写在前面:
文章中涉及到的一些术语的解释
有监督学习与无监督学习_有监督学习和无监督学习_Briwisdom的博客-CSDN博客
Bo Shen & Zhenyu (James) Kong (2023): Active defect discovery: A humanin-the-loop learning method, IISE Transactions, DOI: 10.1080/24725854.2023.2224854
Abstract
无监督缺陷检测方法通过生成基于缺陷分数的排名列表应用于未标记的数据集。不幸的是,许多由无监督算法排名靠前的实例并不是缺陷,这导致了很高的误报率。
主动缺陷发现(ADD)是为了克服这一缺陷而提出的,它顺序地选择实例来获得标记信息(缺陷或非缺陷)。然而,贴标签往往是昂贵的。因此,平衡检测精度和贴标成本至关重要。
注:根据这篇文章
流浪地球2彩蛋里的『人在回路学习』是什么? - 知乎 (zhihu.com)
主动学习(active learning)就是一种实现人在回路的方法。因此本文的“human-in-the-loop”体现在主动缺陷发现(ADD)。
沿着这条思路,本文提出了一种新的ADD方法来实现这一目标。我们的方法是基于最先进的无监督缺陷检测方法,即隔离森林,作为基线缺陷检测器来提取特征。然后,利用提取的特征的稀疏性来调整缺陷检测器,使其能够集中在更重要的特征上进行缺陷检测。为了增强特征的稀疏性,提高检测精度,提出了一种基于在线梯度下降的稀疏近似线性缺陷发现算法(SALDD),并对其进行了理论遗憾分析。在现实世界的数据集上进行了广泛的实验,包括医疗保健、制造、安全等。实验结果表明,该算法明显优于现有的缺陷检测算法。
Introduction
几十年来,缺陷检测一直是一个活跃的研究领域,在各种应用中发挥着越来越重要的作用。
缺陷是由不同于生成“正常”数据实例的过程生成的数据实例,称为名义实例。作为一项学习任务,缺陷检测可以分为监督、半监督和无监督。
监督缺陷检测与二元分类是一样的,在名义和缺陷实例上进行训练。在半监督缺陷检测中,缺陷检测器仅在名义实例上进行训练。
在现实世界的应用程序中,标记的数据集不可用于训练,因为标记过程(即,通过测量确定实例是缺陷或标称)是耗时或昂贵的。作为一种可行的解决方案,无监督缺陷检测方法可以在一定程度上帮助解决这个问题。
无监督缺陷检测方法直接在未标记的数据集上工作,以提供缺陷评分列表,其中缺陷应该比名义实例具有更高的排名。排名靠前的实例被标识为候选缺陷。
注:异常检测的任务是给出一个反应异常程度的排序,常用的排序方法是根据样本点的路径长度或异常得分来排序,异常点就是排在最前面的那些点。
无监督缺陷检测方法通常不能很好地执行,原因有两个:(i)无监督缺陷检测方法是在没有使用任何标签信息的情况下进行训练的,即没有很好地探索缺陷模式;(ii)真实数据集的缺陷比例较低,这是缺陷检测的数据不平衡问题。因此,无监督缺陷检测方法存在假阳性率高的缺点。
ADD的目标是依次选择一个实例进行度量,然后标记(在本文中称为“查询(query)”),并在预算约束的给定度量数量下最大化检测到的缺陷的数量。
GLDD已被证明是大规模缺陷检测的最佳方法之一。尽管GLDD的作者(Siddiqui等人,2018)指出,对于任何特定的例子,特征集都是非常稀疏的,但他们没有进一步探索稀疏性。在本文中,从理论上证明了特征函数是稀疏的,并通过经验进行了验证。然后我们假设,由于两个原因,加强模型权重的稀疏性可以改进GLDD算法。因此,提出了一种基于梯度下降的新算法,即稀疏近似线性缺陷发现(SALDD)来更新权重。
2 Related research
2.1 Defect detection and statistical process control
缺陷检测可以分为三种模式(Chandola et al, 2009)。监督缺陷检测与二元分类相同,其中标称和缺陷实例的标签在训练过程中都是可用的。在半监督缺陷检测中,缺陷检测器仅在名义实例上进行训练。无监督缺陷检测方法直接在未标记的数据集上工作(即,模型在不知道缺陷与否的情况下对所有数据实例进行训练)。
本文提出的缺陷检测方法不同于以往。我们提出的方法从无监督缺陷检测(隔离森林)开始。通过我们的标记方法查询(query)更多的实例来更新缺陷检测器。利用正常和缺陷实例来提高缺陷检测器的性能。它与半监督缺陷检测不同,因为我们同时拥有正常和缺陷数据,而半监督方法只使用正常实例进行训练。它也不同于监督缺陷检测,在监督缺陷检测中,所有的实例都带有用于训练的标签,而我们的方法选择哪些实例用于训练。与无监督缺陷检测相比,我们的方法利用实例中的标签信息来构建模型。
值得一提的是,统计过程控制(SPC)是一种广泛应用于工业的缺陷检测的基本方法。多元控制图(Multivariate control charts)的发展是为了检测过程平均向量的漂移(to detect a shift in process mean vector),即过程的失控信号。我们的方法不同于SPC,它是一种无监督的方法来检测时间序列数据的平均漂移(mean shift)。
2.2 Theoretical background of isolation forest
在本节中,将介绍Liu等人提出的隔离森林作为我们的基线缺陷检测器。在无监督缺陷检测的文献中,隔离森林已被证明是最鲁棒的方法之一,对于具有不同大小和特征空间的不同数据集,它是表现最好的。
考虑含有个数据的数据集
每个实例 含有
个特征
隔离森林基于以下前提:异常点很少,并且与特征空间中的标称实例集群良好分离(defect instances are few and well-separated from clusters of nominal instances in the feature space)。
一个隔离森林是个树的集合,记为
其中 是森立中的第
棵树。隔离林中的每一棵树就是特征空间的一个分割,树中给定数据实例从根节点到终端节点的路径长度表示该数据实例与其余数据实例的隔离程度。具体来说,每棵树都是基于整个数据集的子样本以随机方式构建的。因此,整体
个树提高了算法的准确性和效率。
注1:每棵树都是一个分割,总共
棵树就表示对样本进行了
注2:样本数较多会降低孤立森林孤立异常点的能力,因为正常样本会干扰隔离的过程,降低隔离异常的能力,子采样就是在这种情况下被提出的。
下图阐述了一棵隔离树的产生过程。
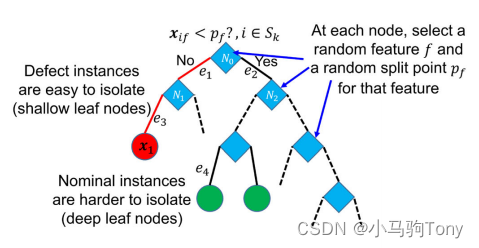
图2.1 一棵隔离树
缺陷实例(如图2.1中的红圈所示)非常快速地通过随机分割到达叶节点,另一方面,形成密集集群的标称实例(如图2.1中的绿圈所示)需要更多的步骤才能最终到达叶节点。因此,对于缺陷实例,平均而言,实例从根节点到叶所遍历的边数(也称为隔离深度(isolation depth))比标称实例短。实例的缺陷分数(defect score)是林中棵树的平均隔离深度。
算法1概述了树的构建过程。

- Step1 (Line2-3): 子样本集
被用于构建一棵隔离树
,
是下标集合,子样本大小为
,子样本是通过随机采样产生的,每个数据点被选到的概率相等。
- Step2 (Line7-11): 设
为当前节点上实例的索引集。
中等概率随机选择
作为特征下标,在
中均匀采样出阈值
,其中
,
。
的示例通过边
被划分到左儿子
,其余
的实例通过边
被划分到右儿子
。
- Step3: 从步骤2开始的过程递归地继续,直到每个实例在叶中被隔离或达到树高度限制
(Line4-5),其中树高度限制是实例可以行进的最大边数。
隔离森林可以被描述为一种特定的方法,这种方法通过特征函数设置基于树的缺陷检测器的权重。特征函数为
其中为森林中边的总数。具体而言,图2.1中的隔离树的特征函数可以如下构造:
(1)
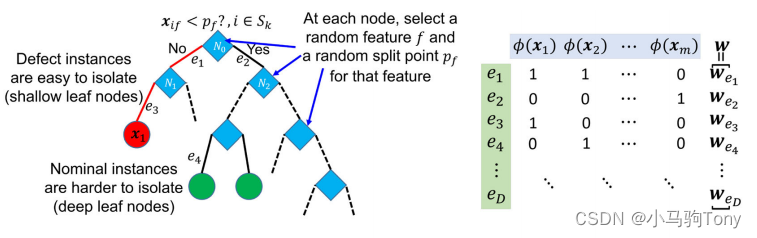
图2.2 特征函数
如图2.2,按照此方法构造的是一个非常稀疏的向量,即大部分特征是0,因为每个实例只能经过少量的边。为每条边分配一个权重
,构建缺陷分数。现在设
和
对不同实例是一致地连接整个森林中的所有特征和权重的向量,并且初始时将所有边的权重均设为1,即
,那么线性缺陷评分函数(linear defect score function)
(2)
与(未规范化的)隔离森林缺陷分数(defect score)完全对应。添加负号的原因是确保分数越高表示越接近缺陷,分数越低表示越正常。
注:例如
是节点(或者称为实例)
经过的所有边的总数,且这些边的权重
3 Research framework
在本文的设置中,是没有标签的数据实例,然而标签可以以一定的成本进行测量,然后标记为缺陷或标称类别,也即
。查询(query)被定义为选择数据实例并进行标记测量的过程。
和
分别表示已标记实例和未标记实例的集合。我们的目标是开发一种抽样程序来顺序查询未标记的数据实例,这在给定的预算量(即固定数量的测量)下,最大限度地增加了查询过程中要检测到的缺陷数量(即,让一组已标记实例
包含尽可能多的缺陷)。

图3.1 本文方法框架,新颖性用蓝色突出显示
图3.1总结了我们实现目标的方法的框架,该方法在迭代过程中工作。一开始,隔离森林作为基线缺陷检测器,在数据上训练。令
和
。
在第1次迭代,特征函数和模型权重
一起被用于获得如2.2节所述的缺陷分数
缺陷分数被用于在中对所有未标记的实例进行排序,以推荐要标记的实例。排名靠前的实例通过测量被识别为查询的候选实例,测量结果被移入
并从
移出,因为缺陷被认为具有高的缺陷分数。一旦标记了排名靠前的实例,
将根据我们在第4.2节中提出的算法进行更新。至此完成了所提出方法的一次迭代。本文提出的框架有以下两个新颖之处:
- Novelty 1 (Section 4.1) 隔离森林的特征函数
可以用来计算缺陷分数,这是一个重要的组成部分。4.1节证明了特征函数的稀疏性,这意味着缺陷检测中重要的边也是稀疏的。这就是在模型权重
上添加稀疏性的动机。
- Novelty 2 (Section 4.2) 执行一种新的测量方法,为查询的实例提供标签。接着
4 Methodology
4.1 Sparsity analysis of feature function
本小节讨论和证明隔离森林中特征函数的稀疏性。对数据集使用算法1,通过式(1)可以得到特征函数,二元特征的维数,即
,与树的高度限制
密切相关。通常,
随着
的增加而增加。以下引理证明了来自隔离森林特征函数
的二元特征在两个条件下确实是稀疏的。
- 引理1 假设在
个实例上,由算法1训练的森林中没有空叶,其中森林中有
(i) 如果树高比较小,即不是所有实例都被隔离到了一个叶节点,那么对
(ii) 如果树高比较大,即每个实例都被隔离到了一个叶节点,并且
,那么
(4)
其中为实例个数,
表示提取的特征集
中非零元素的比率,并且边数
。
注:0范数表示向量中非零元素的个数(即为其稀疏度)。
只有当数据集X中存在重复实例时,才会显示空叶,因为这些实例不能在节点中拆分。但是,可以删除重复的实例,从而满足没有空叶的假设。上述引理讨论了特征函数在两个独立条件下的稀疏性。条件(i)和(ii)分别对应于小树和大树高度限制的情况。条件(i)表示对于任意实例,的稀疏性上界为
。条件(ii)中,当
趋近于无穷,下界收敛为0,上界收敛为1/4。这两个条件都是必要的,因为它们涵盖了隔离林的所有情况。
4.2 Sparse approximated linear defect discovery
在本小节中,所提出的算法是在基于在线梯度下降的在线优化(Shalev-Shwartz,2011)框架内提出的,该算法可以在模型稀疏性和模型精度之间进行权衡。
在线优化是优化理论的一个分支,在计算机科学和运筹学中更为常见,处理对未来(在线)没有或不完全了解的优化问题。与假设完整信息(离线)的经典优化问题相比,此类问题呈现为在线问题。在线优化研究可分为基于零碎输入连续做出多个决策的在线问题和仅做出一次决策的在线问题。做出单一决定的一个众所周知的在线问题是雪具租赁问题。一般来说,在线算法的输出必然总是最优的,并与相应的离线算法的解决方案进行比较,离线算法的整个输入都是预先已知的(竞争分析)。 在许多情况下,必须在对未来不完全了解的情况下做出当前决策(例如,资源分配)。或者,关于未来的分配假设是不可靠的。在这种情况下,可以使用在线优化。这不同于其他方法,例如稳健优化、随机优化和马尔可夫决策过程。参考:
在线优化 Online Optimization: 最新的百科全书、新闻、评论和研究 (academic-accelerator.com)
4.2.1 Connection with online optimization
在第次迭代,基于当前权重
,根据式(2)定义的缺陷分数被分配给未标记集合
中的每个实例,根据缺陷得分列表,选择排名靠前的实例
进行查询(即通过测量/实验将该实例标记为
),这一步骤消耗时间或成本。之后,接收关于排名靠前的实例的测量反馈
以将模型权重更新为
,
当实例是缺陷,
当实例是标称实例。我们问题的目标是通过依次选择合适的
以最小化累计遗憾(accumulated Regret)。对一场T轮的游戏(T-round game),累计遗憾定义为
其中线性损失由下式给出
(6)
这是一个的线性函数。
直观地说,如果,那么我们当前的
应该比
的情况损失更小,因为基于
的排名正确地将缺陷放在了首位。当收到缺陷或标称反馈时,通过第4.2节中的算法更新模型权重为
。具体而言,将
最小化的迭代过程可以如下总结:
在这个过程中模型权重(即决策变量)从
到
依次获得(sequentially obtained)。
在迭代处,根据最后一次迭代导出
(记为
),这一步骤在第2章已经解释过。基于
,选择排名靠前的实例
进行测量以获得标签
。得到
后,就可以根据上式得到
(记为
)。再将得到的
用于更新模型新的权重
(记为
)。
注:
表示的是左边是集合的元素,右边也是集合的元素;而
表示的是左边是集合,右边也是集合。参考:
上述过程属于在线优化的框架。在线优化是针对潜在对手的迭代游戏,其中是从一些约束集
中选择的。游戏进行如下:(i)对手选择一个函数
;(ii)遭受一个损失
;(iii)选择一个向量
。
在我们的问题中,对手是贪婪的策略来选择排名靠前的实例。通常,在线优化的性能是通过最优权重的累计遗憾(accumulated Regret)来衡量的。
是假设
提前已知的最小值。
4.2.2 The SALDD algorithm
为了最小化,在文献中可以使用各种各样的在线优化算法。特别是,在线梯度下降方法(online gradient descent)是预测准确性和计算效率的一个有吸引力的组合。
关于在线优化以及online gradient descent:
所提出的算法SALDD动机来自于Zhai等人(2018),并在算法2中提出。如第4.1节所述,有必要在模型权重中添加稀疏性约束。在文献中,有三种主要技术可以实现稀疏性:(i)施加L1-范式约束;(ii)向损失函数添加L1-范式正则化(L1-norm regularization)以及(iii)使用基于L0的截断。我们提出的稀疏性策略与上述方法不同。具体而言,提出以下稀疏近似问题(sparse approximated problem)以实现
的稀疏性,同时最小化
(7)
它旨在找到最稀疏的向量,并且约束使其足够接近
,并且具有指定为
的合理数量的非零特征。约束中的截断误差
控制着
和
的接近程度,从而影响
的稀疏性。优化问题(7)的约束中的参数
是一个整数,这有助于避免
的值设置得太大的任何不适当的情况。使用简单的贪婪方法可以有效地将问题(7)求解到最优。具体如下:

5 Case studies
为了评估所提出的SALDD的性能,本节进行了数值和真实世界的案例研究。在第5.1节中,用数值模拟数据研究了特征函数的稀疏性和SALDD算法2的收敛性。在第5.2、5.3和5.4节中,使用开源数据集、聚合物增材制造(AM)数据集和金属AM数据集中的真实世界应用来演示所提出的SALDD的性能。对于第5.2、5.3和5.4节中的所有分析,我们提出的SALDD是根据以下基准方法进行评估的:
- 无监督基线:在等式(2)中,所有实例都按缺陷分数的递减顺序排序,使用给定
的隔离森立算法计算:该算法忽略了测量反馈,因此在迭代中排名是恒定的。该基线获取的是不包含测量反馈的无监督缺陷检测方法的性能。
- GLDD:这与激励性论文(Siddiqui等人,2018)相对应,其中缺陷分数是使用基于隔离森林的等式(2)计算的。该算法通过具有非负约束的在线镜像下降来调整模型权重
对于评估度量,缺陷发现曲线(Ding等人,2019)用于绘制发现缺陷的数量与迭代次数(测量)的关系图。一个完美的结果是一条斜率为1的线,即所有查询都是缺陷。最坏的情况是斜率为零的线,即所有查询都是正常的。将第5.2、5.3和5.4节中的所有分析重复10次,以获得用于比较的平均值和标准误差。SALDD算法在Matlab 2019a中实现。实验中使用的计算机的CPU是Intel CoreTM处理器i7-6820HQ(四核2.70 GHz,3.60 GHz Turbo,8MB 45W)。
5.1 Numerical study
在本小节中,使用模拟数据考虑了两种情况:(a)具有不同大小训练数据的特征函数的稀疏性分析;(b)具有不同的算法2的数值优化性能。
- Case (a) 此处使用的实例独立地来自正态分布
。为了研究引理1中所述的特征函数的稀疏性,对于条件(i)和(ii)都考虑了不同数量的实例。具体来说,实例的数量可以设置为
,其中
。对于条件(i),如Liu等人(2008、2012)所建议的,将树极限高度
。
对于条件(ii),树极限高度被设置为一个较大数字,以便所有
个实例被隔离到每个树叶。图5.1绘制了两种情况下非零元素的比例与实例数量的关系。当实例数量增加时,该比率会一直降低到零。此外,式(4)中的下限和上限也如图5.1(b)所示。结果表明,非零元素的比例更接近下界,尤其是当实例数量较大时。因此,图4根据经验说明,对于引理1中的条件(i)和(ii),特征函数都是稀疏的。
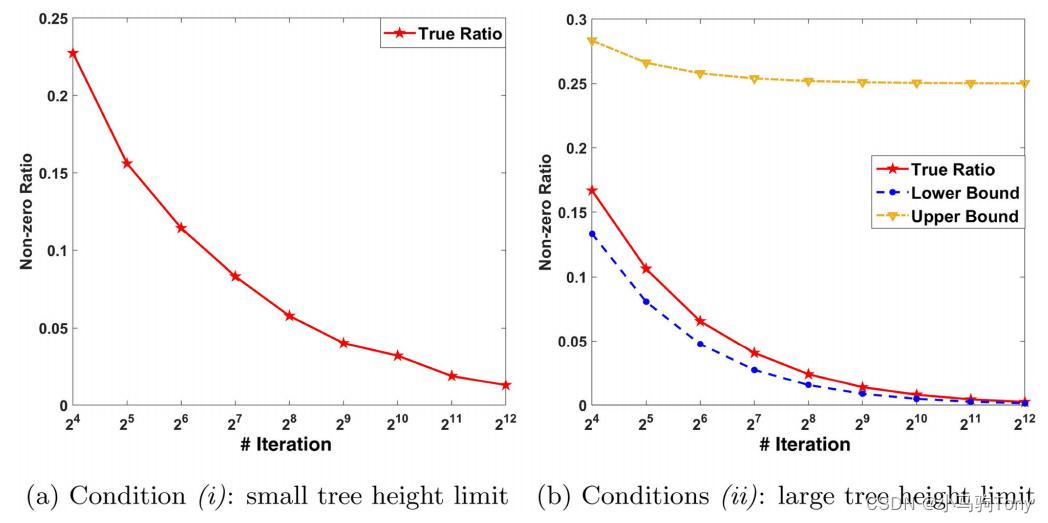
图5.1 稀疏性分析
- Case (b) 标称实例的采样独立地来自
独立采样。本实验总共考虑了400个标称实例和100个缺陷实例。为了研究
的影响,将其取值为
。如果
,我们的算法退化为Streeter和McMahan使用的在线梯度下降算法(online gradient descent algorithm),该算法具有亚线性收敛速度(sub-linear convergence rate)。由于
右侧第二项的最优解未知,因此它可以作为比较的关键信息。在这个实验中,算法2中的第5行被一个随机策略取代,以便在每次迭代时为不同的
被设置为4000。
对于性能评估,平均损失定义为,图5.2(a)中绘制了与迭代次数的关系图,其中
在方程(6)中定义。与5个
对应的五条曲线具有非常相似的趋势。可以观察到,
越大,平均损失越大。这是合理的,因为较大的近似误差会导致较大的损失。另一方面,在图5(b)中,绘制了模型权重
的稀疏性与不同
的迭代次数的关系图。除了
的情况,对所有
,当迭代次数增加时,稀疏性不断降低,直到达到
。此外,较大的
对应于较小的稀疏性值。
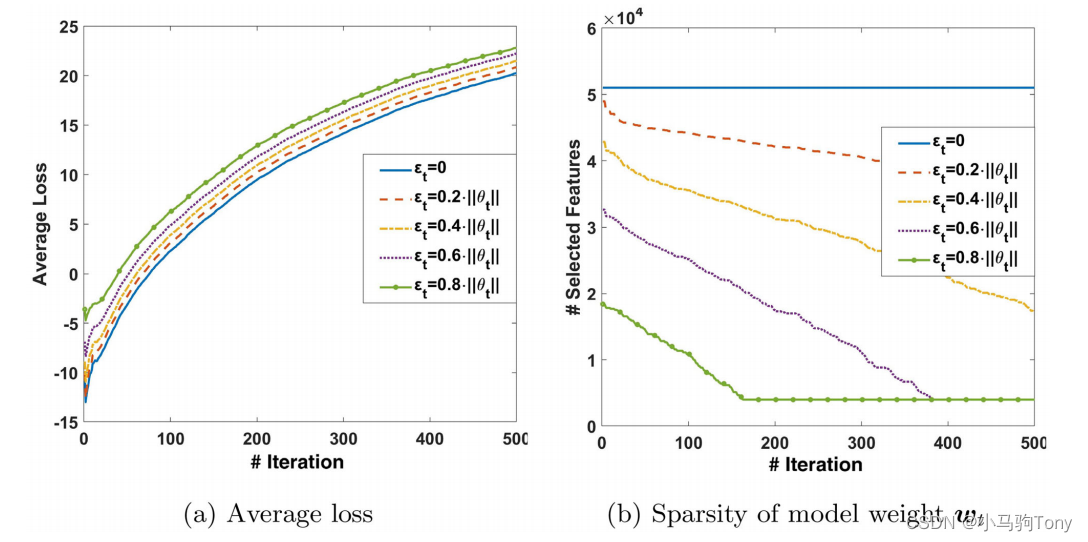
图5.2 SALDD算法的收敛性能:(a)平均损失与迭代次数;(b)模型权重的稀疏性对迭代次数
5.2 Application in open-source datasets
在本小节中,SALDD和基准测试方法应用于开源数据集以进行性能比较。20个数据集选自Campos等人(2016);Ranjan等人(2018)和ODDS3用于本实验。
每个数据集的类被分为两组,一组代表标称实例,另一组代表缺陷实例。表1总结了每个数据集中的尺寸、缺陷数量和缺陷百分比。对于每个数据集,预算由其缺陷数量决定。缺陷数量越多,预算就越大。
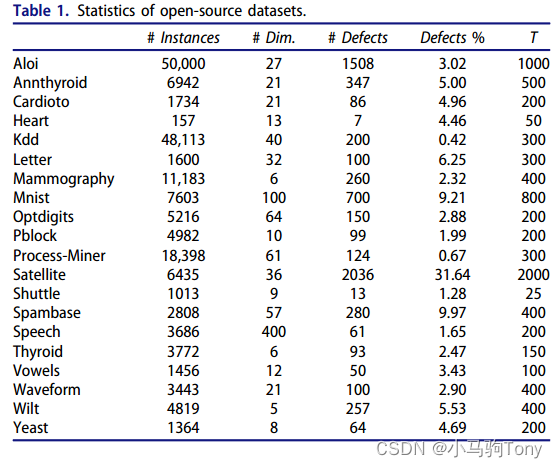
表2显示了所有数据集的定量结果,包括各种选定实例的精度平均值和标准误差(见表1中的列)。
(精度)被定义为真阳性/(真阳性+假阳性),
(召回)被定义为真阳性/(真阳性+假阴性)是不适用的,因为所有选定的实例都被标记为不同算法的“缺陷”(没有做出阴性决定)。总体而言,GLDD和SALDD比无监督基线方法具有更好的性能,证明了将测量反馈纳入无监督分析的优势。所提出的SALDD可以在所有20个数据集中实现最佳平均性能,与GLDD相比具有不同程度的改进。这说明稀疏性可以提高检测缺陷的能力。就标准差(standard error)而言,尽管所提出的SALDD不是最好的,它通常可以实现相对较低的标准误差。

表2中的结果仅显示了达到预算时不同方法的性能。为了探索不同方法在反馈循环期间的性能,图5.3绘制了所有20个数据集检测到的缺陷数量与迭代次数的关系图。在算法的10次独立运行中对曲线进行平均,并显示了95%的置信区间。总体而言,它表明SALDD从未恶化无监督基线(隔离森林)的性能。在大多数情况下,与隔离林和GLDD相比,随着时间的推移,SALDD显著增加了发现的缺陷数量。
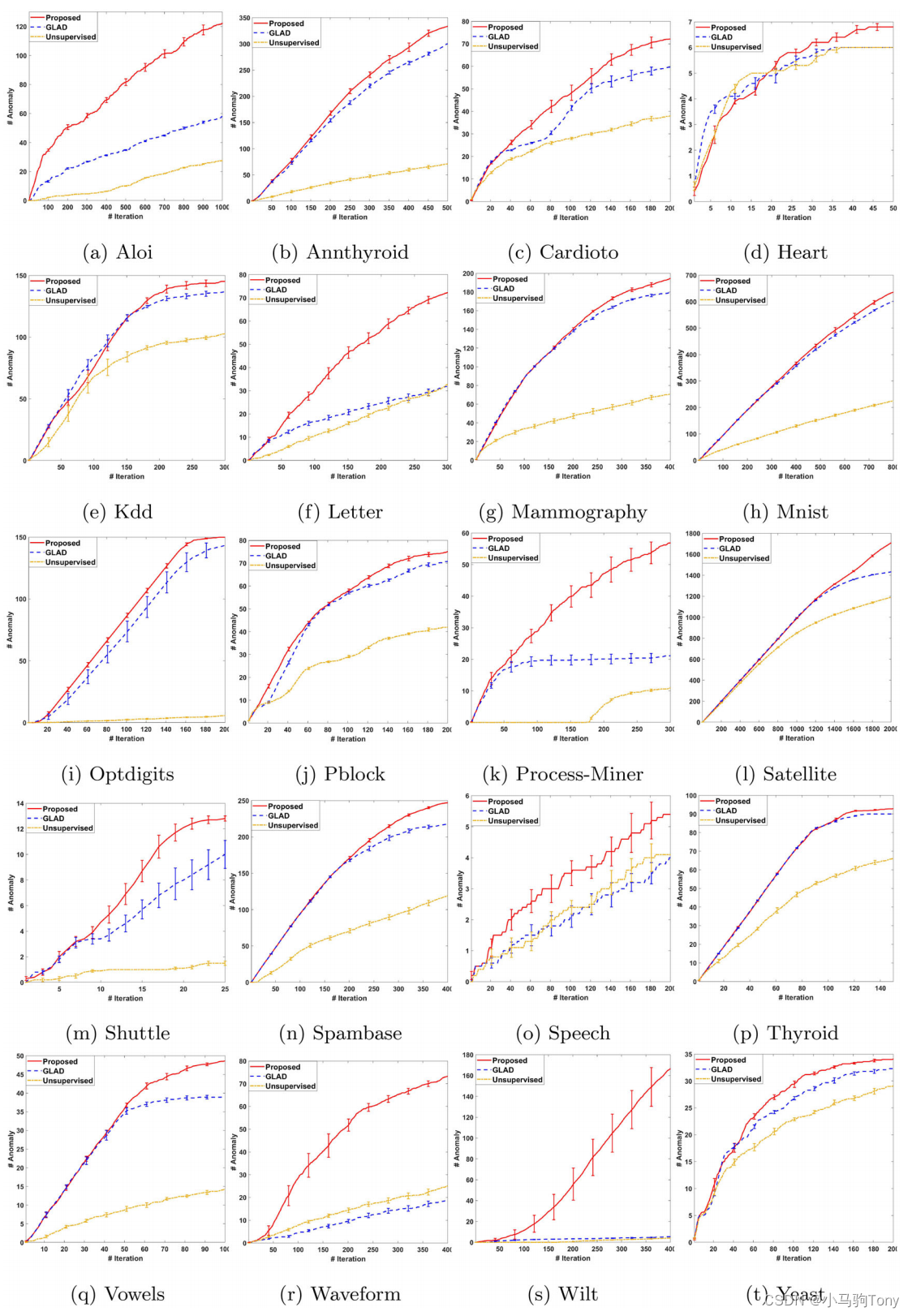
图5.3 检测到的缺陷总数与迭代次数的关系, 其中误差条表示95%置信区间
5.3 Application in polymer AM
在本节中,使用聚合物AM数据集(Shen等人,2020)来探索所提出的SALDD在从未标记数据集中检测感兴趣缺陷方面的性能。在该实验中,台式FFF 3D打印机,即Hyrel System 30M 3D打印机,用于打印测试工件,即尺寸为2英寸的长方体。事实上,FFF印刷工艺可能会遇到诸如空隙、过度填充、填充不足等缺陷。然而,类似缺陷的根本原因可能不同,导致缺陷缓解的困难。例如,用于温度控制的不适当的冷却风扇设置和次优进料速率(材料挤出速度)都可能导致底部填充,但严重程度不同。区分这些类似的缺陷至关重要。因此,安装传感器用于在线监测打印过程。通过安装在3D打印机挤出机两侧的两台数字显微镜以1Hz的采样频率收集正在打印的零件表面的高质量图像。在打印过程中,分别收集了正常、冷却风扇设置不当导致的填充不足和进给速率不理想导致的填充不良的表面质量图像(如图5.4所示)

图5.4 正常、冷却风扇设置不当导致的填充不足和进给速率不理想导致的填充不良的表面质量图像
对于每个图像,使用从原始图像裁剪的感兴趣区域(ROI)(640×480像素)到较小区域(80×80像素),如图7所示。ROI中的图像被转换为具有6400个变量的向量,用于测试不同的算法。对于每个变量,它表示一个范围从0到255的像素值。分别有205个正常图像、153个由进给速率引起的底部填充图像和42个由风扇引起的底部填满图像。
本小节中的实验程序如下:
- Step 1 (重新贴标签, Relabeling):42个由风扇引起的底部填充的图像被标记为
(感兴趣的缺陷),而205个正常图像和153个由进料速率引起的底部填满的图像被标注为
(不是感兴趣的瑕疵)。
- Step 2 (实施, Implementation):在该分析中,步骤1中的所有这400个图像都被视为未标记的图像。它们的实际标签(即
)是需要在我们提出的算法2的第6行中测量的基本事实。我们算法的目标是在给定的预算下,尽可能多地检测风扇导致的填充不足的图像。
预算被设置为100(测量的数量)。图5.5绘制了检测到的缺陷数量与测量次数(迭代)的关系图。在算法的10次独立运行中对曲线进行平均,并显示了95%的置信区间。结果表明,所提出的SALDD表现是最好的,因为在相同数量的测量下,它比基准方法识别出更多的缺陷。GLDD与无监督基线相比略有改善。这再次表明,在我们提出的算法中涉及稀疏性的优势。
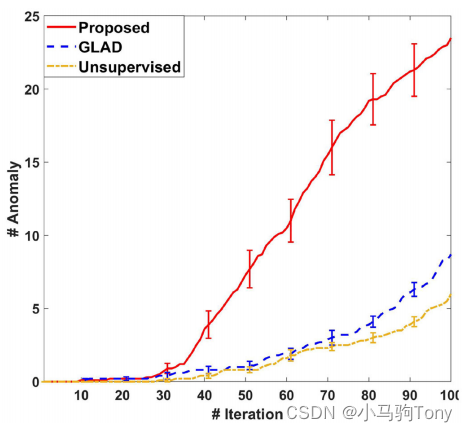
图5.5 聚合物AM数据集上检测到的缺陷总数与迭代次数的关系
为了更深入地理解SALDD,提供了聚合物AM数据集的可视化以及三种算法的查询。我们的目的是提供一些关于AAD如何工作的直觉。为此,t-SNE(Van der Maaten和Hinton,2008)降维技术被应用于在该实验中产生数据集的二维(2D)表示。图5.6显示了t-SNE生产的聚合物AM的2D表示,以及基准测试和SALDD进行的查询。无监督基线和GLDD倾向于在图5.6(a)和图5.6(b)右下角所示的相同位置发现标称实例。相反,我们提出的SALDD不仅从同一位置检测到更多的缺陷,而且还查询更多位置的缺陷,因为SALDD可以检测到图5.6(c)左下角所示的缺陷。总体而言,SALDD可以查询更可能存在缺陷的实例,并将重点放在各个区域。
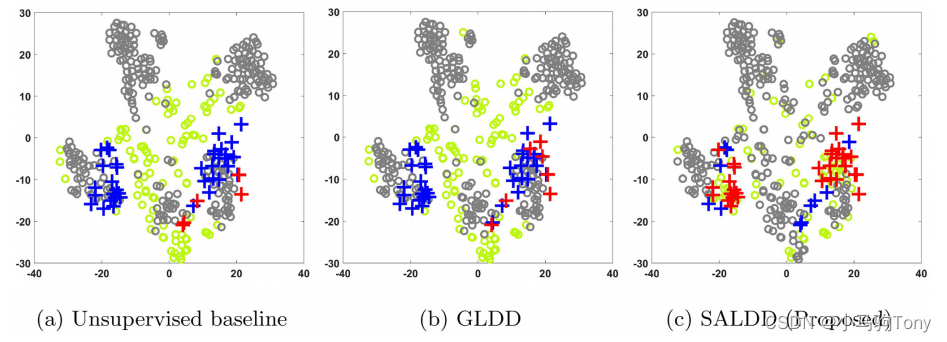
图5.6 使用t-SNE对聚合物AM数据集进行低维可视化。加号是缺陷,圆圈是标称。红色表示查询到了真正的缺陷点。绿色表示查询到了标称点。灰色圆圈对应于未命名的标称。为了使未经验证的缺陷在视觉上突出,它们用蓝色加号表示
5.4 Application in metal AM
本小节使用EBM过程中的金属AM数据集(Townsend等人,2016)来评估SALDD的测量分配问题。在印刷过程中,机器ARCAM Q10 plus用于印刷尺寸为15mm×15mm×25mm的样品。图5.7(a)所示的图像是印刷零件的2D表面图案。我们希望对一些位置进行采样以测量表面形态,因为测量成本高昂,并且成本(测量次数)需要控制在预算范围内。我们提出的算法用于选择Sa(区域的算术平均高度)测量的位置(Thomas,1981),以识别表面光洁度较差的表面区域。

图5.7 金属AM数据集:(a) 2D扫描图像(黄色方形框是随机选择的样本);(b)对应的点云数据
为了获得多个训练样本,从图5.7(a)中的图像中随机选择200个大小为60×60的图像,没有重叠。每个图像被转换为具有3600个变量的向量,其中每个变量表示从0到255的像素值。本小节中的实验程序如下:
- Step 1 (贴标签, Labeling):对于图5.7(a)中的200张图像,根据同一区域的点云数据计算出相应的表面粗糙度Sa,如图5.7(b)所示。具有最高Sa的前7个图像被标记为
- Step 2 (实施, Implementation):对于步骤1中的这200个图像,它们的实际标签(即
预算被设置为45(测量次数)。图5.8(a)绘制了检测到的缺陷数量与测量次数(迭代)的关系图。在算法的10次独立运行中对曲线进行平均,并显示了95%的置信区间。图5.8(a)中的结果表明,所提出的SALDD比无监督基线和GLDD表现更好。具体而言,所提出的SALDD在40次测量中检测到所有7个缺陷。图5.8(b)绘制了我们的算法在2D表面视图中的Sa测量位置。所有缺陷都在中间区域的字母“R”周围,我们的算法正确地识别了这些缺陷。其他测量位置有几个聚类,这表明我们的算法可以准确地决定测量哪个位置,以最大概率捕捉较差的表面光洁度。
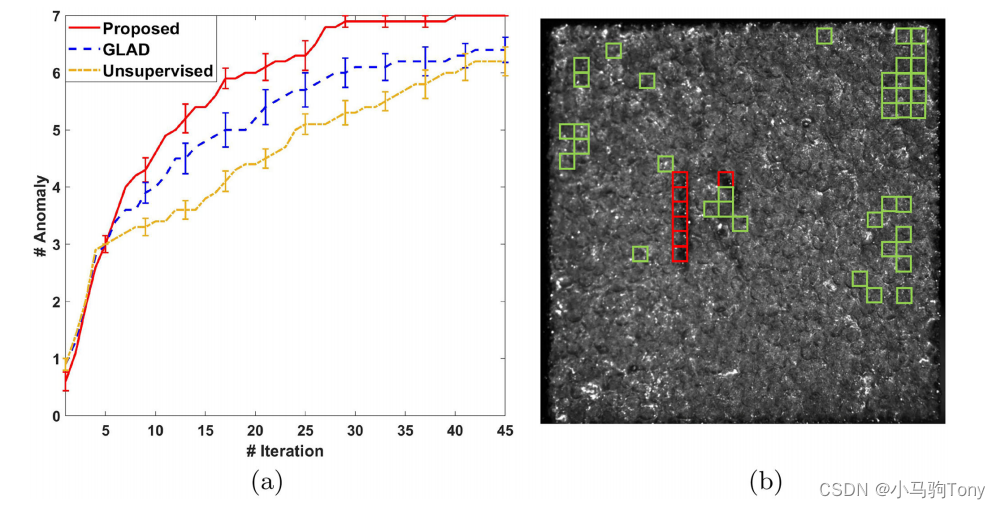
图5.8 (a)检测到的缺陷的总数与金属AM数据集上的迭代次数的关系(误差条表示95%置信区间);(b)Sa测量的位置。红色框表示查询到了真正的缺陷点,绿色框表示查询了标称点。
图5.9显示了t-SNE生产的金属AM的2D表示,以及基准测试和SALDD进行的查询。所提出的SALDD可以检测左下角的所有七个缺陷,如图5.9(c)所示,而无监督基线和GLDD分别遗漏了两个和一个缺陷。此外,图5.9(c)显示了SALDD在缺陷区域查询更多的实例,证明了它在缺陷发现中的有效性。
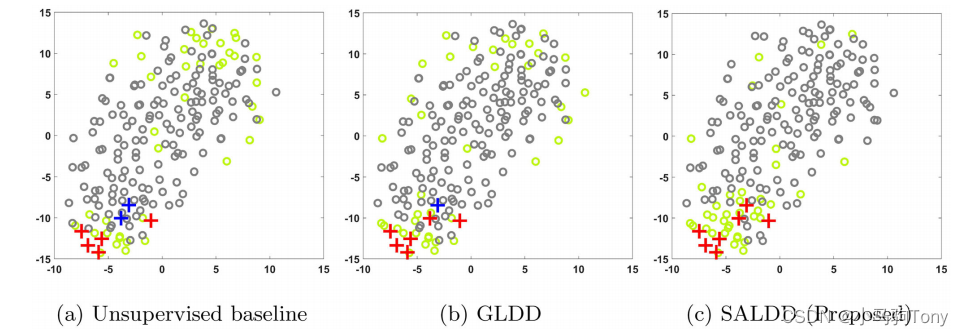
图5.9 使用t-SNE实现金属AM数据集的低维可视化
6 Conclusion
本文提出了一种新的SALDD算法,在基于隔离森林的主动缺陷发现中加入稀疏性约束。对隔离森林特征函数的稀疏性进行了理论研究和实证验证,以表明我们包含稀疏性的动机。通过数值和实际案例研究验证了该算法的有效性。在数值研究中,经验收敛性表明了所提出的SALDD在遗憾和模型稀疏性方面的权衡行为。
具体来说,所提出的SALDD可以同时保持模型的准确性和稀疏性。来自医疗保健、制造、安全等领域的各种应用的真实世界数据集用于评估我们提出的算法。基于这些结果,很明显,SALDD通过在模型中包含稀疏性而优于文献中最先进的算法,尤其是对于具有大量实例的数据集。我们提出的算法适用于缺陷比例较小的多元数据集。