中文是一种词汇量大,字形变换丰富且字符之间具有复杂相互依赖关系的语言,汉字常常具有多个意义,可组成复合词,使得建立准确、一致的文本描述与视觉表示之间的映射变的困难。
中文生成扩散模型的缺点,1.许多现有模型专注于根据通用文本描述生成图像,忽视了在特定领域或上下文中生成图像的能力。2.对于中文而言,尚未充分探索使用lora和controlnet进行精细化图像风格转换和图像编辑的潜力。
2.models

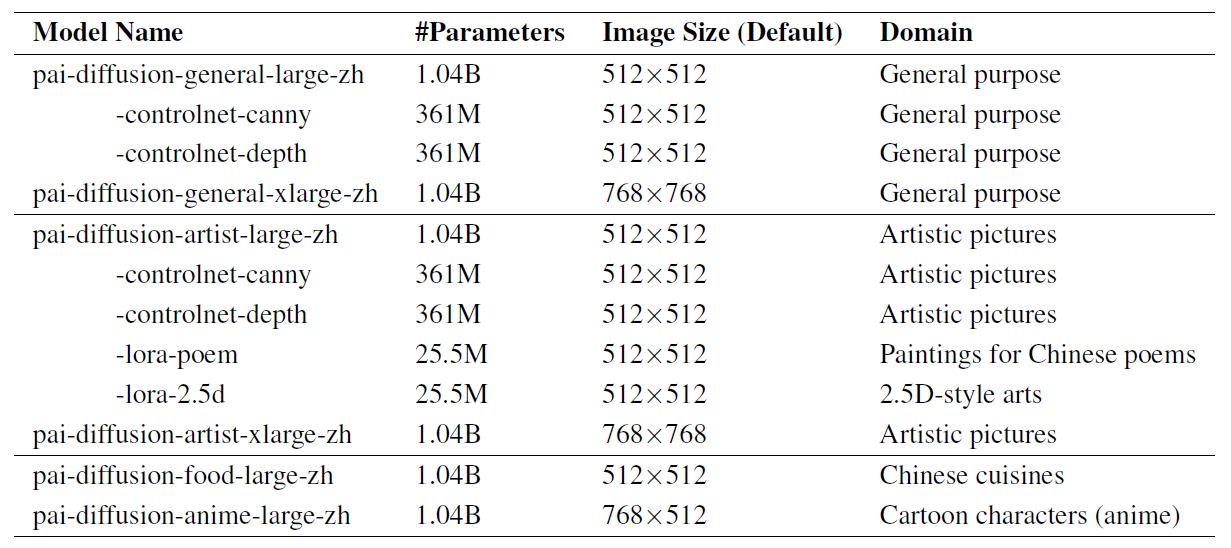
large和xlarge指的是生成图片的尺寸,前者是512x512,后者是768x768,和sd1.5的模型结构完全相同。
训练数据使用wukong的1亿文本图像对以及OpenKG预训练一个中文的clip模型。