前言
以下算法和数据结构代码都可以在本人的GitHub仓库中找到,欢迎大家来下载,可以的话,请给博主的GitHub来一个star,GitHub链接如下https://github.com/hifuda/algorithm-and-data-structure,但是我还是把完整的代码也放在了我的本篇博客上,为了照顾不玩GitHub的朋友。本篇博客是跟着b站视频来学习的,链接如下数据结构与算法特训班365天_哔哩哔哩_bilibili,由于篇幅有限,我打算分篇更新。感谢大家的观看,求个赞!
1,算法复杂度分析与计算
1,时间复杂度:算法运行所需要的时间,一般将算法执行的次数作为时间复杂度是我度量标准。
实例如下:

其中我们注意到为什么for循环执行n+1次呢?明明是1~n,为什么不是执行n次呢?因为,在最后一次,for循环要判断这个条件已经不符合循环了,所以说要加上这一次,同理下面的for循环也是这样!

注:f(n)取T(n)中幂最高的项,且去掉系数。这里的f(n)=n^2

我们通常使用时间复杂度的渐近上界来描述一个算法的时间复杂度。

T(n) = 1+2x。

注意寻找对算法时间复杂度贡献最大的代码块。
上面的算法,我们无法知道x在数组中的那个位置,所以我们要分最好和最坏两种情况来讨论:最好的情况就是x就是数组a的第一个元素,那么直接一次找到,(最坏的情况)如果是最后一个,那么要找n次,像这种分布概率均等的算法,计算其平均执行次数,算的n*(n+1)/2=(n+1)/2
2,空间复杂度


只要算法的空间复杂度是常数那么统统都是O(1)。
递归算法的空间复杂度:
实例如下:
int fac(int n){ if(n < 0){ cout << "小于零的数没有阶乘" << endl; return -1; } else if(n == 0 || n == 1){ return 1; } else{ return n*fac(n-1); } }
递归包括递推和回归。递推就是将原问题不断地分解成子问题直到达到结束条件,返回子问题的解,然后逐一回归,最终到达递推开始的原问题,然后返回原问题的解。

出栈:

进栈:
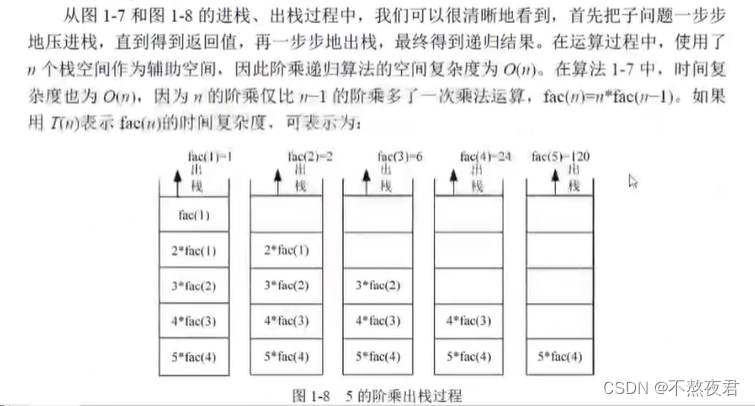
递归算法的时间复杂度如下:

3,常见的时间复杂度:


实例:神奇的兔子序列

解法一:递归算法
long long fib1(int n){//第50项时,耗费时间为 82939 if(n < 1){ return -1; } else if(n == 1 || n == 2){ return 1; } else{ return fib1(n - 1) + fib1(n - 2); } }
缺点:重复的动作太多,导致时间过久
递归树如下:
我们可以看到,f(4)算了两次,f(3)算了3次,依次类推,所以说斐波那契数列用递归来解答的话太浪费了。
空间复杂度:O(n)


解法二:动态规划
long double fib2(int n){//第50项时,耗费时间为 1 long double temp; if(n < 1){ return -1; } long double *a = new long double[n+1]; a[1] = a[2] = 1; for(int i = 3;i <= n; i++){ a[i] = a[i-1]+a[i-2]; } temp = a[n]; delete []a; //动态数组创建之后记得删除 return temp; }
我们可以改进算法如上,我们使用数组来记录当前项的前两项。
这样的话,时间复杂度O(n),空间复杂度就是O(n).
解法三:采集法
//迭代法 long double fib3(int n){ long double i,s1,s2; if(n < 0){ return -1; } if(n == 1 || n == 2){ return 1; } s1 = 1; s2 = 2; for(i = 3; i <=n;i++){ s2 = s1+s2; s1 = s2-s1; } return s2; }

这样的话我们的空间复杂度就是O(1),时间复杂度O(n).
2,线性数据结构
线性表简介:

线性表又分为顺序表和链表:
顺序表:

2.1,链表:

链表模型:
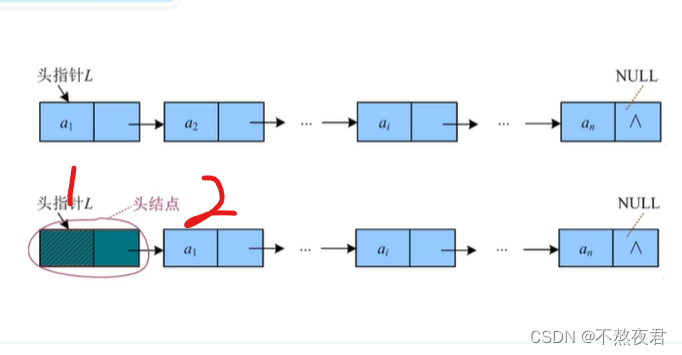
1,头节点一般不存放数据。
2,头节点之后的第一个节点,叫做首元节点
链表的几种基本操作:
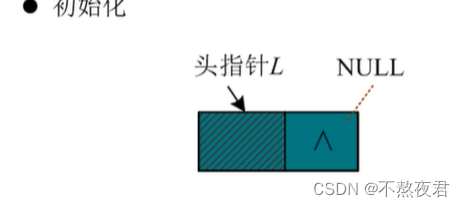
1,初始化:
2,创建

头插法:每次创建的节点都在头节点的后面。
尾插法:每次都在链表的最后一个元素后面插入。
3,查询
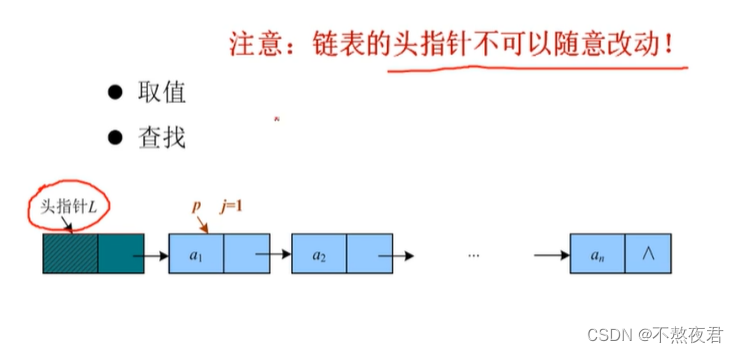
4,删除
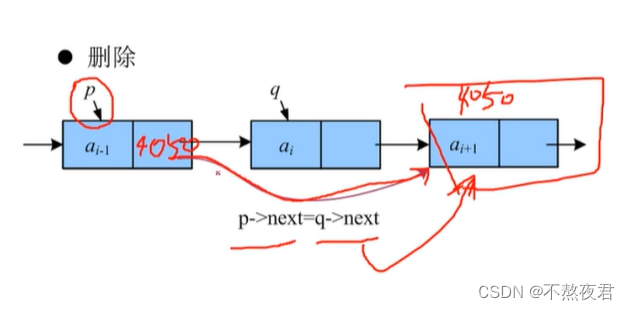
注意:改变p->next的在地址信息之后,记得使用delete 删除q节点。
双向列表的新增:
注意:要先去连上没有指针标记的节点给。
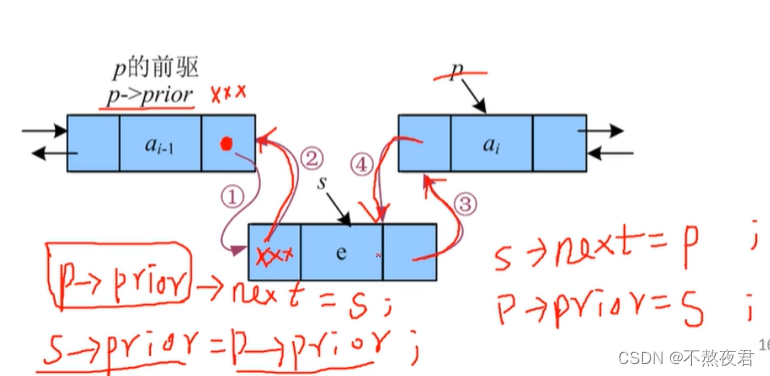
双向链表的删除:

2.2,链表完整代码与算法分析
1,首先定义一种结构体,作为节点类型
代码如下:
//创建结构体
typedef struct LNode{
int data;//节点中存入的数据
struct LNode *next;//定义指向下一个节点的指针
}LNode, *LinkList; //LinkList为指向结构体LNode的指针类型1,节点中的data还可以按照自己的需求定义成想要的类型。
2,使用typedef struct LNode将结构体取别名为LNode。
3,LinkList为指向结构体LNode的指针类型。
4,注意在定义结构体的时候要写struct LNode *next,而不可以写LNode *next,因为typedef struct LNode还没有执行完。
2,初始化节点
代码如下:
bool InitList_L(LinkList &L){//创建一个空的单链表
L = new LNode;
if(!L){//生成节点失败
return false;
}
L->next = NULL;//头节点指针域置为空
return true;
} 1,注意这里的形参列表传入的是引用,而不是简单的指针L,这样是为了在main方法中创建的头指针L做关联。
2,如果在执行过L = new LNode之后,L == NULL则生成节点失败。
3,创建节点
3.1,头插法实现
代码如下:
//创建节点 ,头插法实现
void CreateList_H(LinkList &L){
int n;//输入n个元素的值
LinkList s;//定义一个指针变量
L = new LNode;
L->next=NULL;//置空
cout <<"请输入元素个数n: " << endl;
cin >> n;
cout << "请依次输入n个元素:" << endl;
while(n--){
s = new LNode;//生成新节点
cin >> s->data;
s->next = L->next;//首先将头节点后面的节点和新增的节点相连
L->next = s;//然后,再将头节点和新建的节点相连,相连后断
}
} 1,这里的形参列表传入的是引用,而不是简单的指针L,理由同上。
2,在使用头插法的时候,我们只需要创建一个新的指针来保存节点地址,因为我们是直接插入在被指针标记的头节点后面。——LinkList s;//定义一个指针变量。
3,一定要注意这段代码s->next = L->next;好好理解,可能一开始添加第一个节点的时候会迷惑,因为这个时候L->next == NULL,但是如果添加第三个第四个呢?这时这句话的作用就一目了然了。
4,一定要记住先连上未被指针标记的,然后再连上被指针标记的。
3.2,尾插法实现
代码如下:
//创建节点,尾插法实现
void CreateList_L(LinkList &L){
//输入n个元素的值,建立带头结点的单链表
int n;
LinkList s,r;//这里要创建两个指针
L = new LNode;
L->next = NULL;
r = L;
cout << "请输入元素个数n: " <<endl;
cin >> n;
cout << "请依次输入n个元素:" << endl;
cout <<"尾插法创建单链表:" << endl;
while(n--){
s = new LNode;//创建新的节点
cin >> s->data;
s->next = NULL;
r->next = s;//将新节点插入尾节点r后面
r = s;//更新尾指针
}
}1,尾插法需要创建两个新的指针,由于是不断地从最后面的位置插入,所以需要尾指针的帮助,来标记最后一个元素的位置。
2,节点不断的增加,尾指针也需要不断的更新。
3.3,尾插法和头插法的运行时的区别:
尾插法创建链表如下:我们可以看到,我们输入的1,2,3,4,5。被顺序输出

头插法运行如下:我们可以看到,我们输入的1,2,3,4,5。被逆序输出

4,查找节点
4.1,顺序查找
代码如下:
//单链表的顺序查找
bool GetElem_L(LinkList L,int i,int &e){
//在带头结点的单链表L中查找第i个元素
//用e记录L中第i个元素的值
int j;
LinkList p;
p = L->next;
j = 1; //计数器
while(j < i && p){//当p指向NULL,或者j<i时退出循环
p = p->next;//p指向下一个节点
j++;//计数器加一
}
if(!p || j > i){
//j > i是为了以防特殊数据,比如说i=-1
return false;
}
e = p->data;
return true;
} 1,形参列表使用引用,理由同上。
2,注意遍历链表的时候不可以对指针进行++或者--操作,C可以,但是C++不行,所以这里创建了一个计数器来辅助遍历。
3,注意if和while语句的条件。
4.2,按值查找
代码如下:
//按值查找
bool LocateElem_L(LinkList L,int e){
//注意头节点的指针不可以移动
LinkList p;
p = L->next;
while(p && p->data!=e){//p不指向NULL或者值不相等
p = p->next;
}
if(!p){//如果遍历完都没找到,那么p指针肯定为空
return false;
}
return true;
} 1,注意头节点的指针不可以移动
5,插入节点
代码如下:
//插入节点
bool ListInsert_L(LinkList &L,int i,int e){
int j;
LinkList p,s;
p = L;
j = 0;
while(p && j < i-1){//把指针移动到被插入节点的前一个节点
p = p->next;//移动指针
j++;//计数器加一
}
if(!p && j > i-1){
//p为空,看是否遍历到最后
// j > i-1 同上是为了以防特殊数据
return false;
}
s = new LNode;
s->data = e;
s->next = p->next;//先连接未被标记的节点
p->next = s;//然后再连上被标记的节点
return true;
} 1,注意再插入结点的时候,也创建了两个指针,一个用来标记标记被插入节点的前一个节点i-1,另一个用来保存要插入的节点。
2,注意while和if语句中的条件。
6,删除节点
代码如下:
//单链表的删除
bool ListDelete_L(LinkList &L,int i){
//删除第i个位置的元素
LinkList q,p;
int j;
p = L;
//j从0开始计数是为了可以让头节点后面的节点也可以删除
j = 0;
while((p->next) && (j<i-1)){
//最多遍历到最后一个节点,p->next=NULL
p = p->next;
j++;
}
if(!(p->next) || (j>i-1)){
return false;
}
q = p->next;//让q指向p后面的节点
p->next = q->next;//再让p->next指向q后面的节点
delete q;//删除指针
return true;
}1,首先这里创建了两指针q和p,分别用于指向被删除的i节点和i-1节点。
2,将p遍历到i-1的位置,然后q = p->next;//让q指向p后面的节点 。
3,p->next = q->next;//再让p->next指向q后面的节点 。
4,最后记得删除指针。
7,输出链表
代码如下:
//输出单链表
void Listprint_L(LinkList L){
LinkList p;
p = L->next;
while(p){//此处的判断条件要注意,不要写p->next
cout << p->data << "\t";
p = p->next;
}
cout <<endl;
} 就是在p!=NULL的时候不断地执行p = p->next,将p指针遍历到后面去。
8,完整的代码如下
#include<iostream>
#include<string>
//在iomanip库中,比较常用的有关于进制的转换,小数点的保留,以及域宽等的使用。
#include<iomanip>
//包含了c语言中的一些常用的库函数
#include<stdlib.h>
using namespace std;
//创建结构体
typedef struct LNode{
int data;//节点中存入的数据
struct LNode *next;//定义指向下一个节点的指针
}LNode, *LinkList; //LinkList为指向结构体LNode的指针类型
bool InitList_L(LinkList &L){//创建一个空的单链表
L = new LNode;
if(!L){//生成节点失败
return false;
}
L->next = NULL;//头节点指针域置为空
return true;
}
//创建节点 ,头插法实现
void CreateList_H(LinkList &L){
int n;//输入n个元素的值
LinkList s;//定义一个指针变量
L = new LNode;
L->next=NULL;
cout <<"请输入元素个数n: " << endl;
cin >> n;
cout << "请依次输入n个元素:" << endl;
while(n--){
s = new LNode;//生成新节点
cin >> s->data;
s->next = L->next;//首先将头节点后面的节点和新增的节点相连
L->next = s;//然后,再将头节点和新建的节点相连,相连后断
}
}
//创建节点,尾插法实现
void CreateList_L(LinkList &L){
//输入n个元素的值,建立带头结点的单链表
int n;
LinkList s,r;//这里要创建两个指针
L = new LNode;
L->next = NULL;
r = L;
cout << "请输入元素个数n: " <<endl;
cin >> n;
cout << "请依次输入n个元素:" << endl;
cout <<"尾插法创建单链表:" << endl;
while(n--){
s = new LNode;//创建新的节点
cin >> s->data;
s->next = NULL;
r->next = s;//将新节点插入尾节点r后面
r = s;//更新尾指针
}
}
//单链表的顺序查找
bool GetElem_L(LinkList L,int i,int &e){
//在带头结点的单链表L中查找第i个元素
//用e记录L中第i个元素的值
int j;
LinkList p;
p = L->next;
j = 1; //计数器
while(j < i && p){//当p指向NULL,或者j<i时退出循环
p = p->next;//p指向下一个节点
j++;//计数器加一
}
if(!p || j > i){
//j > i是为了以防特殊数据,比如说i=-1
return false;
}
e = p->data;
return true;
}
//按值查找
bool LocateElem_L(LinkList L,int e){
//注意头节点的指针不可以移动
LinkList p;
p = L->next;
while(p && p->data!=e){//p不指向NULL或者值不相等
p = p->next;
}
if(!p){//如果遍历完都没找到,那么p指针肯定为空
return false;
}
return true;
}
//插入节点
bool ListInsert_L(LinkList &L,int i,int e){
int j;
LinkList p,s;
p = L;
j = 0;
while(p && j < i-1){//把指针移动到被插入节点的前一个节点
p = p->next;//移动指针
j++;//计数器加一
}
if(!p && j > i-1){
//p为空,看是否遍历到最后
// j > i-1 同上是为了以防特殊数据
return false;
}
s = new LNode;
s->data = e;
s->next = p->next;//先连接未被标记的节点
p->next = s;//然后再连上被标记的节点
return true;
}
//单链表的删除
bool ListDelete_L(LinkList &L,int i){
//删除第i个位置的元素
LinkList q,p;
int j;
p = L;
//j从0开始计数是为了可以让节点可以插入头节点的后面
j = 0;
while((p->next) && (j<i-1)){
//最多遍历到最后一个节点,p->next=NULL
p = p->next;
j++;
}
if(!(p->next) || (j>i-1)){
return false;
}
q = p->next;//让q指向p后面的节点
p->next = q->next;//再让p->next指向q后面的节点
delete q;//删除指针
return true;
}
//输出单链表
void Listprint_L(LinkList L){
LinkList p;
p = L->next;
while(p){//此处的判断条件要注意,不要写p->next
cout << p->data << "\t";
p = p->next;
}
cout <<endl;
}
int main()
{
int i,x,e,choose;
LinkList L;
cout << "1. 初始化\n";
cout << "2. 创建单链表(前插法)\n";
cout << "3. 创建单链表(尾插法)\n";
cout << "4. 取值\n";
cout << "5. 查找\n";
cout << "6. 插入\n";
cout << "7. 删除\n";
cout << "8. 输出\n";
cout << "0. 退出\n";
choose=-1;
while (choose!=0)
{
cout<<"请输入数字选择:";
cin>>choose;
switch (choose)
{
case 1: //初始化一个空的单链表
if (InitList_L(L))
cout << "初始化一个空的单链表!\n";
break;
case 2: //创建单链表(前插法)
CreateList_H(L);
cout << "前插法创建单链表输出结果:\n";
Listprint_L(L);
break;
case 3: //创建单链表(尾插法)
CreateList_L(L);
cout << "尾插法创建单链表输出结果:\n";
Listprint_L(L);
break;
case 4: //单链表的按序号取值
cout << "请输入一个位置i用来取值:";
cin >> i;
if (GetElem_L(L,i,e))
{
cout << "查找成功\n";
cout << "第" << i << "个元素是:"<<e<< endl;
}
else
cout << "查找失败\n\n";
break;
case 5: //单链表的按值查找
cout<<"请输入所要查找元素x:";
cin>>x;
if (LocateElem_L(L,x))
cout << "查找成功\n";
else
cout << "查找失败! " <<endl;
break;
case 6: //单链表的插入
cout << "请输入插入的位置和元素(用空格隔开):";
cin >> i;
cin >> x;
if (ListInsert_L(L, i, x))
cout << "插入成功.\n\n";
else
cout << "插入失败!\n\n";
break;
case 7: //单链表的删除
cout<<"请输入所要删除的元素位置i:";
cin>>i;
if (ListDelete_L(L, i))
cout<<"删除成功!\n";
else
cout<<"删除失败!\n";
break;
case 8: //单链表的输出
cout << "当前单链表的数据元素分别为:\n";
Listprint_L(L);
cout << endl;
break;
}
}
return 0;
}
9,应用题一

步骤如下:
1,首先创建三个指针,p和q用于比较,r用来指向最后一个节点。
2,最开始的时候,r指向头节点,q,p分别指向两个不同的链表的第一个元素节点。
3,比较p和q的数据域的大小,2next = q。
4,然后更新辅助指针r = q,并且q指针移动到下一个数q = q->next。
5,然后再比较6和4,由于6>4,所以r->next = p。
6,然后更新辅助指针r = p,并且p指针移动到下一个数p = p->next。
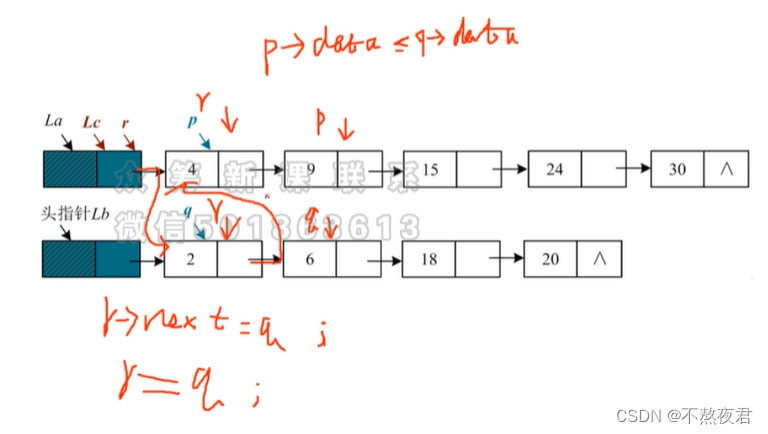
完整代码如下:
#include<iostream>
#include<string>
using namespace std;
typedef struct LNode{
int data;
struct LNode *next;
}LNode,*LinkList;
//创建数组尾插法创建
bool CreateList(LinkList &L){
int n,j;//
LinkList p,q;//p不断指向最后一个节点,q保存新的节点
L = new LNode;
if(!L){
cout << "创建失败" << endl;
return false;
}
L->next = NULL;
p = L;
cout << "请输入要放入的元素个数n:" << endl;
cin >> n;
cout << "请输入要放入的元素值data(数据之间用空格分割):";
for (j = 0; j < n;j++){
q = new LNode;//创建新的节点
q->next = NULL;
cin >> q->data;
p->next = q;//p->next 指向新节点
p = p->next;//p向后移
}
return true;
}
//合并数组
void MergeList(LinkList La,LinkList Lb,LinkList &Lc){
LinkList r,p,q;//创建三个指针
r = La;
Lc = r;
p = La->next;
q = Lb->next;
while(p&&q){
if(p->data > q->data){
r->next = q;
r = r->next;
q = q->next;
}else{
r->next = p;
r = r->next;
p = p->next;
}
}
r->next=p?p:q;//相当于if(p) r->next=p; else r->next=q;
delete Lb;
}
//输出数组
void PrintList(LinkList L){
LinkList s;
s = L->next; //直接指向头指针的后一个节点
cout << "链表输出如下:" << endl;
while(s){
cout << s->data << "\t";
s = s->next;
}
cout << endl;
}
int main(){
LinkList La,Lb,Lc;
cout << "创建链表La" << endl;
CreateList(La);
PrintList(La);
cout << "创建链表Lb" << endl;
CreateList(Lb);
PrintList(Lb);
cout << "合并链表后:" << endl;
MergeList(La,Lb,Lc);
PrintList(Lc);
return 0;
}运行示例如下:

9,应用题二

步骤如下:
当节点数是偶数的时候,那么中间节点就是3。
当节点数是奇数时,如下,快指针在到达6的时候,慢指针到达3,这时快指针到达7后面的节点后(这时快指针等于空NULL),慢指针到达4,中间节点就是4。

完整代码如下:
#include<iostream>
#include<string>
using namespace std;
typedef struct LNode{
int data;
struct LNode *next;
}LNode,*LinkList;
//创建数组尾插法创建
bool CreateList(LinkList &L){
int n,j;//
LinkList p,q;//p不断指向最后一个节点,q保存新的节点
L = new LNode;
if(!L){
cout << "创建失败" << endl;
return false;
}
L->next = NULL;
p = L;
cout << "请输入要放入的元素个数n:" << endl;
cin >> n;
cout << "请输入要放入的元素值data(数据之间用空格分割):";
for (j = 0; j < n;j++){
q = new LNode;//创建新的节点
q->next = NULL;
cin >> q->data;
p->next = q;//p->next 指向新节点
p = p->next;//p向后移
}
return true;
}
//输出数组
void PrintList(LinkList L){
LinkList s;
s = L->next; //直接指向头指针的后一个节点
cout << "链表输出如下:" << endl;
while(s){
cout << s->data << "\t";
s = s->next;
}
cout << endl;
}
//找寻中间节点
LinkList findmiddle(LinkList L)
{
LinkList p,q;
p=L; //p为快指针,初始时指向L
q=L; //q为慢指针,初始时指向L
while(p!=NULL&&p->next!=NULL)//注意这里的条件,要仔细思考为什么这么写
{
p=p->next->next;//p为快指针一次走两步;
q=q->next; //q为慢指针一次走一步
}
return q;//返回中间结点指针
}
int main(){
LinkList L,s;
cout << "创建链表L" << endl;
CreateList(L);
PrintList(L);
s = findmiddle(L);
cout << "中间节点为:" << s->data;
}
运行实例图:

10,课后练习

练习一
1,对于第一题,我的想法是,使用两个辅助指针去q和p,一开始两个辅助指针都指向第一个元素节点,其中一个指针q不断地向后遍历,并且使用一个变量n记录链表的长度,当q遍历到最后的时候,链表长度也就记录在n中了。
2,然后再计算出元素在顺序中的位置,在用另一个指针去得到这个元素节点。
完整代码如下
#include<iostream>
#include<string>
using namespace std;
typedef struct LNode{
int data;
struct LNode *next;
}LNode, *LinkList;
//创建链表(头插法)
bool CreateList(LinkList &L){
LinkList p;
int n,j;
L = new LNode;
if(!L){
return false;
}
L->next = NULL;
cout << "请输入要创建的节点个数n:" << endl;
cin >> n;
cout << "请输入元素值data(值之间用空格分割):" ;
for(j = 0;j < n;j++){
p = new LNode;
p->next = NULL;
cin >> p->data;
p->next = L->next;//首先让新增节点连上头节点后面的节点
L->next = p;//然后头节点再连上新节点
}
return true;
}
//打印链表
void PrintList(LinkList L){
LinkList s;
s = L->next; //直接指向头指针的后一个节点
cout << "链表输出如下:" << endl;
while(s){
cout << s->data << "\t";
s = s->next;
}
cout << endl;
}
练习二
步骤如下:
首先,创建三个指针r,p,q,还有一个数组a[ ];我考虑使用一个数组来存储节点元素出现的次数,p指针用于遍历整个链表,然后得到各个节点的元素的绝对值出现的次数;然后,r指向头指针,q指向第一个元素节点,r指针永远再q指针的前一位,用于连接要删除的元素的后一位元素,而q则标记要删除的元素节点。而这里的判断条件就是看a[ ]数组中对应的元素的出现次数是否大于1,如果成立,则删除此节点,且保存在数组中的次数减一,如果不成立,则r和q指针都向前移动一位。
完整代码如下:
#include<iostream>
#include<string>
#include<cmath> //需要使用他的绝对值函数abs(),所以引入
using namespace std;
typedef struct LNode{
int data;
struct LNode *next;
}LNode, *LinkList;
//创建链表(头插法)
bool CreateList(LinkList &L){
LinkList p;
int n,j;
L = new LNode;
if(!L){
return false;
}
L->next = NULL;
cout << "请输入要创建的节点个数n:" << endl;
cin >> n;
cout << "请输入元素值data(值之间用空格分割):" ;
for(j = 0;j < n;j++){
p = new LNode;
p->next = NULL;
cin >> p->data;
p->next = L->next;//首先让新增节点连上头节点后面的节点
L->next = p;//然后头节点再连上新节点
}
return true;
}
//打印链表
void PrintList(LinkList L){
LinkList s;
s = L->next; //直接指向头指针的后一个节点
cout << "链表输出如下:" << endl;
while(s){
cout << s->data << "\t";
s = s->next;
}
cout << endl;
}
bool AbandonTwo(LinkList &L){
int a[1024] = {0};//用于存储链表中的数据对应的出现的次数
LinkList p,q,r;//p用于遍历链表中的数据
if(L->next){//判断该链表是不是一个空链表,如果不是让p和q指向第一个元素节点
p = L->next;
q = L->next;
r = L;
}else{
return false;
}
while(p){
a[abs(p->data)]++;//0-1,1-2,3---
p = p->next;
}
// cout << "输出数组" <<endl;
// cout << "输出数组:" << sizeof(a)/sizeof(int) <<endl; 获取数组长度
// for(int i = 0;i < sizeof(a)/sizeof(int);i++){
// cout << a[i] << "\t";
// }
while(q){
if(a[abs(q->data)] > 1){//如果该节点的数值的绝对值出现超过1次,就删除
a[abs(q->data)]--; //元素出现次数减一
r->next = q->next;
q = q->next;
//r = r->next; //注意这个时候不用更新r指针
}else{//如果该节点数值的绝对值只有1次,那么直接移动指针到下一位
r = q;
q = q->next;
}
}
// cout << "输出数组2" <<endl;
// cout << "输出数组:" << sizeof(a)/sizeof(int) <<endl; 获取数组长度
// for(int i = 0;i < sizeof(a)/sizeof(int);i++){
// cout << a[i] << "\t";
// }
return true;
}
int main(){
LinkList L;
cout << "创建链表L:" <<endl;
if(CreateList(L)) {
cout << "创建链表成功" << endl;
}else{
cout << "创建链表失败" << endl;
return 0;
}
PrintList(L);
if(AbandonTwo(L)) {
cout << "去除成功,去除后链表如下" <<endl;
PrintList(L);
}else{
cout << "该链表是一个空链表" <<endl;
}
return 0;
}空间复杂度分析:其实,可以看出,由于题目没有对算法的空间复杂度提出要求,那么我就可以申请无限的数组长度,而如上算法的空间复杂度是由链表中的最大数决定的。
时间复杂度分析:在这里我们只遍历了两次链表,所以时间复杂度为O(n).
补充:C++数组长度的获取方法
length = sizeof(array)/sizeof(*array); //表达式1
//length = sizeof(array)/sizeof(array[0]); //表达式2
//length = sizeof(array)/sizeof(int); //表达式3
上述三个表达式都能得到正确的结果,虽然表达式略有不同,但原理是相同的,即通过sizeof(array)获取整个数组所占的内存字节数,再通过sizeof(*array)或者sizeof(array[0])或者sizeof(int)来获取每个元素所占的字节数,数组所占的字节数除以每个元素所占的字节数就是该数组的元素个数了。
2.3,栈和队列
1,栈知识点简介

通常使用的是顺序存储,最好不要使用链式存储。
2,栈
2.1,栈的操作简介:
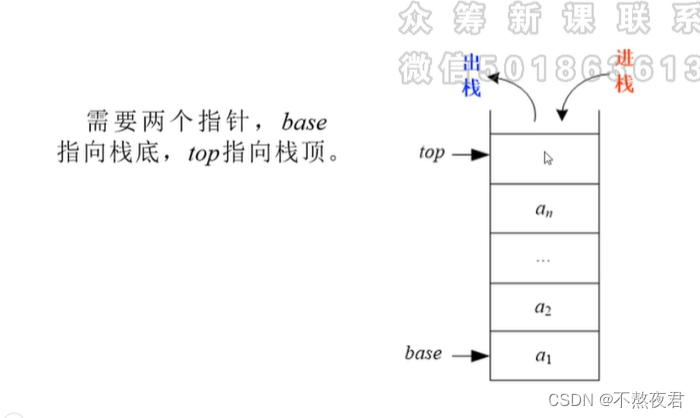
1,top指针在栈内有元素的情况下为空,出栈时top--,入栈时top++。
2,当top==base时,判断此栈为空。
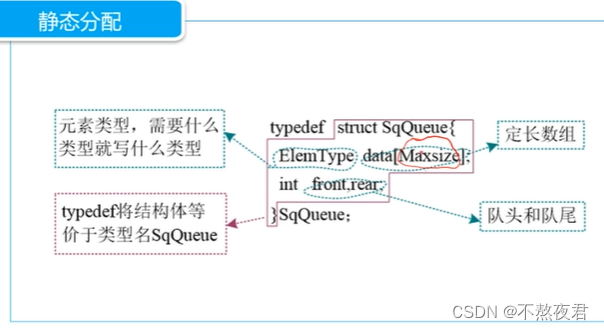
2.2,栈结构体
1,动态分配
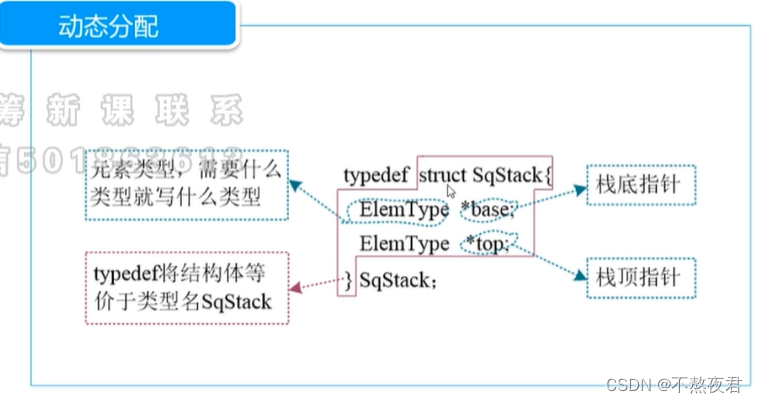
2,静态分配
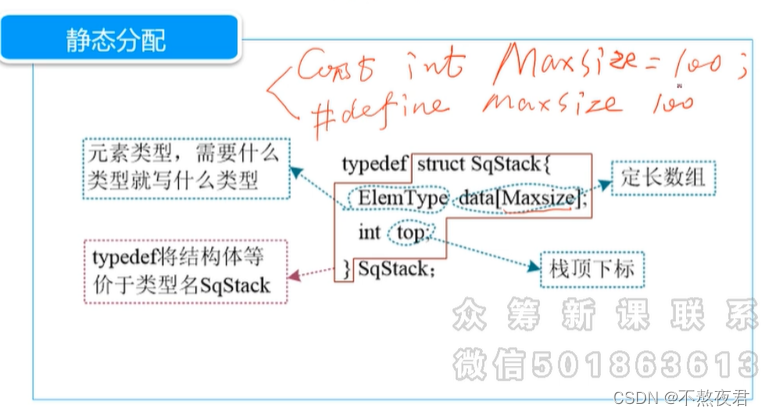
最好使用const int Maxsize = ?来定义数组长度。
3,顺序栈的操作
3.1,栈的初始化

3.2,入栈

S.top-S.base == Maxsize //栈满条件
*(S.top++) = e; //元素e压入栈顶,然后栈顶指针加1,
//上一行代码等价于*S.top=e; S.top++;
//一开始top指针和base指针都指向栈底,而不是像图中分开3.2,入栈

3.3,取栈顶

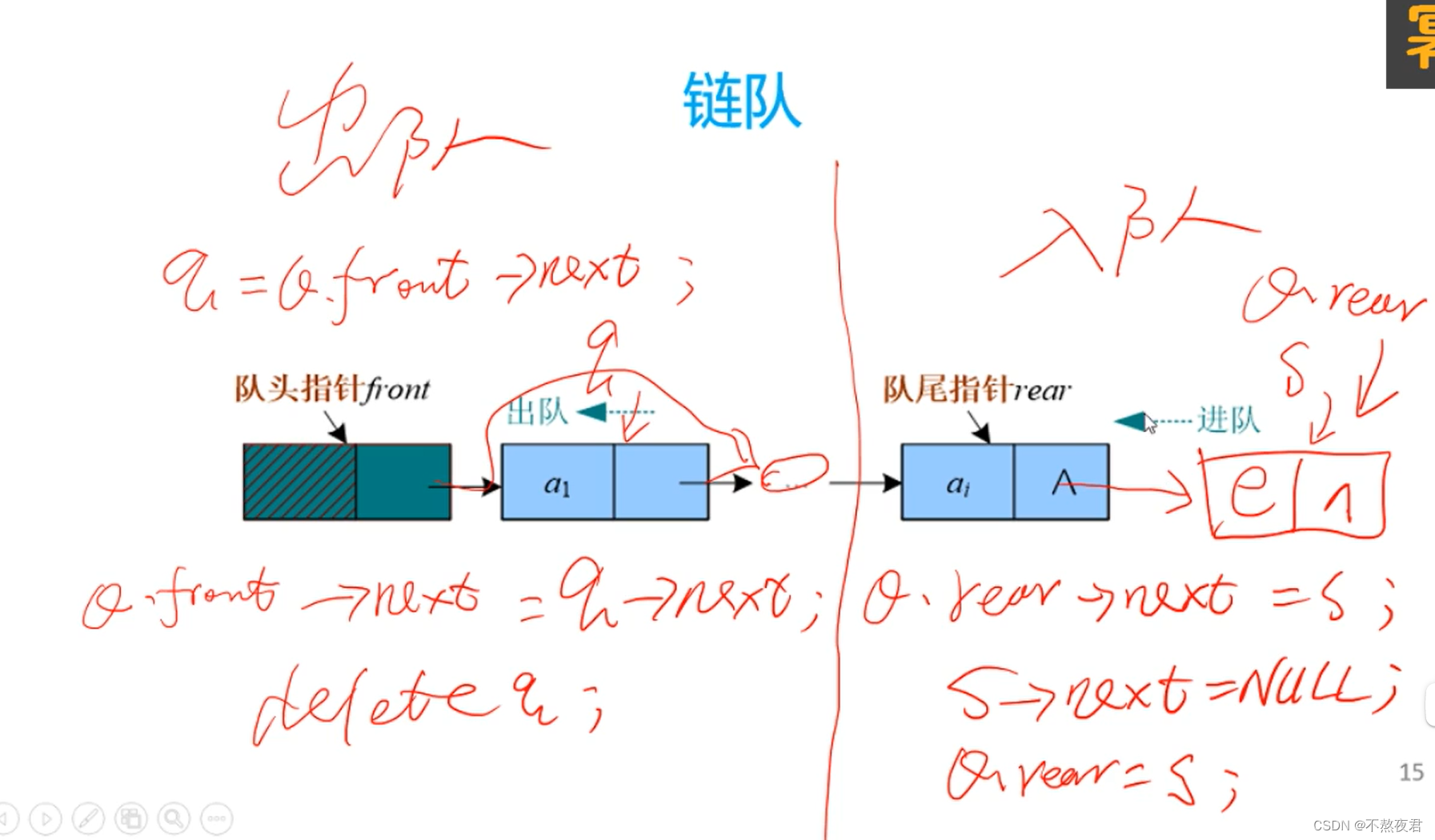
4,链栈
4.1,入栈
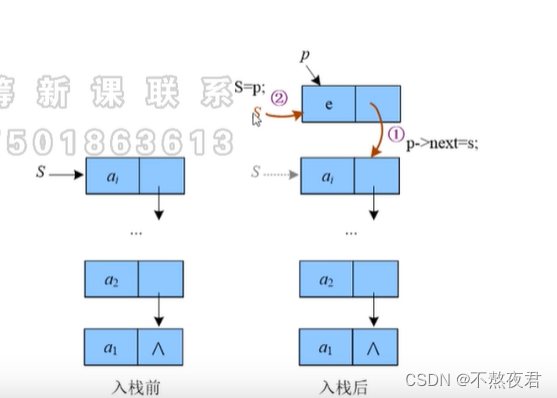
链栈只需要两个指针,一个用来指向栈顶,一个用来保存新的入栈元素。操作步骤如上。
4.2,出栈
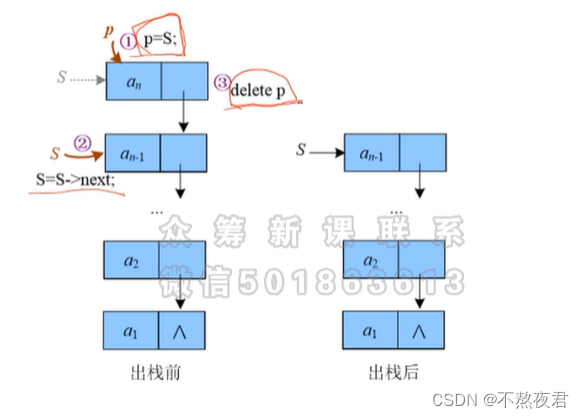
4.3,取栈顶元素

5,队列

5.1,顺序队列
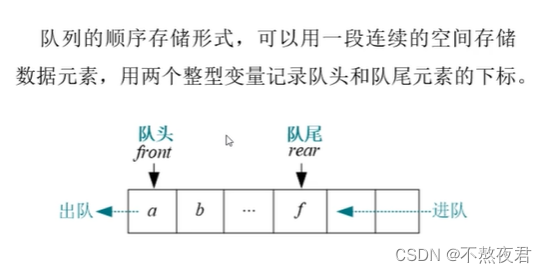
队列结构体动态分配:

队列结构体静态分配:
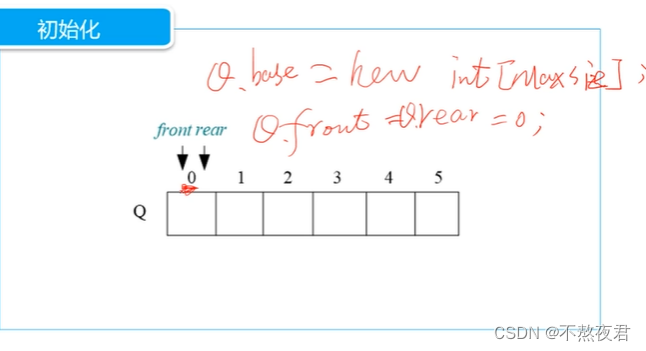
初始化:
入队:

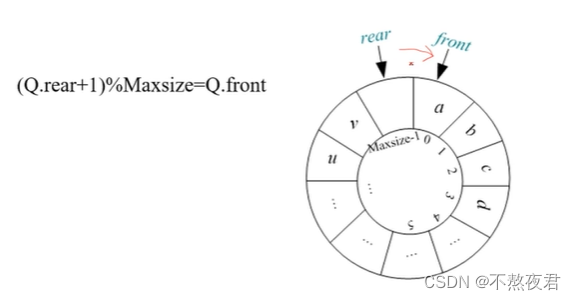
为了方式”假溢出“,我们通常使用循环队列


注意图中的表达式。
队列空和队列满的表达式:

我们在这里浪费了一个空间,方便我们来标识队满。
入队:

出队:
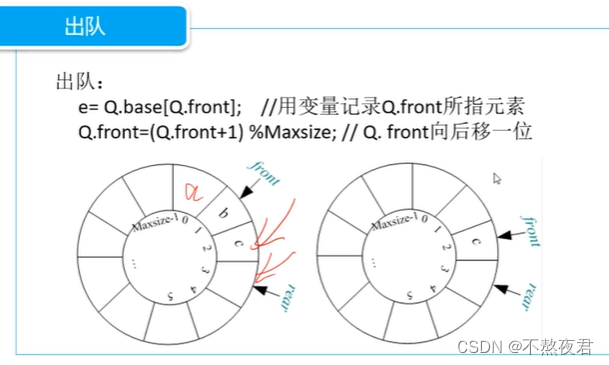
队列中的元素个数计算:

加上Maxsize是为了防止负数,取余Maxsize是为了防止正数。
5.2,链队
2.4,栈完整代码和算法分析
顺序栈完整代码如下:
#include<iostream>
using namespace std;
#define Maxsize 100
typedef struct SqStack {
int *top;
int *base;
}SqStack;
bool InitStack(SqStack &S){
S.base = new int[Maxsize];
if(!S.base){
return false;
}
S.top = S.base; //空栈条件
return true;
}
bool Push(SqStack &S,int e){
if((S.top - S.base) == Maxsize){//判断栈满
return false;
}
*S.top = e;//只需要把值存入这个指针指向的内存地址就好
S.top++;
return true;
}
bool Pop(SqStack &S,int &e){
if (S.base == S.top){//栈空
return false;
}
e = *(S.top - 1);
S.top--; //栈顶指针减1,将栈顶元素赋给e
return true;
}
int GetTop(SqStack &S){
int z;
if(S.top != S.base){
z = *(S.top-1);//要记得先对栈顶指针减一,再取元素,因为栈顶指针一直为空(但是实际上不为空),但是我们不需要移动栈顶指针
return z;
}
}
int main(){
int n,x;//n存储元素个数,x存储入栈元素
SqStack S;
if(InitStack(S)){
cout << "初始化栈成功!" << endl;
} else{
cout << "初始化栈失败!" << endl;
return 0;
}
cout << "请输入入栈元素个数n:";
cin >> n;
cout << endl << "请输入入栈元素x(用空格分割):";
while(n--){
cin >> x;
if(Push(S,x)){
cout << "入栈成功!" << endl;
} else{
cout << "入栈失败!" << endl;
return 0;
}
}
cout << "元素依次出栈:" << endl;
while(S.top!=S.base)//如果栈不空,则依次出栈
{
/*
GetTop(S):输出栈顶元素
Pop(S, x); 栈顶元素出栈,并且将元素指针下移一位
*/
cout<<GetTop(S)<<"\t";//输出栈顶元素
Pop(S, x); //栈顶元素出栈
}
return 0;
}解读
和链栈不同,这里创建的顺序栈的结构体如下:
typedef struct SqStack {
int *top;
int *base;
}SqStack;当我们初始化一个栈的时候,会让结构体中的top和base指针同时指向一个数组,如下:
bool InitStack(SqStack &S){
S.base = new int[Maxsize];
if(!S.base){
return false;
}
S.top = S.base; //空栈条件
return true;
}我们在对顺序栈出入栈的时候,top指针(栈顶指针)上下移动,这样便可以控制出入栈元素存入在数组中的位置。所以说我们的数据还是存储在我们新建的数组中。
运行示例:

链栈完整代码如下:
#include<iostream>
using namespace std;
typedef struct SqStack {
int data;
struct SqStack *next;
}SqStack, *LinkSqStack;
//初始化栈
bool InitSqStack(LinkSqStack &sq,int e) {
sq = new SqStack;
sq->data = e;
sq->next = NULL;
if(!sq){
return false;
}
return true;
}
//入栈
void Push(LinkSqStack &sq,int x){
LinkSqStack p;
p = new SqStack;
p->data = x;
p->next = sq;
sq = p;
}
//出栈
void Pop(LinkSqStack &sq) {
if(sq){
sq = sq->next;//sq指针移动到下一位
}
}
//取栈顶元素,这个对于链栈来说sq指针就是栈顶元素,所以不用在调用了,这个方法如果写了,好鸡肋呀!哈哈哈
//但是工作的时候增加代码量还是不错的哈哈哈
//LinkSqStack GetElem(LinkSqStack sq){
// if(sq){
// return sq;
// }
//}
int main(){
LinkSqStack sq;//创建一个栈顶节点指针,注意这个栈顶结点也有data,不为空
int n,x,e;//n存储入栈元素个数,x存储入栈元素,e用来初始化第一个元素
cout << "请输入初始化元素e:";
cin >> e;
if(!InitSqStack(sq,e)) {
cout << "初始化栈失败!";
return 0;
}
cout << "请输入入栈元素个数n:";
cin >> n;
cout << "请输入入栈元素x(用空格分割):";
while(n--){
cin >> x;
Push(sq,x);
}
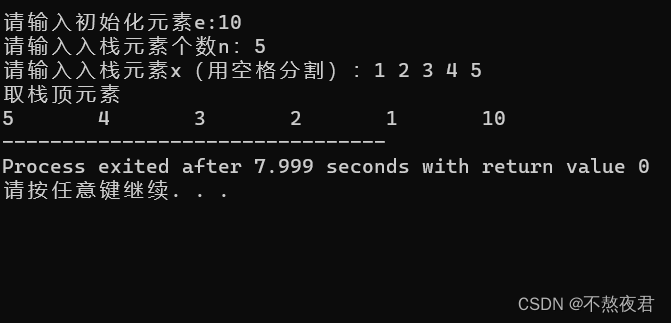
cout << "取栈顶元素" << endl;
while(sq){//当指针指向栈底元素时,该循环还会执行一次,然后sq就会为NULL
cout << sq->data << "\t";
Pop(sq);
}
return 0;
} 解读
和顺序栈不同,链栈中的元素,都是存储在我们自己创建定义的结构体类型的节点中,其实和我们的链表类似,只不过操作的方式不一样。
typedef struct SqStack {
int data;
struct SqStack *next;
}SqStack, *LinkSqStack;出入栈:
//入栈
void Push(LinkSqStack &sq,int x){
LinkSqStack p;
p = new SqStack;
p->data = x;
p->next = sq;
sq = p;
}
//出栈
void Pop(LinkSqStack &sq) {
if(sq){
sq = sq->next;//sq指针移动到下一位
}
}运行示例:
2.5,队列的完整代码和算法分析
链队完整代码:
#include<iostream>
using namespace std;
#define Maxsize 10
typedef struct SqQueue {
int *base;//基指针,指向数组的头部
int front,rear;//头指针和尾指针
}SqQueue;
bool InitQueue(SqQueue &S){
S.base = new int[Maxsize];//指向数组的头部
if(!S.base){
return false;
}
S.front = 0;//头指针和尾指针队空时,全都指向 S.base[0]
S.rear = 0;
return true;
}
void EnQueue(SqQueue &S,int x){
if((S.rear+1)%Maxsize == S.front){
cout << "栈满,无法入栈" << endl;
}
S.base[S.rear]=x; //新元素插入队尾
S.rear = (S.rear+1)%Maxsize;//队尾指针加1
}
int QueueLength(SqQueue S){
return (S.rear-S.front+Maxsize)%Maxsize;//计算队列元素的表达式
}
int GetHead(SqQueue S){
if (S.front!=S.rear) //队列非空
return S.base[S.front];
return -1;
}
bool DeQueue(SqQueue &S, int &x) {//删除S的队头元素,用x返回其值
if(S.front == S.rear){//判断栈是否空
return false;
}
x = S.base[S.front];
S.front = (S.front + 1)%Maxsize;//头指针减一的表达式
return true;
}
int main(){
SqQueue S;
int n,x;//n保存入队元素个数,c存储入队元素
if(!InitQueue(S)){
cout << "初始化错误" << endl;
return 0;
}
cout << "请输入入队元素个数n:";
cin >> n;
cout << "请输入入队元素(用空格分割元素)x:";
while(n--){
cin >> x;
EnQueue(S,x);
}
cout <<"队列内元素个数,即长度:"<<QueueLength(S)<<endl;
cout <<"队头元素:" <<GetHead(S)<<endl;
cout << "依次出队" << endl;
while(true)//如果栈不空,则依次出栈
{
if(DeQueue(S,x))
cout<<x<<"\t";//出队元素
else
break;
}
cout <<endl;
cout <<"队列内元素个数,即长度:"<<QueueLength(S)<<endl;
return 0;
}注意点:
1,入队时,要判断队是否已满,判断条件要理解并熟记
(S.rear+1)%Maxsize == S.front
2,入队后,队尾指针加一;S.rear = (S.rear+1)%Maxsize
3,出队时,判断队是否空,S.front!=S.rear
4,出队后,队头指针加一;S.front = (S.front + 1)%Maxsize;
5,计算队列元素个数;(S.rear-S.front+Maxsize)%Maxsize;
2.6,数组
知识点概述


数据存储:

使用sizeof()函数来获得某种数据类型的所占字节
按行存储:


按列存储:



小试炼:

我一上来就算错了,还是踩坑了hhh,要牢记呀!
从一开始的计算方式:


计算这个元素前面有多少个元素,而不包含他本身。
课后作业:

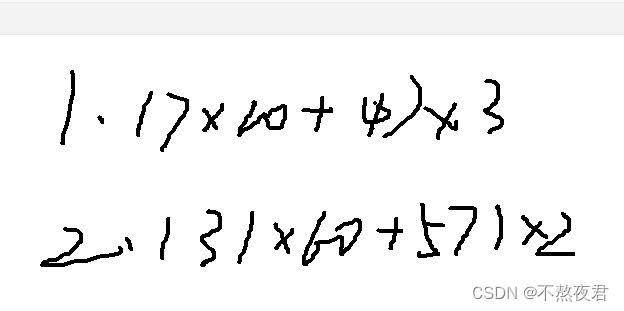
2.7,压缩矩阵
1,概述

1.1,对称矩阵


按行存储下三角矩阵:



k代表的是,元素在一维数组中存储的位置。

两种方法:
1,先包含这个元素构成一个完整的三角形,然后再减一去除这个元素。
2,先算第i+1行上面的元素所构成的三角形,然后再当前i+1行剩余的元素


注意:要是本来是个下三角矩阵,而他给的元素i

1.2,三角矩阵

压缩前存储元素个数:n^2
压缩后存储元素个数:n(n+1) /2
上三角存储元素:
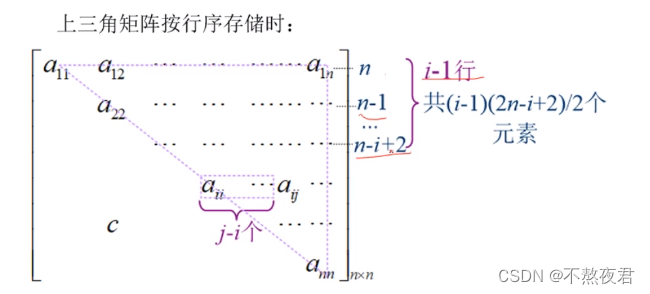
i-1 = n -(n-i+2)+1;

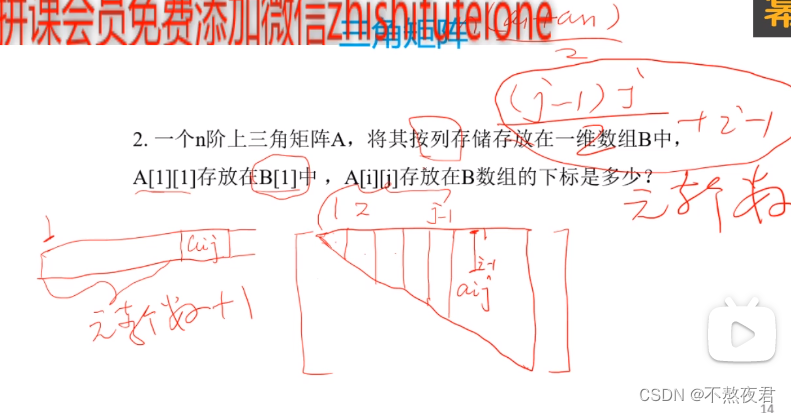
小试炼

注意:这题是从1开始存储的,与0开始寻出的不同
1.3,对角矩阵

存储对角矩阵:

注意:只可以去除最上面和最下面两行的0

总结:千万注意,数组的存储是从0开始还是一开始
小试炼:

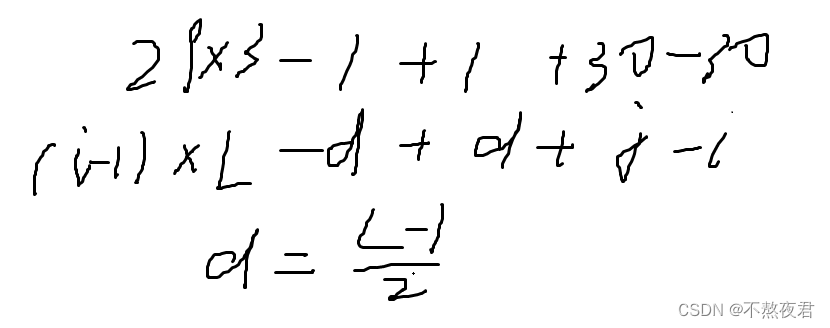

3,BF算法和KMP算法
1,字符串
1.1,使用size()和length()函数,可以返回当前调用元素的字符串的字符个数。
1.2 ,假如你使用cin来接收的字符串中含有空格,则输入程序会终止,我们可以使用getline(cin,s)【s表示要输入的字符串】函数来读入字符串。

2,字符串的存储
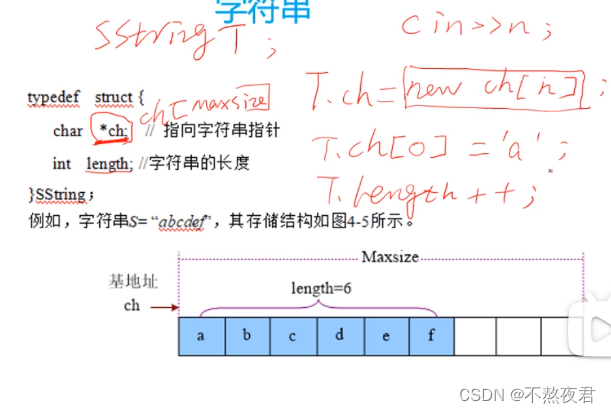
2.1,字符串顺序存储



存在溢出的风险。
2.2,字符串链式存储(很少用)

字符串使用普通的链式存储的的话,每一个节点只存储一个字符串,虽然插入删除方便,但是会浪费大量的空间,其实也不是浪费,存储的效率太低了。
如果采取块链存储的话(如上,三个元素一组),除非你对字符串的添加和删除操作很少,或者基本没有,否则添加和删除操作会导致大量的元素移动。
3,模式匹配

3.1,BF算法思想


3.2,BF算法复杂度
最好的情况时间复杂度为O(n+m)。

最好的情况时间复杂度为O(n*m)。


4,KMP算法

特点:i不回退,j的回退位置

j的回退位置:


没有相等的公共前后缀的时候,还是从子串的第一个位置开始比较。使用next[]数组来存储l+1,就是公共前后缀所包含的字符个数加一,也就是j要回退的位置。

4.1,疑问

我们可以通过j来推出j+1.



求next[]数组

主程序

3.1,BF算法完整代码和算法分析
#include<iostream>
#include<cstring>
using namespace std;
int BF(string s,string t,int op){
int i=op,j=1,sum=0;//sum用来保存比较次数
int slen = s.size();
int tlen = t.length();
cout << slen << endl << tlen << endl;
while(i <= slen && j <= tlen){
sum++;
//cout << "s[i-1]:" << s[i-1] << endl;
if(s[i-1] == t[j-1]){//如果字符相等,则指针都加1
i++;
j++;
}else{//如果字符不相等,则返回上一轮比较的节点的下一个节点
i = i-j+2;//公式
j = 1;
}
}
cout << "匹配次数:" << sum-1 <<endl;
if(j > tlen){
//cout << "j:" << j << endl;
return i-tlen;
}else{
return -1;
}
}
int main(){
string s,t;//主串和子串
int op; //指定从什么位置开始匹配,注意不要输入下标,不要从0开始
getline(cin,s);
getline(cin,t);
cin >> op;
cout << "在位置" << BF(s,t,op) << "成功匹配";
}对以上的代码,可能最后有疑惑的地方有两个!
1,i = i-j+2;//公式 怎么来的?
2,为什么比较成功地位置是i-tlen?
1,首先,我们来看下面这张图主串abcabcd,子串abcd,在第一轮比较的时候,当比较到a和d的时候,第一轮比较终止,我们要计算下一轮比较开始的位置,通过计算得到下一个在主串比较的位置是2:b,然后依次类推。
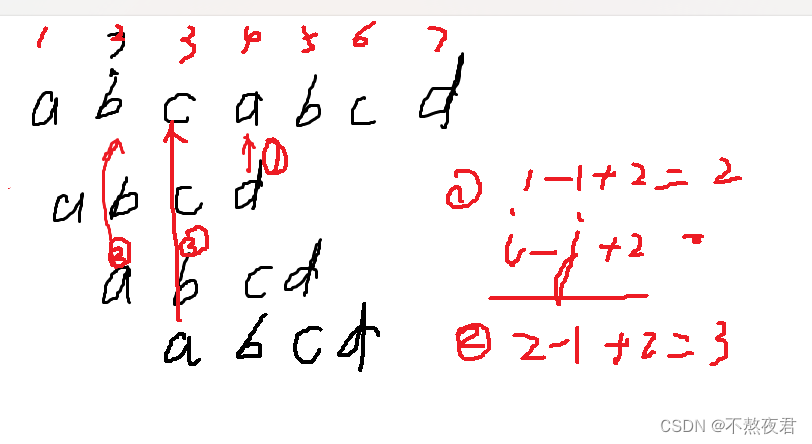
切不可在如下的位置写上i++,因为这个表达式起不到回溯的效果。大家可以用上面的例子代入试一下。
2,在如下的例子中,我们可以很轻易的知道,一共比较了5次,最后一次i=6,j=3.

输入示例:

3.2,KMP算法完整代码如下:
#include<iostream>
#include<string>
using namespace std;
int next[1000];
void getNext(string t){
int k = 0,j = 1;
next[1] = 0;
while(j < t.length()){
if(k == 0 || t[k-1]==t[j-1]){
next[++j] = ++k;
}else{
k = next[k];
}
}
for(int i = 1;i <= t.length();i++){
cout << "next[" << i << "]:" << next[i] << endl;
}
}
int KMP(string s,string t, int op){
getNext(t);
int i = op, j = 1,sum = 0;//这里的i和j都代表的是长度而不是字符串的下标
int slen = s.length();
int tlen = t.length();
while(i<=slen && j<=tlen){//比较长度是否大于字符串本身长度
sum++;
if(s[i-1] == t[j-1]){//相等则i和j指针都加一
i++;
j++;
}else{//不相等时,i指针不动,j指针回退到next[j]
j = next[j];
}
}
cout << "匹配次数:" << sum <<endl;
if(j > tlen){
cout << "j:" << j << endl;
cout << "i:" << i << endl;
return i-tlen;
}else{
return -1;
}
}
int main(){
string s,t;//主串和子串
int op; //指定从什么位置开始匹配,注意不要输入下标
getline(cin,s);
getline(cin,t);
cin >> op;
cout << "在位置" << KMP(s,t,op) << "成功匹配";
}运行示例:

首先我们来看看是如何计算出next[]数组的。
算法如下:
void getNext(string t){
int k = 0,j = 1;
next[1] = 0;
while(j < t.length()){
if(k == 0 || t[k-1]==t[j-1]){
next[++j] = ++k;
}else{
k = next[k];
}
}
for(int i = 1;i <= t.length();i++){
cout << "next[" << i << "]:" << next[i] << endl;
}
}过程如下:

然后我们再来看看KMP算法如何执行
算法如下:
int KMP(string s,string t, int op){
getNext(t);
int i = op, j = 1,sum = 0;//这里的i和j都代表的是长度而不是字符串的下标
int slen = s.length();
int tlen = t.length();
while(i<=slen && j<=tlen){//比较长度是否大于字符串本身长度
sum++;
if(s[i-1] == t[j-1]){//相等则i和j指针都加一
i++;
j++;
}else{//不相等时,i指针不动,j指针回退到next[j]
j = next[j];
}
}
cout << "匹配次数:" << sum <<endl;
if(j > tlen){
cout << "j:" << j << endl;
cout << "i:" << i << endl;
return i-tlen;
}else{
return -1;
}
}当在位置4时,由于a!=b,这时j回退到next[j] = 1,,也就是说子串又从头开始比较,但是主串从比较失败的地方再次开始比较,主串的i指针不会回退。
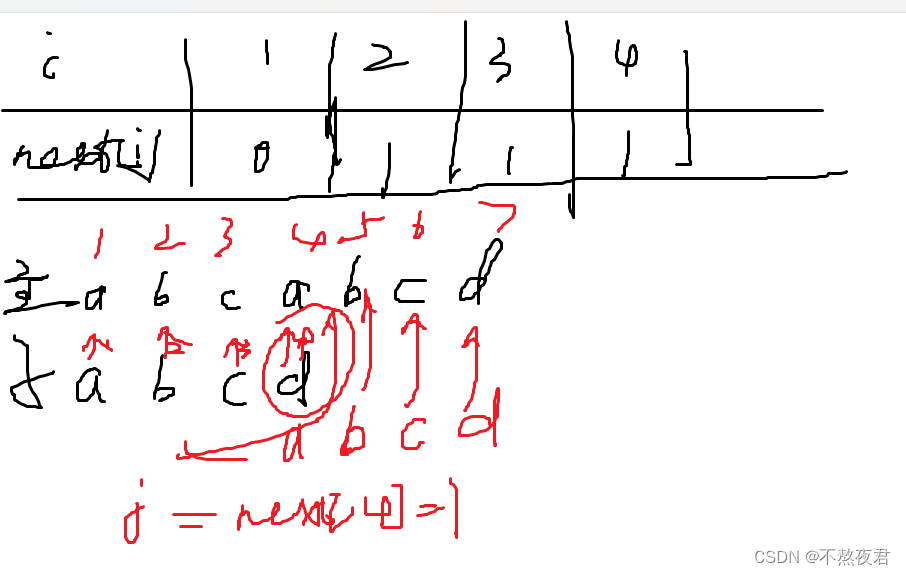
4,二叉树的存储和遍历
1,树





1.2,树的存储结构
链式存储用的多一点。

树的三种顺序表示法:
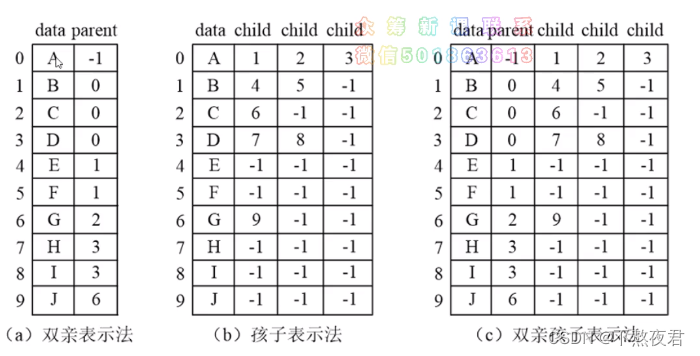
-1表示不存在。
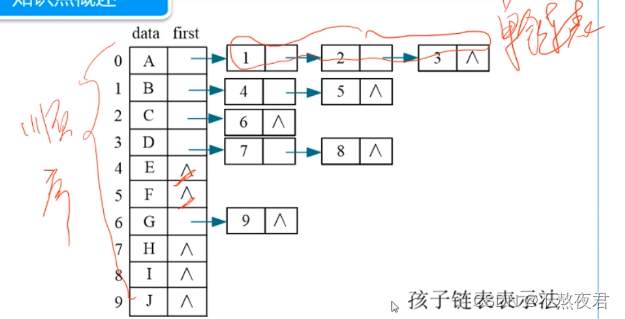
树的链式表示法:


2,二叉树

性质:


顺序存储:
不是完全二叉树就补0
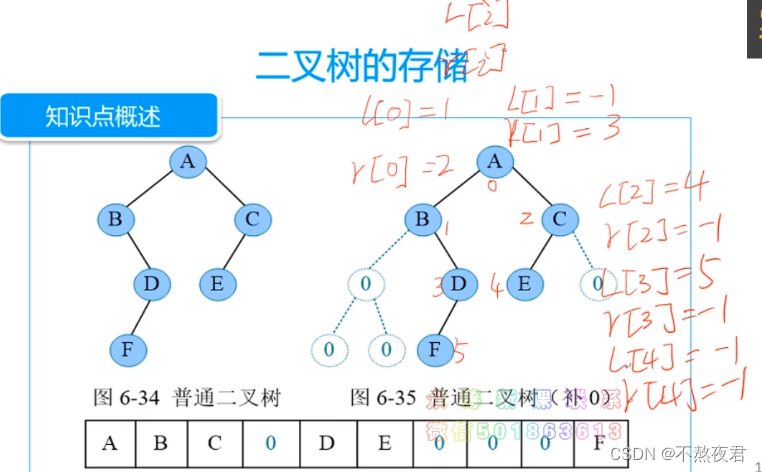
可以使用一个数组,也可以使用两个数组
但是使用两个数组的时候,我们需要指明树的根。如上图。
链式存储:
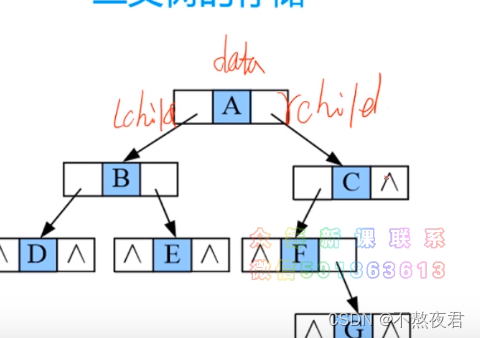
3,遍历二叉树
遍历的秘诀:遍历到那个节点就把这个节点当作更节点
3.1,先序遍历
遍历顺序:先根,后左,再右

先序:ABDECFG

先序:ABCDEFGHJI

3.2,中序遍历
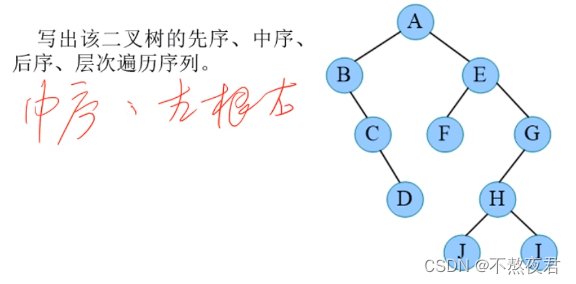
遍历顺序:先左,后根,再右

中序遍历:DBEAFGC

中序:BCDAFEJHIG
3.3,后序遍历

后序:DEBGFCA

后序:DCBFJIHGEA

3.4,层次遍历
同一层从左向右遍历

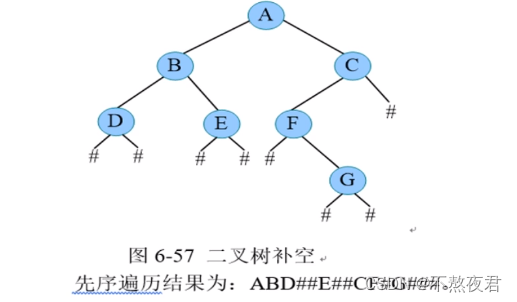
4,创建二叉树

5,还原二叉树
注意:只有给出中序和后序,或者中序和先序才可以还原出树。中序遍历必不可少。

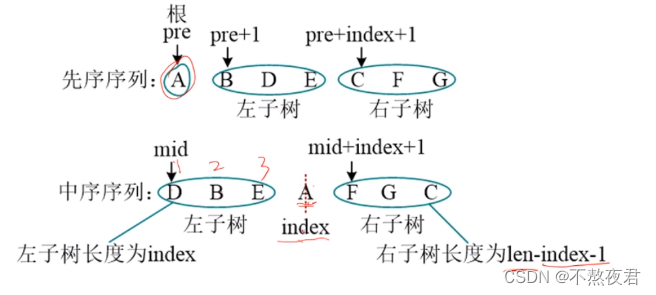
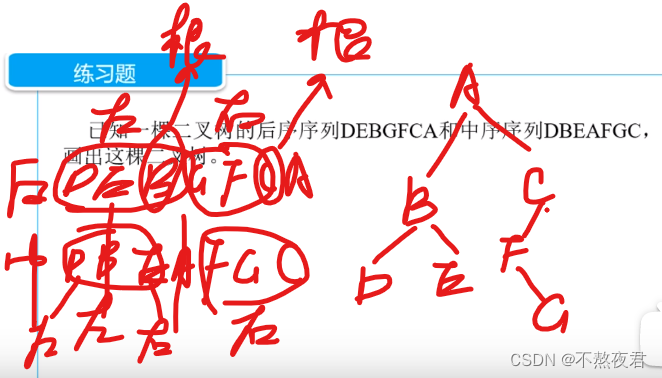
练习:
4.1,二叉树的完整代码和算法分析:
遍历二叉树,完整代码如下:
#include<iostream>
#include <queue>//引入队列头文件
using namespace std;
typedef struct Bnode{
char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
//先序遍历创建二叉树
void Createtree(Btree &T){//传入根节点
char p;
cin >> p;
if(p!='#'){
T = new Bnode;
T->data = p;
Createtree(T->lchild);
Createtree(T->rchild);
}else{
T = NULL;
}
}
//先序遍历输出二叉树
void preNode(Btree T){//传入根节点
if(T){
cout << T->data << "\t";
preNode(T->lchild);
preNode(T->rchild);
}
}
//中序遍历输出二叉树
void inNode(Btree T){
if(T){
inNode(T->lchild);
cout << T->data << "\t";
inNode(T->rchild);
}
}
//后序遍历输出二叉树
void posNode(Btree T){
if(T){
posNode(T->lchild);
posNode(T->rchild);
cout << T->data << "\t";
}
}
//层次遍历输出二叉树
bool LevelNode(Btree T){
Btree p;
queue<Btree> Q;
if(T){
Q.push(T);
}else{
return false;
}
while(!Q.empty()){
p=Q.front();//取出队头元素作为当前扩展结点livenode
Q.pop(); //队头元素出队
cout <<p->data<<"\t";
if(p->lchild){
Q.push(p->lchild); //左孩子指针入队
}
if(p->rchild){
Q.push(p->rchild); //右孩子指针入队
}
}
return true;
}
int main()
{
Btree mytree;
cout<<"按先序次序输入二叉树中结点的值(孩子为空时输入#),创建一棵二叉树"<<endl;
Createtree(mytree);//创建二叉树
cout<<endl;
cout<<"二叉树的先序遍历结果:"<<endl;
preNode(mytree);//先序遍历二叉树
cout<<endl;
cout<<"二叉树的中序遍历结果:"<<endl;
inNode(mytree);//中序遍历二叉树
cout<<endl;
cout<<"二叉树的后序遍历结果:"<<endl;
posNode(mytree);//后序遍历二叉树
cout<<endl;
cout<<"二叉树的层次遍历结果:"<<endl;
LevelNode(mytree);//层次遍历二叉树
return 0;
}运行实例:
还原二叉树
#include<iostream>
#include <algorithm>
using namespace std;
typedef struct Bnode{
char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
//通过前序遍历和中序遍历还原二叉树
Btree pre_mid_createBiTree(char *pre,char *mid,int len){
//作用1,判断是否有节点,结束递归的标志
if(len == 0){
return NULL;
}
char p = pre[0];//保存根节点
int index = 0;//记录左子树有多少个节点,也可以通过len-1-index算出右子树
while(mid[index] != p){//找寻根节点在中序中的位置
index++;
}
cout << index << endl;
Btree T = new Bnode;//创建新的节点保存这个节点
T->data = p;
T->lchild = pre_mid_createBiTree(pre+1, mid, index);//创建左子树
//pre+1:根节点的位置,mid:中序遍历不用做处理,因为左子树的创建,只需要从mid
//的0位置开始遍历,index在这里标识了左子树的节点个数,
T->rchild = pre_mid_createBiTree(pre+index+1,mid+index+1,len-index-1);
//pre+index:是前序遍历中的根节点,pre+index+1:是右子树开始的位置
//mid+index:是中序遍历中的根节点的位置,mid+index+1:也是右子树开始的位置
//len-index-1:标识着右子树的节点数
return T;
}
Btree pro_mid_createBiTree(char *last,char *mid,int len){
if(len == 0){
return NULL;
}
char p = last[0];
int index = 0;
while(mid[index] != p){
index++;
}
cout << index << "\t";bg
Btree T = new Bnode;
T->data = p;
T->lchild = pro_mid_createBiTree(last+index+1, mid, index);
T->rchild = pro_mid_createBiTree(last+1,mid+index+1,len-index-1);
return T;
}
//通过后序遍历和中序遍历还原二叉树
//Btree pro_mid_createBiTree(char *last,char *mid,int len){
// if(len == 0){
// return NULL;
// }
// char p = last[len-1];
// int index = 0;//因为是在中序遍历里面找,所以不用写last.size()-1
// while(mid[index] != p){
// index++;
// }
// Btree T = new Bnode;
// T->data = p;
// T->lchild = pro_mid_createBiTree(last-1 ,mid ,index);
// T->rchild = pro_mid_createBiTree(last+index,mid+index+1,len-index-1);
// return T;
//}
//前序遍历输出
void pre_order(Btree T){
if(T){
cout << T->data << "\t";
pre_order(T->lchild);
pre_order(T->rchild);
}
}
//后序遍历输出
void pro_order(Btree T){
if(T){
pro_order(T->lchild);
pro_order(T->rchild);
cout << T->data << "\t";
}
}
int main()
{
Btree T;
int n;
char pre[100],mid[100],last[100];
cout<<"1. 前序中序还原二叉树\n";
cout<<"2. 后序中序还原二叉树\n";
cout<<"0. 退出\n";
int choose=-1;
while(choose!=0)
{
cout<<"请选择:";
cin>>choose;
switch (choose)
{
case 1://前序中序还原二叉树
cout<<"请输入结点的个数:"<<endl;
cin>>n;
cout<<"请输入前序序列:"<<endl;
for(int i=0;i<n;i++)
cin>>pre[i];
cout<<"请输入中序序列:"<<endl;
for(int i=0;i<n;i++)
cin>>mid[i];
T=pre_mid_createBiTree(pre,mid,n);
cout<<endl;
cout<<"二叉树还原成功,输出其后序序列:"<<endl;
pro_order(T);
cout<<endl<<endl;
break;
case 2://后序中序还原二叉树
cout<<"请输入结点的个数:"<<endl;
cin>>n;
cout<<"请输入后序序列:"<<endl;
for(int i=0 ;i<n;i++)
cin>>last[i];
cout<<"请输入中序序列:"<<endl;
for(int i=0 ;i<n;i++)
cin>>mid[i];
reverse(last,last+n);
cout << last;
T=pro_mid_createBiTree(last,mid,n);
cout<<endl;
cout<<"二叉树还原成功,输出其先序序列:"<<endl;
pre_order(T);
cout<<endl<<endl;
break;
}
}
return 0;
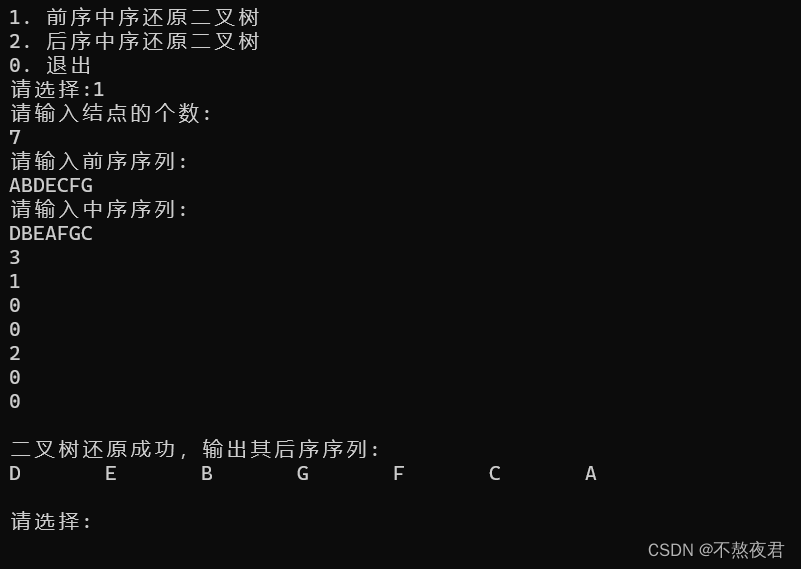
}运行实例:
统计节点数和叶子树
#include<iostream>
using namespace std;
typedef struct Bnode{
char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
//先序遍历创建二叉树
void Createtree(Btree &T){//传入根节点
char p;
cin >> p;
if(p!='#'){
T = new Bnode;
T->data = p;
Createtree(T->lchild);
Createtree(T->rchild);
}else{
T = NULL;
}
}
//统计叶子节点
int LeafCount(Btree T){
int n = 0;
if(T== NULL){
//cout << "这是个空树" << endl;
return 0;
}else{
//如果T->lchild == NULL && T->rchild == NULL
//则表示这是一个叶子节点
if(T->lchild == NULL && T->rchild == NULL){
return 1;
}else{
return LeafCount(T->lchild)+LeafCount(T->rchild);
}
}
}
//统计节点数
int NodeCount(Btree T){
if(T==NULL){
return 0;
}else{
return NodeCount(T->lchild)+NodeCount(T->rchild)+1;
}
}
int main(){
Btree T;
cout << "请输入先序遍历节点顺序:" << endl;
Createtree(T);
cout << "叶子节点有:" << LeafCount(T) << endl;
cout << "节点数有:" << NodeCount(T) << endl;
return 0;
} 运行实例:

部分代码解释:
//统计节点数
int NodeCount(Btree T){
if(T==NULL){
//此节点为空,直接不计数返回0
return 0;
}else{
//其实这个代码就是说返回左子树节点和右子树节点
//最后的加一其实加的是根节点
//注意:请把每一个节点都当作根节点
return NodeCount(T->lchild)+NodeCount(T->rchild)+1;
}
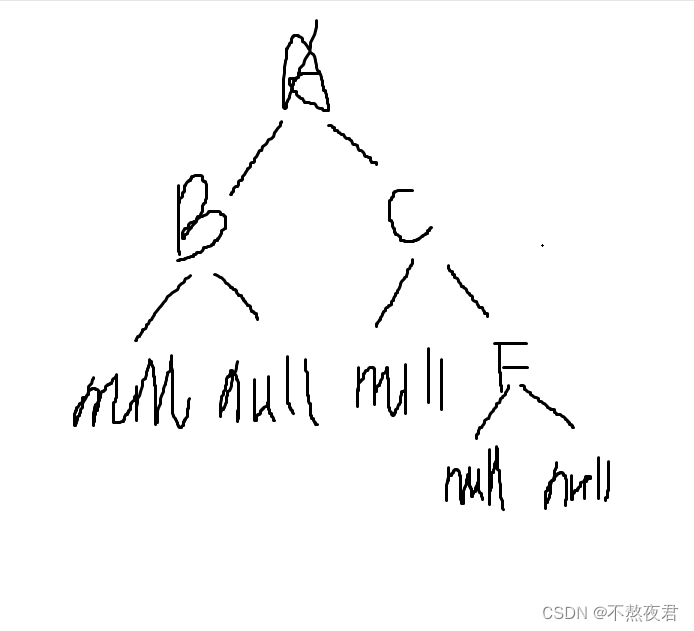
}
计算树的深度
#include <iostream>
using namespace std;
typedef struct Bnode /*定义二叉树存储结构*/
{ char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
void Createtree(Btree &T) /*创建二叉树函数*/
{
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
char ch;
cin >> ch;
if(ch=='#')
T=NULL; //递归结束,建空树
else{
T=new Bnode;
T->data=ch; //生成根结点
Createtree(T->lchild); //递归创建左子树
Createtree(T->rchild); //递归创建右子树
}
}
int Depth(Btree T)//求二叉树的深度
{
int m,n;
if(T==NULL)//如果为空树,深度为0
return 0;
else
{
m=Depth(T->lchild);//递归计算左子树深度
n=Depth(T->rchild);//递归计算左子树深度
if(m>n)//返回深度最大的子树
return m+1;//返回左右子树最大值加1
else
return n+1;
}
}
int main()
{
Btree mytree;
cout<<"按先序次序输入二叉树中结点的值(孩子为空时输入#),创建一棵二叉树"<<endl;
//ABD##E##CF#G###
Createtree(mytree);//创建二叉树
cout<<endl;
cout<<"二叉树的深度为:"<<Depth(mytree)<<endl;
return 0;
}附上一张比较好理解的图:

运行实例:

心得体会
1,体会:
手写完二叉树的遍历,创建,还原和统计之后,我感觉自己对递归的思想有了更深一步的理解,其实递归,就是使用一种可以解决这一类问题的通式,来不断的递推这个问题中的子问题,并且这些子问题可以自动回归,而二叉树就可以使用一种通式来解决二叉树的某一种问题,因为二叉树是一个十分有规律的结构,一棵最简单的树只有四种情况,1,没有左右子树;2,只有左子树;3,只有右子树;4,没有子树。我们解决问题的时候,只要构造出解决这四种情况的通式,所有的问题就可以因迎刃而解。
2,秘诀:
解决二叉树问题的秘诀:把每一个节点都当做根节点,每一个节点都有左子树和右子树(null也是一种子树状态)。
3,构造通式的秘诀:
其实构造通式并不困难,只要可以知道如何解决这个问题的子问题的步骤就好,然后按照步骤来就好。如下代码:
先序遍历创建二叉树
//先序遍历创建二叉树
void Createtree(Btree &T){//传入根节点
char p;
cin >> p;//1,传入节点数据
if(p!='#'){//2,判断这个节点是否为空,不为空就创建根结点,为空则返回0
T = new Bnode;
T->data = p;//2.1,创建并保存根节点
Createtree(T->lchild);//2.2保存好之后,我们开始创建他的左子树
Createtree(T->rchild);//2.3然后开始创建他的右子树
}else{
T = NULL;//2.1,返回空值
}
}5,哈夫曼树和哈夫曼编码
1,哈夫曼树概述


有时候,要是没有给出某个字符的出现频率,就要自己去算,公式为:字符频率=该字符出现的次数/所有字符的个数

哈夫曼树的构建步骤:
1,选没有双亲权值最小的两个节点t1,t2.
2,t1,t2作为左右子树构建一颗新树。
3,新树的根的权值为左右子树t1,t2的和。
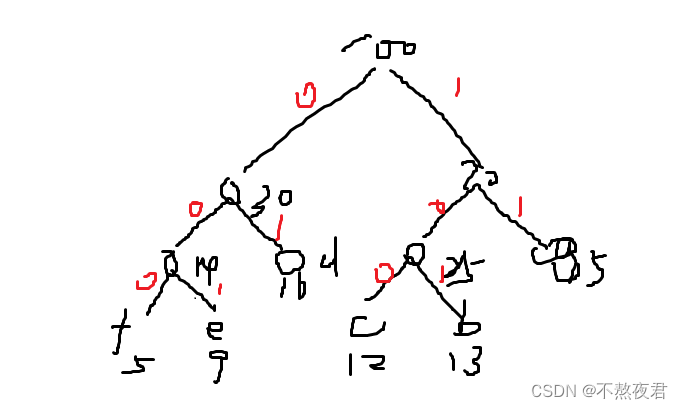
举例
我们可以对字符的出现频率进行扩大,方便于我们计算。

最小的作为左子树,次小的作为右子树,左0,右1

作业:


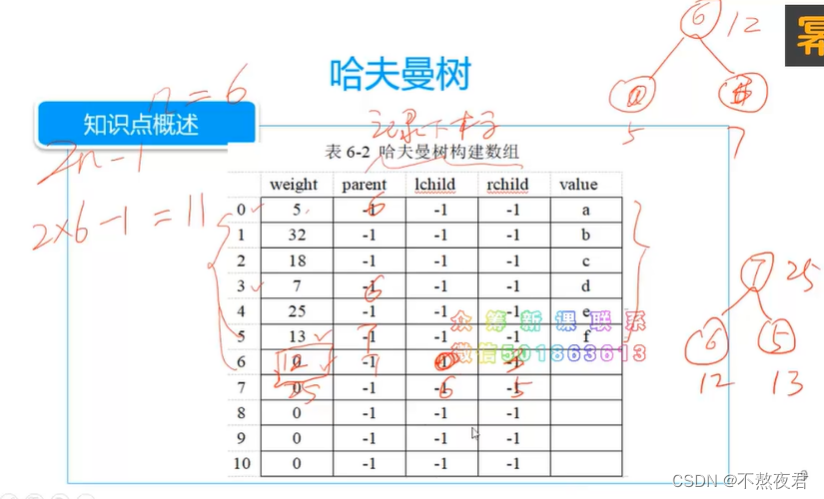
哈夫曼树结构:

n:叶子树,2n-1:总结点数


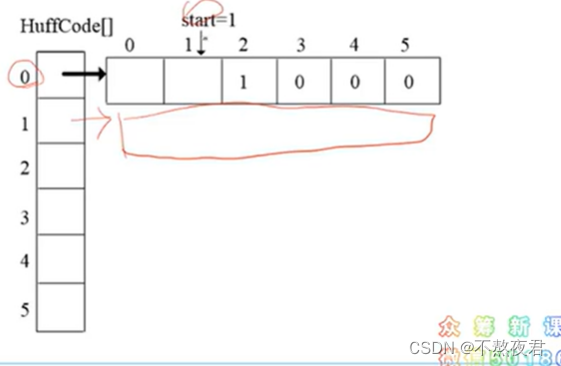
2,哈夫曼编码
使用start标识读取编码的开始位置
存:从后往前存
读:从前往后读

两个指针不断地迭代,不断的指向父亲节点和父亲的父亲节点


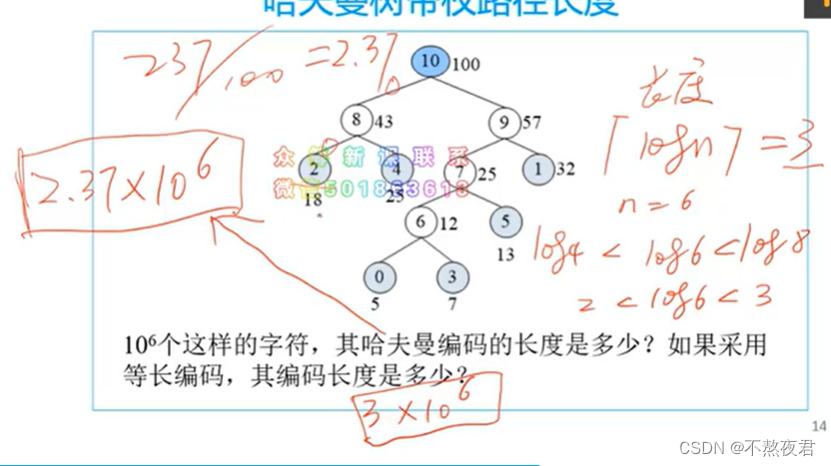
如上图:哈夫曼编码的长度是2.37*10^6,而使用等长编码长度就是3*10^6,
2.37=0.05*4+0.32*2+0.18*2+0.07*4+0.25*2+0.13*3
而3的由来是因为,3位的编码可以表示8种不同的字符,而2位的编码可以表示4种不同的字符,所以要表示6种的不同的字符,只可以使用3位的编码方式。

5.1,哈夫曼树和编码完整代码和算法解析
#include<iostream>
using namespace std;
//预处理不需要加分号
#define MaxSize 100
#define MaxWeight 100
#define MaxLeave 0x3fff
#define MaxNode MaxLeave*2-1
typedef struct HufuNode{
int parent; //记录双亲节点
int lchild; //左孩子
int rchild; //右孩子
double weight; //权重 ,权重是小数时,使用double类型
char value; //字符
}HufuNode;
typedef struct HufuCode{
int start; //记录存储和读取开始的位置
int hfbit[MaxSize]; //保存编码信息,也就是0101的编码
}HufuCode;
//类型名和变量名不可以重名
HufuNode hfNode[MaxNode];//保存节点信息
HufuCode hfCode[MaxLeave];//保存叶子节点信息
//构建哈夫曼树
void HufuTree(HufuNode hfNode[MaxNode],int n){
double m1,m2;
int x1,x2,i,j;
for(i = 0;i < 2*n-1;i++){//初始化,总共要初始化2*n-1个节点
hfNode[i].parent = -1;
hfNode[i].lchild = -1;
hfNode[i].rchild = -1;
hfNode[i].weight = -1;
//hfNode[i].value = '';
}
for(i = 0;i < n;i++){//为叶子节点赋值赋权重
cout<<"请输入叶子节点的值和权重(使用空格分割)"<<i+1<<endl;
cin>>hfNode[i].value>>hfNode[i].weight;
cout << "hfNode[i].value:" << hfNode[i].value << "\t" << "hfNode[i].weight" << hfNode[i].weight << endl;
}
//构建哈夫曼树
for(i = 0;i < n-1;i++){//执行n-1次合并
m1 = m2 = MaxWeight;
x1 = x2 = 0;
for(j = 0;j < n+i;j++){//不断的取最小的两个叶子节点
if(hfNode[j].parent == -1 && hfNode[j].weight < m1){//首先要看这个节点是否有双亲节点
m2 = m1; //有则不参与比较,这也是我们为什么要执行,如下语句的原因
x2 = x1; //hfNode[x1].parent = i+n;
m1 = hfNode[j].weight; //hfNode[x2].parent = i+n;
x1 = j;
}else if(hfNode[j].parent == -1 && hfNode[j].weight < m2){
m2 = hfNode[j].weight;
x2 = j;
}
}
hfNode[i+n].weight = m1 + m2;//新节点的权重等于左右子树权重之和
hfNode[i+n].lchild = x1; //将最小的节点作为新节点的左子树 ,注意不要写成m1
hfNode[i+n].rchild = x2; //将此小的节点作为新节点的右子树 ,注意不要写成m2
hfNode[x1].parent = i+n; //将左子树的双亲节点置为i+n,也就是新节点的位置
hfNode[x2].parent = i+n; //将右子树的双亲节点置为i+n,也就是新节点的位置,也是通过这种方式防止子节点再次参与比较
cout<<"x1.weight and x2.weight in round "<<i+1<<"\t"<<hfNode[x1].weight<<"\t"<<hfNode[x2].weight<<endl;
//cout << "hfNode[x1].parent:" << hfNode[x1].parent <<endl;
}
}
//产生哈弗曼编码
void CHufuCode(HufuCode hfCode[MaxLeave],int n){
HufuCode hc;
int i,j,c,p;//c用来指向当前节点位置,p用来指向节点的父亲节点的下标
for(i = 0;i < n;i++){
hc.start = n-1;
c = i;
p = hfNode[i].parent;
while(p != -1){//当当前节点还有父亲节点,继续循环
if(hfNode[p].lchild == c){//父节点的左子树是否等于当前节点
hc.hfbit[hc.start] = 0;
hc.start--;
//cout << "左子树" << endl;
} else{//节点的右子树是否等于当前节点
hc.hfbit[hc.start] = 1;
hc.start--;
//cout << "右子树";
}
c = p;
p = hfNode[c].parent;
//cout << p << endl;
}
//把叶子结点的编码信息从临时编码cd中复制出来,放入编码结构体数组
for(j = hc.start+1; j < n;j++){//从hc.start+1开始存储编码,start不存
hfCode[i].hfbit[j] = hc.hfbit[j];
}
hfCode[i].start = hc.start;
}
}
int main(){
int n,i,j;
cout << "请输入叶子节点的个数:";
cin >> n;
HufuTree(hfNode,n);
CHufuCode(hfCode,n);
//输出叶子结点的哈弗曼编码
for(i = 0;i < n;i++){
cout << "叶子节点:" << hfNode[i].value << "对应的哈夫曼编码:";
for(j = hfCode[i].start+1;j < n;j++){//也是从hfCode[i].start+1开始读取编码
cout << hfCode[i].hfbit[j];
}
cout << endl;
}
return 0;
} 生成哈夫曼编码的步骤:
1,构建哈夫曼树
1.1,选没有双亲权值最小的两个节点t1,t2.
1.2,t1,t2作为左右子树构建一颗新树。
1.3,新树的根的权值为左右子树t1,t2的和。
//构建哈夫曼树
for(i = 0;i < n-1;i++){//执行n-1次合并
m1 = m2 = MaxWeight;
x1 = x2 = 0;
for(j = 0;j < n+i;j++){//不断的取最小的两个叶子节点
if(hfNode[j].parent == -1 && hfNode[j].weight < m1){//首先要看这个节点是否有双亲节点
m2 = m1; //有则不参与比较,这也是我们为什么要执行,如下语句的原因
x2 = x1; //hfNode[x1].parent = i+n;
m1 = hfNode[j].weight; //hfNode[x2].parent = i+n;
x1 = j;
}else if(hfNode[j].parent == -1 && hfNode[j].weight < m2){
m2 = hfNode[j].weight;
x2 = j;
}
}
hfNode[i+n].weight = m1 + m2;//新节点的权重等于左右子树权重之和
hfNode[i+n].lchild = x1; //将最小的节点作为新节点的左子树 ,注意不要写成m1
hfNode[i+n].rchild = x2; //将此小的节点作为新节点的右子树 ,注意不要写成m2
hfNode[x1].parent = i+n; //将左子树的双亲节点置为i+n,也就是新节点的位置
hfNode[x2].parent = i+n; //将右子树的双亲节点置为i+n,也就是新节点的位置,也是通过这种方式防止子节点再次参与比较
cout<<"x1.weight and x2.weight in round "<<i+1<<"\t"<<hfNode[x1].weight<<"\t"<<hfNode[x2].weight<<endl;
//cout << "hfNode[x1].parent:" << hfNode[x1].parent <<endl;
} 2,生成哈夫曼编码
2.1,从叶子节点开始向上寻找双亲结点,如果当前节点是双亲结点的左子树则编码为0,反之则为1
2.2,重复2.1,知道当前节点没有双亲节点。
for(i = 0;i < n;i++){
hc.start = n-1;
c = i;
p = hfNode[i].parent;
while(p != -1){//当当前节点还有父亲节点,继续循环
if(hfNode[p].lchild == c){//父节点的左子树是否等于当前节点
hc.hfbit[hc.start] = 0;
hc.start--;
//cout << "左子树" << endl;
} else{//节点的右子树是否等于当前节点
hc.hfbit[hc.start] = 1;
hc.start--;
//cout << "右子树";
}
c = p;
p = hfNode[c].parent;
//cout << p << endl;
}
//把叶子结点的编码信息从临时编码cd中复制出来,放入编码结构体数组
for(j = hc.start+1; j < n;j++){//从hc.start+1开始存储编码,start不存
hfCode[i].hfbit[j] = hc.hfbit[j];
}
hfCode[i].start = hc.start;
} 运行示例如下:

哈夫曼树如下:

6,图(邻接矩阵和邻接表)
1,图的概述
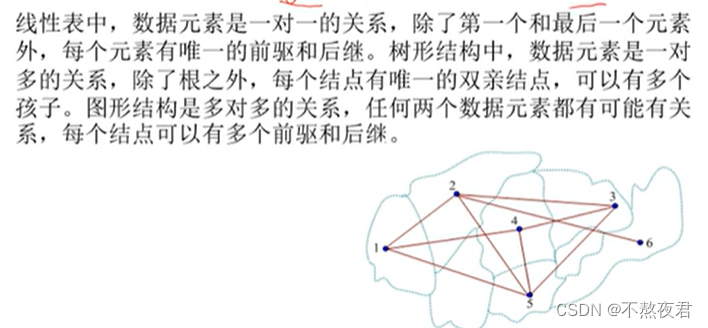
四种数据结构包括:集合,线性,树,图

图中至少有一个顶点,可以没有边。
无向图

有向图

简单图:不含平行边也不含自环

无向完全图和有向完全图
n:顶点
无向完全图边=n(n-1)/2
有向完全图边=n(n-1)



无向图中的概念:
连通图和连通分量

有向图中的概念:
强连通图和强连通分量:

二分图

2,图的存储

2.1,邻接矩阵
1,无向图的邻接矩阵(一定对称)

2,有向图的邻接矩阵(不一定对称 )

3,网的邻接矩阵

邻接矩阵的数据结构

邻接矩阵的优缺点

2.2,邻接表

无向图的邻接表:

有向图的邻接表:
找出度容易,找入度难。
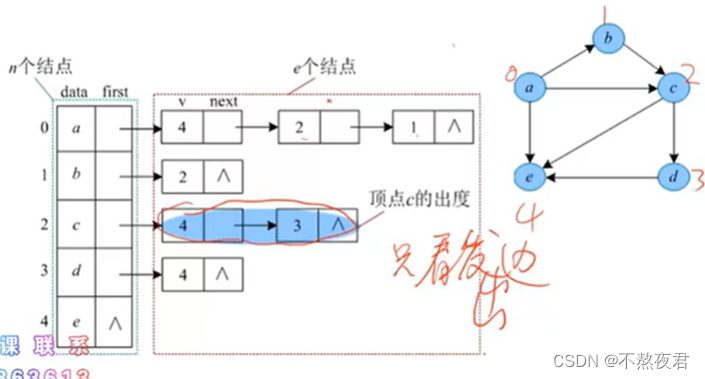




创建邻接表的过程:
1,保存顶点信息
2,输入边(使用头插法实现)
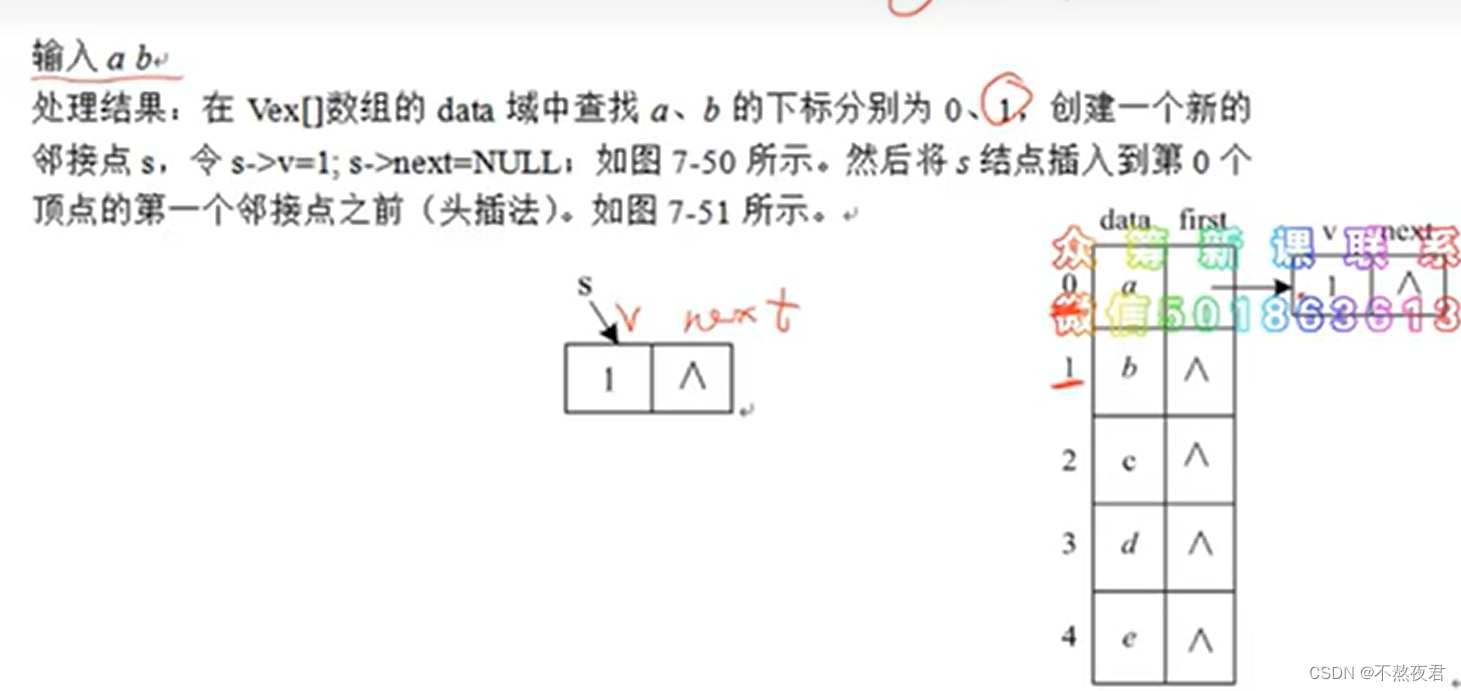

邻接表优缺点:
邻接矩阵遍历所有的邻接点的时间复杂度为O(n^2),空间复杂度为O(n^2),所以说稠密图可以使用邻接矩阵存储。
邻接表遍历所有邻接点的时间复杂度为O(n+e),空间复杂度:O(n+2e)[无向图],O(n+e)[有向图]

6.1,邻接矩阵和邻接表完整代码
示例图:

1,邻接矩阵存储有向图
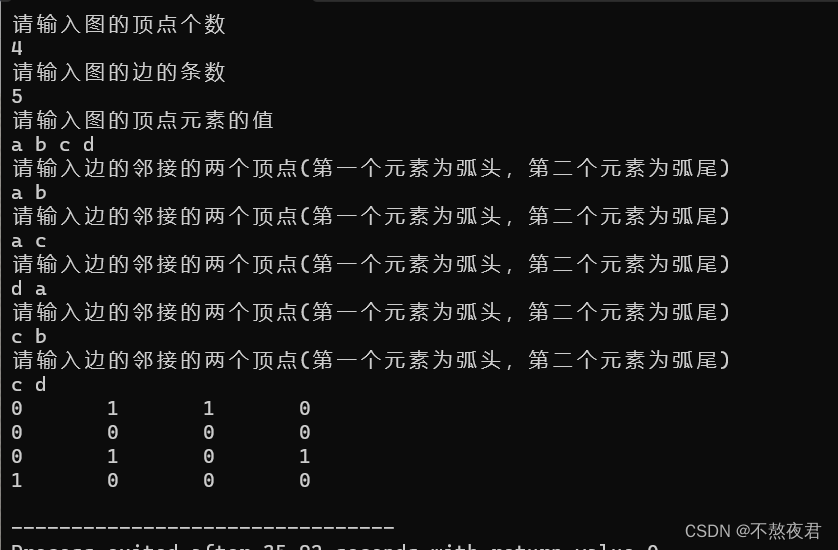
以下代码运行的大致流程:
1,首先我们输入顶点数,边数和相互邻接的两个顶点m,n。
2,查询m和n在顶点表中的位置并且返回。
3,然后在矩阵中找到这两个元素的位置并且——f.Edge[y][z] = 1(这时有向图的做法,存储无向图也只是在这个步骤上做了改动)
//邻接矩阵存储有向图
#include<iostream>
using namespace std;
#define MaxVnum 100 //顶点数最大值
typedef char VexType; //顶点的数据类型,根据需要定义
typedef int EdgeType; //边上权值的数据类型,若不带权值的图,则为0或1
typedef struct FMGragh{
int Enum,Vnum; //存储顶点的个数和边的个数
EdgeType Edge[MaxVnum][MaxVnum];
VexType v[MaxVnum];
}FMGragh;
//寻找顶点在顶点表中的位置
int Locatevex(FMGragh f,char a){
int i;
for(i=0;i < f.Vnum;i++){
if(f.v[i] == a){
return i;
}
}
//cout << "无法找到对应顶点" << endl;
return -1;
}
//初始化有向图
void CreateF(FMGragh &f){
int i,j,y,z;
char m,n;
cout << "请输入图的顶点个数" << endl;
cin >> f.Vnum;
cout << "请输入图的边的条数" << endl;
cin >> f.Enum;
cout << "请输入图的顶点元素的值" << endl;
for(i = 0;i < f.Vnum;i++){
cin >> f.v[i];
}
for(j = 0;j < f.Enum;j++){
cout << "请输入边的邻接的两个顶点(第一个元素为弧头,第二个元素为弧尾)" << endl;
cin >> m >> n;
y = Locatevex(f,m); //寻找m元素在顶点表中的位置,弧头
z = Locatevex(f,n); //寻找n元素在顶点表中的位置,弧尾
if(y != -1 && z != -1){
//a.Edge[y][z] = a.Edge[z][y] = 1;
f.Edge[y][z] = 1;
}else{
cout << "无法找到对应顶点,请重新输入" << endl;
j--;
}
}
}
//打印有向图
void printF(FMGragh f){
int i,j;
for(i = 0;i < f.Vnum;i++){
for(j = 0;j < f.Vnum;j++){
cout << f.Edge[i][j] << "\t";
}
cout << endl;
}
}
int main(){
FMGragh f;
CreateF(f);
printF(f);
return 0;
}运行示例:
分析:
首先我们要知道,有向图和无向图我们在用邻接矩阵存储的时候有什么差异:
我们可以看到有向图使用邻接矩阵存储的示意图如下:

无向图使用邻接矩阵存储的示意图如下:

可以看到无向图在邻接矩阵中的存储是对称的,而有向图则不是。所以我们在存储的使用也应当使用不同的策略。
2,邻接矩阵存储无向图
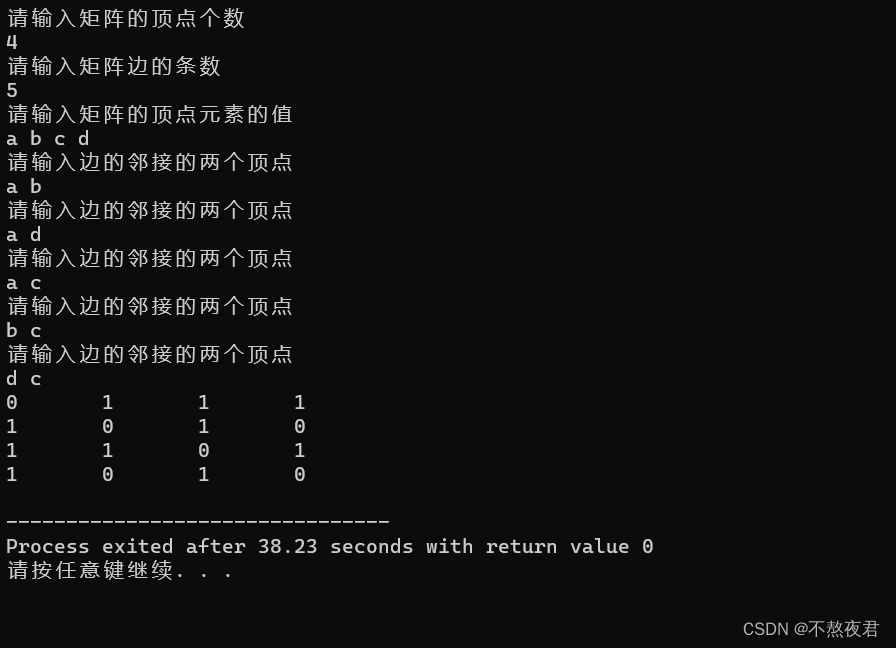
以下代码运行的大致流程:
1,首先我们输入顶点数,边数和相互邻接的两个顶点m,n。
2,查询m和n在顶点表中的位置并且返回。
3,然后在矩阵中找到这两个元素的位置并且——a.Edge[y][z] = a.Edge[z][y] = 1;(这时无向图的做法,存储有向图也只是在这个步骤上做了改动)
//邻接矩阵存储无向图
#include<iostream>
using namespace std;
#define MaxVnum 100 //顶点数最大值
typedef char VexType; //顶点的数据类型,根据需要定义
typedef int EdgeType; //边上权值的数据类型,若不带权值的图,则为0或1
typedef struct AMGragh {
EdgeType Edge[MaxVnum][MaxVnum]; //存储边的信息
VexType v[MaxVnum]; //存储顶点值
int Enum,Vnum; //存储顶点和边的个数
}AMGragh;
//查找顶点所在的位置便且返回
int Locatevex(AMGragh a,char c){
int i;
for(i=0;i < a.Vnum;i++){
if(a.v[i] == c){
return i;
}
}
//cout << "无法找到对应顶点" << endl;
return -1;
}
//初始化邻接矩阵
void CreateL(AMGragh &a){
int i,j,y,z;
char m,n;
cout << "请输入图的顶点个数" << endl;
cin >> a.Vnum;
cout << "请输入图的边的条数" << endl;
cin >> a.Enum;
cout << "请输入图的顶点元素的值" << endl;
for(i = 0;i < a.Vnum;i++){
cin >> a.v[i];
}
for(j = 0;j < a.Enum;j++){
cout << "请输入边的邻接的两个顶点" << endl;
cin >> m >> n;
y = Locatevex(a,m); //寻找m元素在顶点表中的位置
z = Locatevex(a,n); //寻找n元素在顶点表中的位置
if(y != -1 && z != -1){
a.Edge[y][z] = a.Edge[z][y] = 1;
}else{
cout << "无法找到对应顶点,请重新输入" << endl;
j--;
}
}
}
//打印邻接矩阵
void printL(AMGragh a){
int i,j;
for(i = 0;i < a.Vnum;i++){
for(j = 0;j < a.Vnum;j++){
cout << a.Edge[i][j] << "\t";
}
cout << endl;
}
}
int main(){
AMGragh a;
CreateL(a);
printL(a);
return 0;
}运行示例:
3,邻接表存储有向图
以下的代码运行流程如下:
1,首先我们输入图的顶点数和边数。
2,输入顶点值
3,输入相互邻接的顶点
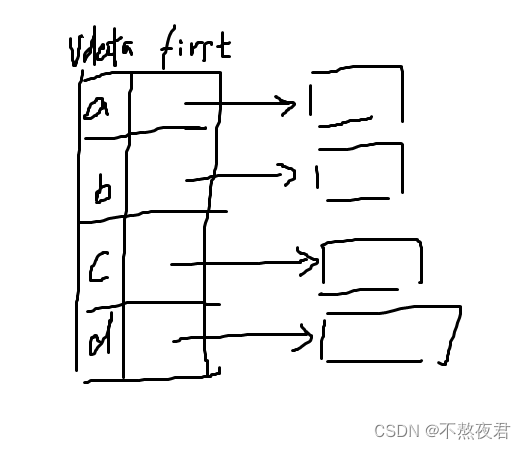
//邻接表存储有向图
#include<iostream>
using namespace std;
#define MaxVnum 100
typedef char NodeType;
typedef struct LNode{ //定义邻接节点数据结构
struct LNode *next; //用于指向下一个邻接节点
NodeType Ndata; //节点中的值
}LNode,*ListNode;
typedef struct LVex{ //定义顶点数据结构
ListNode first; //用于指向第一个邻接节点
NodeType Vdata; //存储顶点信息
}LVex,*ListVex;
typedef struct Vexs{ //用于保存图的简要信息的数据结构
LVex lv[MaxVnum]; //用于线性保存顶点信息
int Enum,Vnum; //用于保存边数和顶点数
}Vexs;
//最好把方法先声明,然后再调用
void Insertedge(Vexs &v);
int LocateVex(Vexs v,NodeType a);
void CreateFG(Vexs &v);
void printFG(Vexs v);
int main(){
Vexs v;
CreateFG(v);
printFG(v);
return 0;
}
//插入边
void Insertedge(Vexs &v){
int i,j,z;
NodeType m,n;
ListNode s;
for(z = 0;z < v.Enum;z++){
cout << "请输入邻接的顶点" << endl;
cin >> m >> n;
i = LocateVex(v,m); //弧头节点的位置
j = LocateVex(v,n); //弧尾节点的位置
cout << "弧头" << i << "\t" << "弧尾" << j << endl;
if(i != -1 && j != -1){
s = new LNode;
s->Ndata = n;
s->next = NULL;
s->next = v.lv[i].first;
v.lv[i].first = s; //注意这里first指针已经指向第一个邻接节点,而不是它本身
cout << "头插法插入" << v.lv[i].first->Ndata << endl;
}else{
cout << "顶点不存在,请重新输入" << endl;
z--;
}
}
}
//用于寻找该字符在顶点线性表中的位置
int LocateVex(Vexs v,NodeType a){
int i;
for(i = 0;i < v.Vnum;i++){
if(v.lv[i].Vdata == a){
return i;
}
}
return -1;
}
//创建邻接表保存有向图
void CreateFG(Vexs &v){
int i;
cout << "请输入有向图的顶点的个数" << endl;
cin >> v.Vnum;
cout << "请输入有向图的边的条数" << endl;
cin >> v.Enum;
cout << "请输入有向图的顶点值" << endl;
for(i = 0;i < v.Vnum;i++){
cin >> v.lv[i].Vdata;
v.lv[i].first = NULL;
}
for(i = 0;i < v.Vnum;i++){//打印输入的顶点
cout << v.lv[i].Vdata << "\t";
}
cout << endl;
Insertedge(v);
}
//打印有向图
void printFG(Vexs v){
int i,j;
ListNode p;
for(i = 0;i < v.Vnum;i++){
//p = v.lv[i].first->next;千万注意这里不可以这么写
p = v.lv[i].first;
cout << "[" << v.lv[i].Vdata << "]:";
while(p){
cout << p->Ndata << "\t";
p = p->next;
}
cout << endl;
}
}
运行示例:

4,邻接表存储无向图
无向图和有向图的存储,只有在存储边的时候,步骤有所改变,它不仅仅插入弧尾,还会插入弧头节点
//邻接表存储无向图
#include<iostream>
using namespace std;
#define MaxVnum 100
typedef char NodeType;
typedef struct LNode{ //定义邻接节点数据结构
struct LNode *next; //用于指向下一个邻接节点
NodeType Ndata; //节点中的值
}LNode,*ListNode;
typedef struct LVex{ //定义顶点数据结构
ListNode first; //用于指向第一个邻接节点
NodeType Vdata; //存储顶点信息
}LVex,*ListVex;
typedef struct Vexs{ //用于保存图的简要信息的数据结构
LVex lv[MaxVnum]; //用于线性保存顶点信息
int Enum,Vnum; //用于保存边数和顶点数
}Vexs;
//最好把方法先声明,然后再调用
void Insertedge(Vexs &v);
int LocateVex(Vexs v,NodeType a);
void CreateFG(Vexs &v);
void printFG(Vexs v);
int main(){
Vexs v;
CreateFG(v);
printFG(v);
return 0;
}
//插入边
void Insertedge(Vexs &v){
int i,j,z;
NodeType m,n;
ListNode s,q;
for(z = 0;z < v.Enum;z++){
cout << "请输入邻接的顶点" << endl;
cin >> m >> n;
i = LocateVex(v,m); //弧头节点的位置
j = LocateVex(v,n); //弧尾节点的位置
cout << "弧头" << i << "\t" << "弧尾" << j << endl;
if(i != -1 && j != -1){
s = new LNode;
s->Ndata = n;
s->next = v.lv[i].first;
v.lv[i].first = s; //注意这里first指针已经指向第一个邻接节点,而不是它本身
q = new LNode;
q->Ndata = m;
q->next = v.lv[j].first;
v.lv[j].first = q;
cout << "头插法插入" << v.lv[i].first->Ndata << endl;
cout << "头插法插入" << v.lv[j].first->Ndata << endl;
}else{
cout << "顶点不存在,请重新输入" << endl;
z--;
}
}
}
//用于寻找该字符在顶点线性表中的位置
int LocateVex(Vexs v,NodeType a){
int i;
for(i = 0;i < v.Vnum;i++){
if(v.lv[i].Vdata == a){
return i;
}
}
return -1;
}
//创建邻接表保存有向图
void CreateFG(Vexs &v){
int i;
cout << "请输入有向图的顶点的个数" << endl;
cin >> v.Vnum;
cout << "请输入有向图的边的条数" << endl;
cin >> v.Enum;
cout << "请输入有向图的顶点值" << endl;
for(i = 0;i < v.Vnum;i++){
cin >> v.lv[i].Vdata;
v.lv[i].first = NULL;
}
for(i = 0;i < v.Vnum;i++){//打印输入的顶点
cout << v.lv[i].Vdata << "\t";
}
cout << endl;
Insertedge(v);
}
//打印有向图
void printFG(Vexs v){
int i,j;
ListNode p;
for(i = 0;i < v.Vnum;i++){
//p = v.lv[i].first->next;千万注意这里不可以这么写
p = v.lv[i].first;
cout << "[" << v.lv[i].Vdata << "]:";
while(p){
cout << p->Ndata << "\t";
p = p->next;
}
cout << endl;
}
}
运行示例:
