实验类型:RDD转换DataFrame
实验要求:
给定三组学生数据,要求从这三组数据中统计所有信息并且最后输出成绩前十名学生。输出结果格式为:排名,班级,学号,成绩。
操作步骤:
1、打开idea软件,创建文件步骤:File —>New —>Project—>Maven—>scala3–>main–>sql,后续只需要跟着提示走就可以了。注:(在做这个实验之前如果你的电脑没有安装scala插件的要在idea中安装Scala插件,步骤为:File —>Settings—>Plugins—>输入Scala—>Apply)。
2、在刚创建的main文件中创建三组学生数据,格式为(.txt)格式,我创建的数据如下:
3、添加Spark SQL依赖:在pom.xml 文件中添加Spark SQL依赖,代码段如下
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
注:可以添加最近几版的spark-sql 版本,我的这个实验是以前做过的,实验依赖版本是以前的。
数据文件:
1、class1.txt文件数据:
1,1001,50,2018001
2,1002,60,2018001
3,1003,70,2018001
4,1004,20,2018001
5,1005,80,2018001
6,1006,66,2018001
7,1007,99,2018001
2、class2.txt 文件数据:
1,2001,55,2018002
2,2002,56,2018002
3,2003,88,2018002
4,2004,60,2018002
5,2005,78,2018002
6,2006,62,2018002
3、class3.txt 文件数据:
1,3001,99,2018003
2,3002,84,2018003
3,3003,59,2018003
4,3004,71,2018003
5,3005,69,2018003
6,3006,100,2018003
创建好数据之后,我们就可以开始实验了,实验代码如下。
实验代码块:
import io.netty.handler.codec.smtp.SmtpRequests.data
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{
DataFrame, Row, SparkSession}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.dense_rank
import org.apache.spark.sql.functions._
case class student(班级:Int,学号:Int,成绩:Int)
object sql {
def main(args:Array[String]):Unit= {
val spark: SparkSession = SparkSession.builder()
.appName("test1")
.master("local[2]")
.getOrCreate()
val sc : SparkContext =spark.sparkContext
sc.setLogLevel("WARN")
val data1:RDD[Array[String]]=
sc.textFile("src/main/class1.txt").map(x=>x.split(","))
val data2:RDD[Array[String]]=
sc.textFile("src/main/class2.txt").map(x=>x.split(","))
val data3:RDD[Array[String]]=
sc.textFile("src/main/class3.txt").map(x => x.split(","))
val data = data1.union(data2).union(data3)
val studentRDD:RDD[student]=
data.map(x => student(x(3).toInt, x(1).toInt, x(2).toInt))
import spark.implicits._
val select=data1.union(data2).union(data3)
val studentDF:DataFrame=studentRDD.toDF("班级","学号","成绩")
//studentDF.sort(studentDF("成绩").desc).show(10)
val windowSpec= Window.partitionBy().orderBy(col("成绩") desc)
val xinliebiao=studentDF.withColumn("排名",row_number()
.over( Window.partitionBy().orderBy(col("成绩") desc)))
.select("排名","班级","学号","成绩")
//.where("rank<=10")
.show(10)
sc.stop()
spark.stop()
}}
在上述一些重要代码解释:
1、开始实验导入相应的包,并且定义样例类:case class student(班级:Int,学号:Int,成绩:Int)
2、import spark.implicits._的作用是支持将RDD转换成DataFrame
3、desc作用降序,col表示列,orderBy表示排序
4、partition by 是在保留全部数据的基础上,只对其中某些字段做分组排序
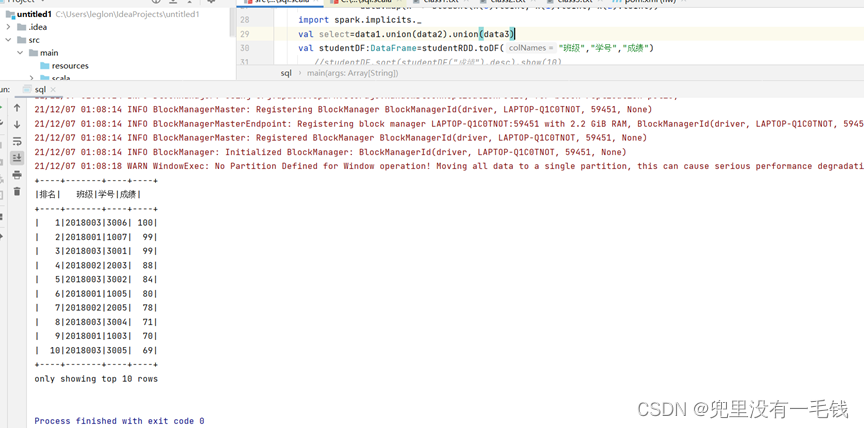
实验结果截图:
从图中我们可以看出统计并且输出了成绩前十名的学生。