前言:近日,合合信息在多模态大模型与文档图像智能理解专题论坛上进行了分享。多模态大模型指的是能够处理多种语义信息的一种深度学习模型。文档图像智能理解则是指对文档和图像进行智能化解析和理解的技术。合合信息在这个领域的分享,无疑将为学术界和产业界带来重要的启示和参考。
作为中国智能产业高峰论坛的重要议题之一,文档图像大模型的思考与探索是当前智能产业领域的热点话题。随着人工智能和大数据技术的快速发展,文档图像处理及识别正在迎来新的突破和进展。文档图像大模型是指利用深度学习等技术构建的庞大模型,以处理和识别大规模的文档图像数据。这些模型通过学习和训练,在文字识别、图像切边、篡改检测等方面具备更高的准确性和鲁棒性,能够应对不同场景下的挑战和复杂任务。
文档图像分析识别与理解的技术难题
目前,文档图像分析识别与理解领域面临着众多技术难题。首先,多样性和复杂性是其中的主要挑战,因为文档和图像具有不同的结构、格式和布局,需要开发出适应各种情况的算法和技术。其次,多模态数据融合也是一个重要问题,如何有效地融合文本、图像和其他模态的信息,提高整体理解和分析能力是一项复杂任务。此外,文字检测和识别准确性仍然是一个具有挑战性的任务,尤其在复杂背景和低质量图像的情况下。同时,大规模数据集和标注的获取也是一个困难,需要耗费大量的时间和精力。
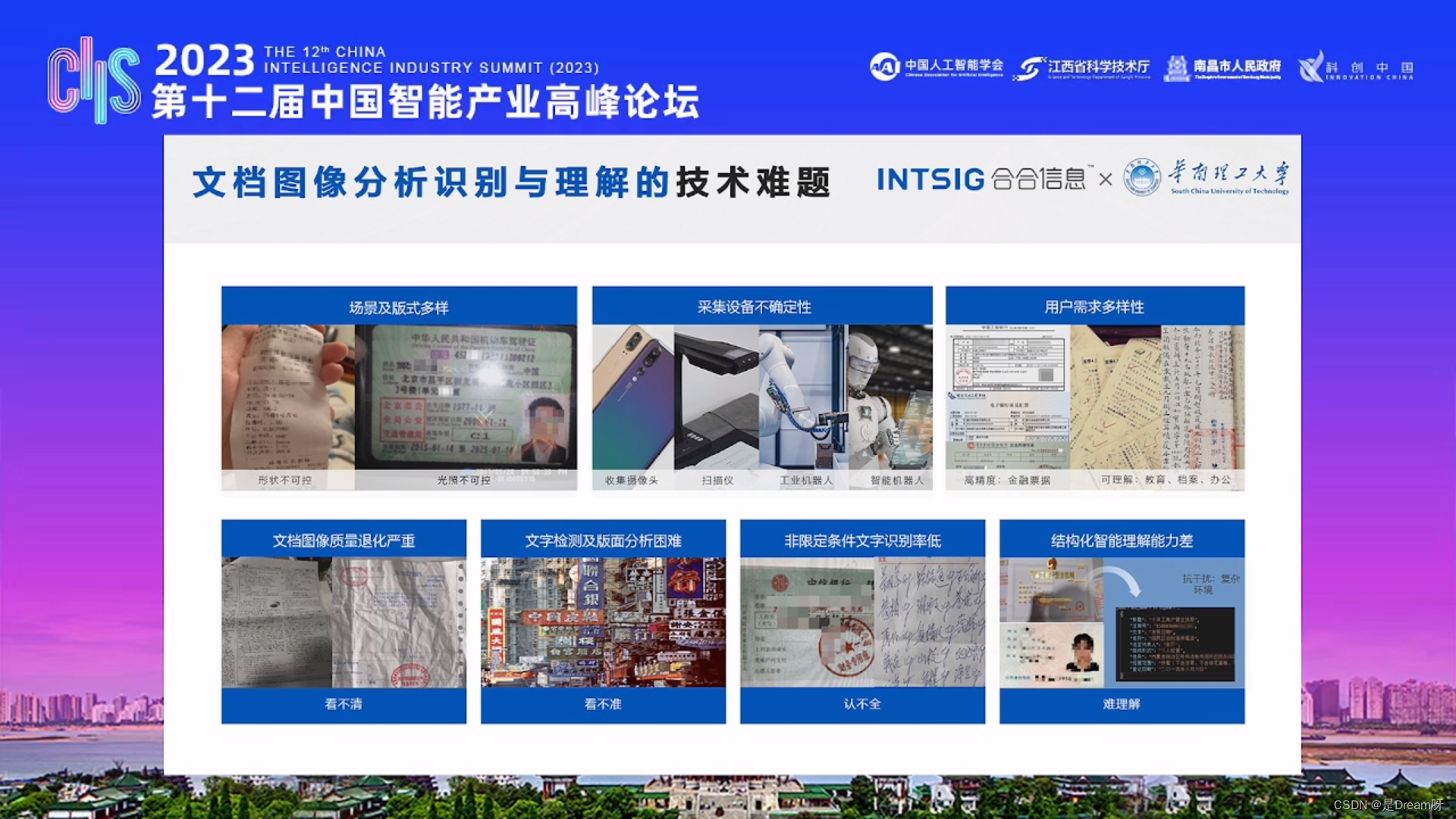
文档图像分析识别与理解的研究主题
同时,文档图像分析识别与理解是一个关注如何利用计算机视觉和自然语言处理等技术,对文档和图像中的信息进行分析、识别和理解的研究领域。该领域涉及许多重要的研究主题,包括图像文字检测和识别、文档结构分析和分割、AI安全等。通过研究这些主题,我们可以开发出更强大和智能化的工具和技术,使计算机能够更准确、自动地分析和理解文档和图像中的内容。这将为文本检测、文档处理、语义识别和版面元素标注等领域带来广阔的应用前景,提高工作效率和信息处理的准确性。
多模态的GPT-4在文档图像上的表现
针对以上情况,GPT-4的发布让人们对语言模型的未来充满了期待和好奇。GPT-4是目前最强大的语言模型之一,它具有超过1万亿个参数,可以处理文本、图片和视频等多种形式的数据。
GPT-4是一个大型多模态模型(输入图像和文本,文本输出)。 其中GPT是生成式预训练模型的缩写。大型多模态模型可以广泛用于对话系统、文本摘要和机器翻译。一般情况下,大型多模态模型包括额外的视觉语言模型组件(VLM)。
相对于GPT-3.5和其他大语言模型,GPT-4在复杂任务上表现出更可靠、更有创意,并且能够处理更细微的指示的关键特征。GPT-4可以接受文本和图像提示,并允许用户指定任何视觉或语言任务。例如,GPT-4可以在给定由分散的文本和图像组成的输入的情况下反馈文本输出。在带有文本和照片的文档、图表或屏幕截图方面,GPT-4 也驾轻就熟。
文档图像大模型的进展
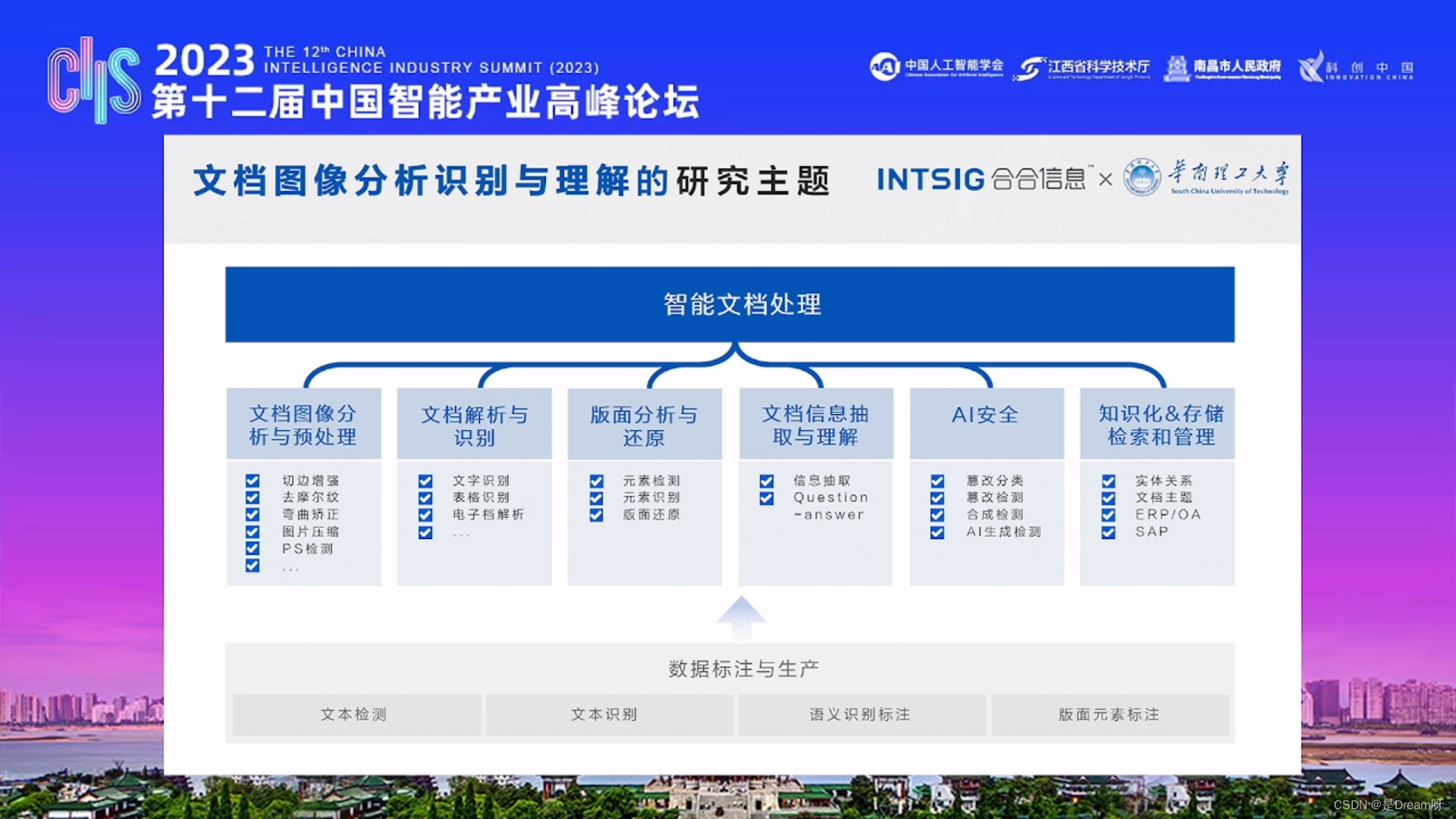
文档图像专有大模型
合合信息还分享了文档图像专有大模型和多模态大模型的发展,以及多模态大模型在OCR领域可能面临的局限性。
1、LayoutLM系列
LayoutLM是微软提出的一系列自然语言处理模型。它是一种基于多模态Transformer Encoder的预训练和下游任务微调,结合了图像和文本信息,用于布局分析任务。
LayoutLM使用了深度神经网络来同时处理图像和文本数据。它将文档视为一个二维网格,并将每个单元格中的图像和文本信息作为输入。通过双流注意力机制,LayoutLM能够有效地在图像和文本之间建立联系,从而准确地识别和理解文档的布局。
LayoutLM的训练过程包括两个阶段:预训练和微调。在预训练阶段,LayoutLM使用大规模的文档数据集进行无监督的训练,学习如何从图像和文本中提取有用的特征。在微调阶段,使用有标注的数据集对模型进行有监督的训练,以适应特定的布局分析任务。LayoutLM是一种创新的多模态模型,结合了图像和文本信息,用于布局分析任务。它可以有效地处理不同类型的文档,并在多个应用领域取得了良好的性能。
2、LiLT
合合信息与华南理工大学正在研究视觉模型与大语言模型解耦联合建模的多模态信息抽取新框架:LiLT,提出双向互补注意力模块(BiCAM)融合视觉与语言模型,LiLT在多语言小样本和零样本场景下表现出出色的性能。
LiLT在多模态信息处理方面具有卓越的能力,能够有效地理解、提取和利用视觉和语言信息。这对于实际应用中需要处理小样本或零样本情况的任务具有重要意义。
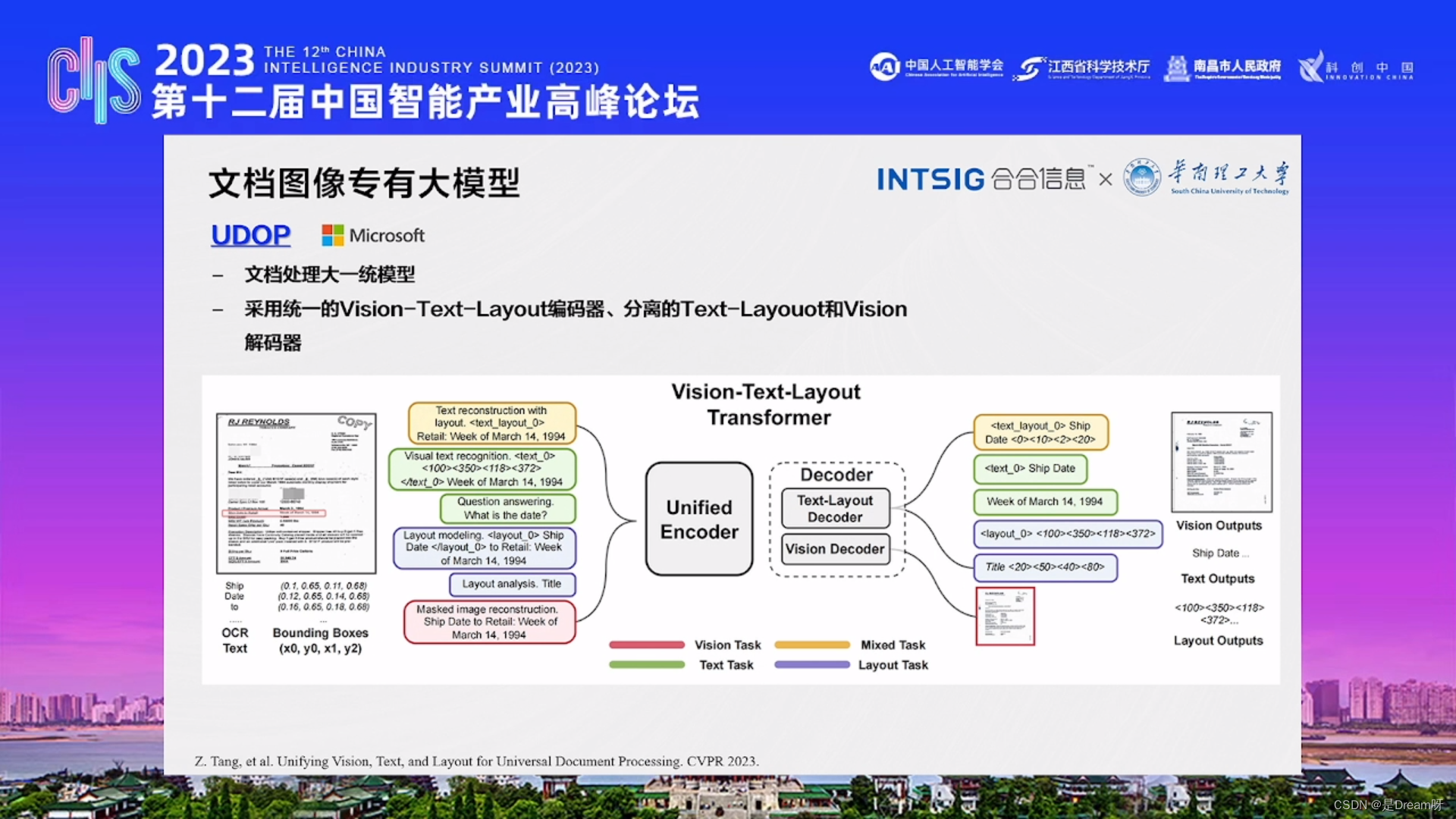
3、UDOP
UDOP是一个文档处理的大一统模型。该模型采用了统一的Vision-Text-Layout编码器,并分离了Text-Layout和Vision解码器。
通过使用统一的Vision-Text-Layout编码器,UDOP模型可以同时处理文档中的视觉、文本和布局信息。这种编码器结构可以使模型更好地理解文档的多模态特征。
此外,UDOP模型还将Text-Layout解码器和Vision解码器分离开来。这种分离的设计可以根据任务的需求单独处理文本与布局信息以及视觉信息,以实现更高的模型灵活性和性能。
总的来说,UDOP模型是一种采用统一的编码器和分离的解码器架构的文档处理模型,它能够有效地处理文本、布局和视觉信息。这种模型设计可以适应不同的任务需求,为文档处理提供了一种综合性解决方案。
在以上的三种做法里面都需要OCR的参与,那可以不可以不让OCR参与呢?那就有了下面的一种模型。
4、Donut
Donut是无需OCR的用于文档理解的Transformer模型,直接把图像、文字放进去,通过解码器进行输出。
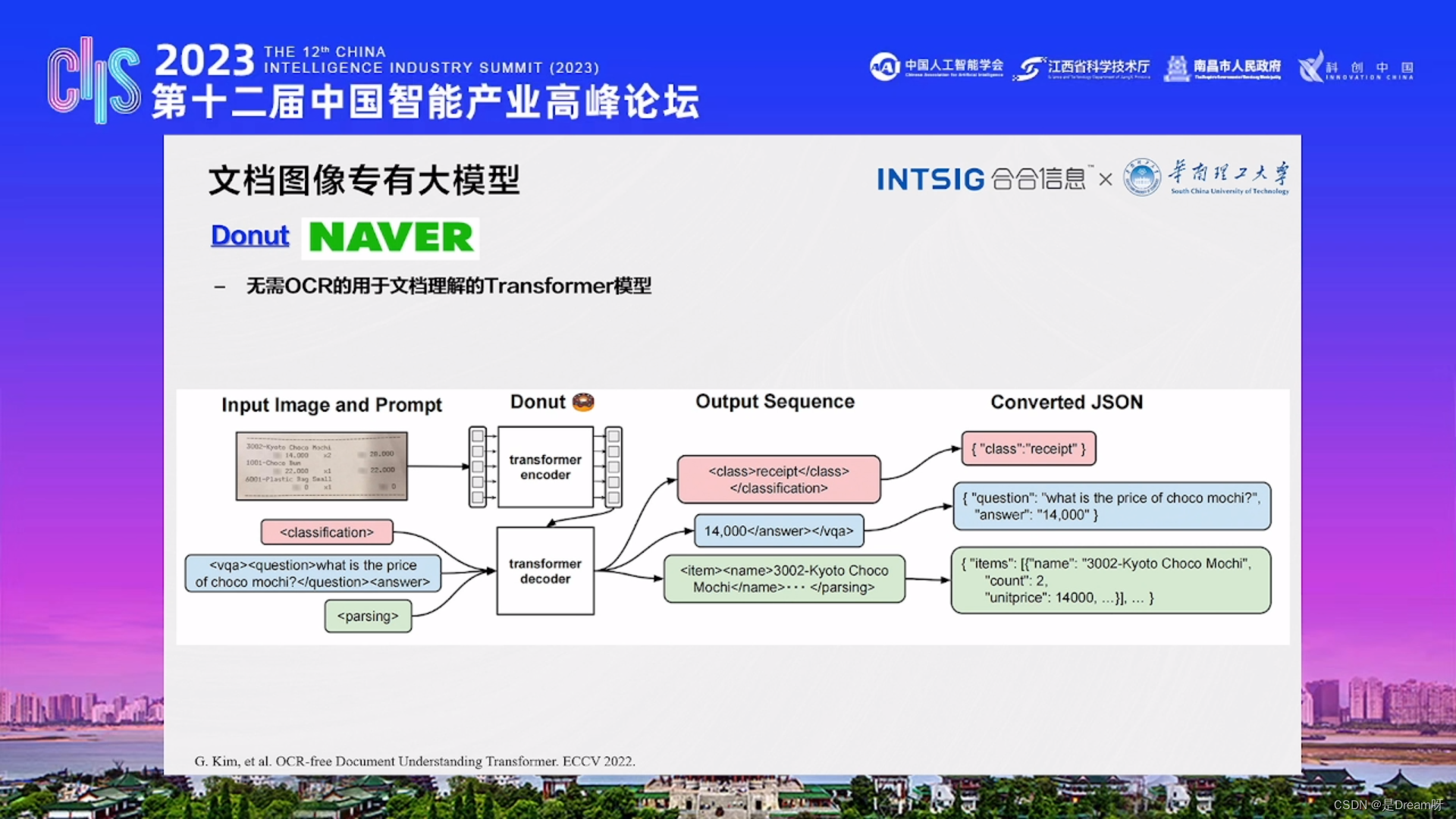
以上方法都是文档图像的专有模型,但是以上方法总体还是偏简单的,但是文档理解是一个非常复杂的工作,文档图像的专有模型并不能有效解决这种问题。大语言模型的出现很好的解决了这种问题。
多模态大模型
1、BLIP2
BLIP2(Bi-directional Layout Integrating Pre-training)是微软提出的一种文档布局分析模型。该模型采用了预训练和微调的方法,使用Q-Former连接预训练的图像编码器(ViT)和LLM解码器(OPT,FlanT5等),结合了图像和文本信息进行布局分析任务。
BLIP2通过使用预训练模型,仅需训练Q-Former部分,学习提取文档中的特征,并通过微调阶段来适应具体的布局分析任务。它能够同时处理图像和文本数据,并通过注意力机制建立跨模态的联系,以便准确理解文档的布局结构。该模型的目标是提供一个强大的文档布局分析工具,适用于处理各种文档类型,包括表格、报告、发票等。通过将图像和文本信息结合起来,BLIP2可以更好地理解和分析文档的结构和内容。

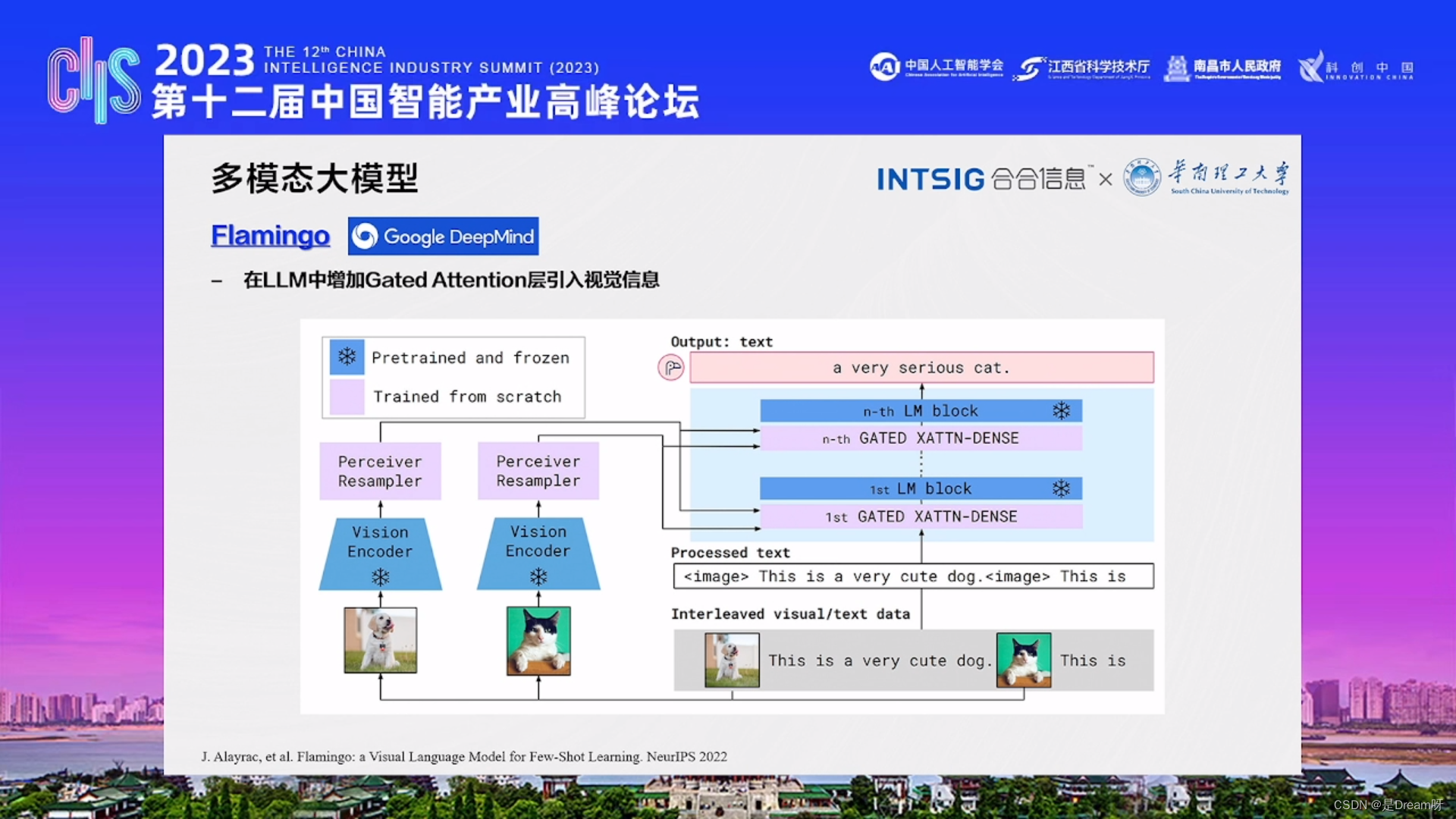
2、Flamingo
Flamingo和LLM(Long-Short Term Memory长-短时记忆模型)结合使用、并通过Gated Attention层引入视觉信息的具体信息,这对于多模态的视觉架构问题是一个非常有意义的尝试!
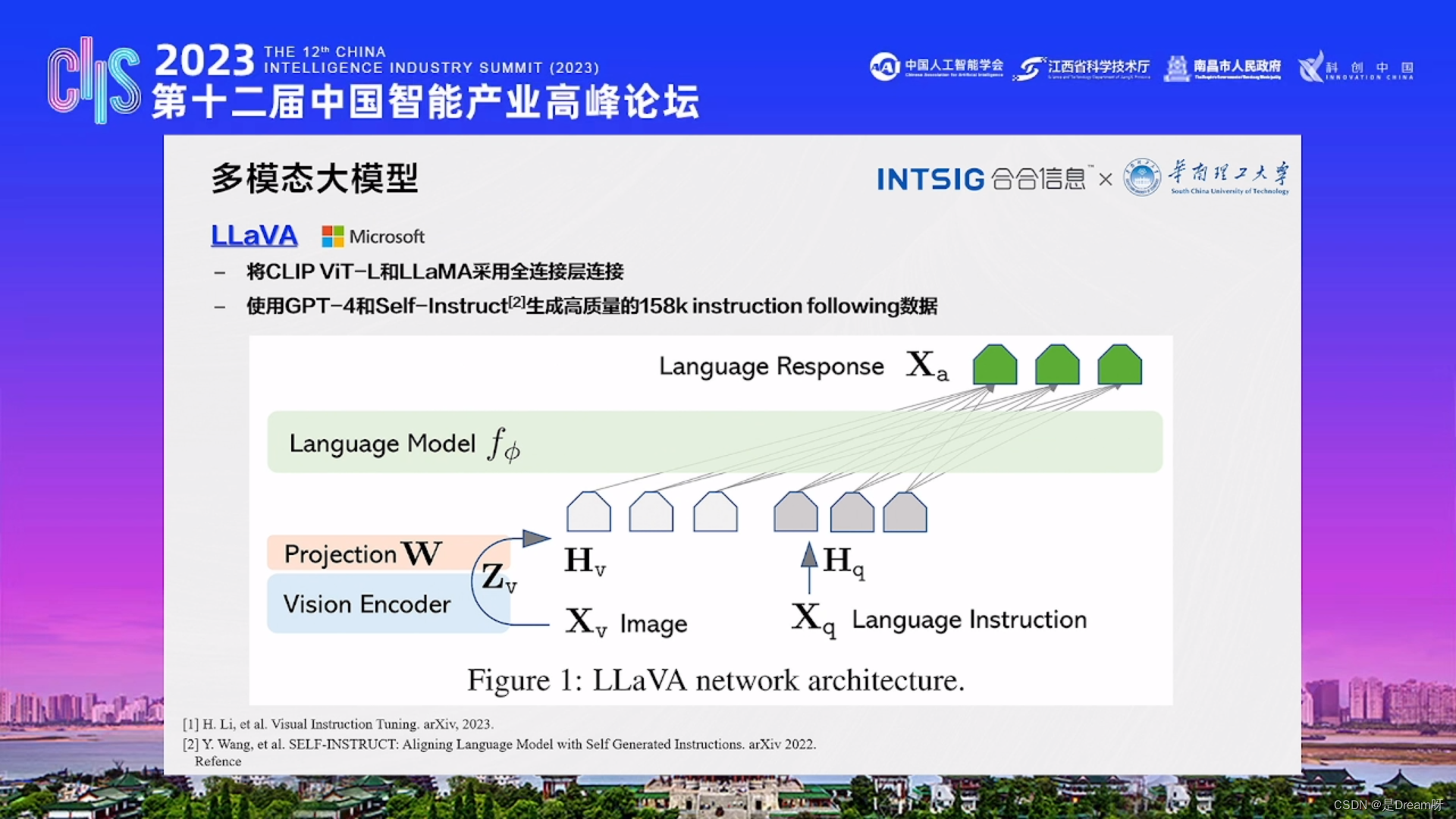
3、LLaVA
以及LLaVA模型,将CLIP ViT-L和LLaMA采用全连接层连接,使用与大语言模型非常类似的方法,GPT-4和Self-Instruct生成高质量的158k instruction following数据,做一个指定微调,实现多模态的架构模型。
那么,从理论上来看,这些多模态大模型很好地利用了视觉信息,也很好的利用了大语言模型本身的特性。那多模态大模型在文档图像中的效果怎样呢?
多模态大模型用于OCR领域的局限性
受到视觉编码器的分辨率和训练数据的限制,现有多模态大模型对显著文本的处理较好,但是对于细粒度文本的处理很差。
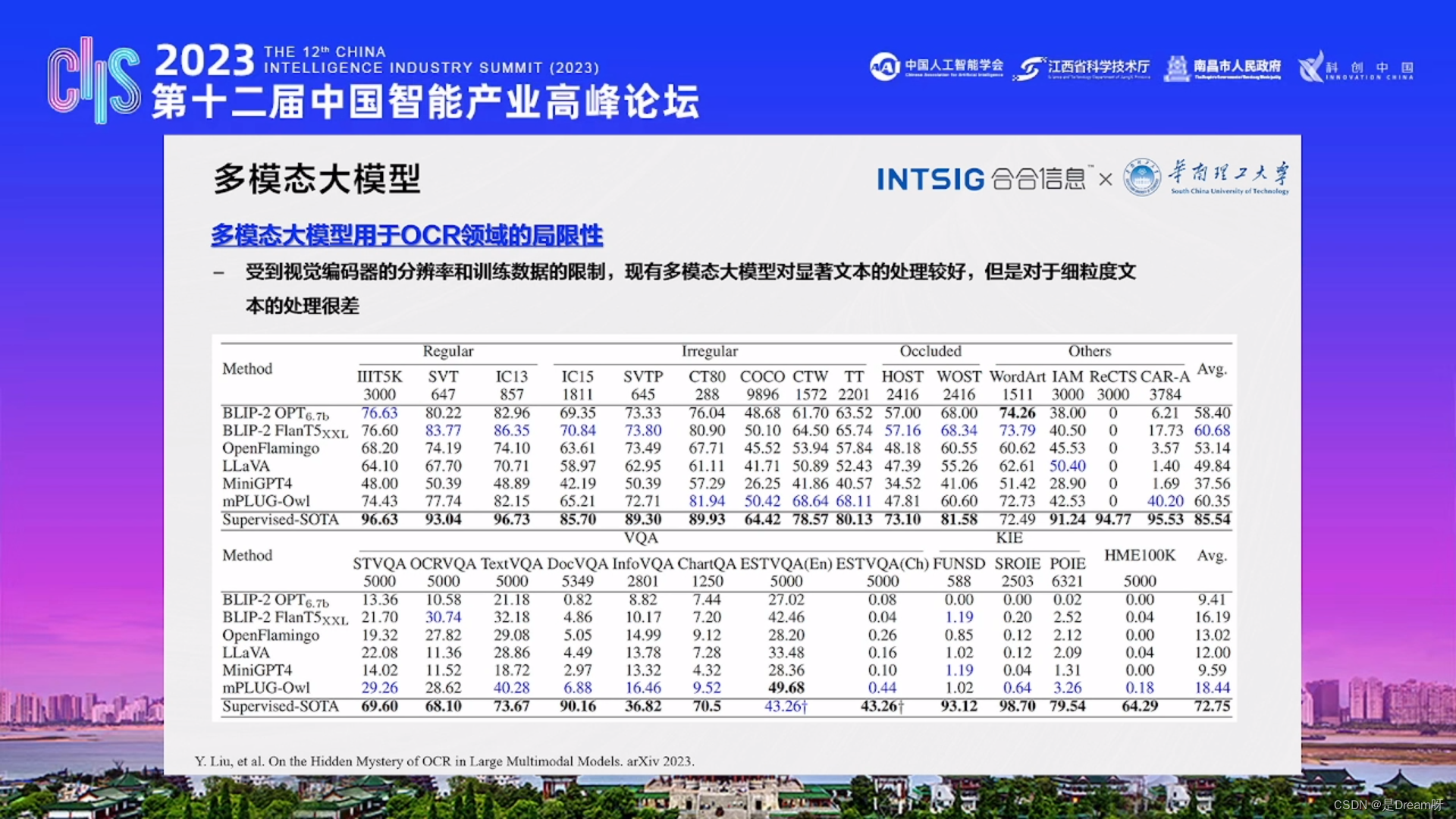
那么在做文档图像问题时是更偏向于文字还是更偏向于图像?
Pixel2seq大模型系列的意义与应用,为文档图像分析识别与理解领域的研究与应用提供新的视角和方法。
文档图像大模型探索
合合信息提到,未来的大模型设计思路主要有以下几个方面:
-
将文档图像识别分析的各种任务定义为序列预测的
形式:文本,段落,版面分析,表格,公式等 -
通过不同的prompt引导模型完成不同的
OCR任务 -
支持篇章级的文档图像识别分析,输出
Markdown/HTML/Text等标准格式 -
将文档理解相关的工作交给
LLM去做
未来,合合信息将继续在文档图像处理方向上发力,推动新技术在更多场景下的应用。希望通过持续的研究和创新,为客户提供更高效、智能化的文档处理解决方案,促进工作效率和生活质量的提升。合合信息的研究成果对智能产业具有重要意义,为行业的发展提供了关键的技术支持。与此同时,合合信息的探索和问题解决过程也为智能产业的发展提供了新的思路和方向。
作为业内领导者,合合信息将持续推动科技创新,为社会带来更多智能化的解决方案。