先打个广告,HERA已开源:https://github.com/XiaoMi/mone,欢迎对云原生技术/研发效能感兴趣的小伙伴加入(Fork、Star)我们。也可以关注我们微信公众号:

HERA是什么?
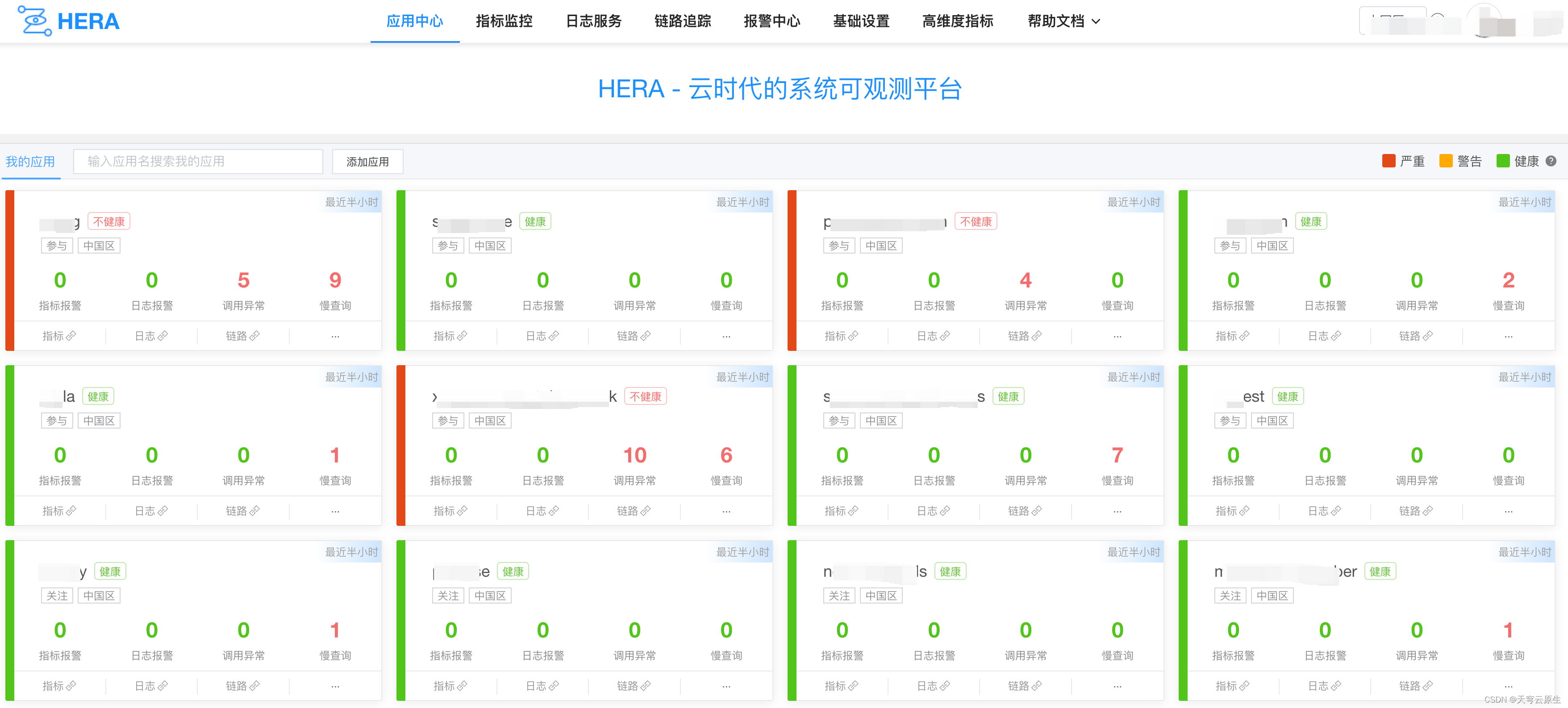
HERA是由中国区研发效能团队开源的一款应用性能观测平台(APM)。以应用为核心,集指标监控、链路追踪、日志、报警于一身,并实现了metrics->tracing->logging的串联和联动,hera还提供应用健康状态列表、应用指标看板、接口大盘、应用大盘、网关大盘等内容丰富的监测看板,以及简洁明了的可视化明文报警,让用户准确、高效定位故障(在这里我们可以发起一个挑战:20秒定位线上问题故障)。
核心特性
准:可用性指标
报警多了基本等同于无效报警,报警的准确性尤为重要。没有人能比自身的业务错误码更了解请求的正确性,我们在业务可用性指标中融合进业务错误码的识别能力,让业务告警只需聚焦于这一个指标即可。
快:metrics-tracing-logging联动
基于traceId打通报警->指标->链路->日志的闭环联动,大幅提升用户定位问题效率
拥抱云原生
遵循Opentracing标准,集成Opentelemetry、Grafana、Prometheus、ES等多个CNCF下明星级产品。同时Hera深度适配K8S,并提供基于K8S一键部署能力。
经济:<1%存储成本,满足99.9%的tracing诉求
有异常的请求 / 总请求数 就是我们降本的依据。需要查trace时往往是面向异常场景,所以我们做到异常trace的识别,并保证trace的存储,对于正常的trace我们采取抽样策略,保证高效的同时兼顾经济成本。
企业级可观测产品
过硬的可观测能力:自身具备完备的指标、链路、日志、告警能力;
高效的企业集成能力:有完善的权限、应用管理机制,方便用户快速在企业内部快速落地并集成自身的账号、CI/CD系统等,还可快速对接企业办公软件实现告警触达;
稳定、经济:核心链路做好解耦方便每个环节快速扩缩容,针对大数据量的tracing,我们实现了尾采样,只需5%的存储成本即可满足99.9%的tracing诉求。
我们为什么做HERA?
内部业务系统1-5-10遇到严重的挑战:服务质量指标缺失、接入效率低、链路无法串联、工程依赖复杂、排查难度高、依赖经验丰富的高级工程师、定位周期远大于5分钟。
基于这样的背景我们着手落地HERA平台,落地时我们首先考虑的是串联,联通性是提效的核心要素;其次是"准",你的系统只有尝试去理解业务调用,才能准确预警。基于这些考虑我们快速落地了HERA平台,并在内部经历多轮大促考验,深得业务好评。
产品介绍
首页
指标监控
Dashboard

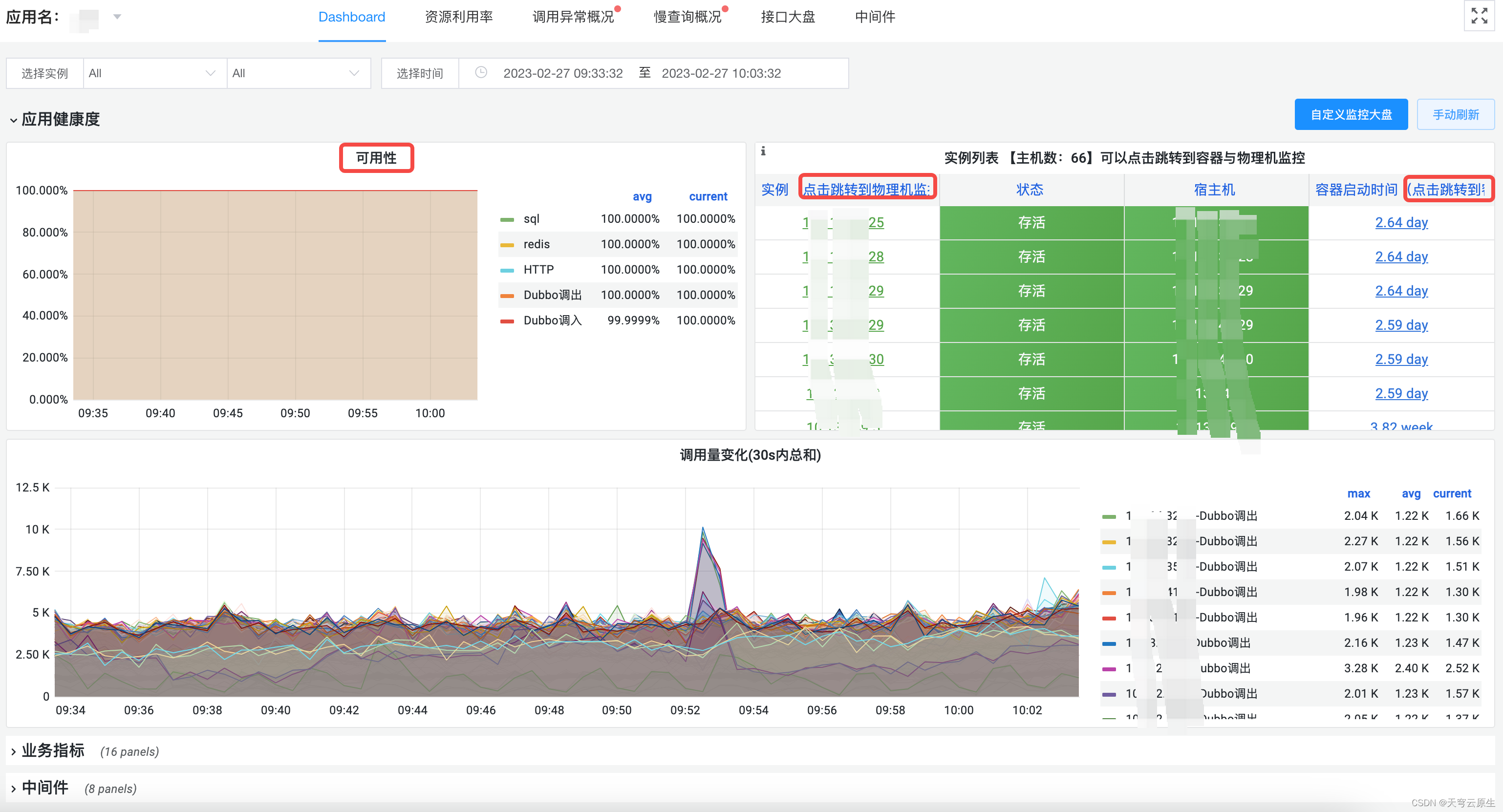
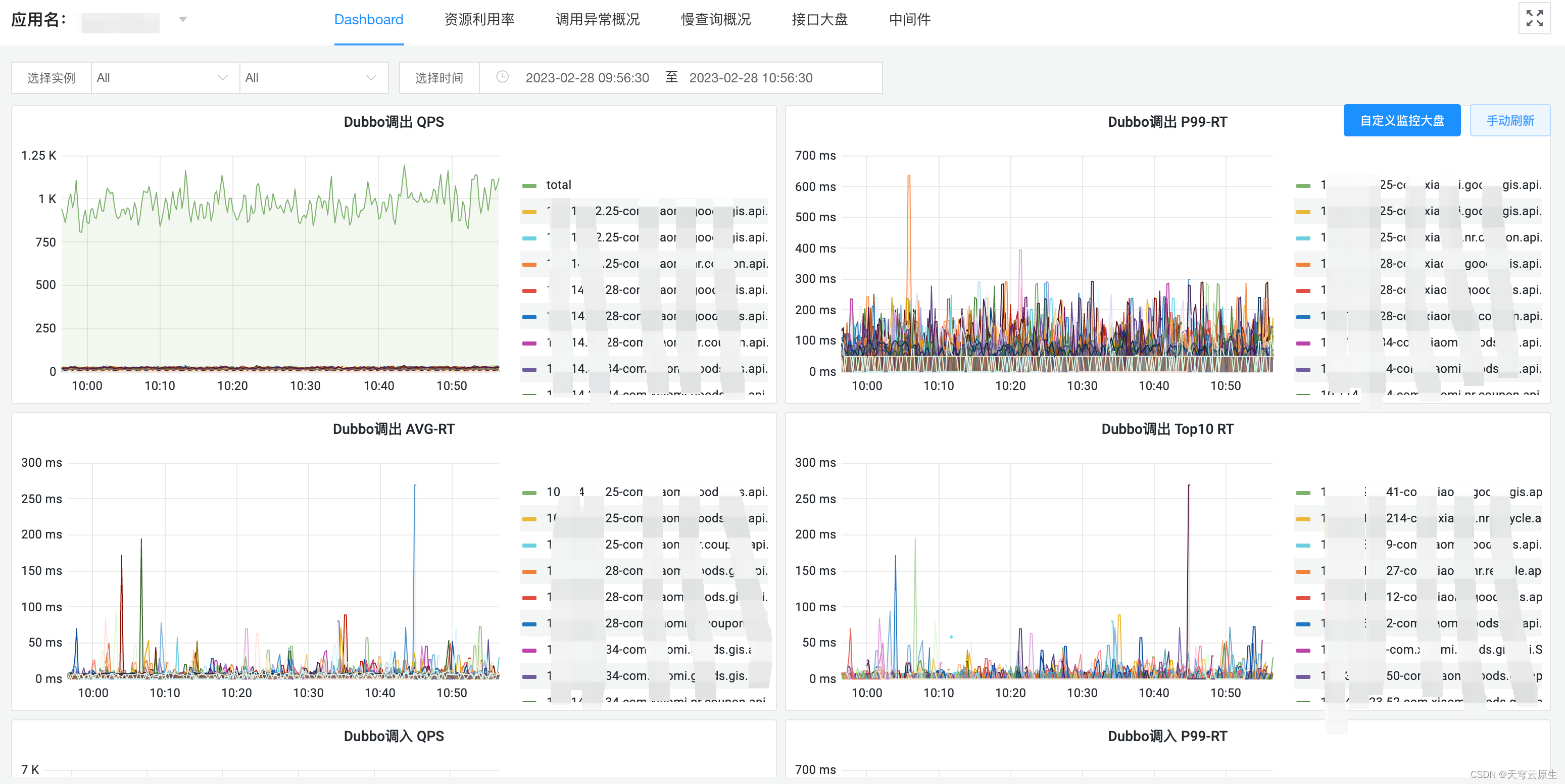
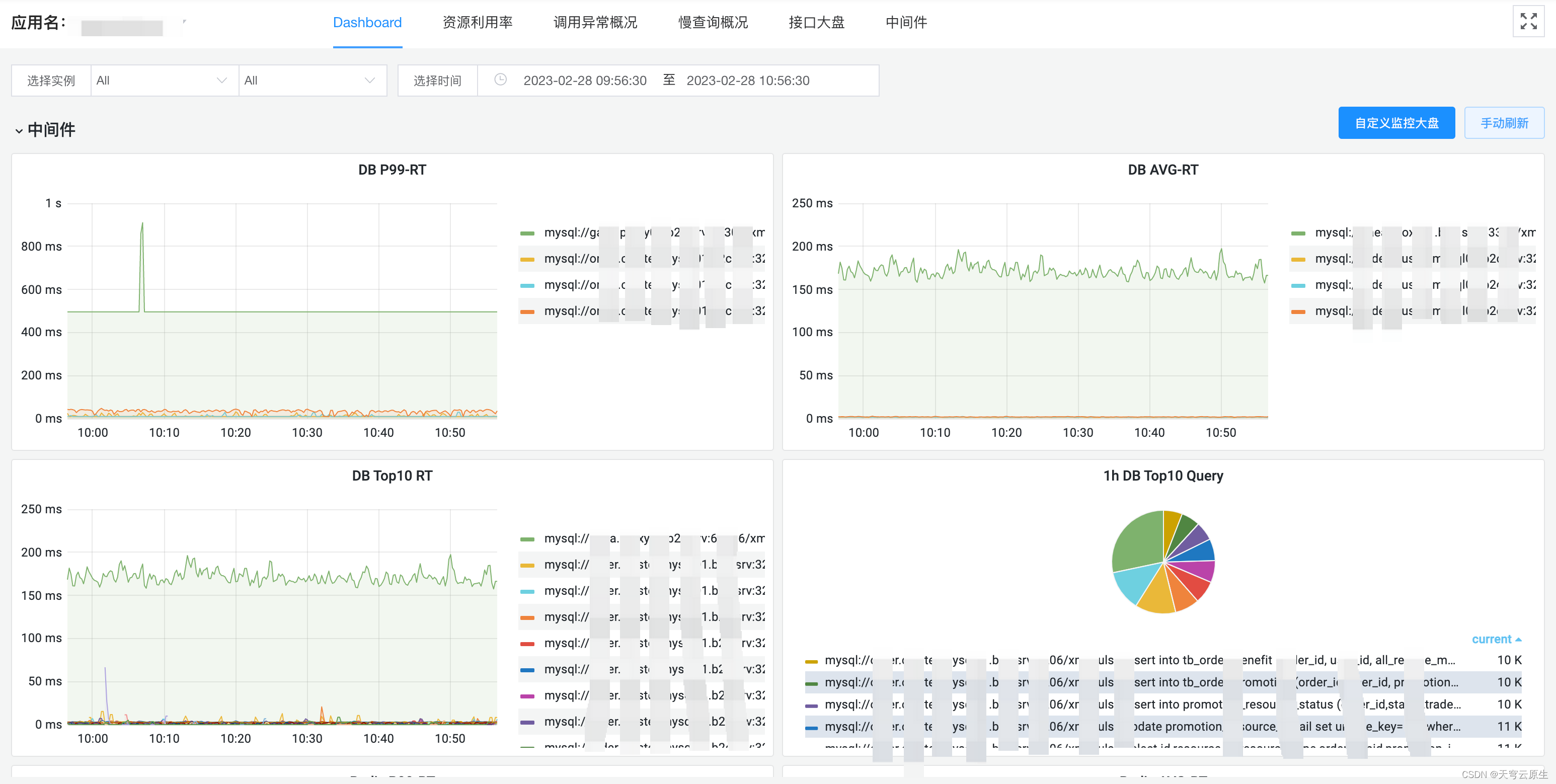
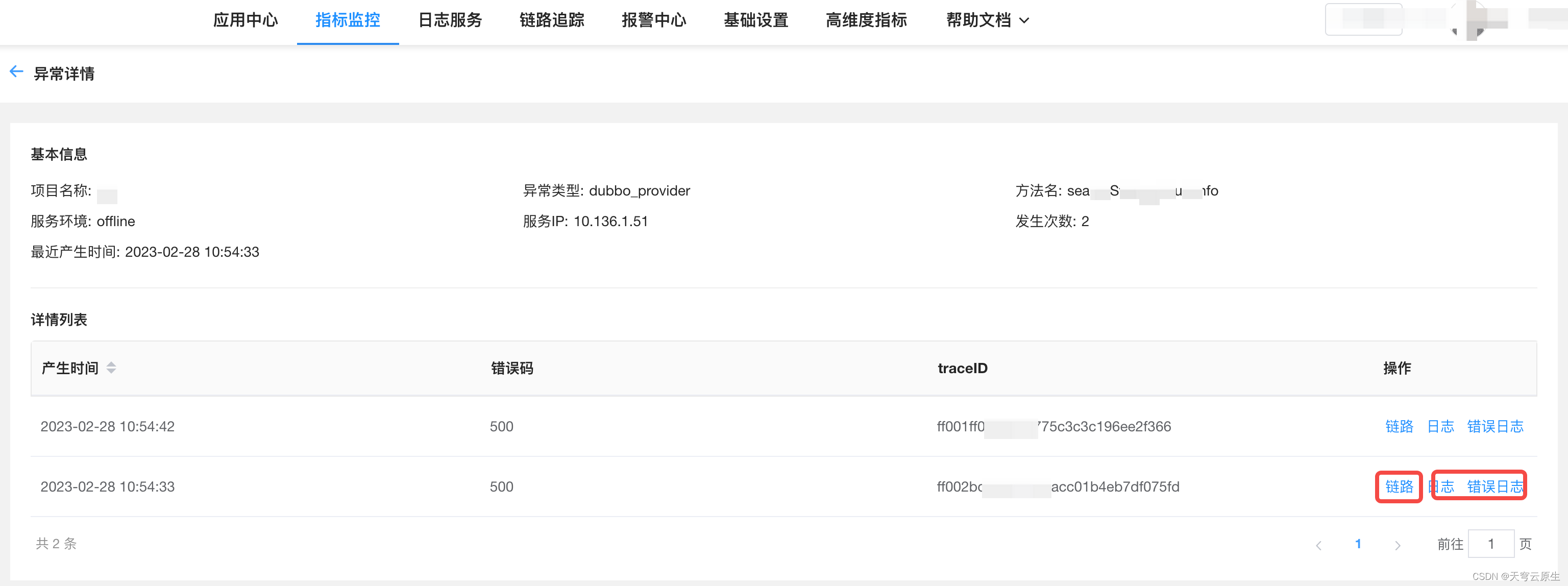
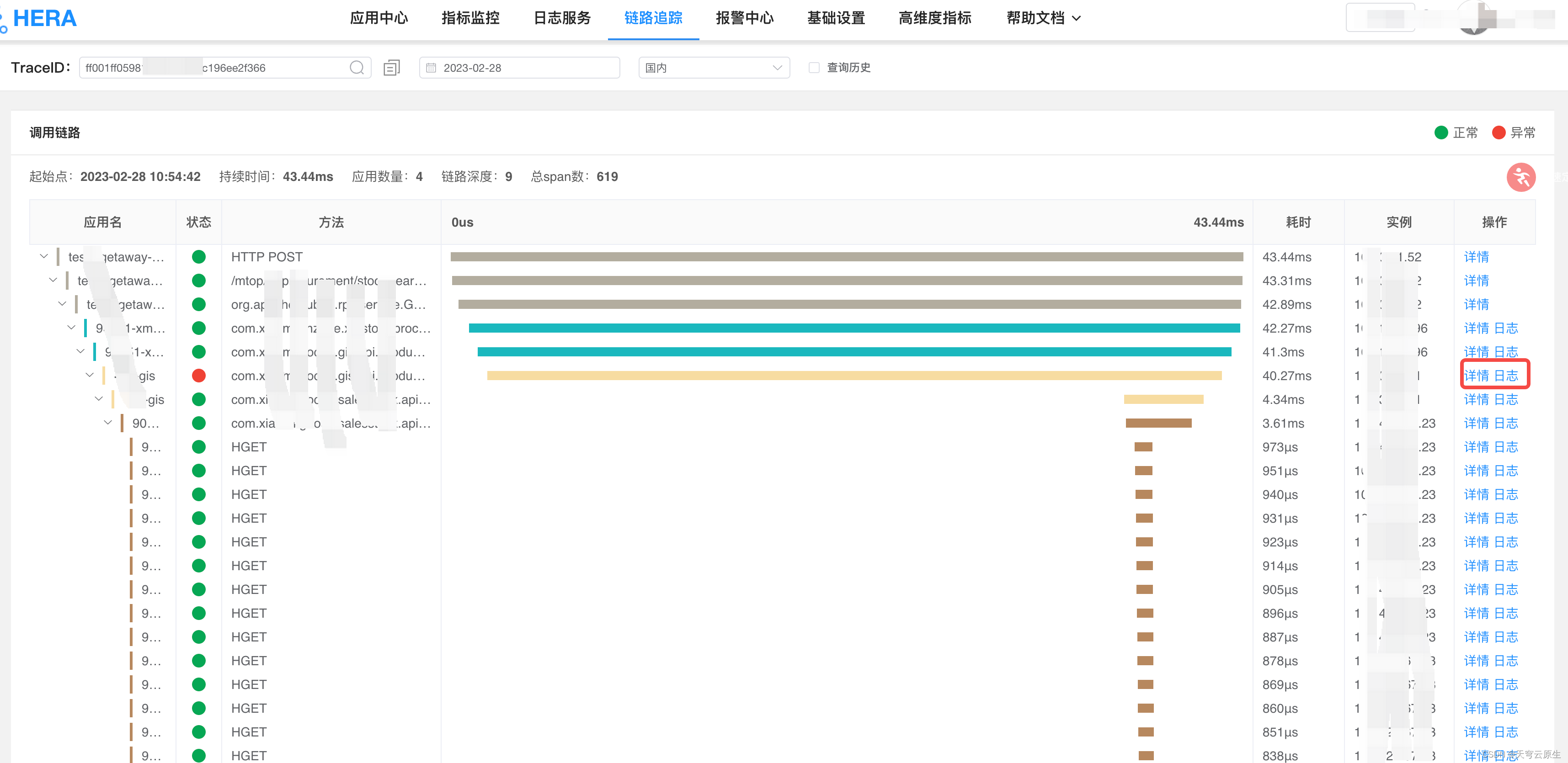
调用异常概况
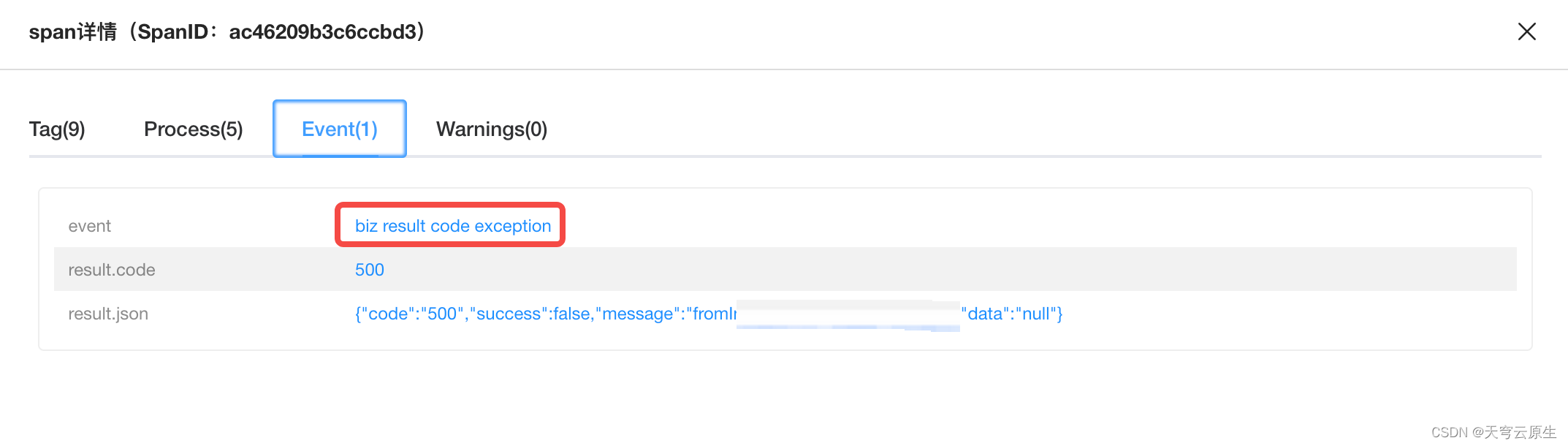
调用异常概况是hera平台问题定位的核心利器。实现了从报警 -> 异常概率 -> 异常列表-> 调用链路/业务日志的串联,从接收到报警开始只需点击三次就可查看到对应异常请求的链路和日志详情(内部实践在20秒内基本可定位线上故障)。


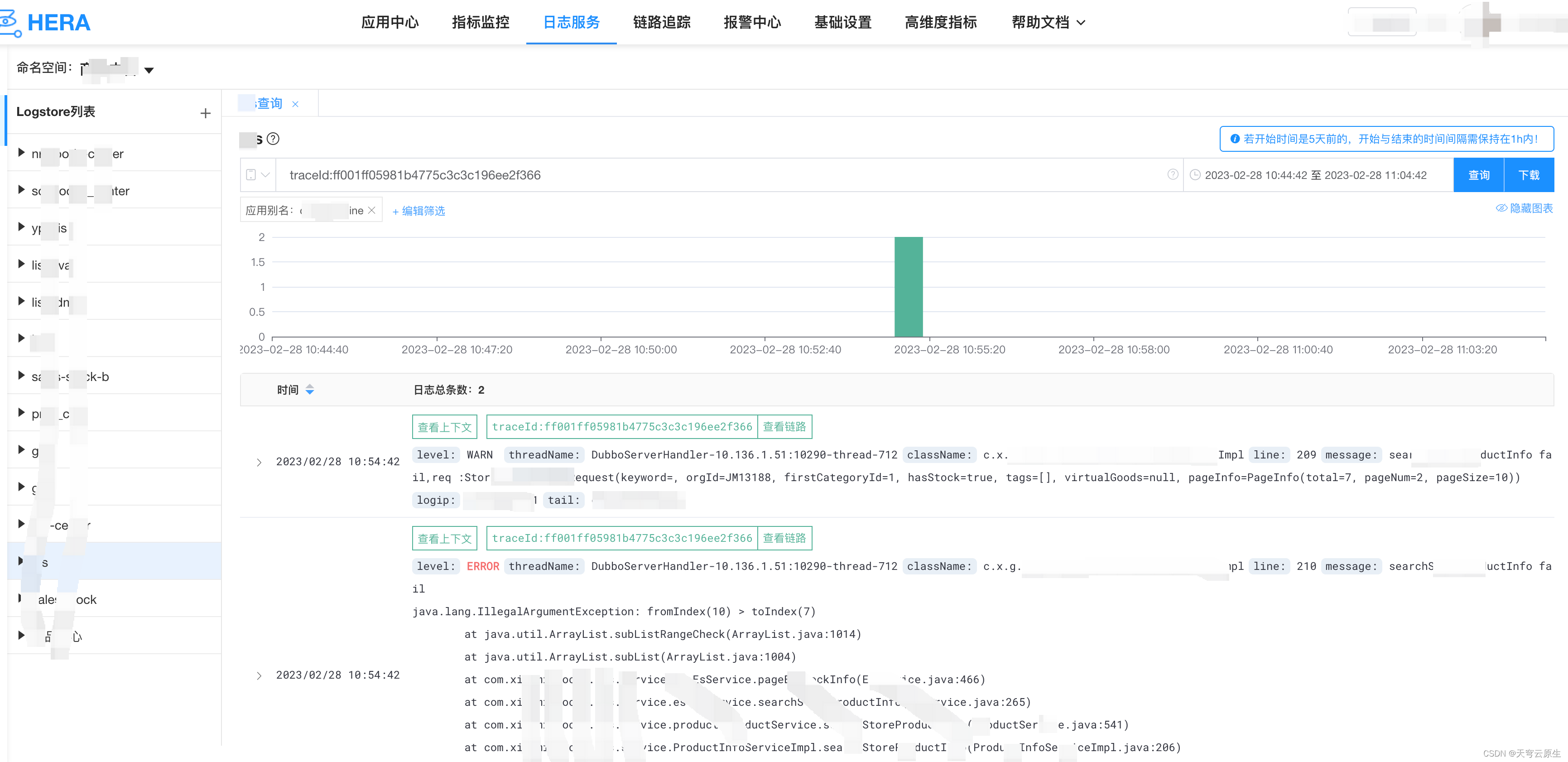
日志服务

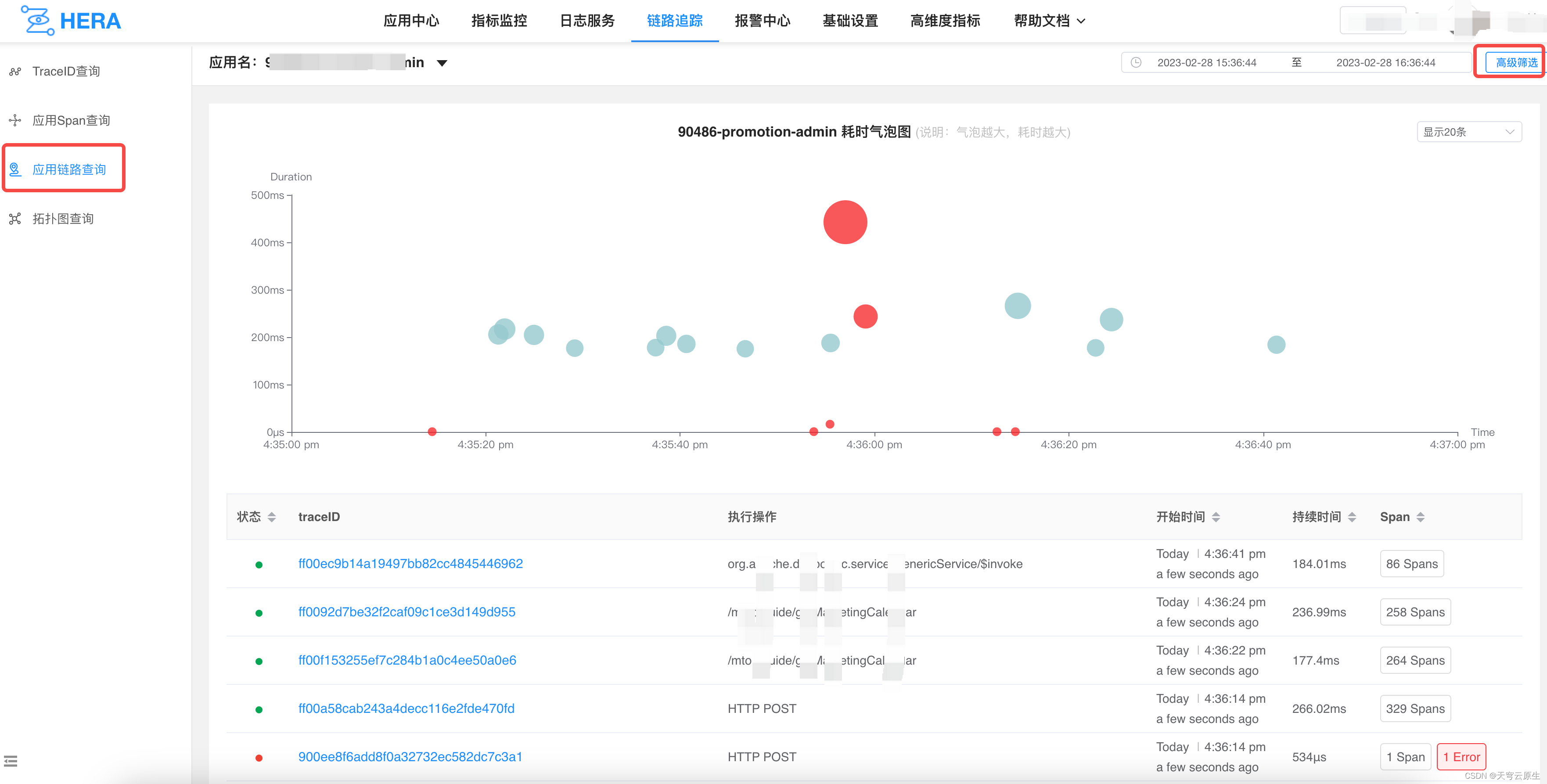
链路追踪
架构设计
核心架构

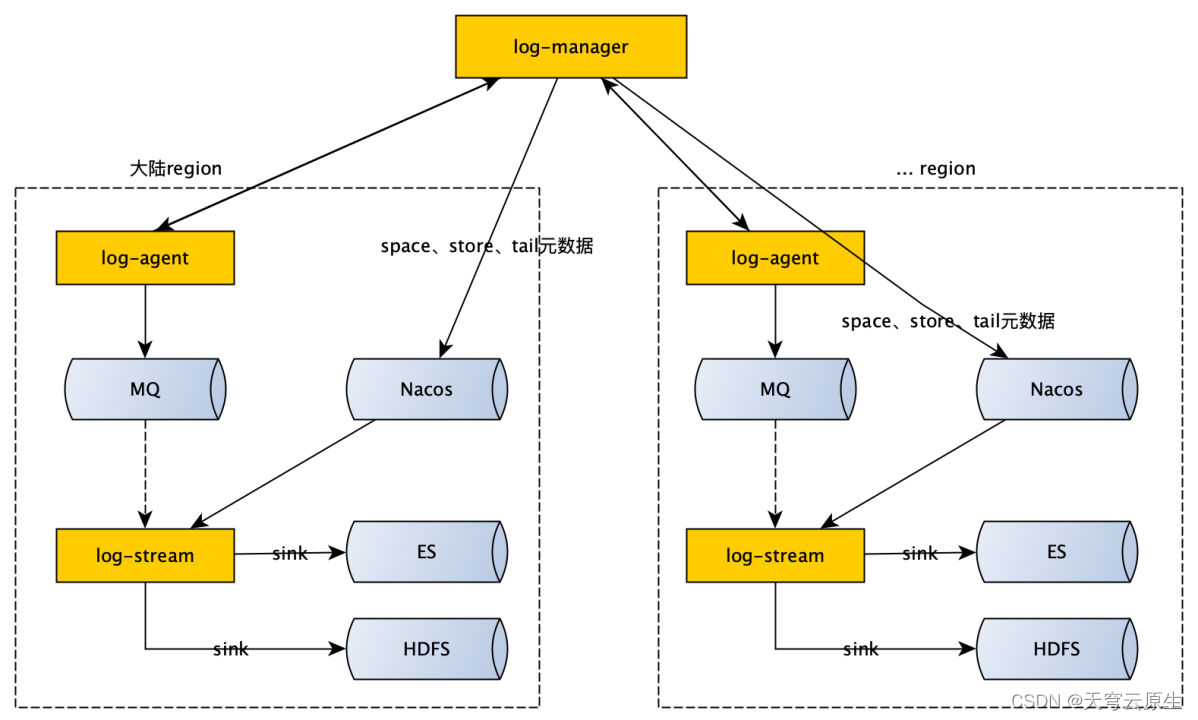
日志设计
日志采用纯自研方案,space、store两级日志隔离机制(space是逻辑空间、store是物理存储空间),采集、发送、解析、存储、索引各环节均可业务自定义。
log-manager是整个日志平台的大脑,负责日志平台的交互及中心元数据的管理、分配等。log-agent负责日志采集,log-stream负责对原始日志进行消费、解析、sink至不同存储引擎。
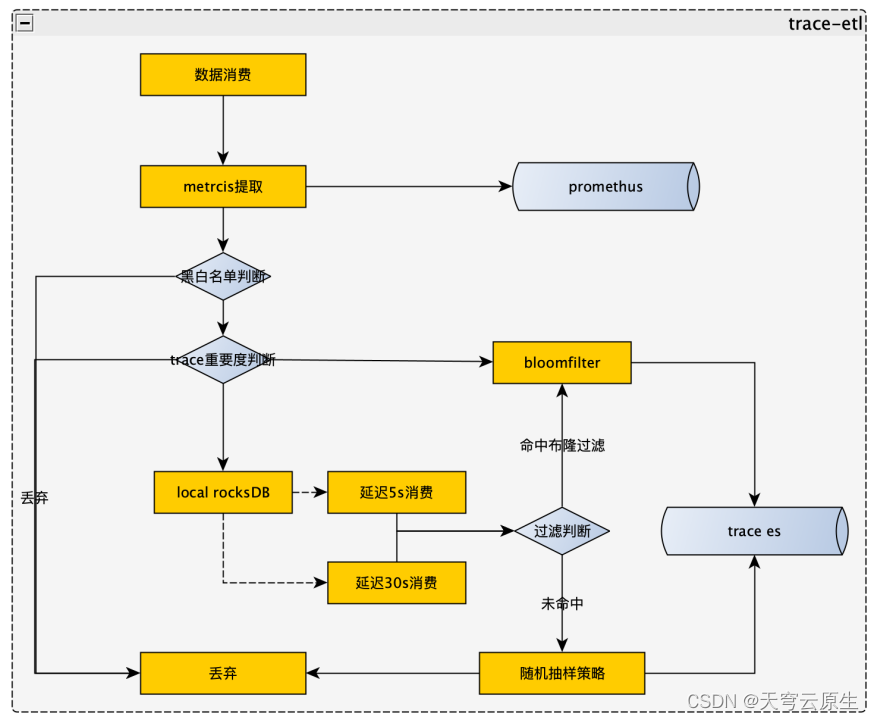
Tracing尾采样
依据tracing的重要度进行判断tracing的存储,实现<5%的存储空间,满足99.9%的Tracing需求
结语
本篇作为Hera系列的开篇,重点介绍了Hera定义、核心特性、产品介绍及核心设计,后续会带来详细的架构及技术实现细节,敬请期待!