目录
让模拟实现的vector支持 {} 初始化,只需加上下面这个构造函数:
C++里面对victor初始化的时候传参数代表的是将这个victor预先扩容,扩容成指定数字的大小。

move, bit: :string s3(move(s1));
例1:在for外面加锁,两线程持续串行打印,一个线程占据for循环时,另一个就一直等待。(是串行打印的)
例2:在for里面加锁,两线程交替串行打印。(是并行打印的)
一.统一的列表初始化
1.{}初始化

容器的{}初始化
比如vector,list,set,map都支持一个initializer_list类型的构造函数,因此他们都可以用 {} 初始化
vector<int> v1 = { 1, 2, 3, 4, 5 };
vector<int> v2 { 1, 2, 3, 4, 5 };
vector<Date> v3 = { { 2022, 1, 1 }, { 2022, 1, 1 }, { 2022, 1, 1 } };
list<int> lt1{ 1, 2, 3 };
set<int> s1{ 3, 4, 5, 6, 3 };
map<string, string> dict = { { "string", "字符串" }, { "sort", "排序" } };
列表初始化在初始化时,如果出现类型截断,是会报警告或者错误的,所以使用{}初始化和直接初始化还是有区别的。
2. std::initializer_list
std::initializer_list是什么类型:


int main()
{
// the type of il is an initializer_list
auto il = { 10, 20, 30 };
cout << typeid(il).name() << endl;//class std: initializer list<int>
return 0;
}
int main()
{
vector<int> v = { 1,2,3,4 };
list<int> lt = { 1,2 };
// 这里{"sort", "排序"}会先初始化构造一个pair对象
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
// 使用大括号对容器赋值
v = {10, 20, 30};
return 0;
}std::initializer_list支持迭代器
initializer_list<double> ilt = { 3.3, 5.5, 9.9 };
initializer_list<double>::iterator it = ilt.begin();
while (it != ilt.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : ilt)
{
cout << e << " ";
}
cout << endl;让模拟实现的vector支持 {} 初始化,只需加上下面这个构造函数:

二.声明
decltype
// decltype的一些使用使用场景
template<class T1, class T2>
void F(T1 t1, T2 t2) {
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
const int x = 1;
double y = 2.2;
decltype(x * y) ret; // 推导出x * y类型是double,所以ret的类型是double
decltype(&x) p; // 推导出x类型是int,p的类型是int*
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl;
F(1, 'a');
return 0;
}三.STL中一些变化

array就是个静态数组,鸡肋
int a1[10];
对比c的静态数据,访问更安全
array<int, 10> a2;
不一定能检查出来越界:
//a1[10];
只要越界一定能检查出来越界:
//a2[10];< forward_ list> 就是单向链表,但是不考虑双链表多开的那一点空间,日常情况下 list就够用了,所以还是鸡肋
C++里面对victor初始化的时候传参数代表的是将这个victor预先扩容,扩容成指定数字的大小。

四.左值引用和右值引用
1.什么是左值?什么是左值引用?
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}2.什么是右值?什么是右值引用?
int main()
{
double x = 1.1, y = 2.2;
以下几个都是常见的右值:
10;
x + y;
fmin(x, y);
以下几个都是对右值的右值引用:
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
下面编译会报错:error C2106: “=”: 左操作数必须为左值:
10 = 1;
x + y = 1;
fmin(x, y) = 1;
下面都是错误的,右值不能被引用:
//cout << &10 << endl;
//cout << &(x + y) << endl;
//cout << &fmin(x, y) << endl;
return 0;
}3.左值引用与右值引用比较
(1)左值和右值最大区别:左值可以取地址,右值不能取地址
左右值在拷贝上的区别:左值拷贝是不会被资源转移(掠夺)偷家,右值拷贝会被资源掠夺偷家
(2)左值引用总结:
void push_ back(const T& x)能传左值和右值。
(3)右值引用总结:
int main()
{
int&& r1 = 10; //右值引用正确写法
int a = 10;
int&& r2 = a; //错误:右值引用不能引用左值
int&& r3 = std::move(a); // 正确,右值引用可以引用move以后的左值
return 0;
}五.移动构造与移动赋值
STL的容器,C++11以后,都提供移动构造和移动赋值
1.将亡值
右值分为两种:
1、纯右值(内置类型的右值):10 a+b
2、将亡值(自定义类型的右值):匿名对象string("11111") ,临时对象to_ string(1234), s1+"hello"表达式的返回值 ,move(s1)-> 都是自定义类型对象,这些表达式的返回值就是将亡值
将亡值定义:这些匿名对象的生命周期就在本行,用完就没了。
move, bit: :string s3(move(s1));
【bit: :string s3(move(s1)); move 是用于把左值属性的s1转换出一个临时对象,这个临时对象是一个右值,我们引用这个右值,当其他对象s3拷贝s1时就可以掠夺s1的资源】本身是是不会改变s1的左值属性,仅仅进行右值引用

2.移动构造
(1)移动构造介绍
移动构造:拷贝将亡值时不能对将亡值深拷贝,应直接把将亡值的资源交给新的对象,就是把将亡值指向资源的地址直接给新的对象(交换_str,_size,_capacity)。而拷贝构造不区分左右值,走的全是深拷贝,效率低。相比之下移动构造效率极高。
swap是自己写的swap,交换了_str,_size,_capacity

namespace bit
{
class string
{
public:
// 移动构造
string(string&& s) 右值匹配
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 资源转移" << endl;
swap(s);
}
// 拷贝构造
string(const string& s) 左值匹配,实际左右值都能匹配,但右值会去匹配更匹配的
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
……
int main()
{
bit::string ret = bit::to_string(1234); 1234是右值,调用移动构造
cout << ret.c_str() << endl;
(2)移动构造中的优化
① C++98中:

② C++11中:加入移动构造
to_ string(1234)函数中返回str,str因即将出作用域,所以只能先拷贝构造一个临时对象,临时对象是将亡值,再用临时对象移动构造一个ret对象;编译器优化后 把返回值str转换识别成右值,然后直接移动构造给ret。(移动构造对直接转移资源,效率极高)

3.移动赋值
namespace bit
{
class string
{
public:
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 资源转移" << endl;
swap(s);
return *this;
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
……
int main()
{
bit::string ret;
ret = bit::to_string(1234);
cout << ret.c_str() << endl;
return 0;
}4.万能引用,完美转发
template<typename T>
void PerfectForward(T&& t)
{
//bit::string copy1 = t;
完美转发:
bit::string copy2 = std::forward<T>(t);
}
int main()
{
PerfectForward(10); // 右值,完美转发后仍调用移动构造
int a;
PerfectForward(a); // 左值,调用拷贝构造
PerfectForward(std::move(a)); // 右值,完美转发后仍调用移动构造
const int b = 8;
PerfectForward(b); // const 左值,调用拷贝构造
PerfectForward(std::move(b)); // const 右值,完美转发后仍调用移动构造
return 0;
}void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
// std::forward<T>(t)在传参的过程中保持了t的原生类型属性。
template<typename T>
void PerfectForward(T&& t) {
//Fun(t); 原本错的会改变属性的写法
完美转发:
Fun(std::forward<T>(t));
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}5.默认 移动构造函数和移动赋值运算符重载
原来C++类中,有6个默认成员函数:
// 以下代码在vs2013中不能体现,在vs2019下才能演示体现上面的特性。
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
private:
bit::string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1; // 拷贝构造
Person s3 = std::move(s1); // 移动构造
Person s4;
s4 = std::move(s2);
return 0;
}(1)强制生成默认函数的关键字default:
如果我们写了拷贝构造,就不会自动生成默认的移动构造,可以使用default关键字强制移动构造或移动赋值生成。
// 以下代码在vs2013中不能体现,在vs2019下才能演示体现上面的特性。
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p)
:_name(p._name)
,_age(p._age)
{}
//强制生成移动构造和移动赋值
Person(Person&& pp) = default;
Person& operator= ( Person&& pp) = default;
private:
bit::string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1; // 拷贝构造
Person s3 = std::move(s1); // 移动构造
Person s4;
s4 = std::move(s2);
return 0;
}
(2)强制不让生成 delete
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p) = delete;
private:
bit::string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
return 0;
}六.可变参数模板
1.模板函数包
声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
下面就是一个基本可变参数的函数模板
template <class ...Args>
void ShowList(Args... args)
{}解释第一个 ShowList(1,'x',1.1) :
1传给val,'x'和1.1传给参数包Args... args,则打印参数包的个数是2个,即sizeof...(args)=2,
cout << sizeof...(args) << endL ; 打印:2
cout << val << "->" << typeid(val).name() << endL ; 打印:1->int (val是1,typeid(val).name() 打印val的类型,是int)
ShowL ist(args...); 把剩下的'x'和1.1传入ShowList——第二次传入:
此时'x'传给val,1.1传给参数包Args...args,则打印参数包的个数是1个,即sizeof...(args)=2,
cout << sizeof...(args) << endL ; 打印:1
cout << val << "->" << typeid(val).name() << endL ; 打印:x->char (val是'x',typeid(val).name() 打印'x'的类型,是char)
ShowL ist(args...); 把仅剩下的1.1传入ShowList——第三次传入:
此时'x'传给val,参数包Args...args什么也不传了,则打印参数包的个数是0个,即sizeof...(args)=0
cout << sizeof...(args) << endL ; 打印:0
cout << val << "->" << typeid(val).name() << endL ; 打印:1.1->double(val是1.1,typeid(val).name() 打印1.1的类型,是double)
ShowL ist(args...); 没有数据可以传了,就结束了

2.emplace_back
template <class... Args>
void emplace_back (Args&&... args);int main()
{
std::list< std::pair<int, char> > mylist;
// emplace_back支持可变参数,拿到构建pair对象的参数后自己去创建对象
// 那么在这里我们可以看到除了用法上,和push_back没什么太大的区别
mylist.emplace_back(10, 'a');
mylist.emplace_back(20, 'b');
mylist.emplace_back(make_pair(30, 'c'));
mylist.push_back(make_pair(40, 'd'));
mylist.push_back({ 50, 'e' });
for (auto e : mylist)
cout << e.first << ":" << e.second << endl;
return 0;
}int main()
{
// 下面我们试一下带有拷贝构造和移动构造的bit::string,再试试呢
// 我们会发现其实差别也不到,emplace_back是直接构造了,push_back
// 是先构造,再移动构造,其实也还好。
std::list< std::pair<int, bit::string> > mylist;
mylist.emplace_back(10, "sort");
mylist.emplace_back(make_pair(20, "sort"));
mylist.push_back(make_pair(30, "sort"));
mylist.push_back({ 40, "sort" });
return 0;
}emplace_back相比push_ back优化:对于list中尾插右值pair,
mylist.emplace_back(10, "sort"); 和mylist.emplace_back(make_pair(20, "sort"));是直接构造了,mylist.push_back(make_pair(30, "sort")); 和 mylist.push_back({ 40, "sort" });是先构造,再移动构造,多了一次移动构造,其实也还好,因为 push_back:拷贝构造(深拷贝)+移动构造(资源转移) 和 emplace_back:直接一次拷贝构造(深拷贝) 的效率差别不大。但是对于Date类这种不需要深拷贝的类型的更明显,因为日期类是浅拷贝,没有资源转移,所以日期类的移动构造就变成的浅拷贝,push_back:拷贝构造(浅拷贝)+移动构造(浅拷贝) 和 emplace_back:直接一次拷贝构造(浅拷贝),emplace_back是直接构造效率会更高。
七.线程库


fn万能引用传函数,Args模板可变参数 是先传给thread构造函数,然后通过构造函数间接拷贝方式传给这个fn函数。
1.线程——std::this_ thread
get_id 得到线程id

例1:双线程乱序打印线程ip和i值
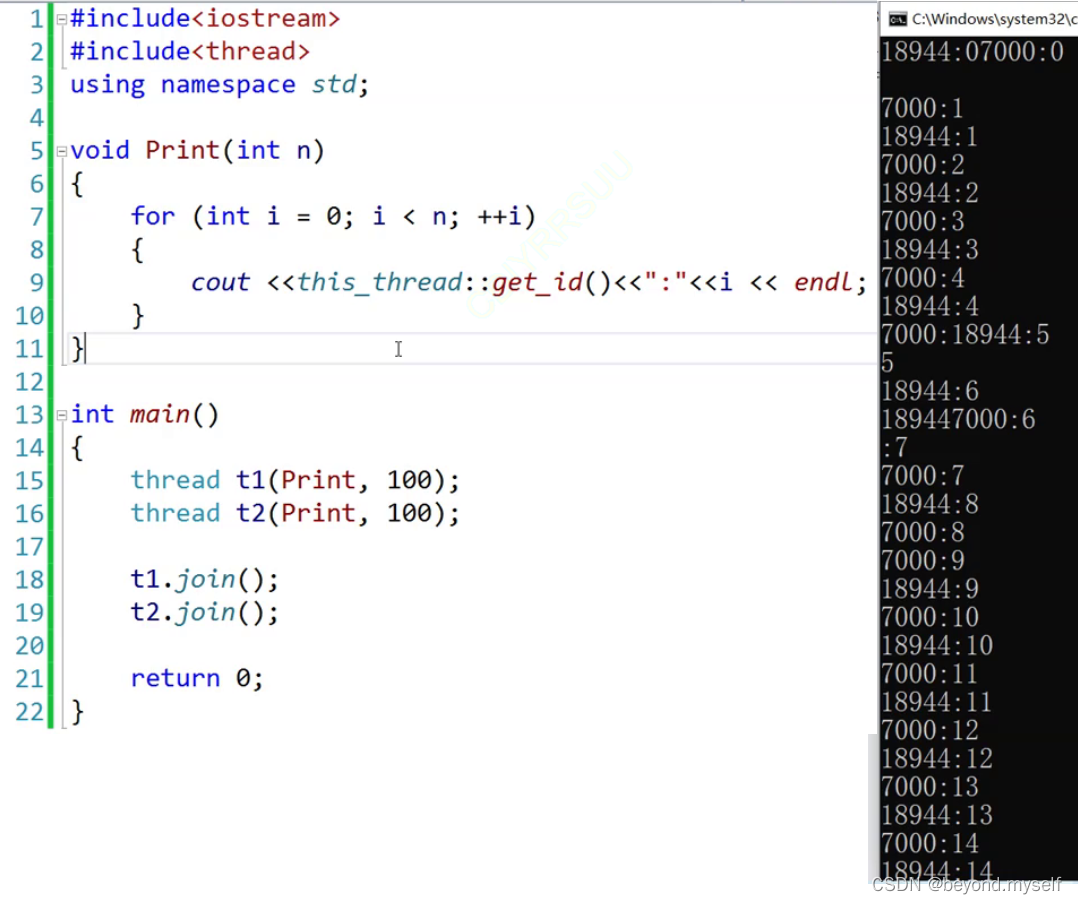
例2:隔100ms-0.1s打印一次

2.mutex

例1:在for外面加锁,两线程持续串行打印,一个线程占据for循环时,另一个就一直等待。(是串行打印的)
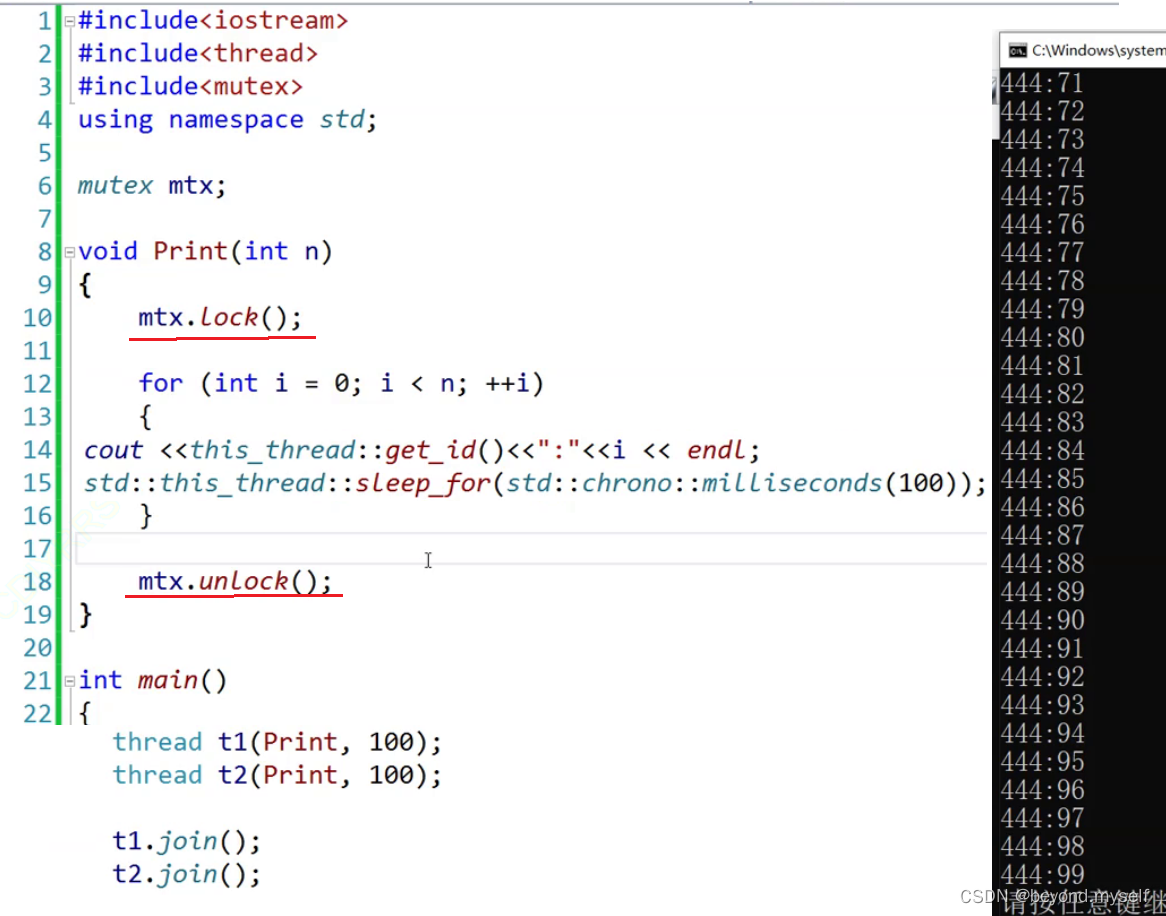
例2:在for里面加锁,两线程交替串行打印。(是并行打印的)

例3:间接传参的 引用小bug
fn万能引用传函数,因为Args模板可变参数 是先传给thread构造函数,然后通过构造函数间接拷贝方式传给这个fn函数。所以引用不起作用,也是编译器识别的bug。即:这无论是int x和int& x,都是拷贝传参。
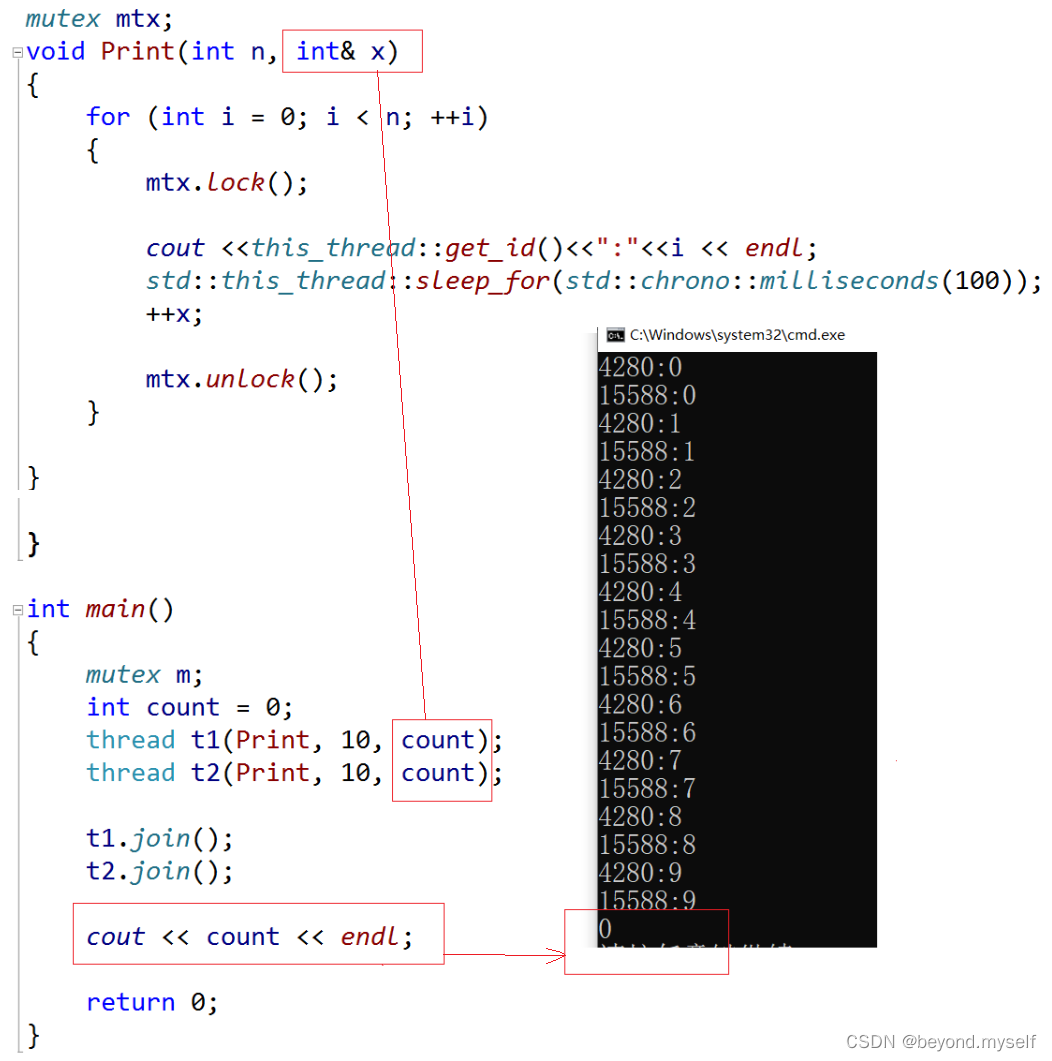
例4:ref解决引用失效小bug(x指针传参也可以解决)
ref+全局变量mutex
ref作用:强制以左值引用传参,这样引用就可以起作用了。(如果上面是int x就还是传值拷贝)
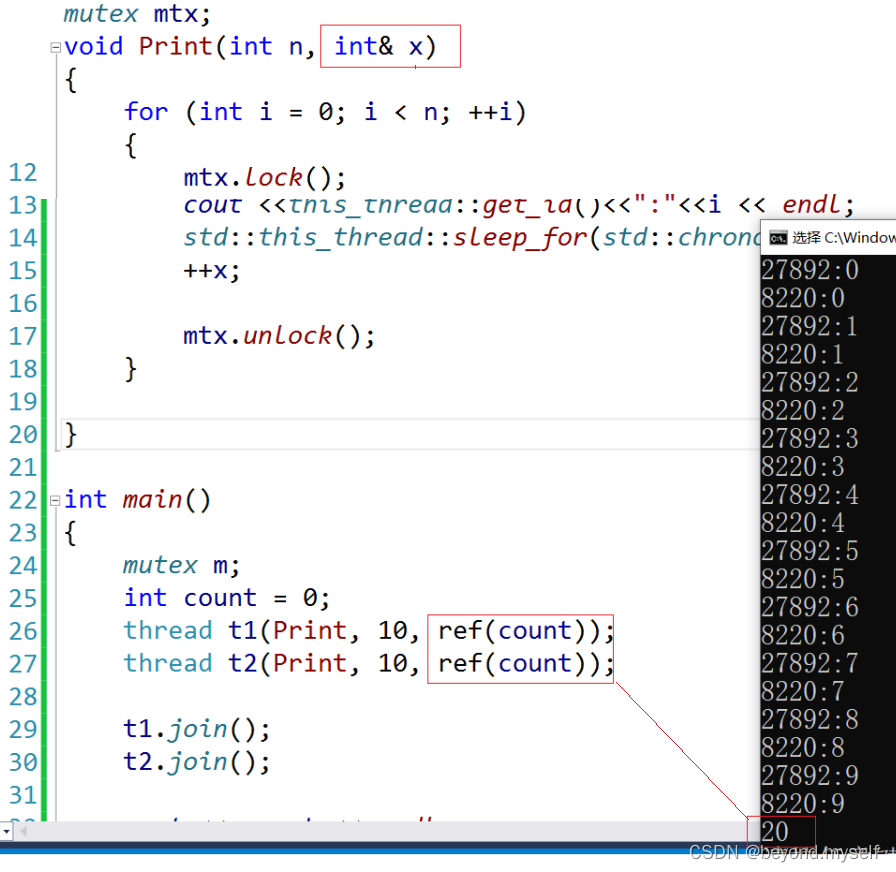
ref+mutex 传参, ref(count), ref(m)
#include<iostream>
#include<thread>
#include<mutex>
#include <condition_variable>
#include<vector>
#include<atomic>
using namespace std;
void Print(int n, int& x, mutex& mtx)
{
for (int i = 0; i < n; ++i)
{
mtx.lock();
cout <<this_thread::get_id()<<":"<<i << endl;
std::this_thread::sleep_for(std::chrono::milliseconds(100));
++x;
mtx.unlock();
}
}
int main()
{
mutex m;
int count = 0;
thread t1(Print, 10, ref(count), ref(m));
thread t2(Print, 10, ref(count), ref(m));
t1.join();
t2.join();
cout << count << endl;
return 0;
}例5:lambada表达式写入线程初始化的第一个参数
#include<iostream>
#include<thread>
#include<mutex>
#include<vector>
int main()
{
mutex mtx;
int x = 0;
int n = 10;
int m;
cin >> m;
vector<thread> v(m);
//v.resize(m);
for (int i = 0; i < m; ++i)
{
// 移动赋值给vector中线程对象
v[i] = thread([&](){ //&捕捉所有变量
for (int i = 0; i < n; ++i)
{
mtx.lock();
cout << this_thread::get_id() << ":" << i << endl;
std::this_thread::sleep_for(std::chrono::milliseconds(100));
++x;
mtx.unlock();
}
});
}
for (auto& t : v)
{
t.join();
}
cout << x << endl;
return 0;
}例6:并行++ 和 串行++
并行++比串行++慢,因为申请锁、释放锁要花时间。并行++要400w次申请释放锁,串行++只需要4次。
int main()
{
mutex mtx;
int x = 0;
int n = 1000000;
int m;
cin >> m;
vector<thread> v(m);
for (int i = 0; i < m; ++i)
{
// 移动赋值给vector中线程对象
v[i] = thread([&](){
for (int i = 0; i < n; ++i)
{
// 并行
mtx.lock();
++x;
mtx.unlock();
}
});
//v[i] = thread([&](){
// // 串行
// mtx.lock();
// for (int i = 0; i < n; ++i)
// {
// ++x;
// }
// mtx.unlock();
//});
}
for (auto& t : v)
{
t.join();
}
cout << x << endl;
return 0;
}3.atomic——CAS操作
CAS 操作(compare and swap):当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
举例说明:atomic<int> x = 0; 则++x时不用加锁了,4个线程可以任意++,若出现同时++的情况,假如x=0,线程t1、t2、t3、t4同时++,t1先把x=1放回内存时,此时内存值是0,比较0和1,发现未被改变,则可以把自己++后的1放入内存;然后t2 / t3 / t4再想放入自己的++结果1时,compare比较当前内存值和之前取得的值是否相等,相等则内存中数据已被修改,则写入失败,重新执行++并尝试写入。
int main()
{
mutex mtx;
atomic<int> x = 0;
//int x = 0;
int n = 1000000;
int m;
cin >> m;
vector<thread> v(m);
for (int i = 0; i < m; ++i)
{
// 移动赋值给vector中线程对象
v[i] = thread([&](){
for (int i = 0; i < n; ++i)
{
// t1 t2 t3 t4
++x;
}
});
}
for (auto& t : v)
{
t.join();
}
cout << x << endl;
return 0;
}两个线程交错打印1-100,一个打印奇数,一个打印偶数
int main()
{
int i = 0;
int n = 100;
thread t1([&](){
while (i < n)
{
while (i % 2 != 0)
{
this_thread::yield();
}
cout <<this_thread::get_id()<<":"<<i << endl;
i += 1;
}
});
thread t2([&](){
while(i < n)
{
while (i % 2 == 0)
{
this_thread::yield();
}
cout << this_thread::get_id() << ":" << i << endl;
i += 1;
}
});
t1.join();
t2.join();
return 0;
}t2打印偶数,所以让线程2先走


当pred是false时,需要wait
int main()
{
int i = 0;
int n = 100;
mutex mtx;
condition_variable cv;
bool ready = true;
// t1打印奇数
thread t1([&](){
while (i < n)
{
{
unique_lock<mutex> lock(mtx);
cv.wait(lock, [&ready](){return !ready; });
cout << "t1--" << this_thread::get_id() << ":" << i << endl;
i += 1;
ready = true;
cv.notify_one();
}
//this_thread::yield();
this_thread::sleep_for(chrono::microseconds(100));
}
});
// t2打印偶数
thread t2([&]() {
while (i < n)
{
unique_lock<mutex> lock(mtx);
cv.wait(lock, [&ready](){return ready; });
cout <<"t2--"<<this_thread::get_id() << ":" << i << endl;
i += 1;
ready = false;
cv.notify_one();
}
});
this_thread::sleep_for(chrono::seconds(3));
cout << "t1:" << t1.get_id() << endl;
cout << "t2:" << t2.get_id() << endl;
t1.join();
t2.join();
return 0;
}