// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x){ pos = i; break;}
}
return pos;
}通过以上代码,我们分析一下平均情况时间复杂度。
以上代码要查找的变量 x 在数组中的位置,有 n+1 种情况:在数组的 0~n-1 位置中和不在数组中。我们把每种情况下,查找需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值
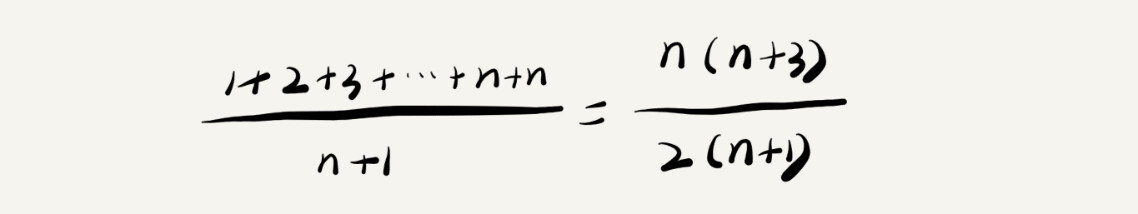
以上推算省略掉系数、低阶、常量,公式简化之后,得到的平均时间复杂度就是 O(n)
这个结论虽然是正确的,但是n+1 种情况,出现的概率并不是一样的。
我们具体分析一下:
要查找的变量 x,要么在数组里,要么就不在数组里。这两种情况对应的概率统计起来很麻烦,为了方便你理解,我们假设在数组中与不在数组中的概率都为 1/2。另外,要查找的数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。所以,根据概率乘法法则,要查找的数据出现在 0~n-1 中任意位置的概率就是 1/(2n)。
因此,前面的推导过程中存在的最大问题就是,没有将各种情况发生的概率考虑进去。如果我们把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样:
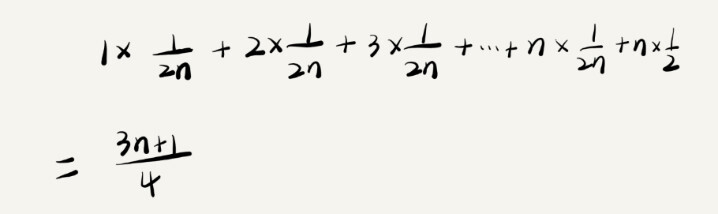
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。引入概率之后,前面那段代码的加权平均值为 (3n+1)/4。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
虽然听起来很复杂,但是我觉得最近在重新学习这部分知识很有意思,尤其是推理,把我的数学知识给捡起来了
此文章为5月Day5学习笔记,内容来源于极客时间《数据结构与算法之美》