基本思想:进行是数据集的预处理和标注,然后进行分开目标检测训练和关键点训练,然后增加追踪逻辑
一、标注关键点数据,这里标注只是使用标注检测框和关键点即可,在本质上也可以不用标注检测框,因为个人的数据集是鱼类,可以通过全身的关键点拟合成检测框,提供标注数据集,然后进行提取两类数据集一类为关键点数据集(coco),另一类为检测类数据集(yolov5/7)
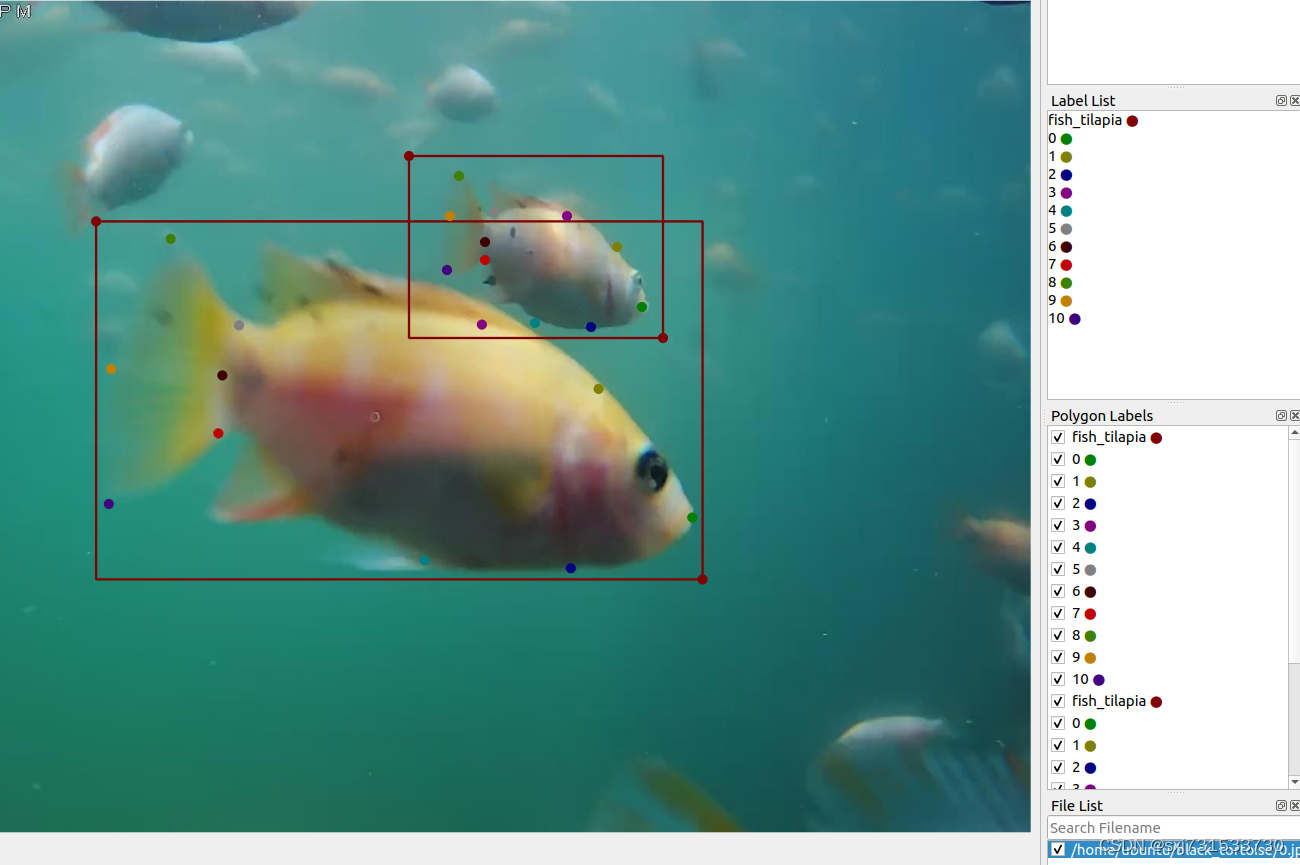 注意:下表从0-10序号,依次为鱼嘴逆时针排列11个关键点,矩形框标签为fish_0 ,序号参考如下
注意:下表从0-10序号,依次为鱼嘴逆时针排列11个关键点,矩形框标签为fish_0 ,序号参考如下

标注完数据之后,进行提取目标检测数据集和关键点数据集,(等待第一版模型出现,做自动化标注,全部以python调用onnx完成开发)代码:
import numpy as np
import json
import glob
import codecs
import os
import cv2
import json
import shutil
import os
from xml.dom.minidom import Document
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
class Tococo(object):
def __init__(self, Path, save_path, labelimg_path, keypoints, skeleton, label, verify_flag, verify_path,
inital_start_id, verify_labelimg_flag, supercategory):
self.labelimg_path = labelimg_path
self.verify_flag = verify_flag
self.label = label
categories = {}
categories.update({"supercategory": supercategory})
categories.update({"id": 0})
categories.update({"name": label})
categories.update({"keypoints": keypoints})
self.keypoints_length = len(keypoints)
self.inital_start_id = inital_start_id
categories.update({"skeleton": skeleton})
self.categories = [categories]
self.imagePath = None
self.imageData = None
self.imageHeight = None
self.imageWidth = None
self.imageName = None
self.imageName_Noext = None
self.image = []
self.annotations = []
self.jsonfile = glob.glob(os.path.join(Path, "*.json"))
self.ext = "png"
self.imgfile = glob.glob(os.path.join(Path, "*." + self.ext))
if len(self.imgfile) == 0:
self.imgfile = glob.glob(os.path.join(Path, "*.jpeg"))
self.ext = "jpeg"
if len(self.imgfile) == 0:
self.imgfile = glob.glob(os.path.join(Path, "*.jpg"))
self.ext = "jpg"
self.save_path = save_path # 保存json的路径
self.class_id = label
self.coco = {}
self.path = Path
self.verify_path = verify_path
self.min_value_x = self.imageWidth
self.min_value_y = self.imageHeight
self.max_value_x = 0
self.max_value_y = 0
self.verify_labelimg = verify_labelimg_flag
self.full_img = None
self.coco_id=0;
def save_label_img(self, all_object):
m_filename = self.image[-1]['file_name']
print('m_filename=', m_filename)
m_width = self.image[-1]["width"]
print('m_width=', m_width)
m_height = self.image[-1]["height"]
print('m_height=', m_height)
object_name = os.path.splitext(m_filename)[0]
new_object_name = object_name + '.xml'
img_name = object_name + ".jpg"
print(new_object_name)
doc = Document() # 创建DOM文档对象
DOCUMENT = doc.createElement('annotation') # 创建根元素
folder = doc.createElement('folder')
folder_text = doc.createTextNode(m_filename)
folder.appendChild(folder_text)
DOCUMENT.appendChild(folder)
doc.appendChild(DOCUMENT)
filename = doc.createElement('filename')
filename_text = doc.createTextNode(m_filename)
filename.appendChild(filename_text)
DOCUMENT.appendChild(filename)
doc.appendChild(DOCUMENT)
path = doc.createElement('path')
path_text = doc.createTextNode(m_filename)
path.appendChild(path_text)
DOCUMENT.appendChild(path)
doc.appendChild(DOCUMENT)
source = doc.createElement('source')
database = doc.createElement('database')
database_text = doc.createTextNode("Unknown") # 元素内容写入
database.appendChild(database_text)
source.appendChild(database)
DOCUMENT.appendChild(source)
doc.appendChild(DOCUMENT)
size = doc.createElement('size')
width = doc.createElement('width')
width_text = doc.createTextNode(str(m_width)) # 元素内容写入
width.appendChild(width_text)
size.appendChild(width)
height = doc.createElement('height')
height_text = doc.createTextNode(str(m_height))
height.appendChild(height_text)
size.appendChild(height)
depth = doc.createElement('depth')
depth_text = doc.createTextNode(str(3))
depth.appendChild(depth_text)
size.appendChild(depth)
DOCUMENT.appendChild(size)
segmented = doc.createElement('segmented')
segmented_text = doc.createTextNode(str(0))
segmented.appendChild(segmented_text)
DOCUMENT.appendChild(segmented)
doc.appendChild(DOCUMENT)
for item in all_object:
m_xmin_0 = int(item['bbox'][0])
print('m_xmin_0=', m_xmin_0)
m_ymin_0 = int(item['bbox'][1])
print('m_ymin_0=', m_ymin_0)
m_xmax_0 = int(item['bbox'][2])
m_ymax_0 = int(item['bbox'][3])
print('m_ymax_0=', m_ymax_0)
m_name_0 = self.categories[0]["name"]
print('m_name_0=', m_name_0)
object = doc.createElement('object')
name = doc.createElement('name')
name_text = doc.createTextNode(m_name_0)
name.appendChild(name_text)
object.appendChild(name)
pose = doc.createElement('pose')
pose_text = doc.createTextNode('Unspecified')
pose.appendChild(pose_text)
object.appendChild(pose)
truncated = doc.createElement('truncated')
truncated_text = doc.createTextNode(str(0))
truncated.appendChild(truncated_text)
object.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult_text = doc.createTextNode(str(0))
difficult.appendChild(difficult_text)
object.appendChild(difficult)
bndbox = doc.createElement('bndbox')
xmin = doc.createElement('xmin')
xmin_text = doc.createTextNode(str(int(m_xmin_0)))
xmin.appendChild(xmin_text)
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin_text = doc.createTextNode(str(int(m_ymin_0)))
ymin.appendChild(ymin_text)
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax_text = doc.createTextNode(str(int(m_xmax_0)))
xmax.appendChild(xmax_text)
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax_text = doc.createTextNode(str(int(m_ymax_0)))
ymax.appendChild(ymax_text)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
DOCUMENT.appendChild(object)
new_path_filename = os.path.join(self.labelimg_path, new_object_name)
print('new_path_filename=', new_path_filename)
f = open(new_path_filename, 'w')
doc.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
def labelme_to_coco(self):
for num, json_file in enumerate(self.jsonfile):
print(json_file)
json_file = os.path.join(self.path, json_file)
full_path, json_file_name = os.path.split(json_file)
json_file_name_Noext, _ = os.path.splitext(json_file_name)
self.full_img = os.path.join(full_path, ".".join([json_file_name_Noext, self.ext]))
data = codecs.open(json_file, 'r')
data = json.load(data)
self.imageHeight, self.imageWidth = data["imageHeight"], data["imageWidth"]
_, self.imageName = os.path.split(data["imagePath"])
self.imageName_Noext, _ = os.path.splitext(self.imageName)
self.imagePath, self.imageData = data["imagePath"], None
self.image.append({"file_name": self.imageName, "width": self.imageWidth, "height": self.imageHeight,
"id": int(json_file_name_Noext)})
shapes = data["shapes"]
segmentations = list(filter(lambda x: x["shape_type"] == "polygon", shapes))
rects = list(filter(lambda x: x["shape_type"] == "rectangle", shapes))
shapes = list(filter(lambda x: x["shape_type"] == "point", shapes))
# print(len(shapes))
if self.verify_flag:
_path, _img_name = os.path.split(self.full_img)
img = cv2.imread(self.full_img)
img_f = os.path.join(self.verify_path, _img_name)
temp_annotations = []
for num_id in range(0, int(len(shapes) / self.keypoints_length)):
num_keypoints = 0
keypoints = [0] * 3 * self.keypoints_length # 这里是我们标注的关节点个数
annotation = {}
print(num_id)
self.min_value_x = self.imageWidth
self.min_value_y = self.imageHeight
self.max_value_x = 0
self.max_value_y = 0
list_shape = shapes[
num_id * self.keypoints_length:num_id * self.keypoints_length + self.keypoints_length]
# print(shapes[num_id*self.keypoints_length:num_id*self.keypoints_length+self.keypoints_length])
segmentation = []
for m_id, shape in enumerate(list_shape):
if shape["shape_type"] == "point":
idx = int(shape['label']) - self.inital_start_id
keypoints[idx * 3 + 0] = int(shape['points'][0][0])
keypoints[idx * 3 + 1] = int(shape['points'][0][1])
keypoints[idx * 3 + 2] = 2
segmentation.extend([shape['points'][0][0], shape['points'][0][1]])
num_keypoints = num_keypoints + 1
self.min_value_x = min(self.min_value_x, shape['points'][0][0])
self.min_value_y = min(self.min_value_y, shape['points'][0][1])
self.max_value_x = max(self.max_value_x, shape['points'][0][0])
self.max_value_y = max(self.max_value_y, shape['points'][0][1])
annotation['bbox'] = [self.min_value_x, self.min_value_y, self.max_value_x, self.max_value_y]
annotation['segmentation'] = [segmentation]
annotation['num_keypoints'] = num_keypoints
annotation['area'] = int(annotation['bbox'][2] - annotation['bbox'][0]) * int(
annotation['bbox'][3] - annotation['bbox'][1])
annotation['iscrowd'] = 0
annotation['keypoints'] = keypoints
if len(rects):
for inclde_item in rects:
x1 = int(min(inclde_item["points"][0][0], inclde_item["points"][1][0]))
y1 = int(min(inclde_item["points"][0][1], inclde_item["points"][1][1]))
x2 = int(max(inclde_item["points"][0][0], inclde_item["points"][1][0]))
y2 = int(max(inclde_item["points"][0][1], inclde_item["points"][1][1]))
include_num = 0
for ii in range(0, self.keypoints_length):
x, y = int(keypoints[ii * 3]), int(keypoints[ii * 3 + 1])
flag = (True if x >= x1 and x <= x2 and y >= y1 and y <= y2 else False)
if flag == True:
include_num = include_num + 1
if include_num == self.keypoints_length:
annotation['bbox'] = [x1, y1, x2, y2]
annotation['image_id'] = int(json_file_name_Noext) # 对应的图片ID
annotation['category_id'] = 0
print("num=",num_id)
annotation['id'] = self.coco_id # 对象id
self.coco_id =self.coco_id +1
self.annotations.append(annotation)
temp_annotations.append(annotation)
self.image_id = int(json_file_name_Noext)
if self.verify_flag:
for item in self.categories[0]["skeleton"]:
idx = item[0]
iddx = item[1]
start_point = (annotation['keypoints'][idx * 3 + 0], annotation['keypoints'][idx * 3 + 1])
end_point = (annotation['keypoints'][iddx * 3 + 0], annotation['keypoints'][iddx * 3 + 1])
rect_start_point = (int(annotation['bbox'][0]), int(annotation['bbox'][1]))
rect_end_point = (int(annotation['bbox'][2]), int(annotation['bbox'][3]))
cv2.rectangle(img, rect_start_point, rect_end_point, (255, 0, 255), 1)
cv2.putText(img, self.label, rect_start_point, cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
cv2.circle(img, start_point, 3, (255, 0, 0), 3)
cv2.circle(img, end_point, 3, (255, 0, 0), 3)
cv2.line(img, start_point, end_point, (0, 255, 0), 2)
cv2.putText(img, "{}".format(idx), start_point, cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 28, 0), 2)
cv2.imwrite(img_f, img)
if self.verify_labelimg:
self.save_label_img(temp_annotations)
shutil.copy(self.full_img, self.labelimg_path)
self.coco["images"] = self.image
self.coco["categories"] = self.categories
self.coco["annotations"] = self.annotations
def get_images(self, filename, height, width):
image = {}
image["height"] = height
image['width'] = width
image["id"] = self.imagePath
image["file_name"] = filename
return image
def get_categories(self, name, class_id):
category = {}
category["supercategory"] = self.class_id
category['id'] = class_id
category['name'] = name
return category
def save_coco_json(self):
self.labelme_to_coco()
coco_data = self.coco
# 保存json文件
json.dump(coco_data, open(self.save_path, 'w'), indent=4, cls=MyEncoder) # indent=4 更加美观显示
all_img_json_path = r'/home/ubuntu/Downloads/fish_data/val'
coco_path = r"/home/ubuntu/Downloads/fish_data/val.json"
labelimg_path = r"/home/ubuntu/Downloads/labelimg"
verify_path = r"/home/ubuntu/Downloads/verify"
keypoints = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
skeleton = [[0, 1], [1, 3], [3, 5], [5, 8], [8, 9], [9, 10], [10, 7], [7, 4], [4, 2], [2, 0], [5, 6], [6, 7], [6, 8],
[6, 9], [6, 10]] # 故意写的关键点和关键点骨节数不一样
supercategory = "fish"
label = "fish_tilapia"
verify_flag = False
inital_start_id = 0 # 初始下标开始序号 ,根据标注数据集来确定
verify_labelimg_flag = False
full_path, json_file_name = os.path.split(coco_path)
if not os.path.exists(full_path):
os.mkdir(full_path)
if not os.path.exists(verify_path):
os.mkdir(verify_path)
if not os.path.exists(labelimg_path):
os.mkdir(labelimg_path)
cocoData = Tococo(all_img_json_path, coco_path, labelimg_path, keypoints, skeleton, label, verify_flag, verify_path,
inital_start_id, verify_labelimg_flag, supercategory)
cocoData.save_coco_json()
print("finish")二、测试mmpose得数据集
修改配置文件一/home/ubuntu/mmpose/configs/_base_/datasets/animalpose.py
dataset_info = dict(
dataset_name='animalpose',
paper_info=dict(
author='Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and '
'Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing',
title='Cross-Domain Adaptation for Animal Pose Estimation',
container='The IEEE International Conference on '
'Computer Vision (ICCV)',
year='2019',
homepage='https://sites.google.com/view/animal-pose/',
),
keypoint_info={
0:
dict(
name='0', id=0, color=[0, 255, 0], type='upper', swap=''),
1:
dict(
name='1',
id=1,
color=[255, 128, 0],
type='upper',
swap=''),
2:
dict(
name='2',
id=2,
color=[0, 255, 0],
type='upper',
swap=''),
3:
dict(
name='3',
id=3,
color=[255, 128, 0],
type='upper',
swap=''),
4:
dict(name='4', id=4, color=[51, 153, 255], type='upper', swap=''),
5:
dict(name='5', id=5, color=[51, 153, 255], type='upper', swap=''),
6:
dict(
name='6', id=6, color=[51, 153, 255], type='lower',
swap=''),
7:
dict(
name='7', id=7, color=[51, 153, 255], type='upper', swap=''),
8:
dict(
name='8',
id=8,
color=[0, 255, 0],
type='upper',
swap=''),
9:
dict(
name='9',
id=9,
color=[255, 128, 0],
type='upper',
swap=''),
10:
dict(
name='10',
id=10,
color=[0, 255, 0],
type='lower',
swap='')
},
skeleton_info={
0: dict(link=('0', '1'), id=0, color=[51, 153, 255]),
1: dict(link=('1', '3'), id=1, color=[0, 255, 0]),
2: dict(link=('3', '5'), id=2, color=[255, 128, 0]),
3: dict(link=('5', '8'), id=3, color=[0, 255, 0]),
4: dict(link=('6', '9'), id=4, color=[255, 128, 0]),
5: dict(link=('9', '10'), id=5, color=[51, 153, 255]),
6: dict(link=('10', '7'), id=6, color=[51, 153, 255]),
7: dict(link=('7', '4'), id=7, color=[51, 153, 255]),
8: dict(link=('4', '2'), id=8, color=[0, 255, 0]),
9: dict(link=('2', '0'), id=9, color=[0, 255, 0]),
10: dict(link=('5', '6'), id=10, color=[0, 255, 0]),
11: dict(link=('6', '7'), id=11, color=[0, 255, 0]),
12: dict(link=('6', '10'), id=12, color=[0, 255, 0]),
13: dict(link=('6', '9'), id=13, color=[0, 255, 0]),
14: dict(link=('6', '8'), id=14, color=[0, 255, 0]),
15: dict(link=('8', '9'), id=11, color=[0, 255, 0]),
},
joint_weights=[
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1
],
# Note: The original paper did not provide enough information about
# the sigmas. We modified from 'https://github.com/cocodataset/'
# 'cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py#L523'
sigmas=[
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.
])
修改配置文件二/home/ubuntu/mmpose/configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py
_base_ = ['../../../_base_/default_runtime.py']
# runtime
train_cfg = dict(max_epochs=1000, val_interval=50)
# optimizer
optim_wrapper = dict(optimizer=dict(
type='Adam',
lr=5e-4,
))
# learning policy
param_scheduler = [
dict(
type='LinearLR', begin=0, end=500, start_factor=0.001,
by_epoch=False), # warm-up
dict(
type='MultiStepLR',
begin=0,
end=210,
milestones=[170, 200],
gamma=0.1,
by_epoch=True)
]
# automatically scaling LR based on the actual training batch size
auto_scale_lr = dict(base_batch_size=512)
# hooks
default_hooks = dict(checkpoint=dict(save_best='coco/AP', rule='greater'))
# codec settings
codec = dict(
type='MSRAHeatmap', input_size=(256, 256), heatmap_size=(64, 64), sigma=2)
# model settings
model = dict(
type='TopdownPoseEstimator',
data_preprocessor=dict(
type='PoseDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True),
backbone=dict(
type='HRNet',
in_channels=3,
extra=dict(
stage1=dict(
num_modules=1,
num_branches=1,
block='BOTTLENECK',
num_blocks=(4, ),
num_channels=(64, )),
stage2=dict(
num_modules=1,
num_branches=2,
block='BASIC',
num_blocks=(4, 4),
num_channels=(32, 64)),
stage3=dict(
num_modules=4,
num_branches=3,
block='BASIC',
num_blocks=(4, 4, 4),
num_channels=(32, 64, 128)),
stage4=dict(
num_modules=3,
num_branches=4,
block='BASIC',
num_blocks=(4, 4, 4, 4),
num_channels=(32, 64, 128, 256))),
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmpose/'
'pretrain_models/hrnet_w32-36af842e.pth'),
),
head=dict(
type='HeatmapHead',
in_channels=32,
out_channels=11,
deconv_out_channels=None,
loss=dict(type='KeypointMSELoss', use_target_weight=True),
decoder=codec),
test_cfg=dict(
flip_test=True,
flip_mode='heatmap',
shift_heatmap=True,
))
# base dataset settings
dataset_type = 'AnimalPoseDataset'
data_mode = 'topdown'
data_root = '/home/ubuntu/mmpose/fish_data/'
# pipelines
train_pipeline = [
dict(type='LoadImage'),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
dict(type='RandomHalfBody'),
dict(type='RandomBBoxTransform'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
val_pipeline = [
dict(type='LoadImage'),
dict(type='GetBBoxCenterScale'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='PackPoseInputs')
]
# data loaders
train_dataloader = dict(
batch_size=32,
num_workers=1,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_mode=data_mode,
ann_file='train.json',
data_prefix=dict(img='train/'),
pipeline=train_pipeline,
))
val_dataloader = dict(
batch_size=32,
num_workers=1,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_mode=data_mode,
ann_file='val.json',
data_prefix=dict(img='val/'),
test_mode=True,
pipeline=val_pipeline,
))
test_dataloader = val_dataloader
# evaluators
val_evaluator = dict(
type='CocoMetric', ann_file=data_root + 'val.json')
test_evaluator = val_evaluator
测试数据集是否正确
ubuntu@ubuntu:~/mmpose$ python3 tools/misc/browse_dataset.py /home/ubuntu/mmpose/configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py --phase val --mode original三、训练数据集
ubuntu@ubuntu:~/mmpose$ python3 tools/train.py /home/ubuntu/mmpose/configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py四、是用mmdeploy转模型
ubuntu@ubuntu:~/mmdeploy$ python3 tools/torch2onnx.py configs/mmpose/pose-detection_onnxruntime_static.py ../mmpose/configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py ../mmpose/work_dirs/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256/epoch_670.pth ../mmpose/tests/data/animalpose/ca110.jpeg
04/24 17:19:28 - mmengine - INFO - torch2onnx:
model_cfg: ../mmpose/configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py
deploy_cfg: configs/mmpose/pose-detection_onnxruntime_static.py
04/24 17:19:29 - mmengine - WARNING - Failed to search registry with scope "mmpose" in the "Codebases" registry tree. As a workaround, the current "Codebases" registry in "mmdeploy" is used to build instance. This may cause unexpected failure when running the built modules. Please check whether "mmpose" is a correct scope, or whether the registry is initialized.
04/24 17:19:29 - mmengine - WARNING - Failed to search registry with scope "mmpose" in the "mmpose_tasks" registry tree. As a workaround, the current "mmpose_tasks" registry in "mmdeploy" is used to build instance. This may cause unexpected failure when running the built modules. Please check whether "mmpose" is a correct scope, or whether the registry is initialized.
Loads checkpoint by local backend from path: ../mmpose/work_dirs/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256/epoch_670.pth
/home/ubuntu/mmpose/mmpose/datasets/datasets/utils.py:102: UserWarning: The metainfo config file "configs/_base_/datasets/animalpose.py" does not exist. A matched config file "/home/ubuntu/mmpose/mmpose/.mim/configs/_base_/datasets/animalpose.py" will be used instead.
warnings.warn(
04/24 17:19:31 - mmengine - WARNING - DeprecationWarning: get_onnx_config will be deprecated in the future.
04/24 17:19:31 - mmengine - INFO - Export PyTorch model to ONNX: ./work-dir/end2end.onnx.
04/24 17:19:31 - mmengine - WARNING - Can not find torch._C._jit_pass_onnx_autograd_function_process, function rewrite will not be applied
04/24 17:20:10 - mmengine - INFO - Execute onnx optimize passes.
04/24 17:20:10 - mmengine - WARNING - Can not optimize model, please build torchscipt extension.
More details: https://github.com/open-mmlab/mmdeploy/tree/1.x/docs/en/experimental/onnx_optimizer.md
04/24 17:20:10 - mmengine - INFO - torch2onnx finished. Results saved to ./work-dir
转ncnn
ubuntu@ubuntu:~/ncnn/build/install/bin$ ./onnx2ncnn /home/ubuntu/mmdeploy/work-dir/end2end.onnx /home/ubuntu/mmdeploy/work-dir/end2end.param /home/ubuntu/mmdeploy/work-dir/end2end.bin五、转rk3588,产生txt
ubuntu@ubuntu:~/mmpose$ find /home/ubuntu/mmpose/fish_data -name "*.jpg" > a.txt转模型
from rknn.api import RKNN
ONNX_MODEL = '/home/ubuntu/mmdeploy/work-dir/end2end.onnx'
RKNN_MODEL = '/home/ubuntu/mmdeploy/work-dir/end2end.rknn'
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]],
target_platform='rk3588',
quantized_dtype='asymmetric_quantized-8', optimization_level=3)
print('done')
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='dataset.txt') # ,pre_compile=True
if ret != 0:
print('Build end2end failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export end2end.rknn failed!')
exit(ret)
print('done')
rknn.release()cmakelists.txt
cmake_minimum_required(VERSION 3.16)
project(untitled10)
set(CMAKE_CXX_FLAGS "-std=c++11")
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ")
include_directories(${CMAKE_SOURCE_DIR})
include_directories(${CMAKE_SOURCE_DIR}/include)
find_package(OpenCV REQUIRED)
#message(STATUS ${OpenCV_INCLUDE_DIRS})
#添加头文件
include_directories(${OpenCV_INCLUDE_DIRS})
#链接Opencv库
add_library(librknn_api SHARED IMPORTED)
set_target_properties(librknn_api PROPERTIES IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib/librknn_api.so)
#官方的zoo社区或者参考前几篇博客寻找其so出处
add_executable(untitled10 main.cpp)
target_link_libraries(untitled10 ${OpenCV_LIBS} librknn_api )main.cpp
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <queue>
#include "rknn_api.h"
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <chrono>
#include <iostream>
using namespace std;
struct Keypoints {
float x;
float y;
float score;
Keypoints() : x(0), y(0), score(0) {}
Keypoints(float x, float y, float score) : x(x), y(y), score(score) {}
};
struct Box {
float center_x;
float center_y;
float scale_x;
float scale_y;
float scale_prob;
float score;
Box() : center_x(0), center_y(0), scale_x(0), scale_y(0), scale_prob(0), score(0) {}
Box(float center_x, float center_y, float scale_x, float scale_y, float scale_prob, float score) :
center_x(center_x), center_y(center_y), scale_x(scale_x), scale_y(scale_y), scale_prob(scale_prob),
score(score) {}
};
void bbox_xywh2cs(float bbox[], float aspect_ratio, float padding, float pixel_std, float *center, float *scale) {
float x = bbox[0];
float y = bbox[1];
float w = bbox[2];
float h = bbox[3];
*center = x + w * 0.5;
*(center + 1) = y + h * 0.5;
if (w > aspect_ratio * h)
h = w * 1.0 / aspect_ratio;
else if (w < aspect_ratio * h)
w = h * aspect_ratio;
*scale = (w / pixel_std) * padding;
*(scale + 1) = (h / pixel_std) * padding;
}
void rotate_point(float *pt, float angle_rad, float *rotated_pt) {
float sn = sin(angle_rad);
float cs = cos(angle_rad);
float new_x = pt[0] * cs - pt[1] * sn;
float new_y = pt[0] * sn + pt[1] * cs;
rotated_pt[0] = new_x;
rotated_pt[1] = new_y;
}
void _get_3rd_point(cv::Point2f a, cv::Point2f b, float *direction) {
float direction_0 = a.x - b.x;
float direction_1 = a.y - b.y;
direction[0] = b.x - direction_1;
direction[1] = b.y + direction_0;
}
void get_affine_transform(float *center, float *scale, float rot, float *output_size, float *shift, bool inv,
cv::Mat &trans) {
float scale_tmp[] = {0, 0};
scale_tmp[0] = scale[0] * 200.0;
scale_tmp[1] = scale[1] * 200.0;
float src_w = scale_tmp[0];
float dst_w = output_size[0];
float dst_h = output_size[1];
float rot_rad = M_PI * rot / 180;
float pt[] = {0, 0};
pt[0] = 0;
pt[1] = src_w * (-0.5);
float src_dir[] = {0, 0};
rotate_point(pt, rot_rad, src_dir);
float dst_dir[] = {0, 0};
dst_dir[0] = 0;
dst_dir[1] = dst_w * (-0.5);
cv::Point2f src[3] = {cv::Point2f(0, 0), cv::Point2f(0, 0), cv::Point2f(0, 0)};
src[0] = cv::Point2f(center[0] + scale_tmp[0] * shift[0], center[1] + scale_tmp[1] * shift[1]);
src[1] = cv::Point2f(center[0] + src_dir[0] + scale_tmp[0] * shift[0],
center[1] + src_dir[1] + scale_tmp[1] * shift[1]);
float direction_src[] = {0, 0};
_get_3rd_point(src[0], src[1], direction_src);
src[2] = cv::Point2f(direction_src[0], direction_src[1]);
cv::Point2f dst[3] = {cv::Point2f(0, 0), cv::Point2f(0, 0), cv::Point2f(0, 0)};
dst[0] = cv::Point2f(dst_w * 0.5, dst_h * 0.5);
dst[1] = cv::Point2f(dst_w * 0.5 + dst_dir[0], dst_h * 0.5 + dst_dir[1]);
float direction_dst[] = {0, 0};
_get_3rd_point(dst[0], dst[1], direction_dst);
dst[2] = cv::Point2f(direction_dst[0], direction_dst[1]);
if (inv) {
trans = cv::getAffineTransform(dst, src);
} else {
trans = cv::getAffineTransform(src, dst);
}
}
void
transform_preds(std::vector<cv::Point2f> coords, std::vector<Keypoints> &target_coords, float *center, float *scale,
int w, int h, bool use_udp = false) {
float scale_x[] = {0, 0};
float temp_scale[] = {scale[0] * 200, scale[1] * 200};
if (use_udp) {
scale_x[0] = temp_scale[0] / (w - 1);
scale_x[1] = temp_scale[1] / (h - 1);
} else {
scale_x[0] = temp_scale[0] / w;
scale_x[1] = temp_scale[1] / h;
}
for (int i = 0; i < coords.size(); i++) {
target_coords[i].x = coords[i].x * scale_x[0] + center[0] - temp_scale[0] * 0.5;
target_coords[i].y = coords[i].y * scale_x[1] + center[1] - temp_scale[1] * 0.5;
}
}
void letterbox(cv::Mat rgb, cv::Mat &img_resize, int target_width, int target_height) {
float shape_0 = rgb.rows;
float shape_1 = rgb.cols;
float new_shape_0 = target_height;
float new_shape_1 = target_width;
float r = std::min(new_shape_0 / shape_0, new_shape_1 / shape_1);
float new_unpad_0 = int(round(shape_1 * r));
float new_unpad_1 = int(round(shape_0 * r));
float dw = new_shape_1 - new_unpad_0;
float dh = new_shape_0 - new_unpad_1;
dw = dw / 2;
dh = dh / 2;
cv::Mat copy_rgb = rgb.clone();
if (int(shape_0) != int(new_unpad_0) && int(shape_1) != int(new_unpad_1)) {
cv::resize(copy_rgb, img_resize, cv::Size(new_unpad_0, new_unpad_1));
copy_rgb = img_resize;
}
int top = int(round(dh - 0.1));
int bottom = int(round(dh + 0.1));
int left = int(round(dw - 0.1));
int right = int(round(dw + 0.1));
cv::copyMakeBorder(copy_rgb, img_resize, top, bottom, left, right, cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));
}
void printRKNNTensor(rknn_tensor_attr *attr) {
printf("index=%d name=%s n_dims=%d dims=[%d %d %d %d] n_elems=%d size=%d "
"fmt=%d type=%d qnt_type=%d fl=%d zp=%d scale=%f\n",
attr->index, attr->name, attr->n_dims, attr->dims[3], attr->dims[2],
attr->dims[1], attr->dims[0], attr->n_elems, attr->size, 0, attr->type,
attr->qnt_type, attr->fl, attr->zp, attr->scale);
}
int post_process_u8(uint8_t *input0, int model_in_h, int model_in_w) {
return 0;
}
int main(int argc, char **argv) {
float keypoint_score = 0.1f;
cv::Mat bgr = cv::imread("../7.jpg");
cv::Mat rgb;
cv::cvtColor(bgr, rgb, cv::COLOR_BGR2RGB);
float image_target_w = 256;
float image_target_h = 256;
float padding = 1.25;
float pixel_std = 200;
float aspect_ratio = image_target_h / image_target_w;
float bbox[] = {516,210,516+702,210+468,
9.995332e-01};// 需要检测框架 这个矩形框来自检测框架的坐标 x y w h score 这里来自我自己标注的检测框
// bbox[2] = bbox[2] - bbox[0];
// bbox[3] = bbox[3] - bbox[1];
float center[2] = {0, 0};
float scale[2] = {0, 0};
bbox_xywh2cs(bbox, aspect_ratio, padding, pixel_std, center, scale);
float rot = 0;
float shift[] = {0, 0};
bool inv = false;
float output_size[] = {image_target_h, image_target_w};
cv::Mat trans;
get_affine_transform(center, scale, rot, output_size, shift, inv, trans);
std::cout << trans << std::endl;
cv::Mat detect_image;//= cv::Mat::zeros(image_target_w ,image_target_h, CV_8UC3);
cv::warpAffine(rgb, detect_image, trans, cv::Size(image_target_h, image_target_w), cv::INTER_LINEAR);
const char *model_path = "../end2end_3588.rknn";
// Load model
FILE *fp = fopen(model_path, "rb");
if (fp == NULL) {
printf("fopen %s fail!\n", model_path);
return -1;
}
fseek(fp, 0, SEEK_END);
int model_len = ftell(fp);
void *model = malloc(model_len);
fseek(fp, 0, SEEK_SET);
if (model_len != fread(model, 1, model_len, fp)) {
printf("fread %s fail!\n", model_path);
free(model);
return -1;
}
rknn_context ctx = 0;
int ret = rknn_init(&ctx, model, model_len, 0,NULL);
if (ret < 0) {
printf("rknn_init fail! ret=%d\n", ret);
return -1;
}
/* Query sdk version */
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version,
sizeof(rknn_sdk_version));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("sdk version: %s driver version: %s\n", version.api_version,
version.drv_version);
/* Get input,output attr */
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printf("model input num: %d, output num: %d\n", io_num.n_input,
io_num.n_output);
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]),
sizeof(rknn_tensor_attr));
if (ret < 0) {
printf("rknn_init error ret=%d\n", ret);
return -1;
}
printRKNNTensor(&(input_attrs[i]));
}
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]),
sizeof(rknn_tensor_attr));
printRKNNTensor(&(output_attrs[i]));
}
int input_channel = 3;
int input_width = 0;
int input_height = 0;
if (input_attrs[0].fmt == RKNN_TENSOR_NCHW) {
printf("model is NCHW input fmt\n");
input_width = input_attrs[0].dims[0];
input_height = input_attrs[0].dims[1];
printf("input_width=%d input_height=%d\n", input_width, input_height);
} else {
printf("model is NHWC input fmt\n");
input_width = input_attrs[0].dims[1];
input_height = input_attrs[0].dims[2];
printf("input_width=%d input_height=%d\n", input_width, input_height);
}
printf("model input height=%d, width=%d, channel=%d\n", input_height, input_width,
input_channel);
/* Init input tensor */
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].buf = detect_image.data;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].size = input_width * input_height * input_channel;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].pass_through = 0;
/* Init output tensor */
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].want_float = 1;
}
printf("img.cols: %d, img.rows: %d\n", detect_image.cols, detect_image.rows);
auto t1 = std::chrono::steady_clock::now();
rknn_inputs_set(ctx, io_num.n_input, inputs);
std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();
ret = rknn_run(ctx, NULL);
if (ret < 0) {
printf("ctx error ret=%d\n", ret);
return -1;
}
auto t2 = std::chrono::steady_clock::now();
std::chrono::duration<double> time_span = std::chrono::duration_cast<std::chrono::duration<double>>(t2 - now);
std::cout << "It took me " << time_span.count()*1000 << " ms."<<std::endl;
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
if (ret < 0) {
printf("outputs error ret=%d\n", ret);
return -1;
}
int shape_b = 0;
int shape_c = 0;
int shape_w = 0;;
int shape_h = 0;;
for (int i = 0; i < io_num.n_output; ++i) {
shape_b = output_attrs[i].dims[0];
shape_c = output_attrs[i].dims[1];
shape_h = output_attrs[i].dims[2];;
shape_w = output_attrs[i].dims[3];;
}
printf("batch=%d channel=%d width=%d height= %d\n", shape_b, shape_c, shape_w, shape_h);
std::vector<float> vec_result_heap;
float *output = (float *) outputs[0].buf;
for (int i = 0; i < shape_c; i++) {
for (int j = 0; j < shape_h; j++) {
for (int k = 0; k < shape_w; k++) {
float elements = output[i * shape_w * shape_h + j * shape_w + k];
vec_result_heap.emplace_back(elements);
}
}
}
std::vector<Keypoints> all_preds;
std::vector<int> idx;
for (int i = 0; i < shape_c; i++) {
auto begin = vec_result_heap.begin() + i * shape_w * shape_h;
auto end = vec_result_heap.begin() + (i + 1) * shape_w * shape_h;
float maxValue = *max_element(begin, end);
int maxPosition = max_element(begin, end) - begin;
all_preds.emplace_back(Keypoints(0, 0, maxValue));
idx.emplace_back(maxPosition);
}
std::vector<cv::Point2f> vec_point;
for (int i = 0; i < idx.size(); i++) {
int x = idx[i] % shape_w;
int y = idx[i] / shape_w;
vec_point.emplace_back(cv::Point2f(x, y));
}
for (int i = 0; i < shape_c; i++) {
int px = vec_point[i].x;
int py = vec_point[i].y;
if (px > 1 && px < shape_w - 1 && py > 1 && py < shape_h - 1) {
float diff_0 = vec_result_heap[py * shape_w + px + 1] - vec_result_heap[py * shape_w + px - 1];
float diff_1 = vec_result_heap[(py + 1) * shape_w + px] - vec_result_heap[(py - 1) * shape_w + px];
vec_point[i].x += diff_0 == 0 ? 0 : (diff_0 > 0) ? 0.25 : -0.25;
vec_point[i].y += diff_1 == 0 ? 0 : (diff_1 > 0) ? 0.25 : -0.25;
}
}
std::vector<Box> all_boxes;
bool heap_map = false;
if (heap_map) {
all_boxes.emplace_back(Box(center[0], center[1], scale[0], scale[1], scale[0] * scale[1] * 400, bbox[4]));
}
transform_preds(vec_point, all_preds, center, scale, shape_w, shape_h);
int skeleton[15][2] = {
{0, 1},{1, 3},{3, 5},{5, 8},
{8, 9},{9, 10},{10, 7},{7,4},{4, 2},
{2, 0},{5, 6},
{6, 7},{6, 10},{6, 8},{6, 9}};
cv::rectangle(bgr, cv::Point(bbox[0], bbox[1]), cv::Point(bbox[0] + bbox[2], bbox[1] + bbox[3]),
cv::Scalar(255, 0, 0));
for (int i = 0; i < all_preds.size(); i++) {
if (all_preds[i].score > keypoint_score) {
cv::circle(bgr, cv::Point(all_preds[i].x, all_preds[i].y), 3, cv::Scalar(0, 255, 120), -1);//画点,其实就是实心圆
}
}
for (int i = 0; i < sizeof(skeleton) / sizeof(sizeof(skeleton[1])); i++) {
int x0 = all_preds[skeleton[i][0]].x;
int y0 = all_preds[skeleton[i][0]].y;
int x1 = all_preds[skeleton[i][1]].x;
int y1 = all_preds[skeleton[i][1]].y;
cv::line(bgr, cv::Point(x0, y0), cv::Point(x1, y1),
cv::Scalar(0, 255, 0), 1);
}
cv::imwrite("../image.jpg", bgr);
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
if (ret < 0) {
printf("rknn_query fail! ret=%d\n", ret);
goto Error;
}
Error:
if (ctx > 0)
ret=rknn_destroy(ctx);
printf("%d \n",ret);
//感觉官方固件有问题,销毁对象存在问题,或许是我的固件有问题 https://t.rock-chips.com/forum.php?mod=viewthread&tid=2365
if (model)
free(model);
if (fp)
fclose(fp);
return 0;
}测试结果

附录 mp4转h264(瑞芯微用第二种)
ubuntu@ubuntu:~/aaa$ ffmpeg -i people.mp4 -codec copy -bsf: hevc_mp4toannexb -f h264 sample.h264
ubuntu@ubuntu:~/aaa$ ffmpeg -i people.mp4 -vcodec h264 people.h264
参考