;
int flag = 0;
while (scanf("%d",&m)!=EOF)
{
Flag1 = 1;
if (m==0 && flag == 0) Flag2 = 2;
LNode *temp = (LNode*)malloc(sizeof(LNode));
temp->data.coef = m; //系数
if (scanf("%d",&n)!=EOF)
{
temp->data.index = n; //指数
if (n == 0 && flag == 0) Flag2 = 2;
else if (n==0) Flag3 = 3;
}
else break;
flag++;
p->next = temp;
p = temp;
p->next = NULL;
}
return L;
}
void Deri_List(LinkList &L)
{
LNode *p = L->next;
while (p != NULL)
{
p->data.coef *= p->data.index;
p->data.index--;
p = p->next;
}
}
void Print_L(LinkList L)
{
if (!Flag1||Flag2 == 2) printf("0 0");
else
{
LNode *p = L->next;
int flag = 0;
while (p != NULL)
{
if (p->data.index != -1)
{
if (flag != 0) printf(" %d %d",p->data.coef,p->data.index);
else printf("%d %d",p->data.coef,p->data.index);
flag++;
}
p = p->next;
}
printf("\n");
}
}
/*补充:(1)输入函数的结束标记:由于while循环体里面要求输入m,所以要在输入m之前break;
(2)如果只输入一个系数的情况
(3)如果输入的第一个数是0的情况
*/
6X6-3求链式线性表的倒数第K项
给定一系列正整数,请设计一个尽可能高效的算法,查找倒数第K个位置上的数字。
输入格式:
输入首先给出一个正整数K,随后是若干正整数,最后以一个负整数表示结尾(该负数不算在序列内,不要处理)。
输出格式:
输出倒数第K个位置上的数据。如果这个位置不存在,输出错误信息NULL。
输入样例:
4 1 2 3 4 5 6 7 8 9 0 -1
输出样例:
7
代码实现:
//求链式线性表的倒数第K项
/*
思路:设置两个指针p和q,两个指针之间的距离始终保持K个单位,当q指针指向末尾时,p指针就指向了倒数第K项
注意:链表长度可能小于K,此时要输出错误信息NULL
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct LNode
{
int data;
struct LNode *next;
}LNode,*LinkList;
//函数实现
Status CreatList(LinkList &L); //创建链表
LinkList InputList(); //输入数据
void Print_K(LinkList L,int k); //按要求输出数据
int main()
{
LinkList L;
CreatList(L);
int k;
scanf("%d",&k);
L = InputList();
Print_K(L,k);
}
//创建链表
Status CreatList(LinkList &L)
{
L = (LNode *)malloc(sizeof(LNode));
if (!L) exit(OVERFLOW);
L->next = NULL;
return OK;
}
//输入元素
LinkList InputList()
{
int n;
LinkList L;
CreatList(L);
LNode *p = L;
scanf("%d",&n);
while (n >= 0)
{
LNode *temp = (LNode*)malloc(sizeof(LNode));
temp->data = n;
p->next = temp;
p = temp;
scanf("%d",&n);
p->next = NULL;
}
return L;
}
void Print_K(LinkList L,int k)
{
LNode *p = L->next;
LNode *q = L->next;
int flag = 1;
while (p->next != NULL && flag < k)
{
p = p->next;
flag++;
}
while (p->next != NULL)
{
p = p->next;
q = q->next;
}
if (flag<k) printf("NULL");
else printf("%d",q->data);
}
7X7-1堆栈操作合法性
假设以S和X分别表示入栈和出栈操作。如果根据一个仅由S和X构成的序列,对一个空堆栈进行操作,相应操作均可行(如没有出现删除时栈空)且最后状态也是栈空,则称该序列是合法的堆栈操作序列。请编写程序,输入S和X序列,判断该序列是否合法。
输入格式:
输入第一行给出两个正整数N和M,其中N是待测序列的个数,M(≤50)是堆栈的最大容量。随后N行,每行中给出一个仅由S和X构成的序列。序列保证不为空,且长度不超过100。
输出格式:
对每个序列,在一行中输出YES如果该序列是合法的堆栈操作序列,或NO如果不是。
输入样例:
4 10
SSSXXSXXSX
SSSXXSXXS
SSSSSSSSSSXSSXXXXXXXXXXX
SSSXXSXXX
输出样例:
YES
NO
NO
NO
代码实现:
/*
思路:定义一个栈,栈的容量就是待输入的m,如果输入s,那么栈顶指针后移,如果输入x,那么栈顶指针前移
如果栈顶指针超过栈底指针+栈容量,返回ERROR;
如果栈顶指针小于栈底指针,返回ERROR;
如果输入结束时,栈顶指针不等于栈底指针,返回ERROR;
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct Stack
{
int *base;
int *top;
int Stacksize;
}Stack;
Status InitStack(Stack &S,int len)
{
S.base = (int *)malloc(len * sizeof(int));
if (!S.base) exit(OVERFLOW);
S.top = S.base;
S.Stacksize = len;
return OK;
}
Status ClearStack(Stack &S)
{
S.top = S.base;
return OK;
}
int main()
{
Stack S;
string s;
int n,m;
scanf("%d %d",&n,&m);
InitStack(S,m);
int flag = 0;
while (n--)
{
cin>>s;
int len = s.length();
for (int i=0; i<len; i++)
{
if (s[i] == 'S') S.top++;
else if (s[i] == 'X') S.top--;
if (S.top > S.base + S.Stacksize || S.top < S.base) flag++;
if (i == len - 1 && S.top != S.base) flag++;
}
if (!flag) printf("YES\n");
else
{
printf("NO\n");
flag = 0;
}
ClearStack(S);
}
}
7X7-2符号配对
请编写程序检查C语言源程序中下列符号是否配对:/与/、(与)、[与]、{与}。
输入格式:
输入为一个C语言源程序。当读到某一行中只有一个句点.和一个回车的时候,标志着输入结束。程序中需要检查配对的符号不超过100个。
输出格式:
首先,如果所有符号配对正确,则在第一行中输出YES,否则输出NO。然后在第二行中指出第一个不配对的符号:如果缺少左符号,则输出?-右符号;如果缺少右符号,则输出左符号-?。
输入样例1:
void test()
{
int i, A[10];
for (i=0; i<10; i++) /*/
A[i] = i;
}
.
输出样例1:
NO
/*-?
输入样例2:
void test()
{
int i, A[10];
for (i=0; i<10; i++) /**/
A[i] = i;
}]
.
输出样例2:
NO
?-]
输入样例3:
void test()
{
int i
double A[10];
for (i=0; i<10; i++) /**/
A[i] = 0.1*i;
}
.
输出样例3:
YES
代码实现:
/*
思路:定义一个栈,然后读入字符,只要没有同时遇到.和回车就判断是不是给定的符号,要是左半部分就存入栈,要是右半部分就出栈,如果二者对应即匹配
否则,即为不匹配。如果不匹配的话,输出对应缺少部分
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define STACK_INIT_SIZE 100
#define STACK_ADDSIZE 10
typedef int Status;
typedef struct Stack
{
char *top;
char *base;
int StackSize;
}Stack;
Status InitStack(Stack &S); //初始化栈
Status push(Stack &S,char ch); //往栈中压入元素
Status Pop(Stack &S); //弹出元素
Status GetTop(Stack &S,char &temp); //获取栈顶元素
void Right(char ch); //检查是否配对
int main()
{
Stack S;
InitStack(S);
char a[110];
int flag = 1;
while (cin>>a)
{
if (a[0] == '.') break;
int len = strlen(a);
for (int i=0;i<len;i++)
{
if (a[i] == '(' || a[i] == '[' || a[i] == '{')
push(S,a[i]);
else if (a[i] == '/' && a[i+1] == '*' && i+1<len) //特殊处理有两个字符出现的/**/,使用@代替
{
i++;
push(S,'@');
}
else if (a[i] == ')')
{
if(S.top!=S.base) //栈不为空
{
char temp;
GetTop(S,temp);
if(temp == '(') Pop(S); //符号匹配,出栈
else if(flag) //符号不匹配
{
cout<<"NO"<<endl;
flag = 0;
Right(temp);
}
}
else if(flag) //栈空并且从未输出的情况,缺少左符号
{
cout<<"NO"<<endl;
flag = 0;
cout<<"?-)"<<endl;
}
}
else if (a[i] == ']')
{
if(S.top != S.base)//如果栈不空
{
char temp;
GetTop(S,temp);
if(temp == '[') Pop(S);
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
Right(temp);
}
}
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
cout<<"?-]"<<endl;
}
}
else if (a[i] == '}')
{
if(S.top!=S.base)//如果栈不空
{
char temp;
GetTop(S,temp);
if(temp == '{') Pop(S);
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
Right(temp);
}
}
else if(flag)
{
cout<<"NO"<<endl;
flag = 0;
cout<<"?-}"<<endl;
}
}
else if(a[i]=='*' && a[i+1]=='/' && i+1<len)
{
i++;
if(S.top!=S.base)
{
char temp;
GetTop(S,temp);
if(temp == '@')
Pop(S);
else if(flag)
{
cout<<"NO"<<endl;
flag=0;
Right(temp);
}
}
else if(flag)
{
cout<<"NO"<<endl;
flag=0;
cout<<"?-*/"<<endl;
}
}
}
}
if(flag) //从未有过输出符号的情况
{
if(S.base == S.top) //没出现过符号或者符号都出栈,匹配成功
cout<<"YES"<<endl;
else //有剩余符号
{
char temp;
GetTop(S,temp);
cout<<"NO"<<endl;
Right(temp);
}
}
}
Status InitStack(Stack &S)
{
S.base = (char *)malloc(STACK_INIT_SIZE * sizeof(char));
if (!S.base) exit(OVERFLOW);
S.top = S.base;
S.StackSize = STACK_INIT_SIZE;
return OK;
}
Status push(Stack &S,char ch)
{
if (S.top == S.base + STACK_INIT_SIZE)
{
S.base = (char*)realloc(S.base,(STACK_INIT_SIZE + STACK_ADDSIZE) * sizeof(char));
if (!S.base) exit(OVERFLOW);
S.top = S.base + S.StackSize;
S.StackSize += STACK_ADDSIZE;
return OK;
}
*S.top = ch;
S.top++;
return OK;
}
Status Pop(Stack &S)
{
if (S.base == S.top) return ERROR;
S.top--;
return OK;
}
Status GetTop(Stack &S,char &temp)
{
if (S.top == S.base)
return ERROR;
temp = *(S.top - 1);
return OK;
}
void Right(char ch)
{
if(ch == '(')
cout<<"(-?"<<endl;
else if(ch == '[')
cout<<"[-?"<<endl;
else if(ch == '{')
cout<<"{-?"<<endl;
else if(ch == '@')//用@代替/*
cout<<"/*-?"<<endl;
}
/*
补充:(1)注意GetTop()函数中temp用于带回值,必须加上引用
(2)比较特殊的是注释符号,这也决定了字符的输入先用数组存起来才能判断下一位是否为*,然后用@代替整体的注释符
(3)缺少左右符号时第一位还得输出?-或者-?,所以需要用到标记变量判断是否是第一次或者最后一次输出
(4)缺少右符号的情况就是栈中有元素但是与当前元素不匹配,缺少左符号是栈为空,但此时还有符号等待匹配
*/
8X8-1递归实现指数函数
本题要求实现一个计算xn(n≥1)的函数。
函数接口定义:
double calc_pow( double x, int n );
函数calc_pow应返回x的n次幂的值。建议用递归实现。题目保证结果在双精度范围内。
裁判测试程序样例:
#include <stdio.h>
double calc_pow( double x, int n );
int main()
{
double x;
int n;
scanf("%lf %d", &x, &n);
printf("%.0f\n", calc_pow(x, n));
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
2 3
输出样例:
8
代码实现:
double calc_pow( double x, int n )
{
if (n == 1) return x;
else return x * calc_pow(x,n-1);
}
8X8-2递归计算Ackermenn函数
本题要求实现Ackermenn函数的计算,其函数定义如下:
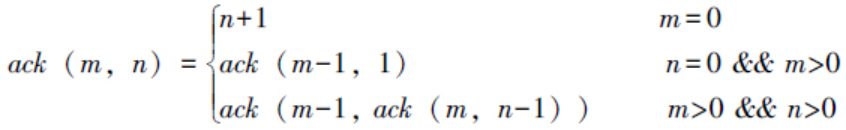
函数接口定义:
int Ack( int m, int n );
其中m和n是用户传入的非负整数。函数Ack返回Ackermenn函数的相应值。题目保证输入输出都在长整型
范围内。
裁判测试程序样例:
#include <stdio.h>
int Ack( int m, int n );
int main()
{
int m, n;
scanf("%d %d", &m, &n);
printf("%d\n", Ack(m, n));
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
2 3
输出样例:
9
代码实现:
int Ack( int m, int n )
{
if (m == 0) return n+1;
else if(n == 0 && m>0) return Ack(m-1,1);
else if (m>0 && n>0) return Ack(m-1,Ack(m,n-1));
}
8X8-3递归求Fabonacci数列
本题要求实现求Fabonacci数列项的函数。Fabonacci数列的定义如下:
f(n)=f(n−2)+f(n−1) (n≥2),其中f(0)=0,f(1)=1。
函数接口定义:
int f( int n );
函数f应返回第n个Fabonacci数。题目保证输入输出在长整型范围内。建议用递归实现。
裁判测试程序样例:
#include <stdio.h>
int f( int n );
int main()
{
int n;
scanf("%d", &n);
printf("%d\n", f(n));
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
6
输出样例:
8
代码实现:
int f( int n )
{
if (n == 0) return 0;
else if (n == 1) return 1;
else return f(n-1) + f(n-2);
}
8X8-4十进制转换二进制
本题要求实现一个函数,将正整数n转换为二进制后输出。
函数接口定义:
void dectobin( int n );
函数dectobin应在一行中打印出二进制的n。建议用递归实现。
裁判测试程序样例:
#include <stdio.h>
void dectobin( int n );
int main()
{
int n;
scanf("%d", &n);
dectobin(n);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
10
输出样例:
1010
代码实现:
void dectobin( int n )
{
if (n == 0 || n == 1) printf("%d",n);
else
{
dectobin(n/2);
printf("%d",n%2);
}
}
8X8-5递归计算P函数
本题要求实现下列函数P(n,x)的计算,其函数定义如下:
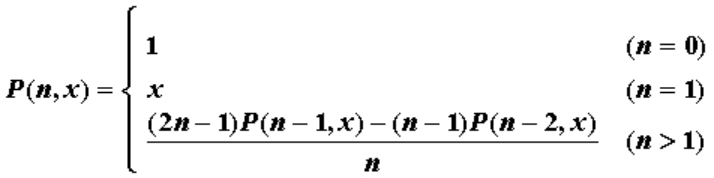
函数接口定义:
double P( int n, double x );
其中n是用户传入的非负整数,x是双精度浮点数。函数P返回P(n,x)函数的相应值。题目保证输入输出都在双精度范围内。
裁判测试程序样例:
#include <stdio.h>
double P( int n, double x );
int main()
{
int n;
double x;
scanf("%d %lf", &n, &x);
printf("%.2f\n", P(n,x));
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
10 1.7
输出样例:
3.05
代码实现:
double P( int n, double x )
{
if (n == 0) return 1;
else if (n == 1) return x;
else return ((2*n-1)*P(n-1,x) - (n-1)*P(n-2,x))/n;
}
8X8-6整数分解为若干项之和
将一个正整数N分解成几个正整数相加,可以有多种分解方法,例如7=6+1,7=5+2,7=5+1+1,…。编程求出正整数N的所有整数分解式子。
输入格式:
每个输入包含一个测试用例,即正整数N (0<N≤30)。
输出格式:
按递增顺序输出N的所有整数分解式子。递增顺序是指:对于两个分解序列N1={n1,n2,⋯}和N2={m1,m2,⋯},若存在i使得n1=m1,⋯,ni=mi,但是ni+1<mi+1,则N1序列必定在N2序列之前输出。每个式子由小到大相加,式子间用分号隔开,且每输出4个式子后换行。
输入样例:
7
输出样例:
7=1+1+1+1+1+1+1;7=1+1+1+1+1+2;7=1+1+1+1+3;7=1+1+1+2+2
7=1+1+1+4;7=1+1+2+3;7=1+1+5;7=1+2+2+2
7=1+2+4;7=1+3+3;7=1+6;7=2+2+3
7=2+5;7=3+4;7=7
代码实现:
/*
思路:如果n等于0,直接输出等号以及前边部分
如果n不等于0,依次递增分解输出,并且输出长度未分解的时候最小,越分解长度越大
*/
#include <bits/stdc++.h>
using namespace std;
int Num[35]; //存储分解的值
int N; //将最初输入的值保存下来以便等号前边的输出
int flag = 0; //控制换行符的输出
int k = 1; //用于控制初始不变的输出分解值
void Print(int len)
{
for (int i=0;i<len;i++)
{
if (i==0) printf("%d",Num[i]);
else printf("+%d",Num[i]);
}
}
int Decompose(int n,int len)
{
//递归边界
if (n<=0)
{
if (flag == 4) //每四个式子输出一个换行符
{
printf("\n");
flag = 0;
}
flag++;
if (flag == 1) //控制分号的输出
{
printf("%d=",N);
Print(len);
}
else
{
printf(";%d=",N);
Print(len);
}
return 0;
}
//递归条件
for (int i=1;i<=n;i++)
{
if (i>=k)
{
Num[len] = i;
k = i;
Decompose(n-i,len+1);
k = i; //回归到前边应该输出的数字
}
}
}
int main()
{
int n;
scanf("%d",&n);
N = n; //用于记录初始值
Decompose(n,0);
return 0;
}
8X8-7输出全排列
请编写程序输出前n个正整数的全排列(n<10),并通过9个测试用例(即n从1到9)观察n逐步增大时程序的运行时间。
输入格式:
输入给出正整数n(<10)。
输出格式:
输出1到n的全排列。每种排列占一行,数字间无空格。排列的输出顺序为字典序,即序列a1,a2,⋯,an排在序列b1,b2,⋯,bn之前,如果存在k使得a1=b1,⋯,ak=bk 并且 ak+1<bk+1。
输入样例:
3
输出样例:
123
132
213
231
312
321
代码实现:
/*
思路:(1)把n之前的所有数字存入一个数组。
(2)从第一个数字开始,以第一个数字为首元素一共排列n个数字
(3)以第一个数字为首排列完成后,将第一个数字和第二个数字交换,重复(2)的操作
(4)以此类推,直到为首的数字是最后一个数字
注意:排列的输出顺序为字典顺序
*/
#include <bits/stdc++.h>
using namespace std;
int a[15];
void Swap(int &m,int &n)
{
int temp;
temp = m;
m = n;
n = temp;
}
//用于排列数组顺序使其按照字典序输出
void Sort(int a[],int start,int end)
{
for (int i=start;i<=end;i++)
{
for (int j = i;j<=end;j++)
{
if (a[i]>a[j])
{
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
}
void Array(int a[],int start,int n)
{
if (start == n)
{
for (int i=1;i<=n;i++)
printf("%d",a[i]);
printf("\n");
}
else
{
for (int i=start;i<=n;i++)
{
Sort(a,start,n);
Swap(a[start],a[i]); //为首的数字进行交换
Array(a,start+1,n);
Swap(a[start],a[i]); //进行下一个全排列的时候将上一次交换的数字归位
}
}
}
int main()
{
int n;
cin>>n;
for (int i = 1;i<=n;i++)
a[i] = i;
Array(a,1,n);
}
8X8-8求前缀表达式的值
算术表达式有前缀表示法、中缀表示法和后缀表示法等形式。前缀表达式指二元运算符位于两个运算数之前,例如2+3*(7-4)+8/4的前缀表达式是:+ + 2 * 3 - 7 4 / 8 4。请设计程序计算前缀表达式的结果值。
输入格式:
输入在一行内给出不超过30个字符的前缀表达式,只包含+、-、*、/以及运算数,不同对象(运算数、运算符号)之间以空格分隔。
输出格式:
输出前缀表达式的运算结果,保留小数点后1位,或错误信息ERROR。
输入样例:
+ + 2 * 3 - 7 4 / 8 4
输出样例:
13.0
代码实现:
/*
思路:只要字符串中是数字字符,就把字符转化成数字;
只要遇见运算符就按照运算规则进行运算;
只要有两个及以上的运算符,先把第一个数字运算上后边整个剩下字符串,直至只有一个数字
注意:(1)运算出来的结构是保留一位小数的double型;
(2)分母为零的情况返回ERROR,并且直接退出程序
(3)判断数字前边是否带有正负号
*/
#include <bits/stdc++.h>
using namespace std;
double Prefix()
{
char str[30];
scanf("%s",str);
if (!str[1]) //判断数字前边是否有符号
{
if (str[0] == '+')
return Prefix() + Prefix();
else if (str[0] == '-')
return Prefix() - Prefix();
else if (str[0] == '*')
return Prefix() * Prefix();
else if (str[0] == '/')
{
double mol = Prefix();
double den = Prefix();
if (den != 0) return mol / den;
else
{
printf("ERROR");
exit(0); //不能用return 0代替,exit(0)强制退出程序
}
}
else return atof(str); //应当将数字字符直接转化成浮点数,不能用str[0]-'0'
}
else //数字前边有符号的情况
{
if (str[0] == '-' || str[0] == '+')
{
char flag = str[0]; //先把数字符号记录下来,然后依次用后边的覆盖前边字符
int i = 0;
while (str[i])
{
str[i] = str[i+1];
i++;
}
if (flag == '-') return 0 - atof(str);
else return atof(str);
}
else return atof(str);
}
}
int main()
{
printf("%.1f",Prefix());
return 0;
}
9X9-1银行业务队列简单模拟
设某银行有A、B两个业务窗口,且处理业务的速度不一样,其中A窗口处理速度是B窗口的2倍 —— 即当A窗口每处理完2个顾客时,B窗口处理完1个顾客。给定到达银行的顾客序列,请按业务完成的顺序输出顾客序列。假定不考虑顾客先后到达的时间间隔,并且当不同窗口同时处理完2个顾客时,A窗口顾客优先输出。
输入格式:
输入为一行正整数,其中第1个数字N(≤1000)为顾客总数,后面跟着N位顾客的编号。编号为奇数的顾客需要到A窗口办理业务,为偶数的顾客则去B窗口。数字间以空格分隔。
输出格式:
按业务处理完成的顺序输出顾客的编号。数字间以空格分隔,但最后一个编号后不能有多余的空格。
输入样例:
8 2 1 3 9 4 11 13 15
输出样例:
1 3 2 9 11 4 13 15
代码实现:
/*
思路:先把所有输入的数据按照奇偶数分别插入到两个队列里,并分别计数。然后循环删除队列元素,A队列每删除一个,B队列删除两个,并且计数器对应相减,直到一方为0
注意:两边窗口有特殊人数需要特殊处理
(1)A有两人以上 :一般处理
(2)A只有一人 :A出一个,B出一个
(3)有一边窗口没有人 :直接让一边的队列元素出队即可
*/
#include <bits/stdc++.h>
using namespace std;
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
typedef int Status;
typedef int Elemtype;
typedef struct QNode
{
Elemtype data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct
{
QueuePtr front;
QueuePtr rear;
} LinkQueue;
Status InitLinkQueue(LinkQueue &Q); //初始化队列
Status InsetLinkQueue(LinkQueue &Q,Elemtype n); //向队列中插入元素
Status DeleteLinkQueue(LinkQueue &Q,Elemtype &e);//删除队列元素,同时带回(注意引用)
int main()
{
LinkQueue A;
LinkQueue B;
InitLinkQueue(A);
InitLinkQueue(B);
int n,number;
int flag = 0; //控制输出格式
int countA = 0,countB = 0;
cin>>n;
for (int i = 0;i<n;i++) //将所有编号存起来
{
cin>>number;
if (number % 2 == 0) //奇数在A,偶数在B
{ InsetLinkQueue(B,number); countB++;}
else { InsetLinkQueue(A,number); countA++;}
}
while (countA && countB) //当两边窗口都有人的时候
{
int a,b,c;
if (countA >= 2 && countB >= 1)
{
DeleteLinkQueue(A,a); //根据题目窗口处理效率出队
DeleteLinkQueue(A,b);
DeleteLinkQueue(B,c);
countA -= 2;
countB--;
if (!flag) {cout<<a<<" "<<b<<" "<<c;flag = 1;}
else {cout<<" "<<a<<" "<<b<<" "<<c;}
}
else if (countA == 1 && countB >= 1) //特殊:A窗口不足两个人,所以只能A出一个,B出一个
{
DeleteLinkQueue(A,a);
DeleteLinkQueue(B,b);
countA--;
countB--;
if (!flag) {cout<<a<<" "<<b;flag = 1;}
else {cout<<" "<<a<<" "<<b;}
}
}
while (countA) //只有A窗口有人
{
int a;
DeleteLinkQueue(A,a);
countA--;
if (!flag) {cout<<a;flag = 1;}
else {cout<<" "<<a;}
}
while (countB) //只有B窗口有人
{
int a;
DeleteLinkQueue(B,a);
countB--;
if (!flag) {cout<<a;flag = 1;}
else {cout<<" "<<a;}
}
}
Status InitLinkQueue(LinkQueue &Q)
{
Q.front = Q.rear = (QueuePtr)malloc(sizeof(QNode));
if (!Q.front) exit(OVERFLOW);
Q.front->next = NULL; //注意!!!
return OK;
}
Status InsetLinkQueue(LinkQueue &Q,Elemtype n)
{
QueuePtr p;
p = (QNode *)malloc(sizeof(QNode));
if (!p) exit(OVERFLOW);
p->data = n;
p->next = NULL;
Q.rear->next = p;
Q.rear = p;
return OK;
}
Status DeleteLinkQueue(LinkQueue &Q,Elemtype &e)
{
if (Q.front == Q.rear) return ERROR;
QueuePtr p = Q.front->next; //队列是先进先出,所以要指向队头
e = p->data;
Q.front->next = p->next;
if (Q.rear == p) Q.rear = Q.front;
free(p);
return OK;
}
11X11-1二叉树求深度和叶子数
编写函数计算二叉树的深度以及叶子节点数。二叉树采用二叉链表存储结构
函数接口定义:
int GetDepthOfBiTree ( BiTree T);
int LeafCount(BiTree T);
其中 T是用户传入的参数,表示二叉树根节点的地址。函数须返回二叉树的深度(也称为高度)。
裁判测试程序样例:
//头文件包含
#include<stdlib.h>
#include<stdio.h>
#include<malloc.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define INFEASIBLE -2
#define NULL 0
typedef int Status;
//二叉链表存储结构定义
typedef int TElemType;
typedef struct BiTNode{
TElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
//创建二叉树各结点,输入零代表创建空树
//采用递归的思想创建
//递归边界:空树如何创建呢:直接输入0;
//递归关系:非空树的创建问题,可以归结为先创建根节点,输入其数据域值;再创建左子树;最后创建右子树。左右子树递归即可完成创建!
Status CreateBiTree(BiTree &T){
TElemType e;
scanf("%d",&e);
if(e==0)T=NULL;
else{
T=(BiTree)malloc(sizeof(BiTNode));
if(!T)exit(OVERFLOW);
T->data=e;
CreateBiTree(T->lchild);
CreateBiTree(T->rchild);
}
return OK;
}
//下面是需要实现的函数的声明
int GetDepthOfBiTree ( BiTree T);
int LeafCount(BiTree T);
//下面是主函数
int main()
{
BiTree T;
int depth, numberOfLeaves;
CreateBiTree(T);
depth= GetDepthOfBiTree(T);
numberOfLeaves=LeafCount(T);
printf("%d %d\n",depth,numberOfLeaves);
}
/* 请在这里填写答案 */
输入样例:
1 3 0 0 5 7 0 0 0
输出样例:
3 2
代码实现:
//求树的深度
int GetDepthOfBiTree ( BiTree T)
{
if (T == NULL) return 0;
int depth1 = GetDepthOfBiTree(T->lchild);
int depth2 = GetDepthOfBiTree(T->rchild);
if (depth1>depth2) return depth1 + 1;
else return depth2 + 1;
}
//求叶子节点数
int LeafCount(BiTree T)
{
if (T == NULL) return 0;
if (T->lchild == NULL && T->rchild == NULL)
return 1;
else return LeafCount(T->lchild) + LeafCount(T->rchild);
}
11X11-2二叉树求结点数
编写函数计算二叉树中的节点个数。二叉树采用二叉链表存储结构。
函数接口定义:
int NodeCountOfBiTree ( BiTree T);
其中 T是二叉树根节点的地址。
裁判测试程序样例:
//头文件包含
#include<stdlib.h>
#include<stdio.h>
#include<malloc.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define INFEASIBLE -2
typedef int Status;
//二叉链表存储结构定义
typedef int TElemType;
typedef struct BiTNode{
TElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
//创建二叉树各结点,输入0代表创建空树。
//采用递归的思想创建
//递归边界:空树如何创建呢:直接输入0;
//递归关系:非空树的创建问题,可以归结为先创建根节点,输入其数据域值;再创建左子树;最后创建右子树。左右子树递归即可完成创建!
Status CreateBiTree(BiTree &T){
TElemType e;
scanf("%d",&e);
if(e==0)T=NULL;
else{
T=(BiTree)malloc(sizeof(BiTNode));
if(!T)exit(OVERFLOW);
T->data=e;
CreateBiTree(T->lchild);
CreateBiTree(T->rchild);
}
return OK;
}
//下面是需要实现的函数的声明
int NodeCountOfBiTree ( BiTree T);
//下面是主函数
int main()
{
BiTree T;
int n;
CreateBiTree(T); //先序递归创建二叉树
n= NodeCountOfBiTree(T);
printf("%d",n);
return 0;
}
/* 请在这里填写答案 */
输入样例(注意输入0代表空子树):
1 3 0 0 5 3 0 0 0
输出样例:
4
代码实现:
int NodeCountOfBiTree ( BiTree T)
{
if (T == NULL) return 0;
else return NodeCountOfBiTree(T->lchild) + NodeCountOfBiTree(T->rchild) + 1;
}
12X12-1根据后序和中序遍历输出先序遍历
本题要求根据给定的一棵二叉树的后序遍历和中序遍历结果,输出该树的先序遍历结果。
输入格式:
第一行给出正整数N(≤30),是树中结点的个数。随后两行,每行给出N个整数,分别对应后序遍历和中序遍历结果,数字间以空格分隔。题目保证输入正确对应一棵二叉树。
输出格式:
在一行中输出Preorder:以及该树的先序遍历结果。数字间有1个空格,行末不得有多余空格。
输入样例:
7
2 3 1 5 7 6 4
1 2 3 4 5 6 7
输出样例:
Preorder: 4 1 3 2 6 5 7
代码实现:
/*
思路:使用递归方法,只要得出根节点、左子树和右子树即可
递归边界:输入的个数N<=0的时候返回
递归关系:先找到后序遍历数组中的最后一位在中序遍历中的位置,这就是根节点,根节点的左侧是左子树,右侧是右子树
然后按照递归的思想,继续分别构造左子树和右子树的根节点、左子树和右子树
*/
//头文件包含
#include<stdlib.h>
#include<stdio.h>
#include<malloc.h>
//函数状态码定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -1
#define INFEASIBLE -2
typedef int Status;
typedef int TElemType;
typedef struct BiNode
{
TElemType data;
struct BiNode *lchild, *rchild;
}BiNode, *BiTree;
BiTree Create(int *Post,int *In,int N)
{
//递归边界
if (N <= 0) return NULL;
//递归关系
int *p = In; //定义一个指针用来遍历中序序列
while (*p != *(Post + N -1))
p++; //找到后序序列的最后一位,即根节点
BiTree T;
T = (BiTree)malloc(sizeof(BiNode));
T->data = *p;
int len = p - In; //找到根节点位置左边有几位数字,即左子树
T->lchild = Create(Post,In,len);
T->rchild = Create(Post + len,p + 1,N - len -1);
return T;
}
void Print(BiTree T)
{
if (T)
{
printf(" %d",T->data);
Print(T->lchild);
Print(T->rchild);
}
return ;
}
int main()
{
int N;
int *Post, *In;
scanf("%d",&N);
Post = (int*)malloc(N * sizeof(int));
In = (int*)malloc(N * sizeof(int));
for (int i=0; i<N; i++)
scanf("%d",&Post[i]);
for (int i=0; i<N; i++)
scanf("%d",&In[i]);
BiTree T = Create(Post,In,N);
printf("Preorder:");
Print(T);
free(Post);
free(In);
return 0;
}
13X13-1家谱处理
人类学研究对于家族很感兴趣,于是研究人员搜集了一些家族的家谱进行研究。实验中,使用计算机处理家谱。为了实现这个目的,研究人员将家谱转换为文本文件。下面为家谱文本文件的实例:
John
Robert
Frank
Andrew
Nancy
David
家谱文本文件中,每一行包含一个人的名字。第一行中的名字是这个家族最早的祖先。家谱仅包含最早祖先的后代,而他们的丈夫或妻子不出现在家谱中。每个人的子女比父母多缩进2个空格。以上述家谱文本文件为例,John这个家族最早的祖先,他有两个子女Robert和Nancy,Robert有两个子女Frank和Andrew,Nancy只有一个子女David。
在实验中,研究人员还收集了家庭文件,并提取了家谱中有关两个人关系的陈述语句。下面为家谱中关系的陈述语句实例:
John is the parent of Robert
Robert is a sibling of Nancy
David is a descendant of Robert
研究人员需要判断每个陈述语句是真还是假,请编写程序帮助研究人员判断。
输入格式:
输入首先给出2个正整数N(2≤N≤100)和M(≤100),其中N为家谱中名字的数量,M为家谱中陈述语句的数量,输入的每行不超过70个字符。
名字的字符串由不超过10个英文字母组成。在家谱中的第一行给出的名字前没有缩进空格。家谱中的其他名字至少缩进2个空格,即他们是家谱中最早祖先(第一行给出的名字)的后代,且如果家谱中一个名字前缩进k个空格,则下一行中名字至多缩进k+2个空格。
在一个家谱中同样的名字不会出现两次,且家谱中没有出现的名字不会出现在陈述语句中。每句陈述语句格式如下,其中X和Y为家谱中的不同名字:
X is a child of Y
X is the parent of Y
X is a sibling of Y
X is a descendant of Y
X is an ancestor of Y
输出格式:
对于测试用例中的每句陈述语句,在一行中输出True,如果陈述为真,或False,如果陈述为假。
输入样例:
6 5
John
Robert
Frank
Andrew
Nancy
David
Robert is a child of John
Robert is an ancestor of Andrew
Robert is a sibling of Nancy
Nancy is the parent of Frank
John is a descendant of Andrew
输出样例:
True
True
True
False
False
代码实现:
#include <bits/stdc++.h>
using namespace std;
struct people
{
char name[15]; //结点名字
char father[15]; //双亲名字
int num; //空格数
}People[101];
void Gets(char temp[])
{
int i = 0;
scanf("%c",&temp[0]);
while (temp[i] != '\n')
{i++;scanf("%c",&temp[i]);}
temp[i] = '\0';
}
int main()
{
int N; //家谱中名字的数量
int M; //判断家谱关系的语句
char temp[75]; //用来临时存储输入的名字和空格,注意名字不超过10个字符,但是还有空格,要把数组开大一点
scanf("%d %d",&N,&M);
getchar(); //注意接下来输入的是字符串,要用getchar把回车吃掉
for (int i = 0; i < N; i++)
{
memset(temp,'0',sizeof(temp));
People[i].num = 0; //先把家谱数组中所有的名字初始化
Gets(temp);
int L = strlen(temp);
for (int j = 0; j < L; j++)
{
if (temp[j] == ' ')
People[i].num++; //记录空格的个数,以便于判断家族关系
else
{
strcpy(People[i].name, temp + j); //把空格之后的名字复制下来
break;
}
}
if (!People[i].num)
strcpy(People[i].father, "root"); //空格数为0则表示根
else
{
for (int k = i-1; k >= 0; k--) //从后往前寻找父节点
{
if (People[i].num > People[k].num)
{
strcpy(People[i].father,People[k].name);
break;
}
}
}
}
char a[15], b[15], c[15], d[15]; //用来存储输入判断语句,a和c分别对应前后两个人名,b表示等待判断的关系
char temp1[15], temp2[15];
for (int i = 0; i < M; i++)
{
scanf("%s %s %s %s %s %s",a,d,d,b,d,c);
if (b[0] == 'c')
{
//X是Y的孩子
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,a)) //首先在数组中找到a,然后判断c是否与a的father一致
{
if (!strcmp(People[k].father,c))
printf("True\n");
else printf("False\n");
break;
}
}
}
else if (b[0] == 'p')
{
//X是Y的双亲
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,c))
{
if (!strcmp(People[k].father,a))
printf("True\n");
else printf("False\n");
break;
}
}
}
else if (b[0] == 's')
{
//X是Y的兄弟
for (int k = 0; k < N; k++)
{
//寻找两个结点的父节点
if (!strcmp(People[k].name,a))
strcpy(temp1,People[k].father);
if (!strcmp(People[k].name,c))
strcpy(temp2,People[k].father);
}
if (!strcmp(temp1,temp2)) printf("True\n");
else printf("False\n");
}
else if (b[0] == 'd')
{
//X是Y的子孙
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,a))
strcpy(temp1,People[k].father);
}
while (strcmp(temp1,c) && strcmp(temp1,"root"))
{
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,temp1))
strcpy(temp1,People[k].father);
}
}
if (!strcmp(temp1,"root"))
printf("False\n");
else printf("True\n");
}
else if (b[0] == 'a')
{
//X是Y的祖先
for (int k = 0; k < N; k++ )
{
if (!strcmp(People[k].name,c))
strcpy(temp1,People[k].father);
}
while (strcmp(temp1,a) && strcmp(temp1,"root"))
{
for (int k = 0; k < N; k++)
{
if (!strcmp(People[k].name,temp1))
strcpy(temp1,People[k].father);
}
}
if (!strcmp(temp1,"root"))
printf("False\n");
else printf("True\n");
}
}
getchar();
return 0;
}
14X14-1哈夫曼编码
给定一段文字,如果我们统计出字母出现的频率,是可以根据哈夫曼算法给出一套编码,使得用此编码压缩原文可以得到最短的编码总长。然而哈夫曼编码并不是唯一的。例如对字符串"aaaxuaxz",容易得到字母 ‘a’、‘x’、‘u’、‘z’ 的出现频率对应为 4、2、1、1。我们可以设计编码 {‘a’=0, ‘x’=10, ‘u’=110, ‘z’=111},也可以用另一套 {‘a’=1, ‘x’=01, ‘u’=001, ‘z’=000},还可以用 {‘a’=0, ‘x’=11, ‘u’=100, ‘z’=101},三套编码都可以把原文压缩到 14 个字节。但是 {‘a’=0, ‘x’=01, ‘u’=011, ‘z’=001} 就不是哈夫曼编码,因为用这套编码压缩得到 00001011001001 后,解码的结果不唯一,“aaaxuaxz” 和 “aazuaxax” 都可以对应解码的结果。本题就请你判断任一套编码是否哈夫曼编码。
输入格式:
首先第一行给出一个正整数 N(2≤N≤63),随后第二行给出 N 个不重复的字符及其出现频率,格式如下:
c[1] f[1] c[2] f[2] ... c[N] f[N]
其中c[i]是集合{‘0’ - ‘9’, ‘a’ - ‘z’, ‘A’ - ‘Z’, ‘_’}中的字符;f[i]是c[i]的出现频率,为不超过 1000 的整数。再下一行给出一个正整数 M(≤1000),随后是 M 套待检的编码。每套编码占 N 行,格式为:
c[i] code[i]
其中c[i]是第i个字符;code[i]是不超过63个’0’和’1’的非空字符串。
输出格式:
对每套待检编码,如果是正确的哈夫曼编码,就在一行中输出"Yes",否则输出"No"。
注意:最优编码并不一定通过哈夫曼算法得到。任何能压缩到最优长度的前缀编码都应被判为正确。
输入样例:
7
A 1 B 1 C 1 D 3 E 3 F 6 G 6
4
A 00000
B 00001
C 0001
D 001
E 01
F 10
G 11
A 01010
B 01011
C 0100
D 011
E 10
F 11
G 00
A 000
B 001
C 010
D 011
E 100
F 101
G 110
A 00000
B 00001
C 0001
D 001
E 00
F 10
G 11
输出样例:
Yes
Yes
No
No
代码实现:
/*
思路:对于给定的字符及其出现的频率,先构建对应霍夫曼树,然后求出对应霍夫曼编码的最大路径长度。
判断是否是正确的霍夫曼编码只要满足前缀规则,并且每一个字符的最大路径长度与最先构建的霍夫曼编码所求出来的长度相等即可。
*/
#include <bits/stdc++.h>
using namespace std;
typedef int Status;
typedef struct HTNode
{
unsigned int weight;
unsigned int parent, lchild, rchild;
} HTNode, *HuffmanTree;
typedef char* *HuffmanCode;
void Select(HuffmanTree &HT, int index, int &s1, int &s2) //在HT数组前index个中选择parent为0,并且权值最小的两个节点,其序号用s1,s2带回
{
int minvalue1, minvalue2;
s1 = s2 = index;
minvalue1 = minvalue2 = 100000; //将最小值设置成无穷大,方便以后比较替换
for(int i = 1; i < index; ++i)
{
if(HT[i].parent == 0)
{
if(HT[i].weight <= minvalue1)
{
minvalue2 = minvalue1;
minvalue1 = HT[i].weight;
s2 = s1;
s1 = i;
}
else if(HT[i].weight <= minvalue2)
{
s2 = i;
minvalue2 = HT[i].weight;
}
}
}
}
int HuffmanCoding(int *w, int n) //已知权值和总数量,构造霍夫曼树,求出编码,并且返回最短路径长度
{
int m = 2 * n - 1;
HuffmanTree HT = (HTNode *)malloc(sizeof(HTNode) * (m + 1));
HuffmanTree p = HT + 1;
w++;
//初始化霍夫曼树
for(int i = 1; i <= n; ++i, ++w, ++p)
{
p->weight = *w;
p->parent = p->lchild = p->rchild = 0;
}
for(int i = n + 1; i <= m; ++i, ++p)
p->weight = p->parent = p->lchild = p->rchild = 0;
p = HT + n + 1;
for(int i = n + 1; i <= m; ++i, ++p)
{
int s1, s2;
Select(HT, i, s1, s2);
p->weight = HT[s1].weight + HT[s2].weight;
p->lchild = s1, p->rchild = s2;
HT[s1].parent = HT[s2].parent = i;
}
int pathnum[n + 1]; //求出每个字符的最大路径长度
for(int i = 1; i <= n; ++i)
{
int length = 0;
for(int cpos = i, ppos = HT[i].parent; ppos != 0; cpos = ppos, ppos = HT[ppos].parent)
length++;
pathnum[i] = length;
}
int min_length = 0;
for(int i = 1; i <= n; i++)
min_length += (pathnum[i] * HT[i].weight);
return min_length;
}
int isUncertain(char Codes[][65], int n) //判断是否符合前缀规则
{
for(int i = 0; i < n; ++i)
for(int j = i + 1; j < n; ++j)
{
int length = strlen(Codes[i]) > strlen(Codes[j]) ? strlen(Codes[j]):strlen(Codes[i]);
int k;
for(k = 0; k < length; ++k)
if(Codes[i][k] != Codes[j][k])
break;
if(k == length)
return 1;
}
return 0;
}
int GetLen(char Codes[][65], int *w, int n)
{
int len = 0;
for(int i = 0; i < n; ++i)
{
int length = strlen(Codes[i]);
len += (length * w[i + 1]);
}
return len;
}
int main()
{
int N, M, W[70];
char ch;
scanf("%d", &N);
getchar();
for(int i =1; i <= N; ++i) //输入字符以及出现的频率,注意空格也是一个字符,在末尾特殊处理
{
if(i <= N - 1)
scanf("%c %d ", &ch, &W[i]);
else
scanf("%c %d", &ch, &W[i]);
}
int min_length = HuffmanCoding(W, N);
scanf("%d", &M);
for(int i = 0; i < M; ++i)
{
char Codes[65][65]; //用来存放等待判断的编码
for(int i = 0; i < N; ++i)
{
getchar(); //吃掉每一行的回车
scanf("%c %s", &ch, Codes[i]);
}
if(isUncertain(Codes, N)) //
printf("No\n");
else
{
if(min_length == GetLen(Codes, W, N))
printf("Yes\n");
else
printf("No\n");
}
}
}
15X15-1邻接表创建无向图
采用邻接表创建无向图G ,依次输出各顶点的度。
输入格式:
输入第一行中给出2个整数i(0<i≤10),j(j≥0),分别为图G的顶点数和边数。 输入第二行为顶点的信息,每个顶点只能用一个字符表示。 依次输入j行,每行输入一条边依附的顶点。
输出格式:
依次输出各顶点的度,行末没有最后的空格。
输入样例:
5 7
ABCDE
AB
AD
BC
BE
CD
CE
DE
输出样例:
2 3 3 3 3
代码实现:
/*
思路:使用一个结构体类型的数组,一个存放顶点字符,一个边的信息。
顶点按照输入顺序直接存放起来即可。
边要读取两个字符,第一个字符是起点,用来定位到对应顶点;另一个用来存终点下标
*/
#include <bits/stdc++.h>
using namespace std;
#define OK 1;
#define ERROR 0;
typedef int Status;
typedef struct VerNode
{
char ch;
struct VerNode *next;
}VerNode;
typedef struct
{
char V; //顶点
VerNode *start; //存放边的链表
int degree; //顶点的度数
}UDirGraph;
Status Create(UDirGraph graph[],int i,int j)
{
if (i < 0 || j < 0) return ERROR;
for (int k=0;k<i;k++)
{
graph[k].V = '0';
graph[k].start = NULL;
graph[k].degree = 0;
}
return OK;
}
int main()
{
int i, j;
char ch1, ch2;
scanf("%d %d",&i,&j);
getchar();
UDirGraph graph[i+1];
Create(graph,i,j);
for (int k=0; k<i; k++)
scanf("%c",&graph[k].V); //注意不要忘记&
graph[i].V = '\0';
getchar();
for (int k=0; k<j; k++)
{
scanf("%c%c",&ch1,&ch2);
getchar();
int n = 0;
int m = 0;
for (m=0; m<i; m++)
{
if (ch1 == graph[m].V)
{
graph[m].degree++;
for (n=0; n<i; n++)
if (ch2 == graph[n].V)
graph[n].degree++;
}
// printf("==%d==\n",graph[m].degree);
}
}
for (int k=0;k<i;k++)
{
if (k==0) printf("%d",graph[k].degree);
else printf(" %d",graph[k].degree);
}
}
16X16-1邻接矩阵存储图的深度优先遍历
试实现邻接矩阵存储图的深度优先遍历。
函数接口定义:
void DFS( MGraph Graph, Vertex V, void (*Visit)(Vertex) );
其中MGraph是邻接矩阵存储的图,定义如下:
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
WeightType G[MaxVertexNum][MaxVertexNum]; /* 邻接矩阵 */
};
typedef PtrToGNode MGraph; /* 以邻接矩阵存储的图类型 */
函数DFS应从第V个顶点出发递归地深度优先遍历图Graph,遍历时用裁判定义的函数Visit访问每个顶点。当访问邻接点时,要求按序号递增的顺序。题目保证V是图中的合法顶点。
裁判测试程序样例:
#include <stdio.h>
typedef enum {false, true} bool;
#define MaxVertexNum 10 /* 最大顶点数设为10 */
#define INFINITY 65535 /* ∞设为双字节无符号整数的最大值65535*/
typedef int Vertex; /* 用顶点下标表示顶点,为整型 */
typedef int WeightType; /* 边的权值设为整型 */
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
WeightType G[MaxVertexNum][MaxVertexNum]; /* 邻接矩阵 */
};
typedef PtrToGNode MGraph; /* 以邻接矩阵存储的图类型 */
bool Visited[MaxVertexNum]; /* 顶点的访问标记 */
MGraph CreateGraph(); /* 创建图并且将Visited初始化为false;裁判实现,细节不表 */
void Visit( Vertex V )
{
printf(" %d", V);
}
void DFS( MGraph Graph, Vertex V, void (*Visit)(Vertex) );
int main()
{
MGraph G;
Vertex V;
G = CreateGraph();
scanf("%d", &V);
printf("DFS from %d:", V);
DFS(G, V, Visit);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:给定图如下
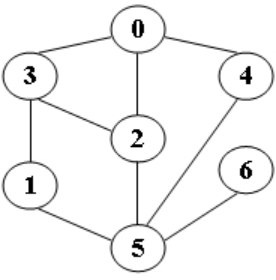
5
输出样例:
DFS from 5: 5 1 3 0 2 4 6
代码实现:
void DFS( MGraph Graph, Vertex V, void (*Visit)(Vertex) )
{
int w;
Visited[V] = true; //标记为true,说明已经访问过该点
Visit(V);
for (w = 0; w < Graph->Nv; w++)
{
if (Graph->G[V][w] == 1 && !Visited[w]) //有节点而且没有被访问过的情况
{
DFS(Graph,w,Visit);
}
}
return ;
}
16X16-2邻接表存储图的广度优先遍历
试实现邻接表存储图的广度优先遍历。
函数接口定义:
void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) );
其中LGraph是邻接表存储的图,定义如下:
/* 邻接点的定义 */
typedef struct AdjVNode *PtrToAdjVNode;
struct AdjVNode{
Vertex AdjV; /* 邻接点下标 */
PtrToAdjVNode Next; /* 指向下一个邻接点的指针 */
};
/* 顶点表头结点的定义 */
typedef struct Vnode{
PtrToAdjVNode FirstEdge; /* 边表头指针 */
} AdjList[MaxVertexNum]; /* AdjList是邻接表类型 */
/* 图结点的定义 */
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
AdjList G; /* 邻接表 */
};
typedef PtrToGNode LGraph; /* 以邻接表方式存储的图类型 */
函数BFS应从第S个顶点出发对邻接表存储的图Graph进行广度优先搜索,遍历时用裁判定义的函数Visit访问每个顶点。当访问邻接点时,要求按邻接表顺序访问。题目保证S是图中的合法顶点。
裁判测试程序样例:
#include <stdio.h>
typedef enum {false, true} bool;
#define MaxVertexNum 10 /* 最大顶点数设为10 */
typedef int Vertex; /* 用顶点下标表示顶点,为整型 */
/* 邻接点的定义 */
typedef struct AdjVNode *PtrToAdjVNode;
struct AdjVNode{
Vertex AdjV; /* 邻接点下标 */
PtrToAdjVNode Next; /* 指向下一个邻接点的指针 */
};
/* 顶点表头结点的定义 */
typedef struct Vnode{
PtrToAdjVNode FirstEdge; /* 边表头指针 */
} AdjList[MaxVertexNum]; /* AdjList是邻接表类型 */
/* 图结点的定义 */
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* 顶点数 */
int Ne; /* 边数 */
AdjList G; /* 邻接表 */
};
typedef PtrToGNode LGraph; /* 以邻接表方式存储的图类型 */
bool Visited[MaxVertexNum]; /* 顶点的访问标记 */
LGraph CreateGraph(); /* 创建图并且将Visited初始化为false;裁判实现,细节不表 */
void Visit( Vertex V )
{
printf(" %d", V);
}
void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) );
int main()
{
LGraph G;
Vertex S;
G = CreateGraph();
scanf("%d", &S);
printf("BFS from %d:", S);
BFS(G, S, Visit);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:给定图如下
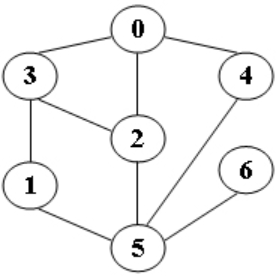
2
输出样例:
BFS from 2: 2 0 3 5 4 1 6
代码实现:
/*
思路:设置一个数组队列,先把这一行读取到的结点存放到队列中一直到NULL,只要队列中有元素就往后取出一个结点访问。
同时更新标记数组Visited的值来避免结点的重复访问。
*/
void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) )
{
int len = Graph->Nv;
int Queue[len + 1];
int v;
PtrToAdjVNode p = NULL;
int i = 0;
int j = 0;
Queue[i++] = S;
Visited[S] = true;
while (j != i)
{
v = Queue[j++];
Visit(v);
p = Graph->G[v].FirstEdge;
while (p)
{
if (!Visited[p->AdjV])
{
Queue[i++] = p->AdjV;
Visited[p->AdjV] = true;
}
p = p->Next;
}
}
}
16X16-3畅通工程之最低成本建设问题
某地区经过对城镇交通状况的调查,得到现有城镇间快速道路的统计数据,并提出“畅通工程”的目标:使整个地区任何两个城镇间都可以实现快速交通(但不一定有直接的快速道路相连,只要互相间接通过快速路可达即可)。现得到城镇道路统计表,表中列出了有可能建设成快速路的若干条道路的成本,求畅通工程需要的最低成本。
输入格式:
输入的第一行给出城镇数目N (1<N≤1000)和候选道路数目M≤3N;随后的M行,每行给出3个正整数,分别是该条道路直接连通的两个城镇的编号(从1编号到N)以及该道路改建的预算成本。
输出格式:
输出畅通工程需要的最低成本。如果输入数据不足以保证畅通,则输出“Impossible”。
输入样例1:
6 15
1 2 5
1 3 3
1 4 7
1 5 4
1 6 2
2 3 4
2 4 6
2 5 2
2 6 6
3 4 6
3 5 1
3 6 1
4 5 10
4 6 8
5 6 3
输出样例1:
12
输入样例2:
5 4
1 2 1
2 3 2
3 1 3
4 5 4
输出样例2:
Impossible
代码实现:
/*
思路:定义一个结构体,里面的变量包括起点,终点,权值
定义一个标记数组
输入完成信息后根据权值把所有的元素排序,从最小的开始挑选能够建设的路
需要满足的条件:起点和终点不能同时在已经挑选的结点里面。用标记变量来确定是否已经被挑选
判断连通分量的时候看标记变量的大小,若只有一个连通分量,标记变量只有两个为1,其余都大于1
*/
#include <bits/stdc++.h>
using namespace std;
typedef struct Info
{
int start;
int last;
int value;
}Info;
void Swap(Info &i,Info &j);
int main()
{
int N,M; //结点个数以及候选道路数目
scanf("%d %d",&N,&M);
Info info[M*2];
int flag[N*2];
for (int i=1;i<=N;i++)
flag[i] = 0; //初始化标记数组
//输入并存储信息
for (int i=0;i<M;i++)
{
scanf("%d %d %d",&info[i].start,&info[i].last,&info[i].value);
flag[info[i].start] = 0;
flag[info[i].last] = 0;
}
//将所有信息进行排序
for (int i=0;i<M;i++)
{
for (int j=i+1;j<M;j++)
{
if (info[i].value > info[j].value)
{
Swap(info[i],info[j]);
}
}
}
//挑选成本小的路
int sum = 0;
int num = 0;
for (int i=0; i<M; i++)
{
//if (num == N-1) break;
if(flag[info[i].start] && flag[info[i].last]) //两个同时都已经在的情况
{
continue;
}
else
{
sum += info[i].value;
num++;
flag[info[i].start]++;
flag[info[i].last]++;
}
}
int con = 0;
for (int i=1; i<=N; i++)
{
if (flag[i] == 0)
{
con++;
break;
}
}
if (num != N-1 ||con) printf("Impossible\n");
else printf("%d\n",sum);
}
void Swap(Info &i,Info &j)
{
int temp;
temp = i.start;
i.start = j.start;
j.start = temp;
temp = i.last;
i.last = j.last;
j.last = temp;
temp = i.value;
i.value = j.value;
j.value = temp;
}
18X18-1城市间紧急救援
作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图。在地图上显示有多个分散的城市和一些连接城市的快速道路。每个城市的救援队数量和每一条连接两个城市的快速道路长度都标在地图上。当其他城市有紧急求助电话给你的时候,你的任务是带领你的救援队尽快赶往事发地,同时,一路上召集尽可能多的救援队。
输入格式:
输入第一行给出4个正整数N、M、S、D,其中N(2≤N≤500)是城市的个数,顺便假设城市的编号为0 ~ (N−1);M是快速道路的条数;S是出发地的城市编号;D是目的地的城市编号。
第二行给出N个正整数,其中第i个数是第i个城市的救援队的数目,数字间以空格分隔。随后的M行中,每行给出一条快速道路的信息,分别是:城市1、城市2、快速道路的长度,中间用空格分开,数字均为整数且不超过500。输入保证救援可行且最优解唯一。
输出格式:
第一行输出最短路径的条数和能够召集的最多的救援队数量。第二行输出从S到D的路径中经过的城市编号。数字间以空格分隔,输出结尾不能有多余空格。
输入样例:
4 5 0 3
20 30 40 10
0 1 1
1 3 2
0 3 3
0 2 2
2 3 2
输出样例:
2 60
0 1 3
代码实现:
#include<bits/stdc++.h>
using namespace std;
#define INF 1000000
int a[1001][1001];
int cnt[1001],exs[1001]={0},cf[1001],ccf[1001],pre[1001];
//最短路径条数,各城市是否经过,各城市的救援队数量,到达该城市时所召集的所有救援队数量,到达该城市前经过的城市编号
int n,m,s,d;
int Dijkstra()
{
cnt[s] = 1;//开始时路径条数为1
exs[s] = 1;//当前在出发城市
for(int i = 0; i<n; i++)
{
int mm = INF,f = -1;
for(int j = 0; j<n; j++)
{
if(exs[j] == 0 && a[s][j] < mm) //寻找下一个距离最短的城市
{
mm = a[s][j];
f = j;//做好下一城市编号的标记
}
}
if(f == -1)break;//与其他未经过的城市不连通,退出循环
else exs[f] = 1;//到达下一城市
for(int j = 0; j<n; j++)
{
if(exs[j] == 0 && a[s][j] > a[s][f] + a[f][j]) //到达某一城市的最短路径
{
a[s][j] = a[s][f] + a[f][j];//最短路径更新
pre[j] = f;//记录上一个城市编号
cnt[j] = cnt[f];//拷贝到达上一个城市时的最短路径条数
ccf[j] = ccf[f] + cf[j];//到达某城市召集的全部救援队数量
}
else if(exs[j] == 0&&a[s][j] == a[s][f] + a[f][j]) //发现其他的最短路径
{
cnt[j] = cnt[j] + cnt[f];//更新到达当前城市时的最短路径条数
if(ccf[j] < ccf[f] + cf[j]) //最多救援队数量更新
{
pre[j] = f;//记录所经过的上一个城市编号
ccf[j] = ccf[f] + cf[j];//更新救援队总数
}
}
}
}
}
int main()
{
cin>>n>>m>>s>>d;
for(int i = 0;i<n;i++){
cin>>cf[i];
ccf[i] = cf[i];
cnt[i] = 1;
}
for(int i = 0;i<n;i++){
for(int j = 0;j<n;j++){
if(i != j) a[i][j] = a[j][i] = INF;//初始化(双向图)
}
}
for(int i = 0;i<m;i++){
int q,w,e;
cin>>q>>w>>e;
a[q][w] = a[w][q] = e;
}
Dijkstra();
cout<<cnt[d]<<" "<<ccf[d]+cf[s]<<endl;
int road[1001];
int x = 0,t = d;
while(pre[t] != 0)
{//所经历的城市的从后往前的顺序
road[x++]=pre[t];
t=pre[t];
}
cout<<s;//出发地
for(int i = x-1;i >= 0;i--)
cout<<" "<<road[i];
cout<<" "<<d;//目的地
}
19X19-1二分查找
本题要求实现二分查找算法。
函数接口定义:
Position BinarySearch( List L, ElementType X );
其中List结构定义如下:
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
L是用户传入的一个线性表,其中ElementType元素可以通过>、==、<进行比较,并且题目保证传入的数据是递增有序的。函数BinarySearch要查找X在Data中的位置,即数组下标(注意:元素从下标1开始存储)。找到则返回下标,否则返回一个特殊的失败标记NotFound。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 10
#define NotFound 0
typedef int ElementType;
typedef int Position;
typedef struct LNode *List;
struct LNode {
ElementType Data[MAXSIZE];
Position Last; /* 保存线性表中最后一个元素的位置 */
};
List ReadInput(); /* 裁判实现,细节不表。元素从下标1开始存储 */
Position BinarySearch( List L, ElementType X );
int main()
{
List L;
ElementType X;
Position P;
L = ReadInput();
scanf("%d", &X);
P = BinarySearch( L, X );
printf("%d\n", P);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例1:
5
12 31 55 89 101
31
输出样例1:
2
输入样例2:
3
26 78 233
31
输出样例2:
0
代码实现:
Position BinarySearch( List L, ElementType X )
{
if (L == NULL) return NotFound;
int left = 1; //最左边位置
int right = L->Last; //最右边位置
int flag = 0;
int mid;
while (left <= right)
{
mid = (left + right)/2; //中间位置
if (L->Data[mid] == X) {flag = 1;return mid;}
else if (L->Data[mid] < X) left = mid + 1;
else right = mid - 1;
}
if (!flag) return NotFound;
}
19X19-2两个有序序列的中位数
已知有两个等长的非降序序列S1, S2, 设计函数求S1与S2并集的中位数。有序序列A0,A1,⋯,AN−1的中位数指A(N−1)/2的值,即第⌊(N+1)/2⌋个数(A0为第1个数)。
输入格式:
输入分三行。第一行给出序列的公共长度N(0<N≤100000),随后每行输入一个序列的信息,即N个非降序排列的整数。数字用空格间隔。
输出格式:
在一行中输出两个输入序列的并集序列的中位数。
输入样例1:
5
1 3 5 7 9
2 3 4 5 6
输出样例1:
4
输入样例2:
6
-100 -10 1 1 1 1
-50 0 2 3 4 5
输出样例2:
1
代码实现:
#include <bits/stdc++.h>
using namespace std;
int main(){
int str[100001],arr[100001];
int n;scanf("%d",&n);
for(int i=0;i<n;i++) scanf("%d",&str[i]);
for(int i=0;i<n;i++) scanf("%d",&arr[i]);
//中位数在大的左边 小的右边
int start1=0,end1=n-1,mid1=(n-1)/2;
int start2=0,end2=n-1,mid2=(n-1)/2;
int mid;int flag=0;
while(start1!=end1&&start2!=end2){
if(str[mid1]==arr[mid2]) {
mid=str[mid1];
flag=1;
break;
}
else if(str[mid1]>arr[mid2]){
if((end1-start1)%2==0&&(end2-start2)%2==0){
end1=mid1;
start2=mid2;
}
else{
end1=mid1;
start2=mid2+1;
}
mid1=(start1+end1)/2;
mid2=(start2+end2)/2;
}
else{
if((end1-start1)%2==0&&(end2-start2)%2==0){
start1=mid1;
end2=mid2;
}
else {
start1=mid1+1;
end2=mid2;
}
mid1=(start1+end1)/2;
mid2=(start2+end2)/2;
}
}
if(!flag) {
if(start1==end1) {
int a=str[start1],b=arr[end2];
if(a>b) mid=b;
else mid=a;
}
else {
int a=arr[start2],b=str[end1];
if(a>b) mid=b;
else mid=a;
}
}
printf("%d\n",mid);
}
20X20-1是否二叉搜索树
题要求实现函数,判断给定二叉树是否二叉搜索树。
函数接口定义:
bool IsBST ( BinTree T );
其中BinTree结构定义如下:
typedef struct TNode *Position;
typedef Position BinTree;
struct TNode{
ElementType Data;
BinTree Left;
BinTree Right;
};
函数IsBST须判断给定的T是否二叉搜索树,即满足如下定义的二叉树:
定义:一个二叉搜索树是一棵二叉树,它可以为空。如果不为空,它将满足以下性质:
非空左子树的所有键值小于其根结点的键值。
非空右子树的所有键值大于其根结点的键值。
左、右子树都是二叉搜索树。
如果T是二叉搜索树,则函数返回true,否则返回false。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
typedef enum { false, true } bool;
typedef int ElementType;
typedef struct TNode *Position;
typedef Position BinTree;
struct TNode{
ElementType Data;
BinTree Left;
BinTree Right;
};
BinTree BuildTree(); /* 由裁判实现,细节不表 */
bool IsBST ( BinTree T );
int main()
{
BinTree T;
T = BuildTree();
if ( IsBST(T) ) printf("Yes\n");
else printf("No\n");
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例1:如下图

输出样例1:
Yes
输入样例2:如下图
输出样例2:
No
代码实现:
int a[101];
int i = 0;
bool IsBST ( BinTree T )
{//中序遍历,得到的结果是从小到大排列,只要满足左边小于右边即可
if (T != NULL)
{
IsBST(T->Left);
a[i++] = T->Data;
IsBST(T->Right);
}
for (int j=0;j<i;j++)
{
if (a[j-1] >= a[j])
return false;
}
return true;
}
21X21-1分离链接法的删除操作函数
试实现分离链接法的删除操作函数。
函数接口定义:
bool Delete( HashTable H, ElementType Key );
其中HashTable是分离链接散列表,定义如下:
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
typedef struct TblNode *HashTable; /* 散列表类型 */
struct TblNode { /* 散列表结点定义 */
int TableSize; /* 表的最大长度 */
List Heads; /* 指向链表头结点的数组 */
};
函数Delete应根据裁判定义的散列函数Hash( Key, H->TableSize )从散列表H中查到Key的位置并删除之,然后输出一行文字:Key is deleted from list Heads[i],其中Key是传入的被删除的关键词,i是Key所在的链表的编号;最后返回true。如果Key不存在,则返回false。
裁判测试程序样例:
#include <stdio.h>
#include <string.h>
#define KEYLENGTH 15 /* 关键词字符串的最大长度 */
typedef char ElementType[KEYLENGTH+1]; /* 关键词类型用字符串 */
typedef int Index; /* 散列地址类型 */
typedef enum {false, true} bool;
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
typedef struct TblNode *HashTable; /* 散列表类型 */
struct TblNode { /* 散列表结点定义 */
int TableSize; /* 表的最大长度 */
List Heads; /* 指向链表头结点的数组 */
};
Index Hash( ElementType Key, int TableSize )
{
return (Key[0]-'a')%TableSize;
}
HashTable BuildTable(); /* 裁判实现,细节不表 */
bool Delete( HashTable H, ElementType Key );
int main()
{
HashTable H;
ElementType Key;
H = BuildTable();
scanf("%s", Key);
if (Delete(H, Key) == false)
printf("ERROR: %s is not found\n", Key);
if (Delete(H, Key) == true)
printf("Are you kidding me?\n");
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例1:散列表如下图

able
输出样例1:
able is deleted from list Heads[0]
输入样例2:散列表如样例1图
date
输出样例2:
ERROR: date is not found
代码实现:
bool Delete( HashTable H, ElementType Key )
{
int w = Hash(Key,H->TableSize); //题目已知的函数,返回Key对表长的求余,即Key在数组中的下标
if (H->Heads[w].Next == NULL) return false; //Key应该在的下标处没有元素,直接返回没找到
PtrToLNode p = H->Heads[w].Next;
PtrToLNode q = p;
while (strcmp(Key,p->Data) && p->Next != NULL)
{
q = p; //记录要删除的结点的上一位
p = p->Next;
}
if (!strcmp(Key,p->Data))
{
printf("%s is deleted from list Heads[%d]",Key,w);
q = p->Next; //删除后的连接结点
free(p); //释放已经删除结点的空间
return true;
}
return false;
}
21X21-2直接插入排序
本题要求实现直接插入排序函数,待排序列的长度1<=n<=1000。
函数接口定义:
void InsertSort(SqList L);
其中L是待排序表,使排序后的数据从小到大排列。
类型定义:
typedef int KeyType;
typedef struct {
KeyType *elem; /*elem[0]一般作哨兵或缓冲区*/
int Length;
}SqList;
裁判测试程序样例:
#include<stdio.h>
#include<stdlib.h>
typedef int KeyType;
typedef struct {
KeyType *elem; /*elem[0]一般作哨兵或缓冲区*/
int Length;
}SqList;
void CreatSqList(SqList *L);/*待排序列建立,由裁判实现,细节不表*/
void InsertSort(SqList L);
int main()
{
SqList L;
int i;
CreatSqList(&L);
InsertSort(L);
for(i=1;i<=L.Length;i++)
{
printf("%d ",L.elem[i]);
}
return 0;
}
/*你的代码将被嵌在这里 */
输入样例:
第一行整数表示参与排序的关键字个数。第二行是关键字值 例如:
10
5 2 4 1 8 9 10 12 3 6
输出样例:
输出由小到大的有序序列,每一个关键字之间由空格隔开,最后一个关键字后有一个空格。
1 2 3 4 5 6 8 9 10 12
代码实现:
void InsertSort(SqList L)
{//先排第一个,然后第二个插入到前边的序列,第三个插入,以此类推。
int i,j;
for (i = 1; i <= L.Length; i++)
{
L.elem[0] = L.elem[i];
for (j = i; L.elem[j-1]>L.elem[0] && j > 0; j--)
{
L.elem[j] = L.elem[j-1];
L.elem[j-1] = L.elem[0];
}
}
}