相干性介绍
两个广义平稳随机过程![]() 和
和![]() 之间的相干函数等于互功率谱
之间的相干函数等于互功率谱![]() 除以自功率谱的乘积的平方根。具体地,复相干性定义为:
除以自功率谱的乘积的平方根。具体地,复相干性定义为:

其中复互功率谱为
![]()
是互相关函数的傅里叶变换
![]()
这里x和y是实数,E表示数学期望(对于遍历随机过程,集合平均可以用时间平均代替)。相干性是一个归一化的互功率谱密度函数,平方相干性(MSC)定义为
![]()
![]()
相干函数在很多领域都有应用,包括系统识别、信噪比(SNR)的测量和时延的确定。相干性,特别是平方相干性(MSC),只有在能准确估计其值的情况下才能发挥作用。事实上,理解评估者的统计数据是非常可取的。因此,本节将解释相干功能。下面几节介绍正确估计MSC和估计器的统计量的过程。
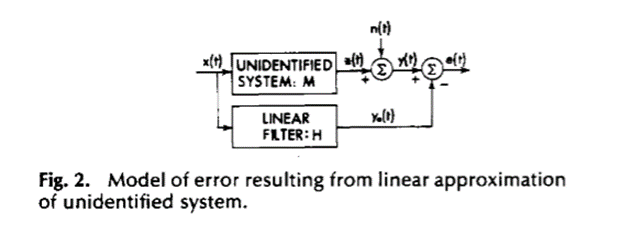
对相干性的一个有趣的解释——尤其是MSC——是对两个过程的相对线性的度量。为了说明这一点,如图1所示:

其中任意平稳随机过程的样本函数y(t)由线性滤波器的响应![]() 加上误差分量e(t)组成。当选择线性滤波器最小化e(t)的均方值,即误差谱下的面积时,
加上误差分量e(t)组成。当选择线性滤波器最小化e(t)的均方值,即误差谱下的面积时,![]() 就成为y(t)中与x(t)线性相关的那部分。e(t)的光谱特性由下式给出:
就成为y(t)中与x(t)线性相关的那部分。e(t)的光谱特性由下式给出:
![]()
![]()
式中*表示复共轭,H(f)为滤波器传递函数。误差谱为:

因此,最佳滤波器由下式给出
![]()
注意相干性是与最佳线性滤波器相关联的

无论y(t)的来源如何,这些结果都适用。均方意义下线性滤波器最优时,误差与x(t)无关,即:
![]()
此外,![]() 的最小值由下式给出:
的最小值由下式给出:
![]()
![]()
![]()
可以看出
![]()
表示MSC为y(t)的线性分量中![]() 的比值,
的比值,![]() 为误差中
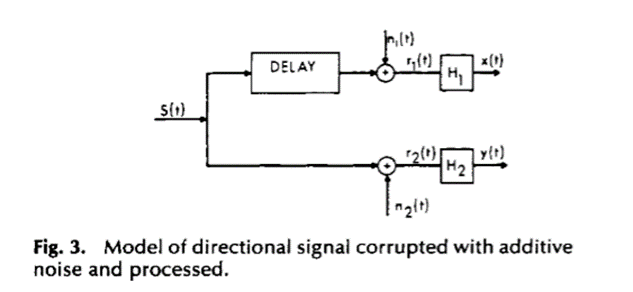
为误差中![]() 的比值,即y(t)的非线性分量。这些结果可以应用于图2和图3所示的配置。
的比值,即y(t)的非线性分量。这些结果可以应用于图2和图3所示的配置。
Welch重叠分段平均法(WOSA)的MSC估计的统计分析
A.引言
许多关于MSC估计统计的历史工作都以WOSA方法为中心;通过对变量的合理解释,这些结果也适用于拉格重塑法。回想一下,WOSA方法包括从被调查的随机过程中获得两个有限时间序列。每个时间序列被分割成等长段,并在等距的数据点上采样。片段是重叠的。然而,统计数据是分析开发的非重叠部分。给出了重叠段的经验结果。每个片段的样本乘以一个加权函数,然后执行加权序列的FFT。然后利用每个加权段的傅立叶系数来估计自动功率谱密度和交叉功率谱密度。由此得到的谱密度估计被用来形成MSC估计。
估计值的光谱分辨率与段长度t成反比变化。适当的加权或t秒段的“加窗”也有助于实现良好的旁瓣缩小。另一方面,对于具有理想窗口的独立段,MSC估计的偏差和方差与段数n成反比。因此,为了在有限的数据下产生良好的估计,段重叠可以增加n和t。当段不相交,即不重叠时,我们称段数为![]() 。然而,随着重叠百分比的增加,计算需求迅速增加,同时由于数据段之间的相关性增强,改进趋于稳定。
。然而,随着重叠百分比的增加,计算需求迅速增加,同时由于数据段之间的相关性增强,改进趋于稳定。
B. MSC估计的概率密度
在表1中给出了MSC的估计的一阶概率密度和分布函数,给定MSC的真实值,以及独立段的数量nd![]() 。符号上,回想
。符号上,回想![]() 。该表中的等式(1b)和(1c)是有用的,因为“
。该表中的等式(1b)和(1c)是有用的,因为“![]() ”超几何函数是第(
”超几何函数是第(![]() )阶多项式。
)阶多项式。

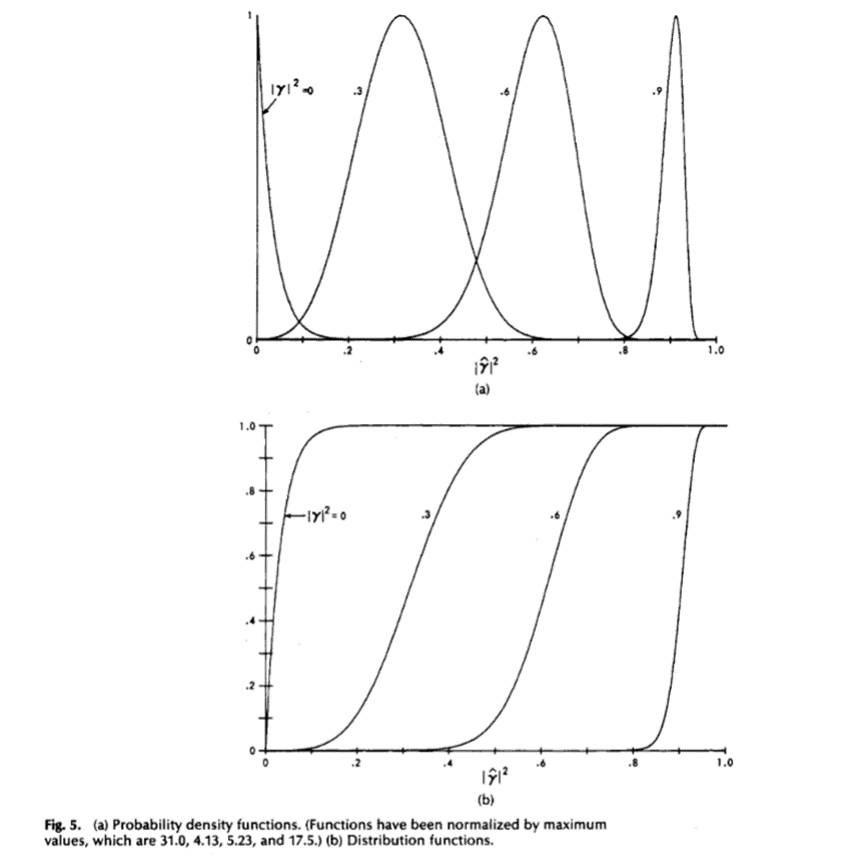
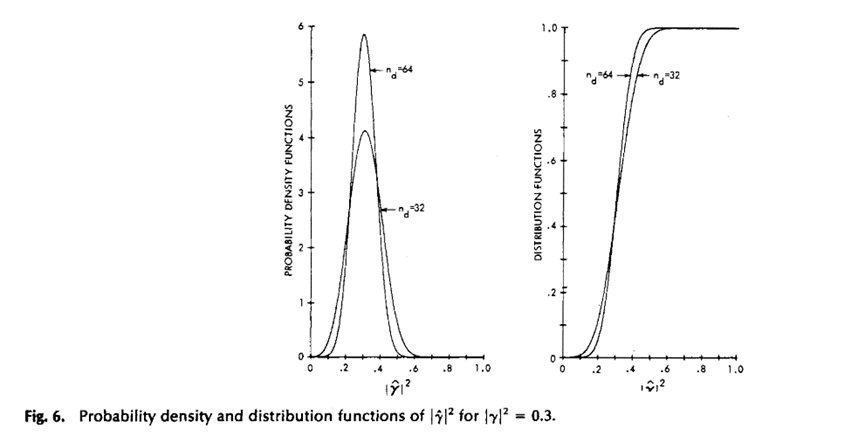
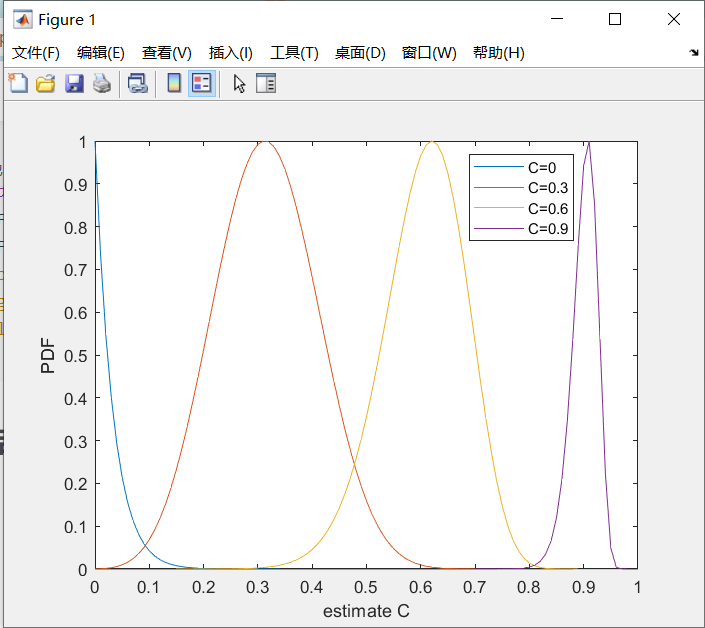
图5和图6显示了几种情况下的概率密度和分布函数,由表1中的(1b)和(1d)计算得到。从图6中可以明显看出,当![]() 增大时,MSC估计的方差减小。
增大时,MSC估计的方差减小。
得到的偏差和方差表达式如表2所示。近似值(2c)和(2d)是截断序列(2a)和(2b)的结果。方程(2e)到(2g)则适用于大的![]() ;它们表明MSC估计是渐近无偏的,并且对于大的
;它们表明MSC估计是渐近无偏的,并且对于大的![]() 可以得出下列结论。
可以得出下列结论。
1)当MSC等于0时,偏差最大,为![]() ,当MSC等于1时,偏差最小,为0。
,当MSC等于1时,偏差最小,为0。
2)当MSC等于1时,方差为0,当MSC等于1/3时,偏差最大,为![]() 。
。
3)如果MSC不为零,则与真值的均方误差等于方差。
 相关代码
相关代码
clear
%实际的MSC分别为0,0.3,0.6,0.9时的概率密度函数(PDF)和累积分布函数(CDF)
nd=32;C_list=[0 0.3 0.6 0.9];
estimate_C=0:0.01:1;%估计的MSC
figure(1)
for i=1:length(C_list)
C=C_list(i);
PDF=(nd-1)*((1-C).^nd)*((1-estimate_C).^(nd-2))...
.*((1-C.*estimate_C).^(1-2*nd))...
.*(hypergeom([1-nd,1-nd],1,C*estimate_C));
PDF=PDF/max(PDF);
plot(estimate_C,PDF);xlabel('estimate C');ylabel('PDF')
legend('C=0', 'C=0.3', 'C=0.6', 'C=0.9');
hold on
end
figure(2)
for j=1:length(C_list)
C=C_list(j);
CDF1=hypergeom([0,1-nd],1,C*estimate_C);%当k=0时
for k=1:nd-2
CDF1=CDF1+(((1-estimate_C)./(1-C*estimate_C)).^k)...
.*hypergeom([(-k),1-nd],1,C*estimate_C);
end
CDF=estimate_C.*(((1-C)./(1-C*estimate_C)).^nd).*CDF1;
CDF=CDF/max(CDF);
plot(estimate_C,CDF);xlabel('estimate C');ylabel('CDF')
legend('C=0', 'C=0.3', 'C=0.6', 'C=0.9');
hold on
end
%C=0.3;nd分别为32和64时的PDF和CDF
estimate_C=0:0.01:1;
C=0.3;nd_list=[32 64];
figure(3)
for i=1:length(nd_list)
nd=nd_list(i);
PDF=(nd-1)*((1-C).^nd)*((1-estimate_C).^(nd-2))...
.*((1-C.*estimate_C).^(1-2*nd))...
.*(hypergeom([1-nd,1-nd],1,C*estimate_C));
plot(estimate_C,PDF);xlabel('estimate C');ylabel('PDF')
legend('nd=32', 'nd=64');
hold on
end
figure(4)
for j=1:length(nd_list)
nd=nd_list(j);
CDF1=hypergeom([0,1-nd],1,C*estimate_C);%当k=0时
for k=1:nd-2
CDF1=CDF1+(((1-estimate_C)./(1-C*estimate_C)).^k)...
.*hypergeom([(-k),1-nd],1,C*estimate_C);
end
CDF=estimate_C.*(((1-C)./(1-C*estimate_C)).^nd).*CDF1;
CDF=CDF/max(CDF);
plot(estimate_C,CDF);xlabel('estimate C');ylabel('CDF')
legend('nd=32', 'nd=64');
hold on
end
仿真结果



有问题欢迎留言哦~~