点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
项目地址:https://github.com/Alwaysssssss/nndeploy
介绍
nndeploy是一款最新上线的支持多平台、高性能、简单易用的机器学习部署框架,一套实现可在多端(云、边、端)完成模型的高性能部署。
作为一个多平台模型部署工具,我们的框架最大的宗旨就是高性能以及简单贴心(^‹^),目前nndeploy已完成TensorRT、OpenVINO、ONNXRuntime、MNN、TNN、NCNN六个业界知名的推理框架的继承,后续会继续接入tf-lite、paddle-lite、coreML、TVM、AITemplate,在我们的框架下可使用一套代码轻松切换不同的推理后端进行推理,且不用担心部署框架对推理框架的抽象而带来的性能损失。
如果你需要部署自己的模型,目前nndeploy可帮助你在一个文件(大概只要200行代码)完成模型在多端的部署。nndeploy提供了高性能的前后处理模板和推理模板,上述模板可帮助你简化端到端的部署流程。如果只需使用已有主流模型进行自己的推理,目前nndeploy已完成YOLO系列等多个开源模型的部署,可供直接使用,目前我们还在积极部署其它开源模型。(如果你或团队有需要部署的开源模型或者其他部署相关的问题,非常欢迎随时来和我们探讨(^-^))
模型部署的痛点
现在业界尚不存在各方面都远超其同类产品的推理框架,不同推理框架在不同平台,硬件下分别具有各自的优势。例如,在Linux以及nVidia显卡配置下,TensorRT是性能最好的推理框架;在Windows以及x86配置下,OpenVINO时性能最好的推理框架;在Android以及ARM配置下,有ncnn、MNN、TFLite、TNN等一系列选择。
不同的推理框架有不一样的推理接口、推理配置、tensor等api,针对不同推理框架都需要写一套代码,这对模型部署工程师而言,将带来较大学习成本、开发成本、维护成本
模型部署不仅仅只有模型推理,还有前处理、后处理,推理框架往往只提供模型推理的功能,nndeploy提供了端到端的高性能的模型部署方案
目前很多场景是需要由多个模型组合解决该业务问题(例如stable diffusion、老照片修复、人脸识别等等),直接采用推理框架的原生接口,会有大量且低效的业务代码编写。nndeploy提供一种全新的解决方案(有向无环图 + 线程池 + 内存池),可以高性能且高效的解决多模型部署的痛点问题
架构简介
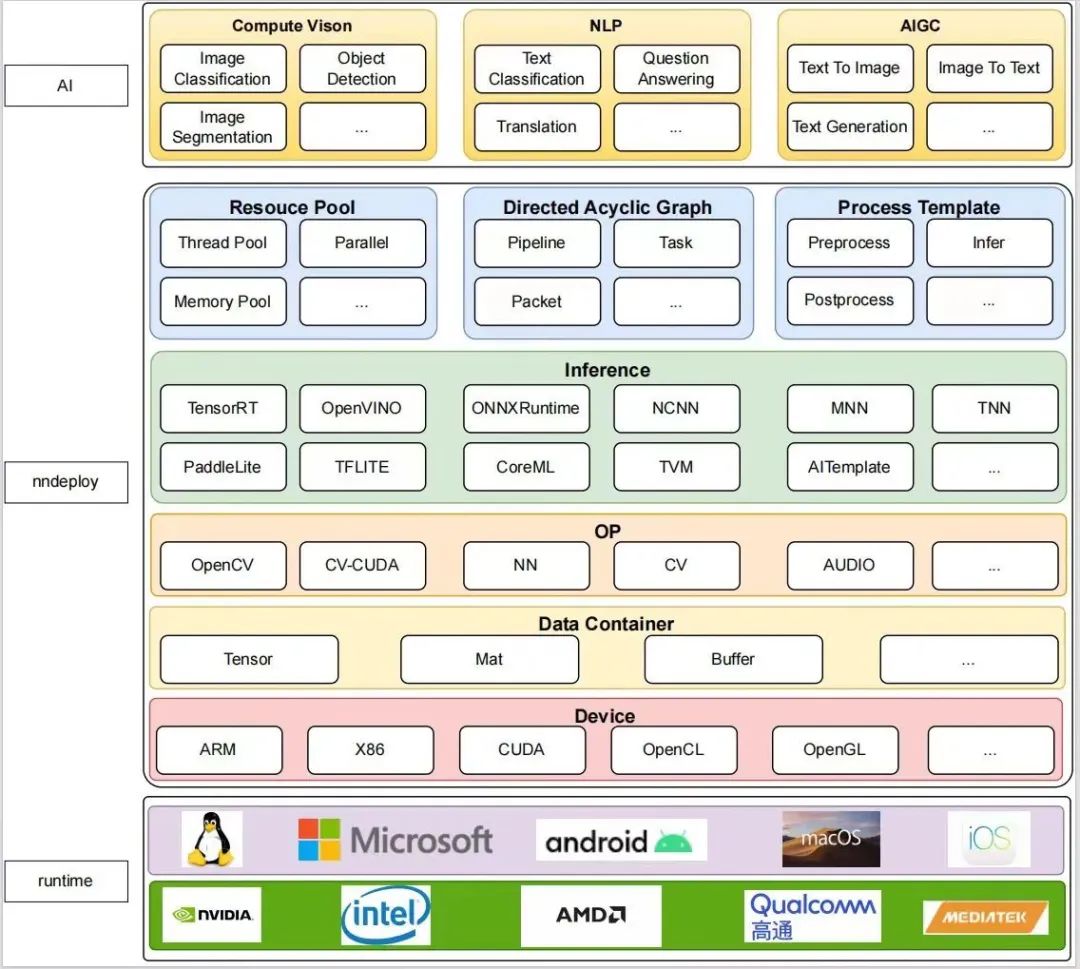
nndeploy的优势
支持多平台和多推理框架
多种推理框架接入:对多个业界知名推理框架的全面支持,包括 TensorRT、OpenVINO、ONNXRuntime、MNN、TNN、NCNN 等。未来,我们将继续扩展支持,包括 tf-lite、paddle-lite、coreML、TVM、AITemplate、RKNN等
nndeploy支持多种不同操作系统,包括Android、Linux、Windows,正在适配macOS、iOS。可帮助各种操作系统上无缝运行您的深度学习模型
| OS/Inference | Linux | Windows | Android | MacOS | iOS |
|---|---|---|---|---|---|
| TensorRT | yes | no | no | no | no |
| OpenVINO | yes | yes | no | no | no |
| ONNXRuntime | yes | yes | no | no | no |
| MNN | yes | yes | yes | no | no |
| TNN | yes | yes | yes | no | no |
| ncnn | no | no | yes | no | no |
直接可用的算法
目前已完成YOLOV5、YOLOV6、YOLOV8等一系列模型部署,可供你直接使用,后续我们持续不断去部署其它开源模型,让你开箱即用
| 算法 | Inference |
|---|---|
| YOLOV5 | TensorRt/OpenVINO/ONNXRuntime/MNN |
| YOLOV6 | TensorRt/OpenVINO/ONNXRuntime |
| YOLOV8 | TensorRt/OpenVINO/ONNXRuntime/MNN |
简单易用
一套代码多端部署:通过切换推理配置,一套代码即可在多端部署,算法的使用接口简单易用。示例代码如下
int main(int argc, char *argv[]) { // 有向无环图pipeline名称,例如: // NNDEPLOY_YOLOV5/NNDEPLOY_YOLOV6/NNDEPLOY_YOLOV8 std::string name = demo::getName(); // 推理后端类型,例如: // kInferenceTypeOpenVino / kInferenceTypeTensorRt / kInferenceTypeOnnxRuntime base::InferenceType inference_type = demo::getInferenceType(); // 推理设备类型,例如: // kDeviceTypeCodeX86:0/kDeviceTypeCodeCuda:0/... base::DeviceType device_type = demo::getDeviceType(); // 模型类型,例如: // kModelTypeOnnx/kModelTypeMnn/... base::ModelType model_type = demo::getModelType(); // 模型是否是路径 bool is_path = demo::isPath(); // 模型路径或者模型字符串 std::vector<std::string> model_value = demo::getModelValue(); // 有向无环图pipeline的输入边packert model::Packet input("detect_in"); // 有向无环图pipeline的输出边packert model::Packet output("detect_out"); // 创建模型有向无环图pipeline model::Pipeline *pipeline = model::createPipeline(name, inference_type, device_type, &input, &output, model_type, is_path, model_value); // 初始化有向无环图pipeline base::Status status = pipeline->init(); // 输入图片 cv::Mat input_mat = cv::imread(input_path); // 将图片写入有向无环图pipeline输入边 input.set(input_mat); // 定义有向无环图pipeline的输出结果 model::DetectResult result; // 将输出结果写入有向无环图pipeline输出边 output.set(result); // 有向无环图Pipeline运行 status = pipeline->run(); // 有向无环图pipelinez反初始化 status = pipeline->deinit(); // 有向无环图pipeline销毁 delete pipeline; return 0; }算法部署简单:将AI算法端到端(前处理->推理->后处理)的部署抽象为有向无环图Pipeline,前处理为一个任务Task,推理也为一个任务Task,后处理也为一个任务Task,提供了高性能的前后处理模板和推理模板,上述模板可帮助你进一步简化端到端的部署流程。有向无环图还可以高性能且高效的解决多模型部署的痛点问题。示例代码如下
model::Pipeline* createYoloV5Pipeline(const std::string& name, base::InferenceType inference_type, base::DeviceType device_type, Packet* input, Packet* output, base::ModelType model_type, bool is_path, std::vector<std::string>& model_value) { model::Pipeline* pipeline = new model::Pipeline(name, input, output); // 有向无环图 model::Packet* infer_input = pipeline->createPacket("infer_input"); // 推理模板的输入边 model::Packet* infer_output = pipeline->createPacket("infer_output"); // 推理模板的输出 // 搭建有向无图(preprocess->infer->postprocess) // 模型前处理模板model::CvtColrResize,输入边为input,输出边为infer_input model::Task* pre = pipeline->createTask<model::CvtColrResize>( "preprocess", input, infer_input); // 模型推理模板model::Infer(通用模板),输入边为infer_input,输出边为infer_output model::Task* infer = pipeline->createInfer<model::Infer>( "infer", inference_type, infer_input, infer_output); // 模型后处理模板YoloPostProcess,输入边为infer_output,输出边为output model::Task* post = pipeline->createTask<YoloPostProcess>( "postprocess", infer_output, output); // 模型前处理任务pre的参数配置 model::CvtclorResizeParam* pre_param = dynamic_cast<model::CvtclorResizeParam*>(pre->getParam()); pre_param->src_pixel_type_ = base::kPixelTypeBGR; pre_param->dst_pixel_type_ = base::kPixelTypeRGB; pre_param->interp_type_ = base::kInterpTypeLinear; pre_param->h_ = 640; pre_param->w_ = 640; // 模型推理任务infer的参数配置 inference::InferenceParam* inference_param = (inference::InferenceParam*)(infer->getParam()); inference_param->is_path_ = is_path; inference_param->model_value_ = model_value; inference_param->device_type_ = device_type; // 模型后处理任务post的参数配置 YoloPostParam* post_param = dynamic_cast<YoloPostParam*>(post->getParam()); post_param->score_threshold_ = 0.5; post_param->nms_threshold_ = 0.45; post_param->num_classes_ = 80; post_param->model_h_ = 640; post_param->model_w_ = 640; post_param->version_ = 5; return pipeline; }
高性能
推理框架的高性能抽象:每个推理框架也都有其各自的特性,需要足够尊重以及理解这些推理框架,才能在抽象中不丢失推理框架的特性,并做到统一的使用的体验。nndeploy可配置第三方推理框架绝大部分参数,保证了推理性能。可直接操作理框架内部分配的输入输出,实现前后处理的零拷贝,提升模型部署端到端的性能。
线程池正在开发完善中,可实现有向无环图的流水线并行
内存池正在开发完善中,可实现高效的内存分配与释放
一组高性能的算子正在开发中,完成后将加速你模型前后处理速度

nndeploy架构详解
Directed Acyclic Graph:有向无环图子模块。模型端到端的部署为模型前处理->模型推理->模型推理,这是一个非常典型的有向无环图,对于多模型组合的算法而言,是更加复杂的的有向无环图,直接写业务代码去串联整个过程不仅容易出错,而且还效率低下,采用有向无环图的方式可以极大的缩减业务代码的编写。
Process Template:前后处理模板以及推理子模板。我们希望还再可以简化你的部署流程,因此在模型端到端的部署的模型前处理->模型推理->模型推理的三个过程中,我们进一步设计模板。尤其是在推理模板上面花了足够多的心思,针对不同的模型,又有很多差异性,例如单输入、多输出、静态形状输入、动态形状输入、静态形状输出、动态形状输出、是否可操作推理框架内部分配输入输出等等一系列不同,只有具备丰富模型部署经验的工程师才能快速解决上述问题,故我们基于多端推理模块Inference+有向无环图节点Task再设计功能强大的推理模板Infer,这个推理模板可以帮你在内部处理上述针对模型的不同带来的差异。
Resouce Pool:资源管理子模块。正在开发线程池以及内存池(这块是nndeploy正在火热开发的模块,期待大佬一起来搞事情)。线程池可实现有向无环图的流水线并行,内存池可实现高效的内存分配与释放。
Inference:多端推理子模块(nndeploy还需要集成更多的推理框架,期待大佬一起来搞事情)。提供统一的推理接口去操作不同的推理后端,在封装每个推理框架时,我们都花了大量时间去理解并研究各个推理框架的特性,例如TensorRT可以使用外存推理,OpenVINO有高吞吐率模式、TNN可以操作内部分配输入输出等等。我们在抽象中不丢失推理框架的特性,并做到统一的使用的体验,还保证了性能。
OP:高性能算子模块。我们打算去开发一套高性能的前后处理算子(期待有大佬一起来搞事情),提升模型端到端的性能,也打算开发一套nn算子库或者去封装oneDNN、QNN等算子库(说不定在nndeploy里面还会做一个推理框架呀)
Data Container:数据容器子模块。推理框架的封装不仅推理接口的API的封装,还需要设计一个Tensor,用于去与第三方推理框架的Tensor进行数据交互。nndeploy还设计图像处理的数据容器Mat,并设计多设备的统一内存Buffer。
Device:设备管理子模块。为不同的设备提供统一的内存分配、内存拷贝、执行流管理等操作。
未来计划
接入更多的推理框架,包括TFLite、coreML、TVM、AITemplate、RKNN、算能等等推理软件栈
部署更多的算法,包括Stable Diffusion、DETR、Segment Anything等等热门开源模型
加入我们
欢迎大家参与,一起打造最简单易用、高性能的机器学习部署框架
微信:titian5566 (可加我微信进nndeploy交流群,备注:nndeploy)
微信群:nndeploy表情包交流群
本文作者:
02200059Z:https://github.com/02200059Z
qixuxiang:https://github.com/qixuxiang
Always:https://github.com/Alwaysssssss
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
