1. 嵌入式开发为什么学习c++
(1)c++在嵌入式开发中的地位及应用领域
①上层应用软件(Java、object、php、Python)等均是以c++为基础;
②中间框架(运行库)(sqlite3、OpenGL、opencv、TensorFlow、caffer框架)均是以c++为基础;
③系统:Linux、Android等内核均是以c++为基础;
④底层:ARM等人工智能芯片(FPGA)均是以c++为基础;
(2)学习c++的意义
①提高C语言的编程能力;
②从面向过程的开发思路转换为面向对象的开发思路,有助于系统架构的设计搭建;
③有助于快速学习其他语言;
(3)c++的就业方向
①应用软件:桌面软件开发、游戏开发;
②服务器方向:主要是游戏开发服务器及效率稳定性强的服务器;
③图像处理方向(人工智能);
2. c++概述
(1)c++之父:本尼贾.斯特劳斯特鲁普,丹麦;
(2)c++语言标准
①c++98:正式确定了c++基本形态,引入了标准库,但是缺乏现代编程语言的特性,没有收录散列表;
②c++11/14:语法方面:增加了范围循环,匿名函数、自动类型推导;标准库方面:增加了散装容器、元组、随机数、多线程、智能指针、函数适配器、正则表达式;开始向编译器编程靠拢;
③c++17:语法方面:增强了编译期间计算的支持,静态断言等,新增了许多模板元函数;标准库方面:增加了并行计算、字符串视图、文件系统库、特殊容器;
④c++20:语法方面新增了用于替代#include的模块(modules),同步非阻塞的协程、模板元编程(concept);标准库方面:新增了bit/span/ranges/format/semaphore等库;
(3)c++编程范式
①面向过程:把任务分解成若干了小任务,按照顺序自顶而下编写程序,遇到什么问题就编写什么样的任务函数,核心思想是顺序执行语句、函数;
②面向对象,核心思想是“封装”、“抽象”,把任务分解为一些“高内聚、低耦合”的对象,对象之间相互通信和协作完成任务;三大特点是封装(提高代码的维护性)、继承(提高代码的复用性)、多态(提高代码的扩展性);
③基于对象、面向对象:初期均是基于对象(把类当成结构体封装数据、继承多态等高级特性用的比较少,对象彼此之间互动较少);后期提高为面向对象(强调统一用对象建模,大量应用设计模式,对象之间关系复杂,整个过程都是基于对象之间的相互通信协作完成任务);
④泛型编程:核心思想“一切皆为类型”,使用模板而不是继承的方式复用代码,运行小路高,代码整洁;
⑤模板元编程:核心思想“类型运算”,操作的数据时编译时可见的“类型”,只能编译执行,而不能被运行时的CPU运行;
⑥函数式编程:核心思想“一切皆可调用”,“函数式”并不是c++里写成函数的被调函数,而是数学意义上、无副作用的函数,具有代表性的是lambda表达式;
(4)c++编码风格
①命名规范:“缓存失效和命名是计算机科学两大难题”;类名称用大写字母开头,其他采用下划线连接的方式命名;
②源码组织和管理:传统方式、现代编程;传统方式是源代码和头文件分开,现代编程是两者整合;
3. c++对c的加强
(1)命名空间:为了避免大型软件开发过程中多名程序员各自的程序中出现变量或函数的命名冲突;命名空间将全局作用域分成不同的部分,不同命名空间的标识符可以同名而不会发生冲突,命名空间可以相互嵌套,全局作用域也叫做默认命名空间;
(2)输入和输出流
①c++的I/O发生在流中,流就是字节序列;
②头文件
| <iostream> | 该文件定义了cin(标准输入流)、cout(标准输出流)、cerr(非缓冲标准错误流)、clog对象(缓冲标准错误流); |
| <iomaniop> | 该文件通过所谓的参数化的流操纵器(比如setw和setpresision),来声明对执行标准化I/O有用的服务; |
| <fstream> | 该文件为用户控制的文件处理声明服务; |
四种标准流:
①标准输出流cout : cout是一个预定义的对象,是iostream类的一个实例;
②标准输入流cin : cin是一个预定义对象,是iostream类的一个实例;
③标准错误流cerr : cree是iostream类的一个实例,是非缓冲的且每个流插入到cerr中都会立即输出;
④标准日志流clog :clog是iostream类的一个实例,是无缓冲的;
(3)register关键字的升级
register关键字的作用是请求编译器将局部变量存储在寄存器中,避免了CPU多次从内存中访问该数据的时间,从而提高了程序运行效率,在C语言中无法对register变量取地址,但是在c++中若要对register变量取地址,则系统将该变量转化为普通变量,从而可以取地址;
(4)新增了bool类型,c++在C语言的基本类型基础上新增了bool类型,true代表1,false代表0;一般bool类型占用一个字节;
(5)对三目运算符的加强
①C语言在三目运算符中返回的是变量的值,c++中返回的是变量本身;
②所以C语言的三目运算符不可以作为左值使用,但是c++的返回值则可以;
#include <iostream>
using namespace std;
int main(int argc, char **argv)
{
int a = 10;
int b = 20;
(a > b ? a : b) = 90; //c++返回的是变量本身,所以b = 90;
*(a > b ? &a : &b) = 90; //也可以操作地址;
return 0;
}(6)新增了一种定义别名的方式,C语言中只有typedef,c++新增了using:
using func_t = void(*)(int, int);(7) 引用
①引用是变量的别名,定义初始化的时候必须绑定一个对象,且一旦绑定不可更改;
②主要用于传参和返回值;避免了指针复杂的语法;其中在做返回值时,其引用的变量可以作为左值被再次赋值,而C语言中则不可以;
int &l_num = num;(8) 引用与指针的区别?
①定义方面:引用主要用来优化在使用指针过程中,需要取地址(&)、取值(*)等复杂的操作(主要是解决传参使用中的问题);引用既可以使用变量值也可以直接修改变量的值;引用变量和原变量的地址一样;
②效率方面:引用通过别名直接访问内存空间,效率较高;指针还需要通过地址间接访问内存空间;
③安全性:引用因为不操作地址,不会造成内存泄漏;而指针操作不当则会造成内存泄漏;
④内存空间大小:引用生成的变量其大小与被引用的变量类型一样大小,指针大小为8字节,存在空间占用过大的问题(int类型为4字节,引用变量为4字节,但指针类型为8字节);
⑤初始化:引用要初始化,且一旦定义将无法再次引用;指针可以不初始化;
(9) 指针与数组的区别?
①空间分配方式:数组是静态分配方式;指针是动态分配内存空间的方式,且分配效率更高;
②访问效率:数组是通过数组名直接访问内存空间;指针是通过地址间接地访问内存空间;
③安全性:数组容易出现越界的问题;指针需要避免出现野指针,且指针用完要及时释放,避免出现野指针;
④使用场景:数组是地址常量,引用元素的形式是转换为指针形式进行;指针是被赋予变量的地址;
(10) malloc/free 和new/delete的区别?
①malloc/free是C语言库里的函数,new/delete是c++中的运算符;
②malloc是以字节为单位分配地址空间;new是以类型所占空间大小为单位分配地址空间;
③new分配空间是可以对变量初始化,而malloc则不可以;
(11)函数调用的过程
①通过函数名找到函数入口地址;
②给形参分配空间(传值进来);
③将实参的值赋给形参;
④执行函数语句;
⑤函数返回,交回控制权;
(12) cv属性
㈠ const关键字
①原理:编译器看到const定义,就会对该变量进行优化,把所有const常量出现的地方都替代成原始值;
②当修饰指针时,能够确保指向的数据不被修改;
③当修饰引用时,则不能够通过引用去修改绑定值;
㈡ volatile关键字
①利用volatile修饰的关键字,将禁止编译器进行任何形式的优化,每次使用时都必须老老实实的到对应的内存去取值,确保值的准确性;示例如下:
#include <iostream>
using namespace std;
int main(int argc, char **argv)
{
//const volatile int MAX_LEN = 1024;
const int MAX_LEN = 1024;
int *p = const_cast<int *>(&MAX_LEN);
*p = 2048;
cout<<"MAX_LEN = " << MAX_LEN << endl;
cout<<"*p = " << *p << endl;
return 0;
}运行结果: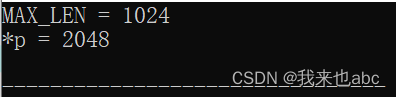
可以看出,未经过volatile修饰的MAX_LEN变量,被const修饰后,系统在输出时不再取内存中查看,虽然中间通过*p = 2048修改了它的值,但是系统依然按照编译器优化的结果输出(即在编译期,系统将MAX_LEN优化为常量);而按照*p方式输出时,系统依然会访问内存,此时输出的便是修改过的值2048;
若将第一行启用,注释第二行将采用volatile修饰MAX_LEN变量,此时每一次输出都将老老实实的访问对应内存输出,而不会在编译期优化;
#include <iostream>
using namespace std;
int main(int argc, char **argv)
{
const volatile int MAX_LEN = 1024;
//const int MAX_LEN = 1024;
int *p = const_cast<int *>(&MAX_LEN);
*p = 2048;
cout<<"MAX_LEN = " << MAX_LEN << endl;
cout<<"*p = " << *p << endl;
return 0;
}运行结果为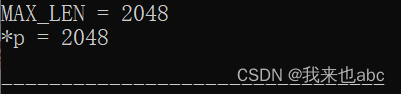
(13) 常量表达式值constexpr
① c++优化的思路:尽可能的将运行阶段的处理工作转移到编译阶段,提高程序执行效率;
② 引入constexpr的原因是const修饰的变量不能确保在编译器全部替换完成(尤其涉及到函数返回值时,一般都放到运行阶段优化);示例如下:
const int max_len = 1024;
int num = max_len; //编译器阶段优化
int get_num(int num)
{
return num * num;
}
const int max_len = get_num(10);
int num = max_len; //运行阶段常量化③ 如果利用constexpr修饰指针,那么将无法修改这个指针的指向,但是指向的值是可以更改的;
④ constexpr函数就是该函数的形参必须是常量,或者函数无参,返回的是常量,示例如下:
constexpr int new_sz() {return 42;}
cosntexpr int foo = new_sz(); ⑤ 因为constexpr函数约束的太多,c++20引入了consteval关键字,利用consteval修饰的函数,可以确保函数在编译期就执行计算,对于无法在编译器执行计算的情况就报错;
(14)动态分配内存(new、delete)——示例如下:
int *p1 = new int;
int *p2 = new int(5); //进行了初始化
int *p3 = new int[5]; //定义了一个数组
int *p4 = new int[5]{1,2,3,4,5}; //对数组进行了初始化(15)类型推导(后续博文有更详细的介绍)
① 作用:高效开发,提高函数的可读性;
② 关键字一auto,语法:auto temp = int i = 7;
③ 关键字decltype,decltype关键字是利用给定变变量或表达式的类型,来声明对应的变量为对应的类型;语法: decltype(i)temp,与auto的位置正好相反,这里将temp推导为整型;
4. c++对c的函数扩展
(1)内联函数:使用inline申请该函数成为内联函数,由编译器决定和执行;作用是在函数规模很小的情况下,函数调用的时间开销可能相当于甚至执行函数本身的时间,把它定义为内联函数,可以大大减少程序运行时间;
限制:①内联函数不可含有循环;②内联函数不可含有静态变量;③内联函数不可含有递归函数;④内联函数不可含有错误处理;
一般只将规模很小的(一般5个语句以下)且使用频繁的函数,声明为内联函数;示例如下:
#include <iostream>
using namespace std;
inline void func() //内联函数的定义就是直接在函数定义前面加上关键字inline即可;
{
int a = 3;
cout<<"a = "<< a <<endl;
}
int main()
{
int i = 0;
func();
return 0;
}(2)默认参数
①c++中可以在函数声明时为部分参数或全部提供一个默认值;当函数调用时,没有指定这个参数的值,编译器会自动用默认值代替;若函数声明和函数定义分开,则在函数声明时提供默认参数即可,在下面的函数定义则不需要再次指定;
②一旦在一个函数参数的列表中使用默认参数,则这个参数后面的所有参数都必须使用默认参数,示例如下:
#include<iostream>
using namespace std;
int add(int a, int b = 1, int c = 1)
{
return a+b+c;
}
int main(int argc, char **argv)
{
int a = 2;
int b = 2;
int c = 2;
cout<<add(1)<<endl;
return 0;
}(3)函数占位参数
占位参数的作用是允许你给一个参数设置一个参数而不去使用它,当你想要去修改函数定义的时候,可以不用再去一个个修改所有调用该函数的地方(就比如原来这个参数在方法中是被使用过的,但是后来不用了);如果你说为什么不直接在函数方法中删除所有使用该参数的地方呢?原因是如果这样的话,编译器就会发出警告,说该函数定义了该参数但是没有使用它;示例如下,将占位参数与默认值结合使用:
#include <iostream>
using namesapce std;
int func(int a, int b, int = 0) //如果这里不采用默认值,int=0,那么像func2(1, 2)这样的函数调用就会报错,因为缺失了第三个参数;
{
return a + b;
}
int main()
{
//如果默认参数和占位参数在一起,都能调用起来
cout<< func2(1, 2) <<endl;
cout<< func2(1, 2, 3) <<endl;
return 0;
}(4)函数重载
①函数重载就是用同一个函数名,但是参数的个数、类型、顺序不同,这样在主函数里调用该函数,虽然使用的是同一个函数名,系统会根据实参的不同自动匹配适配的函数;
②重载函数在本质上是相互独立的不同函数,在编译期间,系统会根据形参的不同将函数生成不同的函数名;
5. 对struct结构的升级(c++中别称class类)
(1)C语言中的不可以在结构体中定义函数,只可以有函数指针,而c++优化为可以放函数,也可以放其他成员(称为属性);
(2)C语言中不可以直接结构体名称定义变量,每一次都要加上struct,即struct Student stu;而c++则可以直接利用类型名定义变量,即Student stu;
(3)C语言中的结构体无权限设置,只要是该类型的变量就可以直接访问内部的成员;而c++升级了权限设置,分为三种公有(public)、保护(protect)、私有(private),类型的变量要访问私有成员,需要通过提前设置的接口;
(4)引入了this指针,用以区别类内的成员属性与成员函数的形参;
(5)C语言中的结构体大小与每个成员的大小相关,在字节对齐的原则下求个成员大小的成员;c++中的函数被所有类型变量共享;
(6)名称统一,在c++中结构体称为类;结构体变量称为对象;结构体内的变量,称为类的属性;结构体内的函数,称为成员函数或类的方法;
6. string类的引入,是对字符串的升级,是一个强大的字符串处理库,属于c++STL库的一部分,详见后面的博文STL;
7. vector类的引入,是对数组的升级,是一个强大的数组处理库,属于c++STL库的一部分,详见后面的博文STL;
8. 类型转换
(1)static_cast<T>(expr) :应用于①相关类型转化;②派生类转基类;③void*指针与其他类型指针之间的转换;
(2)const_cast<T>(expr) :应用于①去除指针和引用的const属性,上面介绍 volatile关键字时的例子中就使用了该转换运算符;②使用该运算符转换就意味着代码设计存在缺陷;
(3)dynamic_cast<T>(expr) :用在类型继承中的向下类型转换(基类转派生类),场景一般是运行时状态检查,用来判断基类指针调用了哪一个派生类的方法;
(4)reinterpret_cast<T>(expr) :应用于任意不同类型之间指针的转换,缺点是不安全,在编译期进行类型转换时,不检查安全性,完全由程序员决定;