搜索引擎应该具有什么要求?
-
查询快
高效的压缩算法 快速的编码和解码速度
-
结果准确
BM25 TF-IDF
-
检索结果丰富
召回率
面向海量数据,如何达到搜索引擎级别的查询效率?
索引
- 帮助快速检索
- 以数据结构为载体
- 以文件形式落地
倒排索引的数据结构
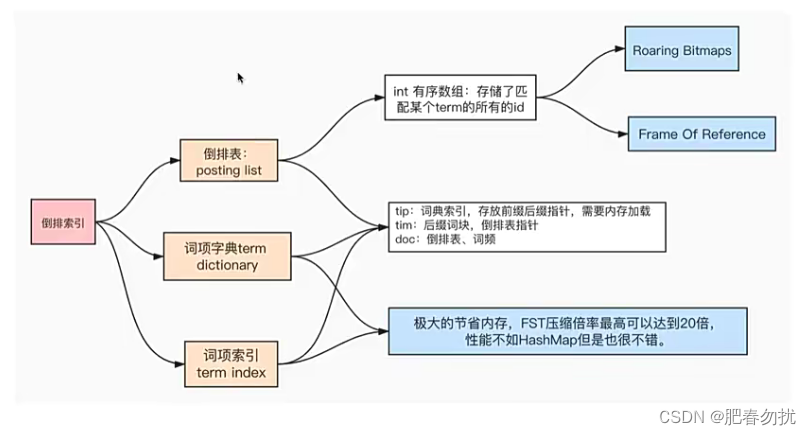 倒排索引
倒排索引
概念
一句话就是 关键词到文档id的映射
倒排索引的基本数据结构
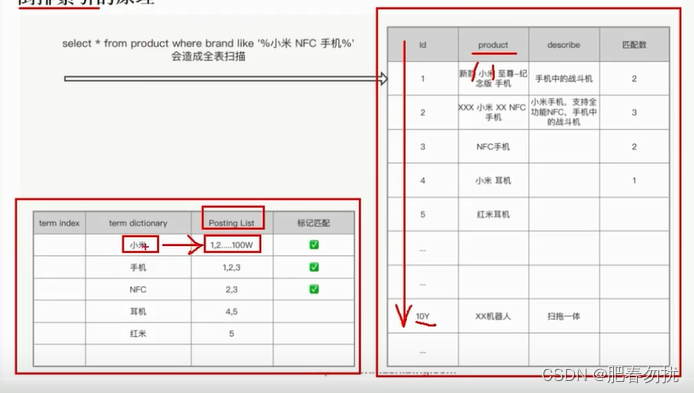
term_dictionary:词项字典 不重复
Posting_List: 倒排表 存词项的文档id int类型存储,为什么单个分片的倒排表有容量上限呢?就是因为int存储
term_index: 词项索引
当前的数据是一个十亿级别的数据,这时候我们词项字典有很多,这时候检索不久又麻烦了吗
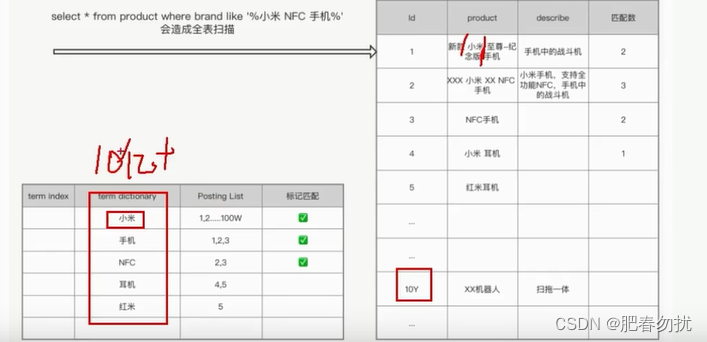
这时候就延伸出了FST ,它实际上是trie的变种。这时候看这个图 10亿的数据 导致倒排表存的id特多,所以倒排表对这个做了优化,如下图
词项字典存在tim文件中
词项索引存放在tip中
倒排表存在doc中