1 样本数据ex2data2.txt
0.051267,0.69956,1
-0.092742,0.68494,1
-0.21371,0.69225,1
-0.375,0.50219,1
-0.51325,0.46564,1
-0.52477,0.2098,1
-0.39804,0.034357,1
-0.30588,-0.19225,1
0.016705,-0.40424,1
0.13191,-0.51389,1
0.38537,-0.56506,1
0.52938,-0.5212,1
0.63882,-0.24342,1
0.73675,-0.18494,1
0.54666,0.48757,1
0.322,0.5826,1
0.16647,0.53874,1
-0.046659,0.81652,1
-0.17339,0.69956,1
-0.47869,0.63377,1
-0.60541,0.59722,1
-0.62846,0.33406,1
-0.59389,0.005117,1
-0.42108,-0.27266,1
-0.11578,-0.39693,1
0.20104,-0.60161,1
0.46601,-0.53582,1
0.67339,-0.53582,1
-0.13882,0.54605,1
-0.29435,0.77997,1
-0.26555,0.96272,1
-0.16187,0.8019,1
-0.17339,0.64839,1
-0.28283,0.47295,1
-0.36348,0.31213,1
-0.30012,0.027047,1
-0.23675,-0.21418,1
-0.06394,-0.18494,1
0.062788,-0.16301,1
0.22984,-0.41155,1
0.2932,-0.2288,1
0.48329,-0.18494,1
0.64459,-0.14108,1
0.46025,0.012427,1
0.6273,0.15863,1
0.57546,0.26827,1
0.72523,0.44371,1
0.22408,0.52412,1
0.44297,0.67032,1
0.322,0.69225,1
0.13767,0.57529,1
-0.0063364,0.39985,1
-0.092742,0.55336,1
-0.20795,0.35599,1
-0.20795,0.17325,1
-0.43836,0.21711,1
-0.21947,-0.016813,1
-0.13882,-0.27266,1
0.18376,0.93348,0
0.22408,0.77997,0
0.29896,0.61915,0
0.50634,0.75804,0
0.61578,0.7288,0
0.60426,0.59722,0
0.76555,0.50219,0
0.92684,0.3633,0
0.82316,0.27558,0
0.96141,0.085526,0
0.93836,0.012427,0
0.86348,-0.082602,0
0.89804,-0.20687,0
0.85196,-0.36769,0
0.82892,-0.5212,0
0.79435,-0.55775,0
0.59274,-0.7405,0
0.51786,-0.5943,0
0.46601,-0.41886,0
0.35081,-0.57968,0
0.28744,-0.76974,0
0.085829,-0.75512,0
0.14919,-0.57968,0
-0.13306,-0.4481,0
-0.40956,-0.41155,0
-0.39228,-0.25804,0
-0.74366,-0.25804,0
-0.69758,0.041667,0
-0.75518,0.2902,0
-0.69758,0.68494,0
-0.4038,0.70687,0
-0.38076,0.91886,0
-0.50749,0.90424,0
-0.54781,0.70687,0
0.10311,0.77997,0
0.057028,0.91886,0
-0.10426,0.99196,0
-0.081221,1.1089,0
0.28744,1.087,0
0.39689,0.82383,0
0.63882,0.88962,0
0.82316,0.66301,0
0.67339,0.64108,0
1.0709,0.10015,0
-0.046659,-0.57968,0
-0.23675,-0.63816,0
-0.15035,-0.36769,0
-0.49021,-0.3019,0
-0.46717,-0.13377,0
-0.28859,-0.060673,0
-0.61118,-0.067982,0
-0.66302,-0.21418,0
-0.59965,-0.41886,0
-0.72638,-0.082602,0
-0.83007,0.31213,0
-0.72062,0.53874,0
-0.59389,0.49488,0
-0.48445,0.99927,0
-0.0063364,0.99927,0
0.63265,-0.030612,0
2 Python代码实现
主要包含4个任务:进行数据映射、实现正则化的梯度下降,绘制决策边界以及进行预测。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict#用于导入数据的函数
def inputData():
#从txt文件中导入数据,注意最好标明数据的类型
data = pd.read_csv('D:/dataAnalysis/MachineLearning/ex2data2.txt'
,names = ['Microchip test 1','Microchip test 2','Label']
,dtype={0:float,1:float,2:int})
#插入一列全为1的列
data.insert(0,"ones",np.ones((data.shape[0],1)))
print(data.head())
#分别取出X和y
X=data.iloc[:,0:3]
X=X.values
y=data.iloc[:,3]
y=(y.values).reshape(y.shape[0],1)
return X,y#用于最开始进行数据可视化的函数
def showData(X,y):
#分开考虑真实值y是1和0的行,分别绘制散点,并注意使用不同的label和marker
for i in range(0,X.shape[0]):
if(y[i][0]==1):
plt.scatter(X[i][1],X[i][2],marker="+",c='b',label='y=1')
else:
plt.scatter(X[i][1],X[i][2],marker='o',c='y',label='y=0')
#设置坐标轴和图例
plt.xticks(np.arange(-1,1.5,0.5))
plt.yticks(np.arange(-0.8,1.2,0.2))
plt.xlabel('Microchip Test 1')
plt.ylabel('Microchip Test 2')
#因为上面绘制的散点不做处理的话,会有很多重复标签
#因此这里导入一个集合类消除重复的标签
handles, labels = plt.gca().get_legend_handles_labels() #获得标签
by_label = OrderedDict(zip(labels, handles)) #通过集合来删除重复的标签
plt.legend(by_label.values(), by_label.keys()) #显示图例
plt.show()#定义sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))#计算代价值的函数
def computeCostsJ(X,y,theta,lamda,m):
#根据吴恩达老师上课讲的公式进行书写
hx=sigmoid(X@theta)
costsJ=-(np.sum(y*np.log(hx)+(1-y)*np.log(1-hx)))/m+lamda*np.sum(np.power(theta,2))/(2*m)
return costsJ#进行特征映射
def featureMapping(x1,x2,level):
answer = {} #定义一个字典
for i in range(1,level+1): #外层循环,映射的阶数
for j in range(0,i+1): #内存循环,x1的次数
answer['F{}{}'.format(i-j,j)]=np.power(x1,i-j)*np.power(x2,j) #形成字典中的key-value
answer = pd.DataFrame(answer) #转换为一个dataframe
answer.insert(0,"ones",np.ones((answer.shape[0],1))) #插入第一列全1
return answer.values#进行梯度下降的函数
def gradientDescent(X,y,theta,alpha,iterations,m,lamda):
for i in range(0,iterations+1):
hx=sigmoid(X@theta)
temp0=theta[0][0]-alpha*np.sum(hx-y)/m #因为x0是不需要进行正则化的,因此需要单独计算
theta=theta-alpha*(X.T@(hx-y)+lamda*theta)/m #根据公式进行同步更新theta
theta[0][0]=temp0 #单独修改theta0
return theta#利用训练集数据判断准确率的函数
def judge(X,y,theta):
ys=sigmoid(X@theta) #根据假设函数计算预测值ys
yanswer=y-ys #使用真实值y-预测值ys
yanswer=np.abs(yanswer) #对yanswer取绝对值
print('accuary',(yanswer<0.5).sum()/y.shape[0]*100,'%') #计算准确率并打印结果#对决策边界进行可视化的函数
def evaluateLogisticRegression(X,y,theta):
#这里和上面进行数据可视化的函数步骤是一样的,就不重复阐述了
for i in range(0,X.shape[0]):
if(y[i][0]==1):
plt.scatter(X[i][1],X[i][2],marker="+",c='b',label='y=1')
else:
plt.scatter(X[i][1],X[i][2],marker='o',c='y',label='y=0')
plt.xticks(np.arange(-1,1.5,0.5))
plt.yticks(np.arange(-0.8,1.2,0.2))
plt.xlabel('Microchip Test 1')
plt.ylabel('Microchip Test 2')
handles, labels = plt.gca().get_legend_handles_labels()
by_label = OrderedDict(zip(labels, handles))
plt.legend(by_label.values(), by_label.keys())
#通过绘制等高线图来绘制决策边界
x=np.linspace(-1,1.5,250) #创建一个从-1到1.5的等间距的数
xx,yy = np.meshgrid(x,x) #形成一个250*250的网格,xx和yy分别对应x值和y值
#利用ravel()函数将xx和yy变成一个向量,也就是62500*1的向量
answerMapping=featureMapping(xx.ravel(),yy.ravel(),6) #进行特征映射
answer=answerMapping@theta #代入映射后的数据进行计算预测值
answer=answer.reshape(xx.shape) #将answer换成一样格式
plt.contour(xx,yy,answer,0) #绘制等高线图,0代表绘制第一条等高线
plt.show()
X,y = inputData() #导入数据
theta=np.zeros((28,1)) #初始化theta数组
iterations=200000 #定义迭代次数
alpha=0.001 #定义alpha值
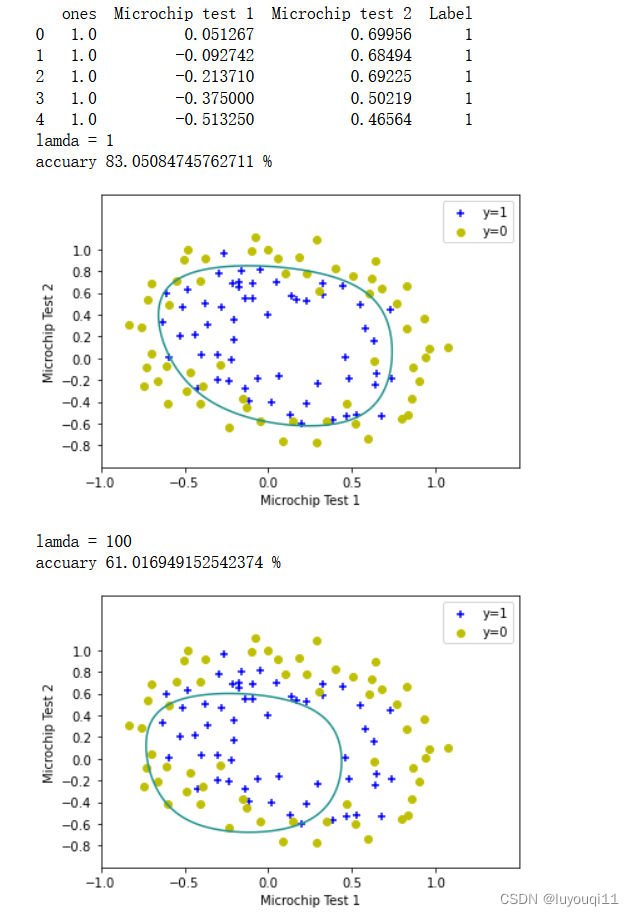
lamda=1 #定义lamda
print(f'lamda = {lamda}')
mappingX = featureMapping(X[:,1],X[:,2],6) #进行特征映射
theta=gradientDescent(mappingX,y,theta,alpha,iterations,X.shape[0],lamda) #进行正则化的梯度下降
judge(mappingX,y,theta) #计算预测的准确率
evaluateLogisticRegression(X,y,theta) #绘制决策边界
lamda=100 #定义lamda
print(f'lamda = {lamda}')
mappingX = featureMapping(X[:,1],X[:,2],6) #进行特征映射
theta=gradientDescent(mappingX,y,theta,alpha,iterations,X.shape[0],lamda) #进行正则化的梯度下降
judge(mappingX,y,theta) #计算预测的准确率
evaluateLogisticRegression(X,y,theta) #绘制决策边界
运行结果如下: