参考资料:DeepWalk【图神经网络论文精读】
word2vec
相关论文:
Efficient Estimation of Word Representations in Vector Space
Distributed Representations of Words and Phrases and their Compositionality
随机游走Ramdom Walk简述
通过随机游走可以采样出一个序列。
序列好比一句话,节点好比一个单词。
随机游走的假设是类似word2vec的,假设相邻单词应该相似。于是可以构造skip-gram问题,输入中心节点,预测周围邻近节点。这样就能完全套用word2vec。
Deepwalk官方ppt介绍
https://dl.acm.org/doi/10.1145/2623330.2623732
核心思想:随机游走=句子
Deepwalk的优势
- 可扩展-在线学习算法,来了一个新数据,不需要从手开始训练。
- 可以把随机游走当成句子,直接套用NLP中的语言模型
- 在稀疏标注的图分类任务上,效果不错
语言模型
在NLP领域,有一个现象,称为“word frequency”:有一些词出现的特别频繁,有一些不频繁。
在图里,特别是无标度图网络里,也有类似的现象:“Vertex frequency”:有一些网站被访问的特别频繁,有一些不频繁。
流程
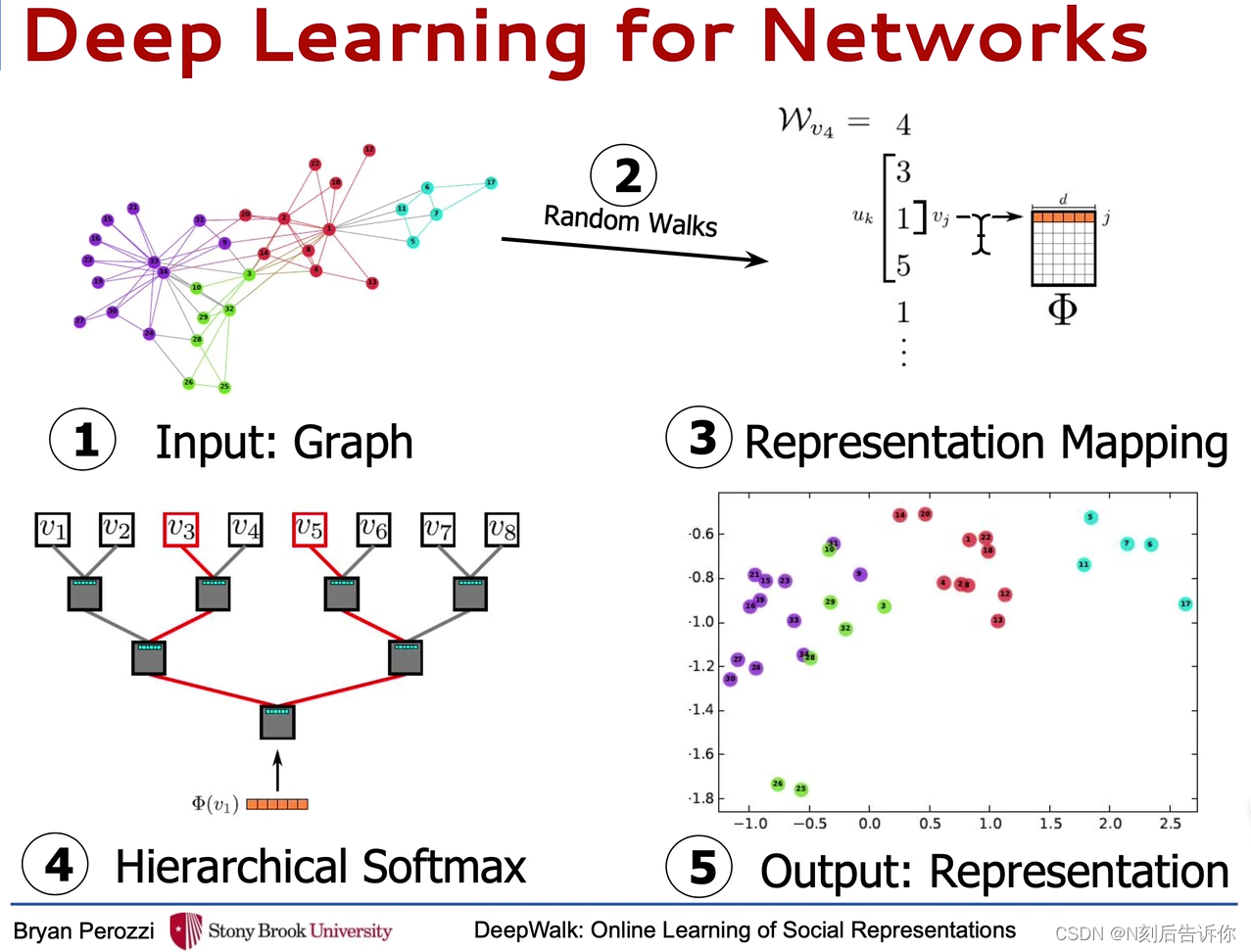
- 输入图
- 采样出随机游走序列
- 用随机游走序列训练word2vec
- 使用层次softmax
- 得到每个节点的向量表示
2.随机游走
- 每个节点产生 γ \gamma γ个随机游走序列。
- 每个随机游走的最大长度是 t t t。
- 同概率地选择节点的下一个节点
- 如: v 46 → v 45 → v 71 → v 24 → v 5 → v 1 → v 17 v_{46} \rightarrow v_{45} \rightarrow v_{71} \rightarrow v_{24} \rightarrow v_5 \rightarrow v_1 \rightarrow v_{17} v46→v45→v71→v24→v5→v1→v17
3.用随机游走序列构造skip-gram任务,训练word2vec
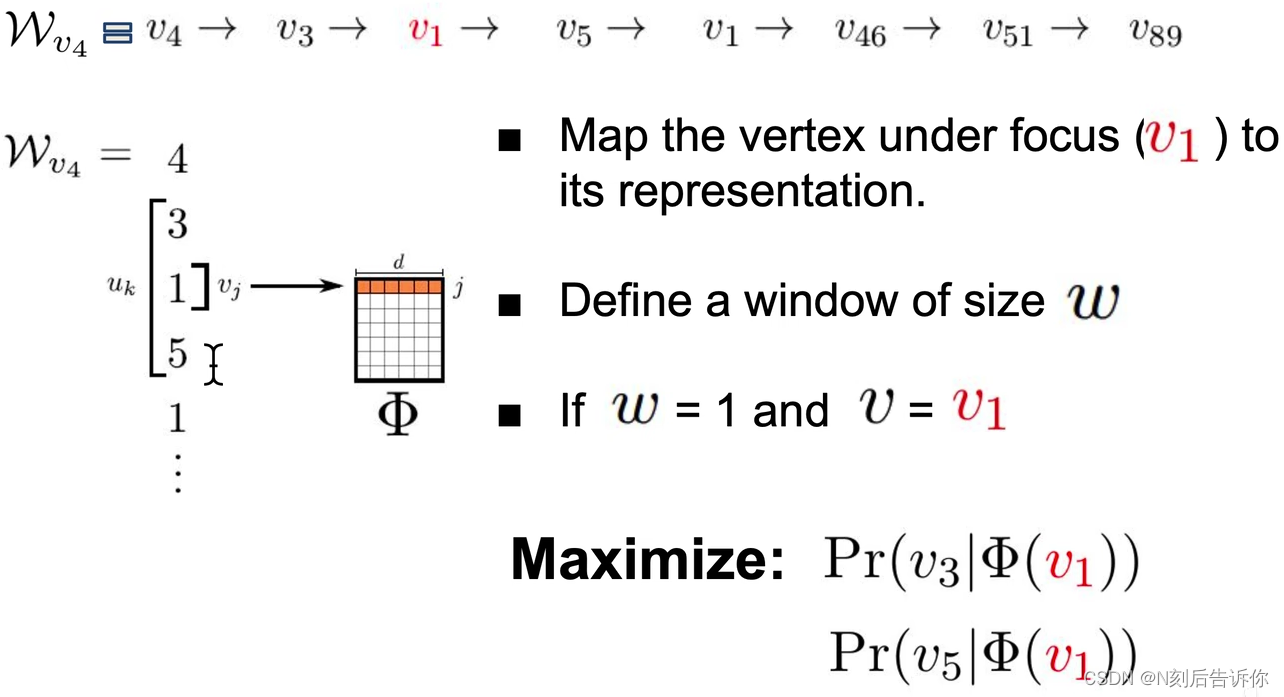
4.使用层次softmax
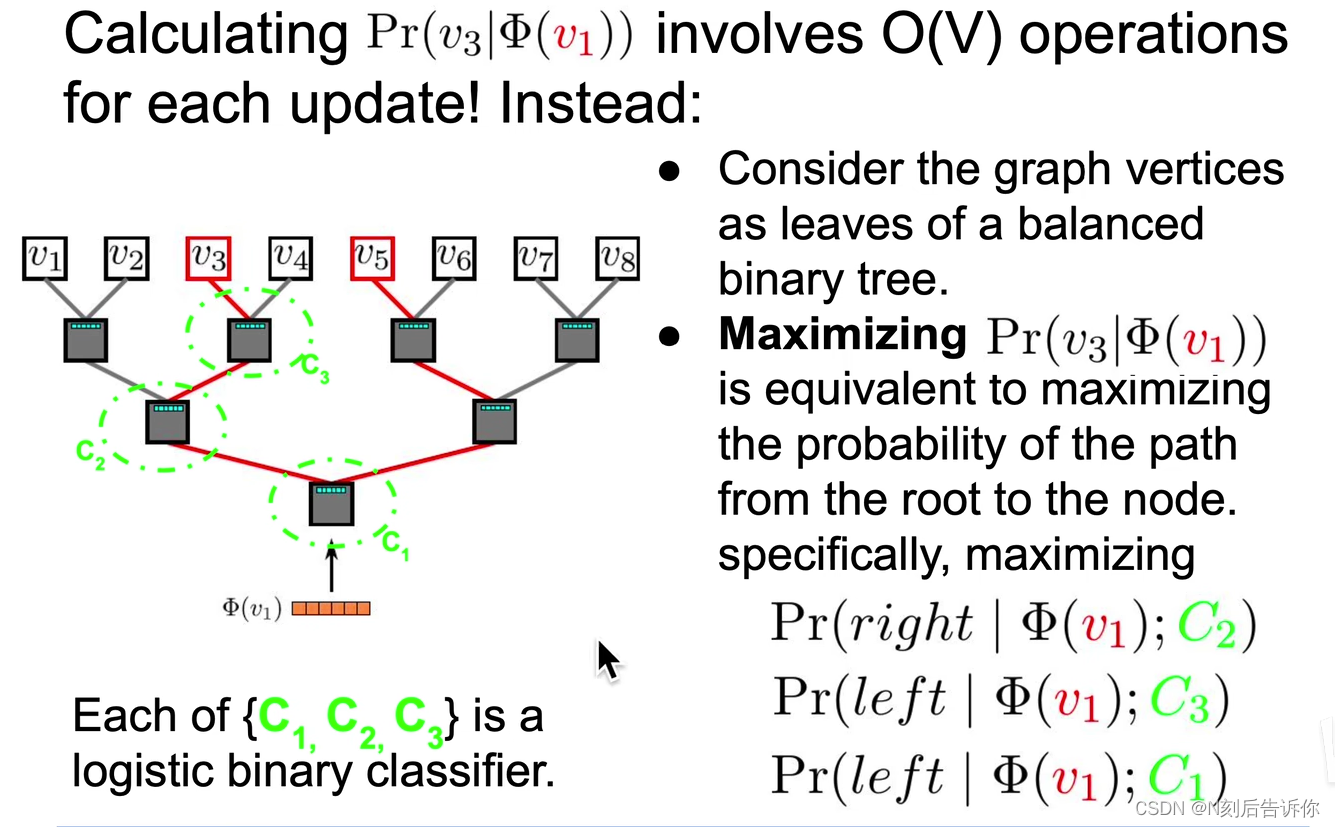
学习参数:节点表示、分类器的权重
使用随机梯度下降,同时优化
评估
属性预测(节点分类问题)
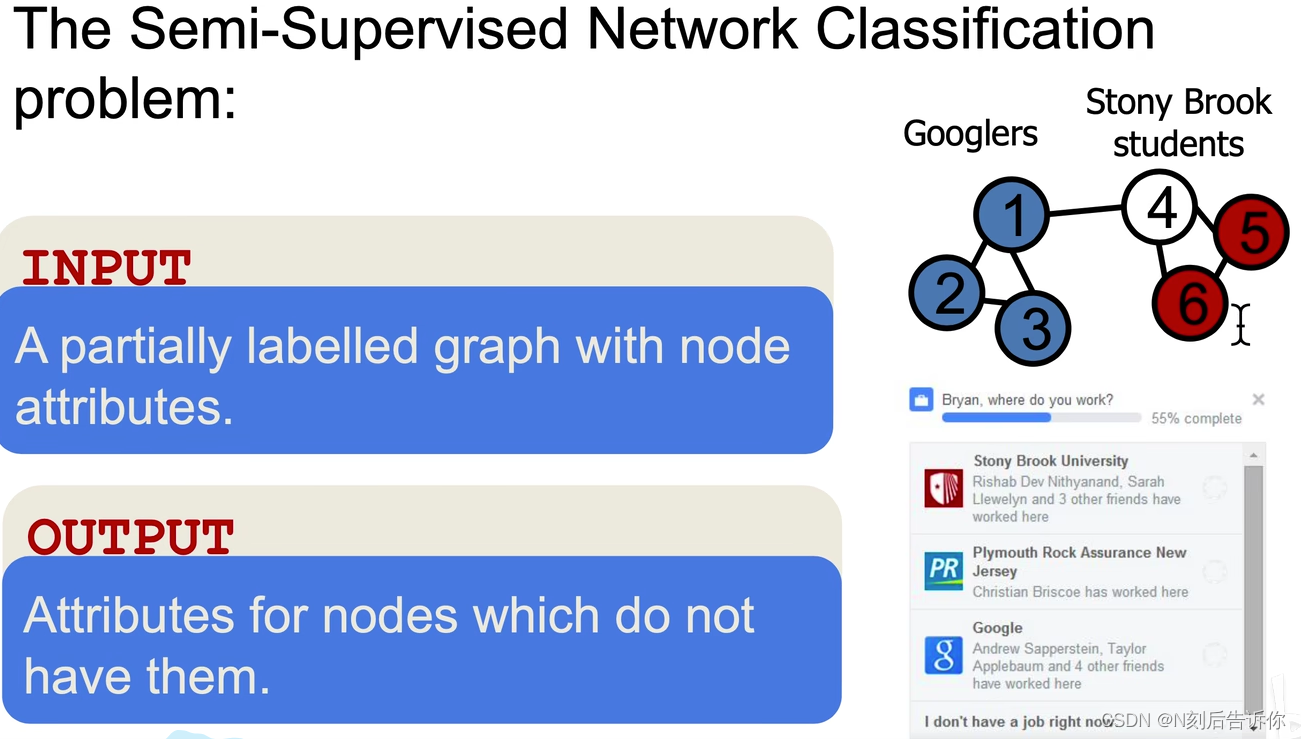
这是一个稀疏标注的问题。将Deepwalk和spectralclustering,edgecluster,modularity,wvRN比较。
- BlogCatalog

- Flicker
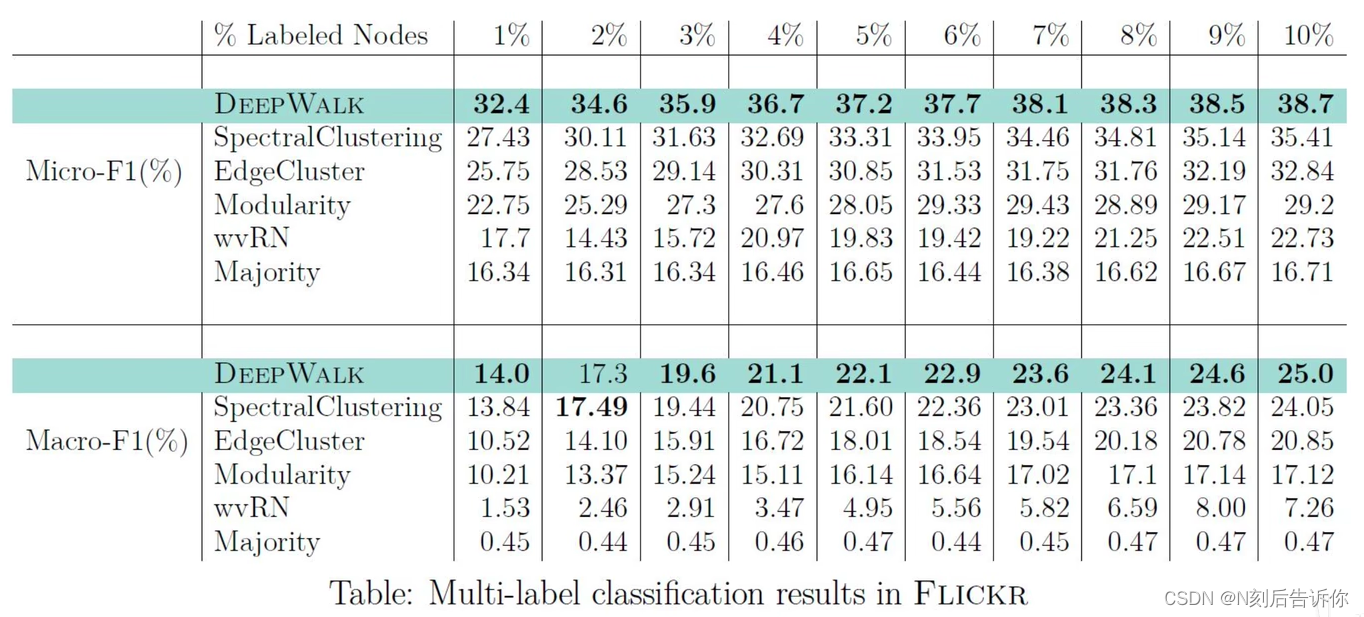
deepwalk表现非常好,特别是在标签非常少的情况下。
可并行
并行不影响表示质量。
展望
- Streaming:不需要整个图的信息。动态更新。
- “不随机”游走:可以携带一定的倾向性。
- 图和语言,相辅相成,两个领域的突破可以互相借鉴。

论文精读
数据集:空手道俱乐部
问题定义
G = ( V , E ) G=(V,E) G=(V,E)
G L = ( V , E , X , Y ) G_L=(V,E,X,Y) GL=(V,E,X,Y)
X ∈ R ∣ V ∣ × S X \in \mathbb{R}^{|V| \times S} X∈R∣V∣×S:每个节点有S维特征
Y ∈ R ∣ V ∣ × ∣ Y ∣ Y \in \mathbb{R}^{|V| \times|\mathcal{Y}|} Y∈R∣V∣×∣Y∣:每个节点有 Y \mathcal{Y} Y个标签
任务:relational classification(不满足独立同分布假设)
目标:学到 X E ∈ R r ∣ V ∣ × d X_E \in \mathbb{R}_r^{|V| \times d} XE∈Rr∣V∣×d:d是词嵌入后的维度
反映连接信息的embedding+反映节点本身的特征=>机器学习分类(欺诈检测)
希望学到的特性
- 适应性:在线学习算法
- 反映社群聚类信息:原图中相近的节点,嵌入后依然接近
- 低维数:防止过拟合
- 连续:方便拟合出平滑的决策边界
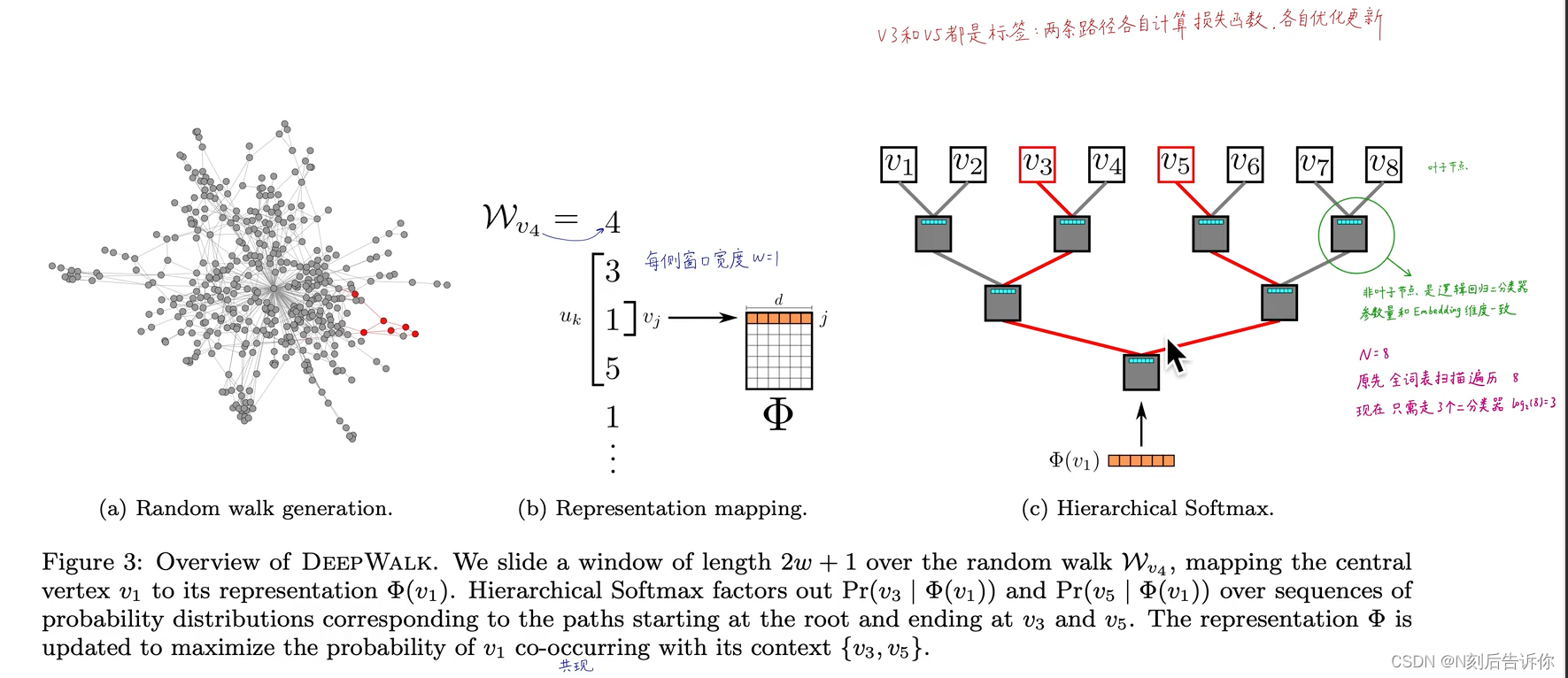
3.1 随机游走
起点: v i v_i vi
随机游走: W v i \mathcal{W}_{v_i} Wvi: W v i 1 , W v i 2 , … , W v i k \mathcal{W}_{v_i}^1, \mathcal{W}_{v_i}^2, \ldots, \mathcal{W}_{v_i}^{k} Wvi1,Wvi2,…,Wvik:右上角表示第k步
随机游走已经被用于内容推荐、社群检测,作为相似性测量的方法。
随机游走也是一些output sensitive算法的基石(至少要遍历一遍全图)。
随机游走的优点:
1.并行采样生成随机游走序列
2.在线学习:当网络有新节点、新关系时候,不需要把全图信息重新计算,只需把跟新节点、新关系采样出来,迭代在线增量训练即可。
3.2幂律分布(Power laws)
-
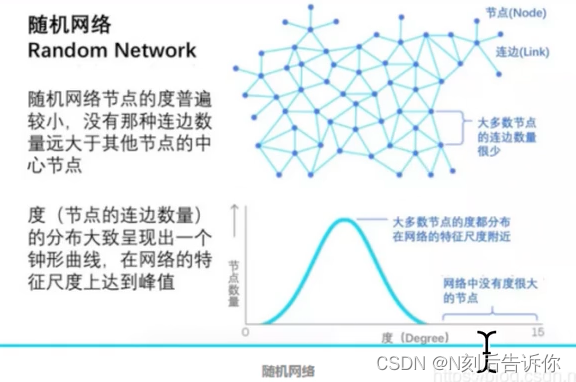
随机网络
如果是随机网络,那么节点的度普遍偏小,没有某些节点度远大于其他节点
度的分布大致呈现出正态曲线。
-
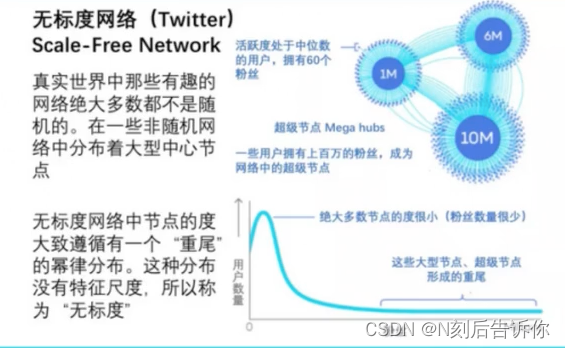
无标度网络(Scale-free network)
-
Zipf定律
一个单词的词频与词频排序名次的常数次幂成反比。即只有极少数的词(节点)被经常使用。
3.3 语言模型
语言模型的目标是估计一个特定序列的词出现的似然概率。更正式地:
给定一个词序列 W 1 n = ( w 0 , w 1 , ⋯ , w n ) W_1^n=\left(w_0, w_1, \cdots, w_n\right) W1n=(w0,w1,⋯,wn),希望最大化概率:
Pr ( w n ∣ w 0 , w 1 , ⋯ , w n − 1 ) \operatorname{Pr}\left(w_n \mid w_0, w_1, \cdots, w_{n-1}\right) Pr(wn∣w0,w1,⋯,wn−1)
即已知前 n n n个词,预测第 n + 1 n+1 n+1个词的概率。
论文用前 i − 1 i-1 i−1个节点,预测第 n n n个节点。
引入 Φ : v ∈ V ↦ R ∣ V ∣ × d \Phi:v \in V \mapsto \mathbb{R}^{|V| \times d} Φ:v∈V↦R∣V∣×d映射,通过查表,将节点映射到向量。
于是问题转化为(用前i-1个节点的embedding预测第i个节点):
Pr ( v i ∣ ( Φ ( v 1 ) , Φ ( v 2 ) , ⋯ , Φ ( v i − 1 ) ) ) \operatorname{Pr}\left(v_i \mid\left(\Phi\left(v_1\right), \Phi\left(v_2\right), \cdots, \Phi\left(v_{i-1}\right)\right)\right) Pr(vi∣(Φ(v1),Φ(v2),⋯,Φ(vi−1)))
但是将它转化为条件概率,会越乘越小,导致游走到很远的时候,概率变很小。
参考word2vec
word2vec是自监督模型,且周围词的顺序无关。
skip-gram的损失函数: minimize Φ − log Pr ( { v i − w , ⋯ , v i + w } \ v i ∣ Φ ( v i ) ) \underset{\Phi}{\operatorname{minimize}}\ \ -\log \operatorname{Pr}\left(\left\{v_{i-w}, \cdots, v_{i+w}\right\} \backslash v_i| \Phi\left(v_i\right)\right) Φminimize −logPr({ vi−w,⋯,vi+w}\vi∣Φ(vi))
随机游走生成的图,顺序本就没有意义。
模型较小,一次输入一个节点,预测周围节点。
4.方法
4.2 算法:deepwalk
算法分为两部分:
1.随机游走生成器
2.更新步骤
- deepwalk伪代码

- skipgram伪代码

可以设置随机游走序列在走一定路之后传送回起始节点的概率,但预实验的结果是没有明显影响。
4.2.1 skipgram

4.2.2 分层softmax
原来直接做softmax,计算配分函数(partition function)太昂贵。
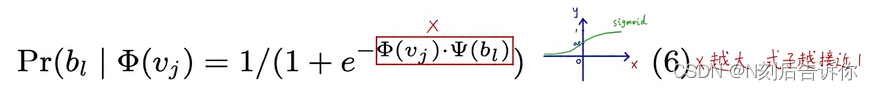
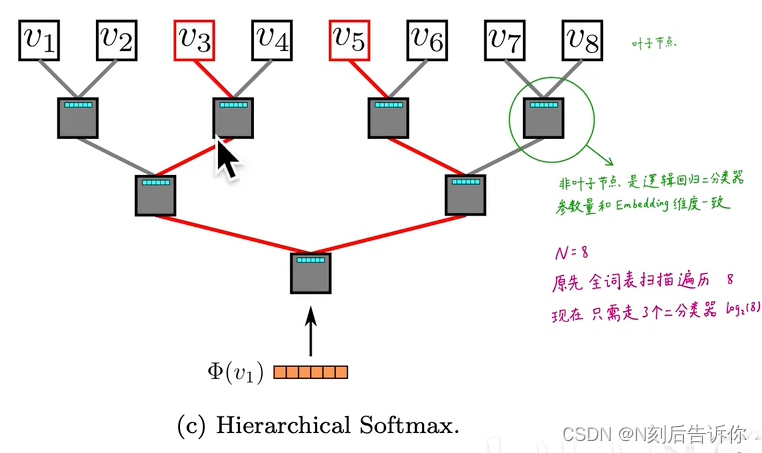
所以,deepwalk是要训练两套权重:
1.词嵌入矩阵
2.N-1个逻辑回归的权重,(N个叶子节点有N-1个逻辑回归)
- 整体流程图
4.2.3 优化
参数是上面提到的两套权重,大小是 O ( d ∣ V ∣ ) O(d|V|) O(d∣V∣)
4.3 多线程异步并行
4.4 算法变种
4.4.1 streaming
保证学习率不变,且较小。
4.4.2 不随机的游走
用户交互往往有偏向。这样不仅可以考虑到连接的存在性,还可以考虑到连接的权重。句子事实上也可以看作是有偏向的采样序列。
5.实验设计
数据集:
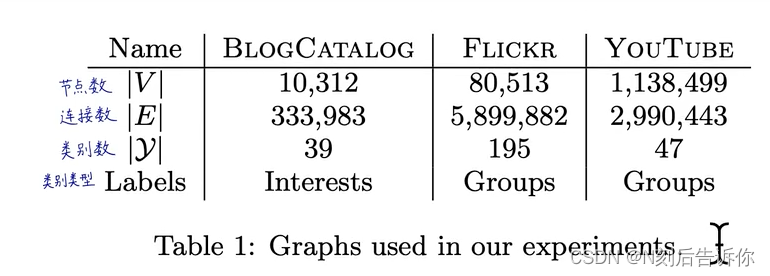
5.2 对比算法

6.实验
6.1 多类别节点分类
T R T_R TR:标注节点的比例
评估指标: M a c r o − F 1 Macro-F1 Macro−F1(每一类F1取平均)和 M i c r o − F 1 Micro-F1 Micro−F1(总体的TP、FN、FP、TN计算总体的F1)
这里用one-vs-rest逻辑回归实现分类器。
关于one-vs-rest可以参考资料
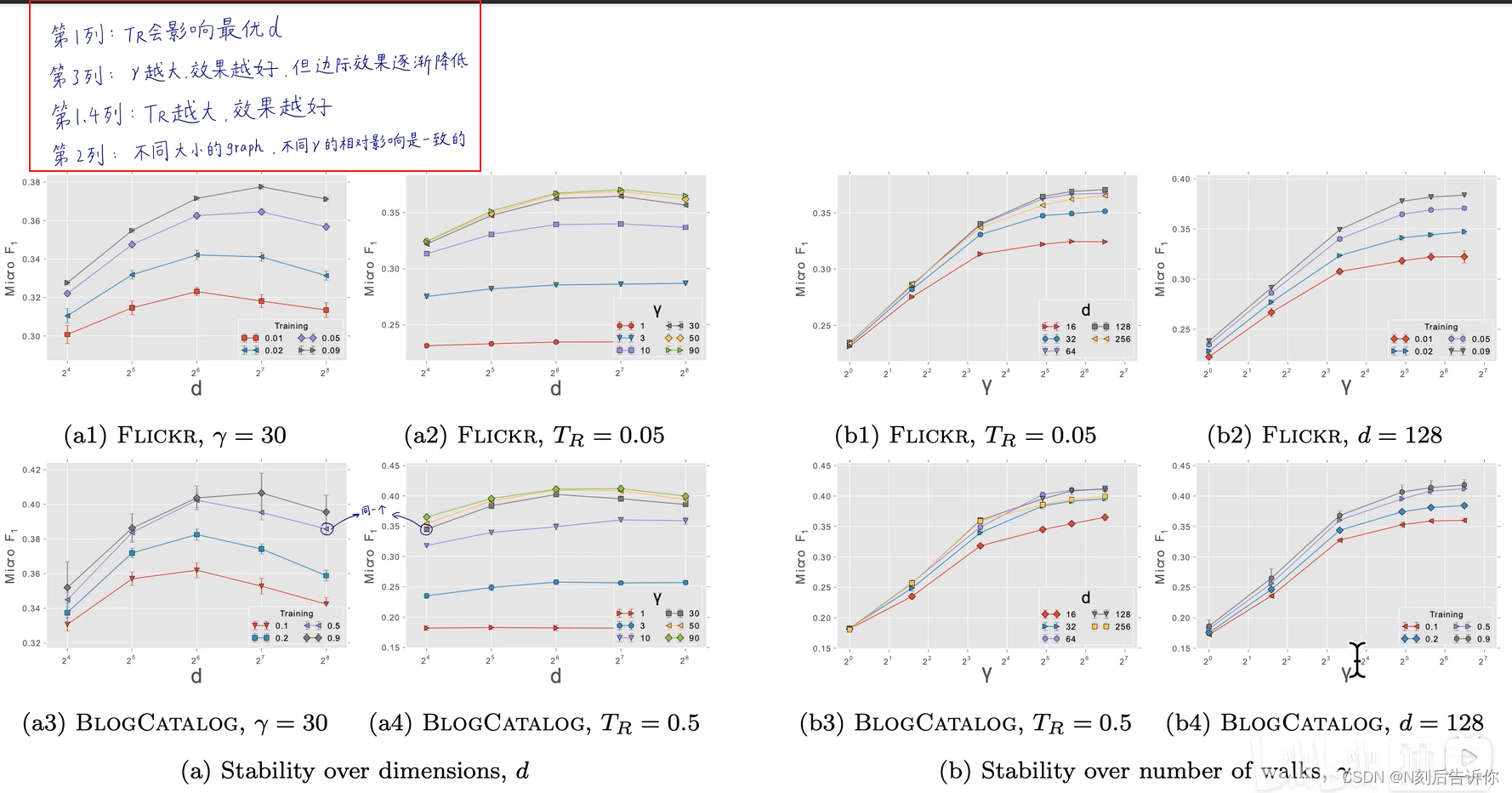
下面展示了效果。
图中展示的结果:
1. T R T_R TR会影响最优的维度d, T R T_R TR越大,最优的d也越大
2. γ \gamma γ越大,效果越好,但存在边际
3. T R T_R TR越大,效果越好
4.不同大小的图,不同 γ \gamma γ的相对影响是一致的
7.相关工作
1.embedding通过自监督(无监督)学习得到的。
2.只考虑graph中的连接信息。后续可以用embedding和标注训练有监督的分类模型。
3.在线学习。