1 相关标记
神经网络在分类问题中的应用
- 训练集:
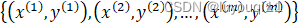
- 神经网络的层数:L。L=4
 层中的神经元数(不包括偏差单元):
层中的神经元数(不包括偏差单元): 。
。
- 输出单元数:K
当K=1,只有一个输出单元,
,
有K个输出单元,
,例如:
;
2 代价函数
逻辑回归的代价函数为:
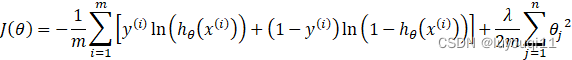
神经网络的代价函数为:
![]()
 3 反向传播算法(Backpropagation algorithm)
3 反向传播算法(Backpropagation algorithm)
代价函数:

目标:![]()
需要计算:
重点在于如何计算偏导项。
3.1 前向传播计算过程
对于一个训练样本![]() :
:
前向传播计算的过程是:
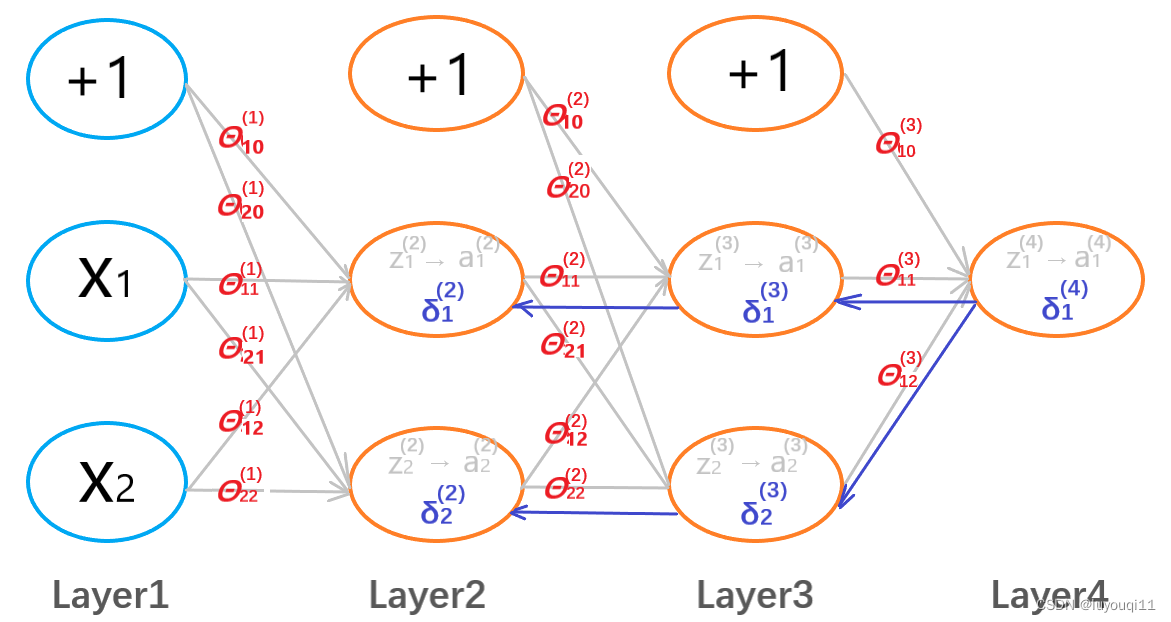
3.2 反向传播梯度计算原理
反向传播法从直观上说就是研究![]() 层
层![]() 节点的误差)
节点的误差)![]() ,
,![]() 是该节点的激活值
是该节点的激活值

反向传播的输出层误差是(L=4):
![]()
用向量表示则有:
![]()
反向传播的计算如下:
不存在![]() ,因为对于第一层而言,是训练样本,不存在误差。
,因为对于第一层而言,是训练样本,不存在误差。
所谓反向传播,就是相对于前向传播而言的。就是先计算输出层的误差,在反向计算L-1层的误差,…,直到计算出第二层的误差。
3.3 反向传播梯度计算过程
训练集:![]()
神经网络的层数:L。L=4
![]() 层中的神经元数(不包括偏差单元):
层中的神经元数(不包括偏差单元):![]() 。
。![]()
输出单元数:K
当K=1,只有一个输出单元,![]() ,
,![]()
有K个输出单元,![]() ,例如:
,例如: ;
;![]()
第一步:设置![]()
![]() 是
是![]() 的大写,用来计算偏导项
的大写,用来计算偏导项![]()
第二步:循环
For i=1 to m
Set![]()
Perform forward propagation to compute ![]() for l=2,3,…,L
for l=2,3,…,L
Using![]() ,compute
,compute ![]()
Compute![]()
![]() 用向量表示为
用向量表示为![]()
第三步:跳出这个循环的条件分两种情况讨论:
![]()
![]()
3.4 正向传播和反向传播的计算过程对比
训练集:![]()
神经网络的层数:L。L=4
![]() 层中的神经元数(不包括偏差单元):
层中的神经元数(不包括偏差单元):![]() 。
。![]()
输出单元数:K。K=1
前向传播计算详细过程如下:
第一步:设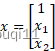 ,
,![]() ,
,![]() ,则有
,则有
![]()
第二步:加一个偏置项![]() ,则有
,则有 ,则有
,则有![]() =
=![]()
第三步:加一个偏置项![]() ,则有
,则有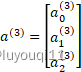 ,则有
,则有![]() =
= ![]()
反向传播计算详细过程如下:
反向计算的代价函数:
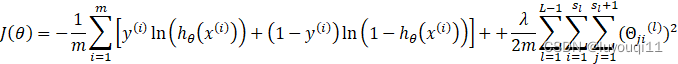
对于一个训练集样本![]() ,只有一个输出单元,可以忽略正则化项λ=0,单样本代价函数为:
,只有一个输出单元,可以忽略正则化项λ=0,单样本代价函数为:
![]()
这个函数表示了预测的精确度。为了方便理解:【这个表达式扮演了类似方差的角色,于是可以考虑![]() ,即神经网络预测值和实际值的方差,就像逻辑回归中的单样本方差一样。】熟悉微积分的都知道:
,即神经网络预测值和实际值的方差,就像逻辑回归中的单样本方差一样。】熟悉微积分的都知道:


- 对于输出层而言,可以计算
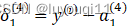
- 由
 进行反向计算
进行反向计算 ,
,
- 再进一步计算
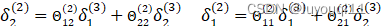
3.5 随机初始化(Random initialization)
如何初始化参数?
初始化为零向量
千里之行始于足下,如果用梯度下降法找最好的参数的时候也需要一个起始点,那如果把初始值全部设为0可以么?来看一下。
在逻辑回归的算法中,理论上是可以将参数都设置为0的,但在神经网络中将参数设置为0的话,将起不到任何作用。相当于![]()
在神经网络中,如果初始化所有的参数(也就是权重)相同,那么所有输入都相同,神经网络就失去了它的作用了。所以我们需要随机初始化。
随机初始化
为了训练神经网络,我们需要对权重进行随机初始化。
前面,所有权值都初始化为0(或者说初始化为相同的值)是不合适的,这就是所谓的对称权重问题。
因此,需要对权重进行随机初始化,将每个参数都初始化为某一个闭区间内的随机数。
4 总结
利用神经网络训练数据,最重要的首先是确定神经网络的结构。
4.1确定神经网络的结构
神经网络的结构呢,无非就是输入层、输出层外加隐藏层,那隐藏层有几层?每一层有多少个神经元?输入层、输出层分别又有多少个单元?
那这些多少,到底该是多少呢?在进行神经网络训练之前必须回答这些问题。
首先,输入层的单元数是由你的自变量的维度决定的;
其次,输出层的单元数又是由要分类的问题最终分成多少个类来决定的。
因此,神经网络结构的选择问题,实质上就是要确定隐藏层的层数以及各隐藏层的单元数目
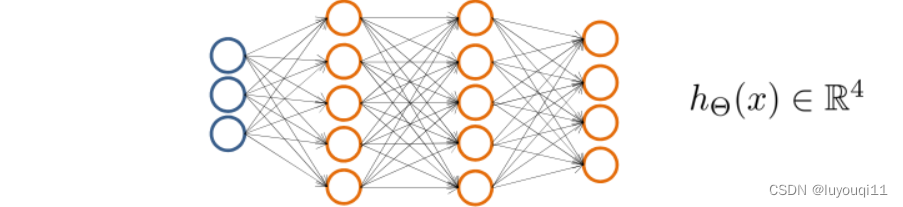
以3个输入单元、4个输出单元的神经网络为例,常见的隐藏层的设置如下图所示。

按分类的效果来说呢,隐藏层的单元数是越多越好的,但是过多的神经元会让训练相当的缓慢,因此需要平衡一下,一般将隐藏层的单元数设置为输入层单元数的2~4倍为宜。而隐藏层的层数呢就以1、2、3层比较常见。
4.2 神经网络训练的一般步骤
Step1:随机初始化权重;
Step2:实现前向传播算法,获得各个输入的激活函数![]() ;
;
Step3:编码计算代价函数)![]() ;
;
Step4:实现反向传播计算激活函数的偏导数)![]() 。
。
看一下伪代码:
for i=1:m
用训练集xi,yi
执行前向传播和反向传播计算
获得每一层的激活值a(l)
和误差δ(l) for l=2,…,L
代码中的m是训练样本的个数。
Step5:使用梯度检验验证反向传播计算偏导数的代码是否正确,如果正确就关闭掉梯度检验部分的代码。
Step6:结合一些更优秀的算法算出能使代价函数最小的那些参数![]() 。
。