文章目录
前言
作为一个开发人员,在服务器上查看日志是必备的技能。
运行在服务器上的程序会实时产生大量的日志,精准的找到自己需要查看部分,查看命令日志这么多,需要用什么效率比较高呢,来实践一下。
一、常用命令总结
1、tail命令:用于显示文件的末尾内容。
例如:tail -n 100 filename 将显示文件filename的最后100行内容。
2、head命令:用于显示文件的开头内容。
例如:head -n 100 filename 将显示文件filename的前100行内容。
3、cat命令:用于将文件内容输出到终端。
例如:cat filename 将显示文件filename的全部内容。
4、less命令:用于以可滚动的方式查看大型文件。
例如:less filename 将打开文件filename,您可以使用上下箭头和Page Up/Page Down键来浏览文件。
5、grep命令:用于在文件中搜索特定的内容。
例如:grep “keyword” filename 将在filename文件中搜索包含"keyword"的行。
二、使用案例
1、tail命令
常用参数
-f 循环读取 【常用】
-n<行数> 显示文件的尾部 n 行内容 【常用】
-q 不显示处理信息 【不常用】
-v 显示详细的处理信息 【不常用】
-c<数目> 显示的字节数 【不常用】
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部 【不常用】
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
- -n<行数> :显示文件的尾部 n 行内容
tail -n 20 doupo.txt

- -f : 循环读取【实时获取到文件更新内容】 常用
常用于程序运行起来时候,触发条件,获取实时日志内容。
# 监听文件实时更新内容,打印新添加内容到控制台
tail -f mydata.txt
# 查看最后1000行并实时监听文件的更新
tail -1000f doupo.txt
文件添加who am i
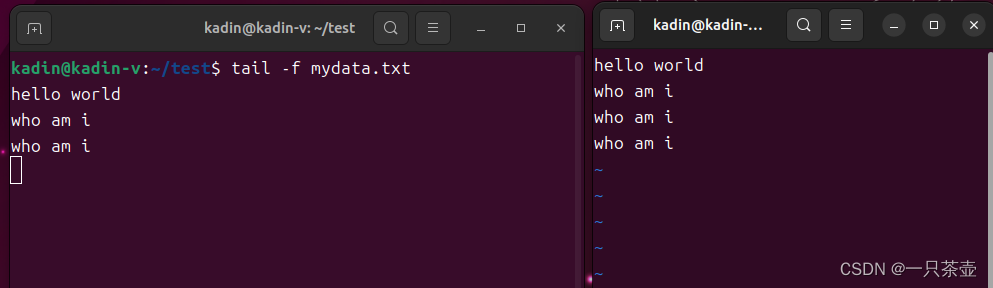
控制台实时输出,who am i
2、head命令
head 命令可用于查看文件的开头部分的内容,有一个常用的参数 -n 用于显示行数,默认为 10,即显示 10 行的内容。
-q 隐藏文件名 【不常用】 tail -q doupo.txt
-v 显示文件名】【不常用】 tail -v doupo.txt
-c<数目> 显示的字节数。【不常用】 tail -c 1M doupo.txt
-n<行数> 显示的行数。【常用】
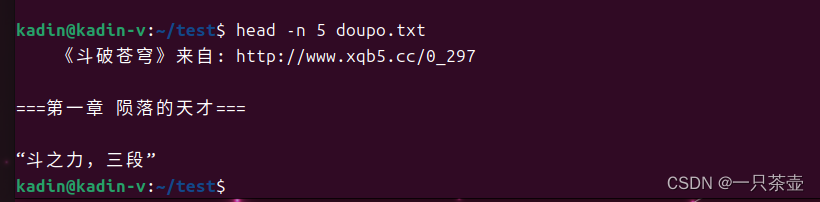
# 查看文件最开头的5行
head -n 5 doupo.txt
3、cat命令
命令用于连接文件并打印到标准输出设备上。
常用参数:
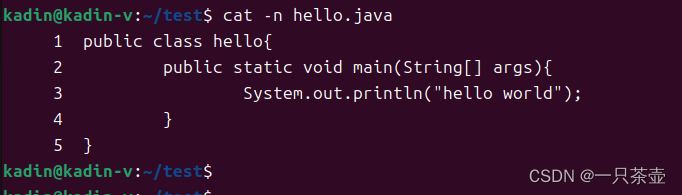
-n 或 --number:由 1 开始对所有输出的行数编号。
cat -n hello.java
4、less命令 [好用]
less 可以随意浏览文件,支持翻页和搜索,支持向上翻页和向下翻页。和more 类似
命令选项:
-N:显示行号。
-n:不显示行号。
-i:忽略大小写。
-F:一次性显示整个文件,不进行分页。
-f:强制显示文件名。
-q:静默模式,不显示任何提示信息。【退出】
【执行 less filename 后使用】:
:G 移动到文件末尾 ---【很常用】
:g 移动到文件最开头
:/ 搜索指定字符串。向上匹配 ---【很常用】
:? 全文向上匹配字符,高亮显示 ---【很常用】
:n 重复前一个搜索(与 / 或 ? 有关) ---【很常用】
:N 反向重复前一个搜索(与 / 或 ? 有关)---【很常用】
:b[pageup] backward向上翻一页---【很常用】
:f[空格/pagedown] forward向后翻一页---【很常用】
:d 向后翻半页
:u 向前滚动半页
:y 向前一行
:Enter 向后一行
匹配字段高亮显示字段
less doupo.txt
- 输入G滚动到末尾
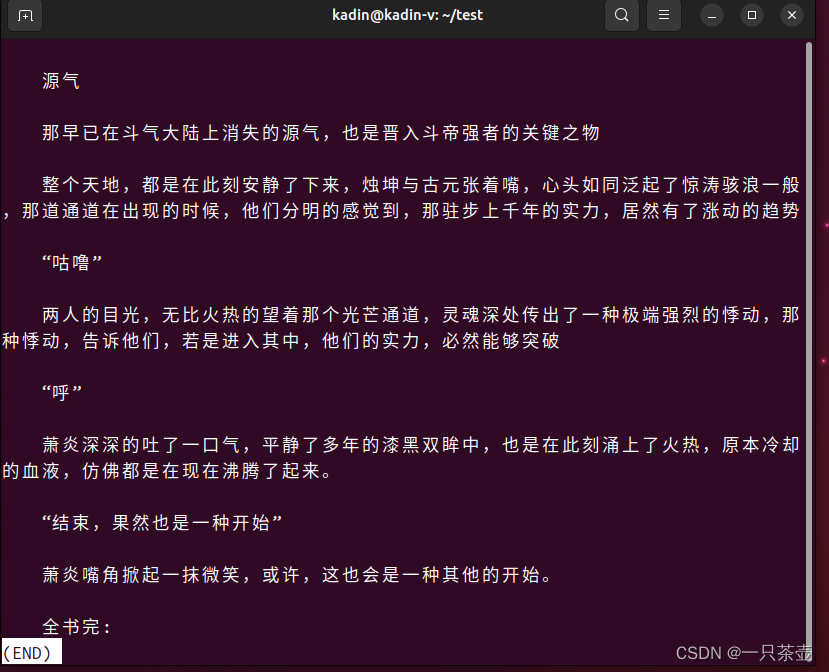
- 输入? 加需要匹配的字符
?桀桀
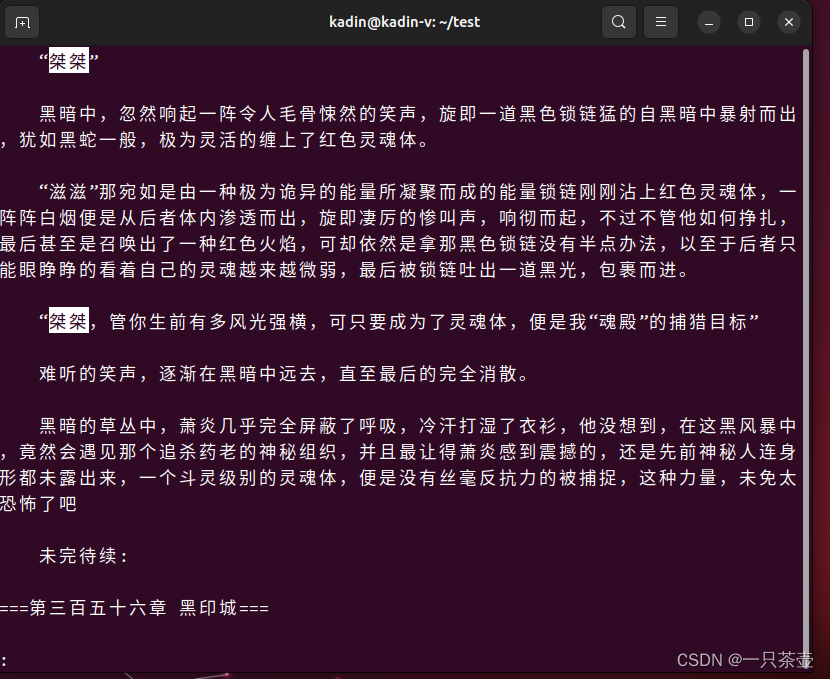
- 再按 n 或者N,快速查看匹配字段的上一个,下一个
5、grep命令【好用】
用于查找文件里符合条件的字符串或正则表达式
显示符合样式的那一行
【添加其他参数可以显示匹配行的周围行{-A,-B,-C}后面接上行数】
-a 或 --text : 不要忽略二进制的数据。
-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 --count : 计算符合样式的列数。
-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-i 或 --ignore-case : 忽略字符大小写的差别。
常用
grep 桀桀 doupo.txt
# 每一个匹配内容所在行+后10行
grep -A 10 桀桀 doupo.txt
# 每一个匹配内容所在行+前10行
grep -B 10 桀桀 doupo.txt
# 每一个匹配内容所在行+前后10行
grep -B 10 桀桀 doupo.txt
还有其他参数,但是我不常用吗,后续用到补充

6、>和>>
都属于输出重定向,都可以输出内容到指定文件。
-
当日志文件内容太多,不方便查看,可以把需要的内容输出到新的文件中, 通过查看新的文件中的日志内容更快速查看
> 会覆盖目标的原有内容,当文件存在时,会先删除原文件,再重新创建文件,然后把内容写入该文件,否则直接创建文件。 >>会在目标原有内容后追加内容,当文件存在时直接在文件末尾进行内容追加,不会删除原文件,否则直接创建文件。
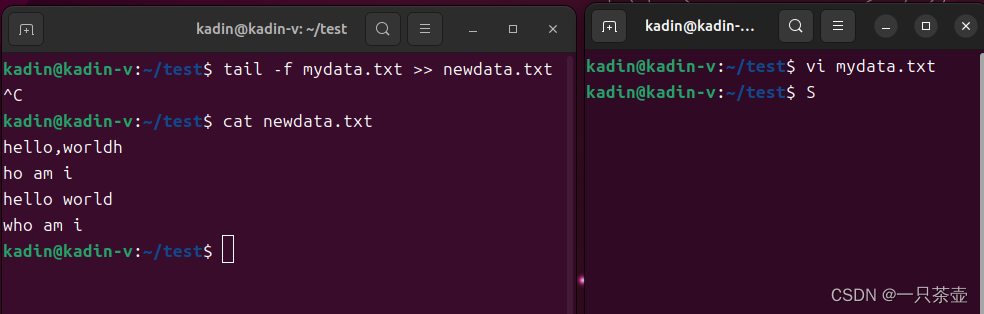
# 实时输出内容到 newdata.txt文件中
tail -f mydata.txt > newdata.txt
# 实时输出内容追加到 newdata.txt文件中
tail -f mydata.txt >> newdata.txt

7、| 管道符
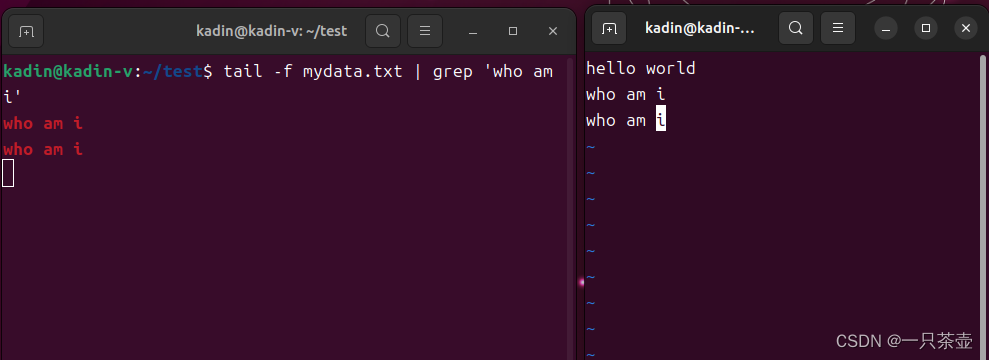
“|”是Linux管道命令操作符,简称管道符。使用此管道符“|”可以将两个命令分隔开,“|”左边命令的输出就会作为“|”右边命令的输入,此命令可连续使用,第一个命令的输出会作为第二个命令的输入,第二个命令的输出又会作为第三个命令的输入,依此类推。
常用查看日志命令
tail -f mydata.txt | grep ‘who am i’
加上 grep参数-C 20可以查看匹配字符周围几行,我比较常用
总结
服务器中查看日志比较常用的:
# 配合G ? / n N 使用
less filename
# 配合grep 参数
tail -f filename | grep -C 50 'content' > newlog.txt