基础概念
模块:一组相关功能的代码,就是一个单独的.py文件
包:一个文件夹,由几个模块或几个子包组成。目录下一般有一个__init__.py文件【python3.3以后非必须】
库:完成一定功能的代码集合,具体表现为可以是一个包或模块
框架:解决一个问题而设计的具有一定约束性的支撑结构。通过一个框架可以快速的实现一个问题的骨架,然后再具体填充。
包和模块的作用
1.编写一些“轮子”,工具代码供其它模块使用;方便维护管理。
2.防止同一模块内命名重复的问题(每个模块都是一个单独的命名空间)
分类
【1】标准包/模块<内置模块>:安装python时自动安装,可直接调用,如os 、sys等模块。
【2】三方包/模块:一些开发人员开发的模块供他人使用。需额外下载才能使用,如torch、tensorflow等。
【3】自定义包/模块:自己写的模块,如果发布出去供别人使用,就变成第三方包/模块。
创建方式
- 创建模块:创建一个.py文件即可
- 创建包:创建一个文件夹,里面包含一个__init__.py文件【python3.3后非必须,但建议创建】;当导入包时会先执行__init__.py文件
- 创建多级包:在包里面创建另外一个包,可以无限嵌套
导入方式【重点】
import语句用来导入其他python文件(称为模块module),使用该模块里定义的类、方法或者变量,从而达到代码复用的目的。
导入语法—常规导入
import M ----- 导入单个模块;如果时某个包里的模块,可以通过点语法进行定位【包.模块】
import M1, M2 ----- 导入多个模块用逗号分割
import M1 as *** ---- 给模块起别名,简化访问前缀,增强代码的扩展性
注意:使用时需要指明资源的模块名称 xxx_modelu.run()
import cv2
import numpy as np
cv2.line(img, (lf_x, pos, color, thickness)
result = np.concatenate((result_1,result_2),1)
如果导入的是一个包,默认情况下是不会导入任何模块的,解决方案有两种:
1.在__init__.py文件中,再次导入所需的模块【导入包是会执行该文件】
2.用from ** import **的形式导入
导入语法—from语句导入
作用:导入模块/包中的一部分
语法: from A import B 【as C】
- 规则:导入只能从大的地方到小的地方,即:包>模块>资源
- 组合:从包导入模块,从模块导入资源<不能跳跃导入>
- 面向关系:包里面只能看到模块,看不到模块资源
举个栗子:
-- P1[包1]
------sub_P[子包1]
----------- __init__.py [子包1下的init文件]
----------- sub.py [子包1下的模块]
------ __init__.py [包1下的init文件]
------ Tool1.py [包1下的模块]
------ Tool2.py [包1下的模块]
from P1 import Tool1 as t1 #正确
from P1.sub_P import sub #正确
from P1 import sub_P.sub #错误 面向关系:不能调用导入,包中看不到模块资源
特例:
from 模块 import * 导入模块中所有资源
from 包 import *
配合 __ all __ = ["…字符串名称…","…"]使用,自动导入列表中的东西,告诉调用者该模块/包中,哪些是有用的。* 代表列表中每一个字符串元素。
如果单独使用,代表将所有非下划线开头的资源导入到该位置
慎用 * 因为无法预知到时会导入哪些内容,容易发生变量名冲突
模块搜索路径
a. sys.modules中查找【预先导入的所有模块的缓存】
b. 内置模块列表进行搜索【和Python一起预先安装的,Python标准库】
c. sys.path中查找,sys.path是一个有序列表,其搜索顺序如下:
- 当前目录 【当前执行文件所在的文件夹,与你在哪个路径下执行代码无关】:比如你的程序放在/home/zhangsan/test.py, 在运行这个程序的时候,这个程序的sys.path列表的第一个路径就是/home/zhangsan
- 环境变量PYTHON PATH中指定的搜索路径列表
- 特定路径下的.pth文件中包含的文件路径列表:在需要大量添加外部路径的时候推荐使用,而且是永久生效。启动Python程序时候,解释器就会遍历目录,遇到pth就会读取这个文件中的内容并添加到sys.path中
- python安装路径下的Lib库中搜索【虚拟环境中的第三方包路径】
追加路径的方式
1.直接修改sys.path:既然sys.path是一个列表,那么我们就可以在列表中添加相应的路径,使用insert、append可以追加路径。这种是动态添加的,作用范围仅仅是当前py文件,不适应于多个文件同时引入的情况.
2.修改环境变量:PYTHON PATH【变量值即为路径】,仅在shell中有效
3.添加.pth文件:一般存放在lib site_package下面,文件中存放相应的路径
import sys
sys.path.append('./') #在哪个路径运行脚本/代码,就将该路径添加到sys.path中
sys.path.append('****')
查看当前包含哪些路径
print(sys.path)
查看当前已经加载的模块
print(sys.modules)
绝对导入
1>.关键看搜索路径中能否找到对应的模块。按照模块的搜索路径去寻找【主要是在sys.path中寻找】,如果没有找到就会报错;在实际工程中一般会将工程的根目录添加到sys.path中,后续绝对导入都是在这个目录的基础上进行。
2>.导入时注意面对关系的问题
3>.可以使用 import <> 或 from <> import <> 这两种语法
import a
from a import b
相对导入:
1>.使用相对导入,只需要知道模块与模块之间的相对位置即可,通过.来代表相对路径:
. : 根据模块名称【__ name __】所获取的当前目录
… : 根据模块名称所获取的父级目录
… : 根据模块名称所获取的祖父级目录
2>.注意顶级目录问题。与执行文件处于一个目录下的包是顶级包,相对导入不能跨过顶级包,即顶级包之间是不能相互相互访问【执行文件的执行方式不一样,顶级目录也不一样。如:python tool/main.py 和 cd tool & python main.py两种执行方式的顶级目录不一样】
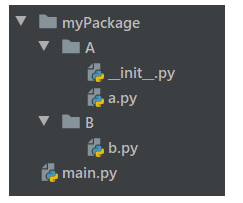
执行main.py,即main.py所在目录下的A包和B包是顶级包,不能通过相对导入的方式互相访问,所以a.py不能导入B包中的b.py。如果出现顶级包之间的互相访问,python解释器会报错:
ValueError: attempted relative import beyond top-level package
此时可以考虑采用绝对导入的方式。
3>.相对导入只能在被导入的模块中使用。存在相对导入语句的模块,是不能直接运行的。 这是因为:一个模块直接运行,Python 认为这个模块就是顶层模块,不存在层次结构,所以找不到其它的相对路径
4>.相对导入只能使用 from <> import <> 这种语法,并且使用 . 作为前导点。
5>.在模块里可通过属性 __ package __ 获取自身的包信息,即该模块所在包的结构,诸如 XXX、XXX.YYY.ZZZ 等形式,第一个节点就是顶层包,如果 __ package __ 为 None 表示该模块是顶层模块。模块的位置是由该模块的 __ name __ 属性来确定,如果是 __ main __ 则它本身是顶层模块,没有包结构,如果是A.B.C 结构,那么顶层模块是 A。
6>.相对导入对于包的维护优势:相对导入可以避免硬编码带来的包维护问题,例如我们改了某一层包的名称,那么其它模块对于其子包的所有绝对导入就不能用了,但是采用相对导入语句的模块,就会避免这个问题。
从不同的路径位置下执行代码,主要影响两个地方
1.sys.path.append(’./’)
2.相对导入时的顶级目录
模块导入后执行了哪些操作
第一次导入
1.在导入模块的命名空间执行所有代码【不管是导入整个模块,还是一个函数都会执行模块内所有的代码】
2.创建一个模块对象,并将模块中所有顶级变量以属性的形式【可以通过对象.方式访问】绑定到该对象上
3.在import的位置引入import后面的变量名到该命名空间【即引入模块对象,可以用了】
第二次导入
直接执行第三步
无论是从包导入模块还是模块资源,都会执行模块内所有的代码;当直接导入包时,包中__ init __.py导入了哪些模块/模块资源,就会执行那个模块内的所有代码,其它模块不会执行;在 __ init __.py中再次导入模块时,需要使用绝对路径