需要java安装包和hadoop安装包的可以选择这里下载
链接:https://pan.baidu.com/s/1sQQ-uiwmJvYFPgpVsftL6Q?
提取码:aubt
在这里开始,直接上干货,前面的操作系统安装,与虚拟机的安装都不做赘述了
第一步 预分配ip地址
为虚拟机做Ip预分配,我这里搭建3个节点的hadoop平台
192.168.83.131/24 Hadoop1
192.168.83.132/24 Hadoop2
192.168.83.133/24 Hadoop3
第二步 为虚拟机配置ip (可以选择先配置一台虚拟机,然后拷贝到3台虚拟机上,需要更改,ip地址,hostname, 和添加ssh无密钥登录既可)
(也可以选择一台一台的配置,我这里选择的是一台一台的拷贝)
打开网卡编辑
![]()
配置静态IP地址 将![]() 修改
修改
添加
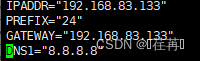
配置DNS节点 使用![]() 进入hosts节点
进入hosts节点
192.168.83.131 Hadoop1
192.168.83.132 Hadoop2
192.168.83.133 Hadoop3

将配置好的节点拷贝到每个节点
![]()
![]()
第三步 关闭防火墙(每个节点都要操作的)
关闭服务
![]()
关闭开机自起
![]()
第四步配置免密登录
生成ssh免密协议
![]()
查看ssh协议(公钥和私钥)
![]()
将主节点的公钥拷贝到特定的文件夹下authorized_keys
![]()
将特定文件拷贝到每个节点
![]()
![]()
将后面的每个节点的公钥追加到authorized_keys
![]()
![]()
会生成一个公钥集合,包含三个节点的公钥

将集合公钥回传到每个节点中
![]()
![]()
验证 ssh hadoop3
到这里前期的虚拟机环境配置成功
第五步 安装jdk和hadoop文件并配置他们的环境变量 (建议先配置一台,然后拷贝到另外两台虚拟机上)
安装jdk
创建文件夹develop/server 解压文件
创建文件夹develop/software 安装包文件
![]()
![]()
上传压缩包
![]()
![]()
检查java的运行版本
![]()
卸载多余java环境
![]()
卸载完成

解压压缩包完成hadoop和java jdk的安装
![]()
![]()
![]()
修改文件名与赋予root权限
![]()
![]()
赋予root权限
![]()
![]()
![]()
配置环境变量
![]()
将java的环境变量和hadoop的环境变量添加到PATH路径下

使配置文件生效
![]()
查看是否配置成功
![]()
![]()
第六步 配置hadoop文件 (建议先配置一台,然后拷贝到另外两台虚拟机上)
配置hadoop文件的java_home
在hadoop/etc/hadoop文件下
修改core_site.xml文件
![]()
<configuration>
<property>
<!--配置hdfs的地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<!--保存临时文件目录,需要在hadoop文件下创建temp目录-->
<name>hadoop.temp.dir</name>
<value>/develop/server/hadoop/temp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
修改hdfs-site.xml
![]()
<configuration>
<property>
<!--主节点地址-->
<name>dfs.namenode.http-address</name>
<value>hadoop1:50070</value>
</property>
<property>
<!--保存临时文件目录,需要在hadoop文件下创建temp目录-->
<name>dfs.namenode.name.dir</name>
<value>file:/develop/server/hadoop/temp/name</value>
</property>
<property>
<!--保存临时文件目录,需要在hadoop文件下创建temp目录-->
<name>dfs.datanode.data.dir</name>
<value>file:/develop/server/hadoop/temp/data</value>
</property>
<property>
<!--备份份数-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--第二节点地址-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<!--配置为false后,可以允许不要检查权限就生成dfs上的文件,需要防止误删操>作-->
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改hadoop-env.sh
![]()
export JAVA_HOME=/develop/server/jdk
修改mapred-site
![]()
<configuration>
<property>
<!--yarn节点-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--10020端口-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<!--web19888-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
修改![]()
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--yarn节点-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--class-->
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--8032-->
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<!--NodeManager中的配置,这里配置过小可能导致nodemanager启动不起来 大小>应该大于spark中executor-memory+driver的内存-->
<value>6144</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<!--RsourceManager中的配置,这里配置过小可能导致nodemanager启动不起来 大
小>应该大于spark中executor-memory+driver的内存-->
<value>61440</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<!--使用核数-->
<value>2</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<!--使用核数-->
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name> <!--使用>核数-->
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<!--忽略虚拟内存的检查-->
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<!--调度策略,设置为公平调度器-->
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
修改slaves增加从节点(若配置了hosts可直接使用主机名,亦可用IP地址
![]()
Hadoop2
Hadoop3
第七步,拷贝并启动hadoop
拷贝hadoop和java安装包文件到其他节点
![]()
![]()
拷贝环境变量到其他节点
![]()
![]()
格式话hadoop hdfs namenode -format
![]()
启动hadoop
Start-all.sh
查看进程
Jps
关闭
Stop-all.sh
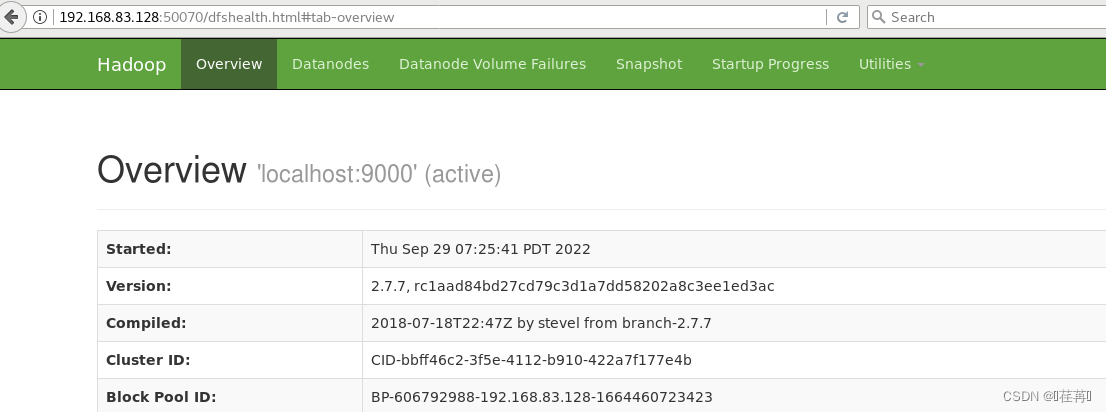
在启动的情况下访问hadoop
浏览器中输入http://localhost:50070 访问hdfs 访问成功