一、决策树
简介
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
ID3算法原理
ID3算法是决策树的代表,具有描述简单,分类快等特点,大多算法在此基础上进行改进。ID3算法的基本思想如下:
(1)任选取某一个属性作为决策树的根结点,对该属性所有取值创建树的分支。
(2)用这棵树对训练集进行分类,若某一叶结点所有实例都属于同一类,则以该类为标记标识此叶结点;若所有叶结点都有类标记,则算法终止;
(3)否则,选取一个从该叶结点到根路径中没有出现过的属性为标记,标识该结点,在对该属性所有取值继续创建树的分支,重复步骤(2)。
至于如何选择合适的叶结点,ID3算法是以树上的每个信息增益作为度量选取叶结点的。其中选择最高信息增益的属性作为当前节点,该属性能使得结果划分中样本分类所需信息量最小,也就是对某一对象分类所需的期望测试数目达到最小,也能找到一个简单的决策树。
接下来分别介绍期望信息量、熵、信息增益
期望信息量:
集合S是n个样本,假定分类属性(即最后一列)有m个不同值,定义m个不同类Ci(i=1,2,…,m),si是类Ci中的样本数。对给定的样本分类的期望信息:

其中pi是样本属于类Ci的概率,可用si/S估计,因此S中样本要具有代表性。
熵:
属性A(样本除了分类属性的其他属性)具有v个不同取值{a1,a2,…,av}。可以用属性A把S划分为v个子集{S1,…,Sv},其中Sj包含S中在属性A上取值aj的样本。以属性A作测试属性,那么属性A的v个取值对应v个分支。设sij是样本子集Sj中类Ci(分类属性)的样本数。则属性A划分样本子集的熵确定为:
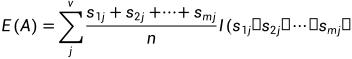
其中 表示子集中的样本个数除以S中的样本总数,即第j个子集的权。如果熵值越小,样本子集划分的纯度就越高。给定样本子集Sj的期望信息:
表示子集中的样本个数除以S中的样本总数,即第j个子集的权。如果熵值越小,样本子集划分的纯度就越高。给定样本子集Sj的期望信息:

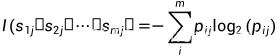
通俗的来讲,该期望信息是在属性A取某值下,分类属性的期望信息量。
信息增益:
在上面的基础上,A作为分支属性的信息增益为:

gain(A)表示的是属性A的值而导致熵的期望压缩。其中熵越大表示系统越混乱,否则反之。
ID3算法执行流程
通俗的来讲,ID3算法是分别计算除了分类属性外的属性的信息增益,找到信息增益最大的属性作为当前结点,并以该属性的取值作出分支,若同一分支下的样本属于同一类,则该分支往下不在分支,并取一个叶结点;若不属于同一类,则继续以该分支下的样本以剩余的属性继续计算信息增益,直到分支下属于同一类或者没有样本了。
二、ID3算法举例
关于ID3算法有很多典型的例子,接下来分别用python和C++实现不同的例子。
基于python代码实现
(1)数据预处理
利用python实现西瓜数据集的案例,将样本实例数据存入文本文件,放在相应的工作目录之中。数据如下:
编号,色泽,根蒂,敲声,纹理,脐部,触感,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,是