1 代码运行正常,显存占用在逐渐增长,最终 out of memory!
常见的可能性与解决方案:
# 加torch的显存优化
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True
# loss加item()
train_loss += loss.item()
# delete caches
del 变量
torch.cuda.empty_cache()
# 以上常见解决方案没有奏效,empty cache 只能清理掉被丢弃的缓存,并不能降低峰值显存占用。
遇到的问题:
(模型中加了一个可微的layer,training 的时候此子模型是在with torch.enable_grad() 内,因此初步尝试将其放在with torch.no_grad():下找找问题所在)
with torch.no_grad(): # 加了这句,显存增长问题解决
out = self.noise_layers(encoded, cover_img)
打印显存分配变化,梯度缓存的累加并没有在显存分配这里体现
memory1 = torch.cuda.memory_allocated(0)
out = self.noise_layers(encoded, cover_img)
memory2 = torch.cuda.memory_allocated(0)
print('noise layer:', memory2-memory1, '\n')
虽然加了with torch.enable_grad() 后显存不增长了,但是enable_grad() 会导致计算图中断,梯度无法反传。
最终,找到代码里有如下定义:
matrix = np.array(
[[0.299, 0.587, 0.114], [-0.168736, -0.331264, 0.5],
[0.5, -0.418688, -0.081312]], dtype=np.float32).T
self.shift = nn.Parameter(torch.tensor([0., 128., 128.]), requires_grad=False)
self.matrix = nn.Parameter(torch.from_numpy(matrix), requires_grad=False)
问题在这儿!nn.Parameter() 统统加上requires_grad=False ,搞定!
查一下torch官方doc里的 torch.nn.Parameter()
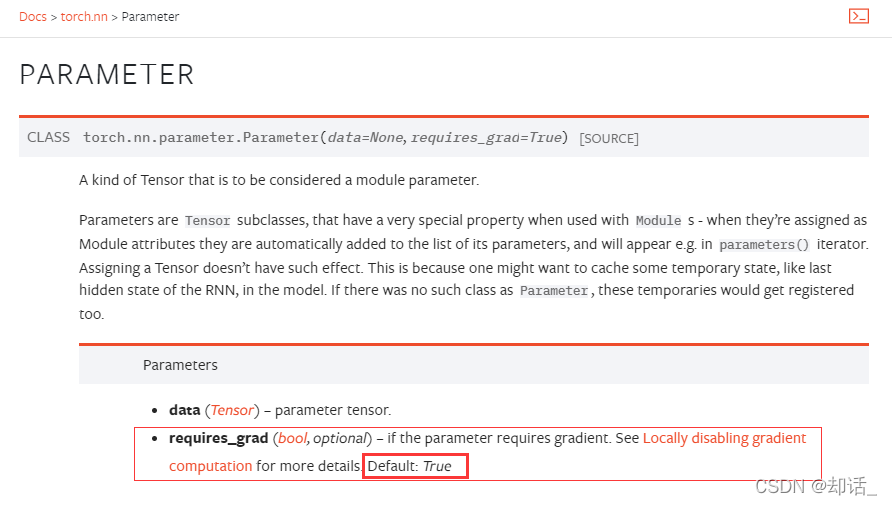
可知 nn.parameter() 是tensor的一个子类,required_grad默认是true!,可以作为 nn.module 里的可训练参数使用。另一个作用时torch里初始化参数用的就是nn.parameter()。
最近又遇到一个新坑,保存loss的时候直接保存了tensor,导致tensor在不断的累加
# step update
current_step += 1
train_step += 1
loss_per_epoch = loss_per_epoch + (loss_RecImg + loss_RecMsg + loss_encoded)
# write losses
utils.mkdir(loss_w_folder)
utils.write_losses(os.path.join(loss_w_folder, 'train-{}.txt'.format(time_now_NewExperiment)), loss_per_epoch/train_step, current_epoch)
显存一直涨,改为
loss_per_epoch = loss_per_epoch + (loss_RecImg.item() + loss_RecMsg.item() + loss_encoded.item())