
埃隆·马斯克 (Elon Musk) 的星际飞船于 2023 年 4 月 20 日升空后爆炸。想象一下,当时您正在观察股市,突然出现新闻,您会如何交易 TSLA 股票?
我希望您不要与我争论,您作为交易者(而不是投资者)要做的第一件事就是摆脱现有的多头头寸并可能做空股票。让我们看看这样的交易是否有利可图。
根据此链接SpaceX rocket launch recap: First Starship explodes soon after launch,我注意到以下两个时间戳:美国东部时间上午 9:33,星舰从德克萨斯州 Starbase 升空的倒计时已经恢复。美国东部时间上午 9 点 40 分,星舰因分离失败而失联。然后我们知道 Starship 大约 2 分钟后爆炸了。
现在我们看一下当天TSLA股票的1分钟图。美国东部时间上午 9:30 开盘后,该股看涨。上午 9:34 至 9:42 之间有一些盘整。然后,从上午 9:43 到 9:46,出现了一次峰值,随后在上午 9:46 到 9:56 出现了巨大的抛售。然后,盘整一直持续到上午11:00,然后持续下跌,一直到下午3:15。
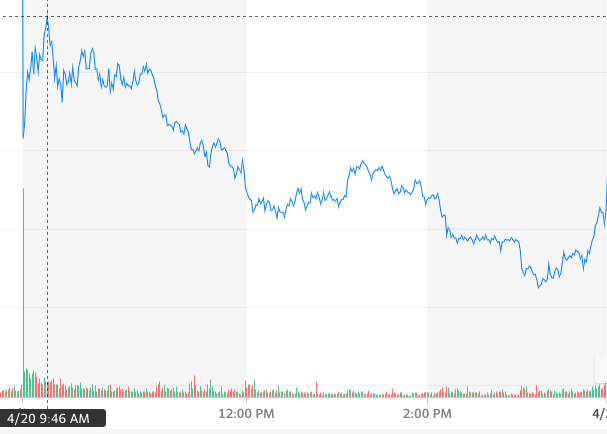
2023 年 4 月 20 日 TSLA 股票 1 分钟图。价格在上午 9:46 达到峰值——Starship 分离失败后 6 分钟(图表来源:雅虎财经)
请注意,对于那些没有观看 Starship 发射现场直播的人来说,您最早可以在美国东部时间 9:58 收到 Starship 爆炸消息。
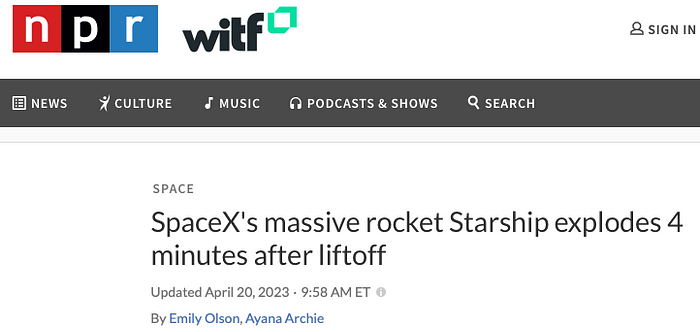
NPR 的屏幕截图显示美国东部时间 9:58,这是我能找到的关于 2023 年 4 月 20 日星舰爆炸的最早新闻
因此,如果您同时观看星舰发射和股市直播,那么早在上午 9:40 意识到直播中明显的分离失败后,您就可以进行空头交易。如果你能在接下来的 6 分钟的挤压中幸存下来,你就会迎来盈利的一天。另一方面,如果您依靠新闻来了解正在发生的事情,那么您最早可以采取贸易行动的是美国东部时间 9:58。那是消息传出的时间戳。如果您当时立即做空股票,您将需要遭受一小时的痛苦才能最终获得盈利。
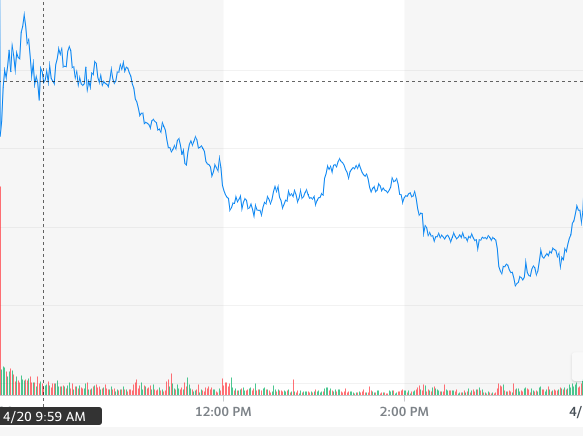
如果你在上午 9:58 读到新闻,并在上午 9:59 立即做空股票,那么在股票最终下跌让你盈利之前的一小时,你将遭受损失(图表来源:雅虎财经)
正如你所看到的,即使有后市事实,在市场重播中准确把握市场时机仍然非常困难。然而,我希望你仍然同意我的观点,即一个消息灵通、拥有股票头条新闻的人可能会在股票市场上交易得更好。至少对于趋势交易者来说,这样的股票头条不会让他们站在交易的错误一边。在这个例子中,价格模式不是很干净,这可能是由于新闻情绪上的争议,因为无论如何,这次爆炸被 SpaceX 工程师认为是成功的,因为他们试图从“计划中的爆炸”中获得有价值的见解。失败”。尽管如此,将爆炸消息解读为“负面”的常识仍然占了上风,股市的最终反应就证明了这一点。
由于在交易过程中成为一个消息灵通的人很重要,因此在本文中,我们将探讨如何使自己充分了解股票头条新闻。请注意,我们的目标并不是成为那些观看发布会现场直播的“内部人士”,因此可以在上午 9:40 做空股票,只需要忍受 6 分钟的时间,我们希望成为那些收到消息的人早在上午9点58分,就迅速解读了消息,并据此进行了交易。我知道这可能已经晚了,因为记者写新闻文章需要时间,编辑和发布过程也需要时间。但对于几乎所有其他股票,我们不可能成为内部人士,不是吗?
理论基础
算法是:(1)我们使用网络抓取工具从新闻网站中提取新闻;(2)我们将提取的新闻输入大型语言模型(LLM,例如ChatGPT)来分析新闻的情绪;(3) 我们重复步骤 1 和步骤 2,如果出现额外的标题,我们要求gpt按照从时间零到最新的顺序重新评估所有先前新闻的情绪。
为了实现有效指导交易的算法,我们需要从零时间的定义开始。根据现代学术界普遍接受的有效市场理论,任何时刻的股票价格都充分反映了所有可获得的信息。这意味着只要股票正在交易,任何新闻发布都已经纳入价格中。换句话说,没有套利,也没有免费的午餐。这就是为什么你可以在前面的例子中看到,即使未来知道星舰爆炸的时间戳,当我们想象在市场重播中进行交易时,仍然很难盈利。另一方面,根据适应性市场理论(由麻省理工学院的 Andrew Lo 教授提出),有时,由于市场参与者的非理性,我们交易者可以利用市场进行短暂的套利。这就是为什么我们需要这篇文章来有效地利用新闻来指导交易。这里我们将零时间设置为前一交易日晚上 8:00 收盘时的时间戳。如果今天是周一以外的工作日,则时间“零”将是昨天的晚上 8:00。另一方面,如果今天是星期一,则时间零将是上周五的晚上 8:00。这是因为,在股市休市的同时,消息却不断传出,消息与股价肯定存在不一致的情况。许多公司还故意将新闻发布日期定在周末或盘后时间,以减轻新闻对股价的影响,因为在市场重新开市之前,投资者有更多的时间冷静下来消化信息。因此,当我们从新闻网站提取新闻时,我们会提取零时的所有最近新闻。零时间之前的新闻将被丢弃,因为它们已经被纳入价格中。
那么我们该如何处理被抓取的新闻呢?如果收盘后没有消息,那么我们都很好。如果只有一条新闻,任何自训练的自然语言处理模型都可以通过给我们一种情绪来很好地完成这项工作。然而,正如您所看到的,在这个项目中,我们使用gpt,因为我们需要它们的推理能力和一致性来对一系列新闻进行评级。阅读以下示例后,您将明白为什么这是必须的:
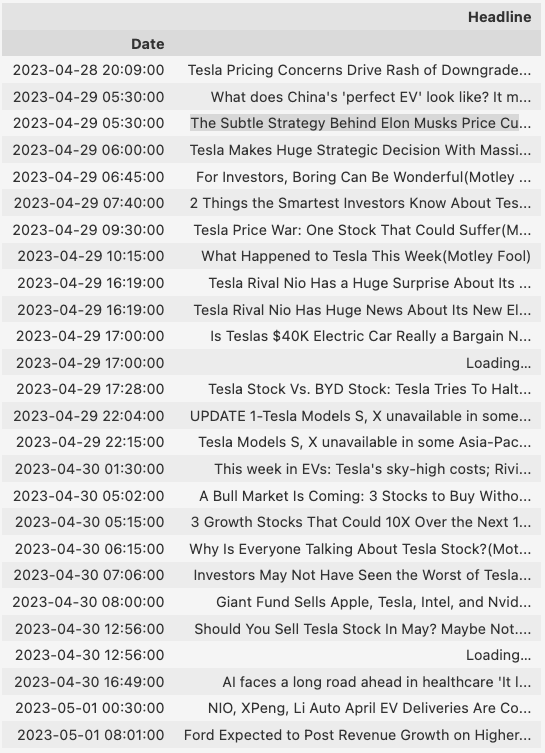
2023 年 5 月 1 日星期一零时至上午 9:30 期间从 finviz.com 网络抓取的新闻(按作者列出)
这里我特意选择2023年5月1日星期一作为我当前的交易日。因此,时间“零”将是 4 月 28 日晚上 8:00,即前一个交易日的星期五。这三天里发生了很多事情。4 月 28 日晚上 8:09,网络抓取返回了“零时”后的第一个标题:“特斯拉定价担忧导致降级潮”。不需要任何复杂的金融知识,你就可以立即做出预测,许多人会计划抛售 TSLA 股票,甚至在 5 月 1 日市场重新开放时做空该股票,因此,如果出现这种情况,该股票应该下跌周末唯一的新闻。但第二天4月29日凌晨5点30分,却传来这样的消息:“中国的‘完美电动车’是什么样子的?它必须聪明、方便,并且有耐力才能走完很远的路”。现在,我们有一个新闻叠在另一个新闻上。根据我有限的金融知识,最新的应该是积极的。这是因为“完美的电动汽车”虽然是中国制造,但应该惠及包括特斯拉在内的整个电动汽车行业。除了消极情绪之外,我们还有一点乐观情绪。总体而言,市场情绪仍应为负面。我们在评估方面开始遇到一些困难。随后第三则消息传出:《埃隆·马斯克特斯拉降价背后的微妙策略》。这个消息与特斯拉直接相关,似乎一切都被埃隆·马斯克控制住了,投资者无需担心。现在,让我问你,你对特斯拉股票的总体看法是什么?我想我可能会得到积极、中立或消极的回应。既然3条新闻的叠加变得如此主观和复杂,5月1日上午9点30分开盘前把全部26条新闻叠加起来怎么样?我们人类根本做不到,或者可能做到但无法给出一致的答案。
现在,gpt在这种情况下非常方便。它的表现优于人类,因为它会对一堆新闻给出一致的答案,基于此,我们可以使用它给出的情绪评分进行自由交易或训练人工智能算法。

本例中关于新闻的 ChatGPT 响应示例(图片由作者提供)

本例中关于新闻的 ChatGPT 响应示例(图片由作者提供)
为什么gpt可以对新闻情绪给出一致的答案,而人类却不能?
人类太主观了,因为我们的心理状态受到很多变量的影响,比如我们的情绪、饥饿信号、身体状态等等。相反,gpt一旦经过训练,在神经元连接中就有固定的权重。尽管可能存在可能引入一些不确定性的丢失层,但总的来说,在相同的输入和温度设置下,输出非常一致。
凭借gpt的推理能力,我们假设gpt在评估新闻堆栈方面可能比人类表现得更好。
这里我使用 ChatGPT 作为 LLM 的示例。通过适当的提示工程,我要求 ChatGPT 对连续新闻列表的输入进行评分,评分范围为 -10 到 10。负 10 表示极度负面,正 10 表示极度正面,零表示中性。一旦有新的标题出现,我就会反复致电 ChatGPT,并立即绘制出情绪得分与时间的关系图。正如您所看到的,整个周末的整体情绪评分仍然为负,因此,当您看到周一开盘后 TSLA 股票暴跌并希望您早点阅读这篇文章,这样您就不会感到惊讶了。利用gpt对新闻的情绪分析。
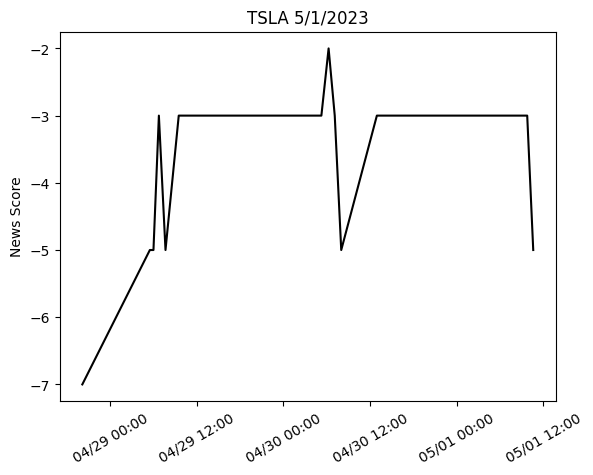
ChatGPT 给出的情绪评分与零时至 2023 年 5 月 1 日之间发布与 TSLA 相关的头条新闻的时间的可视化结果。评分始终为负
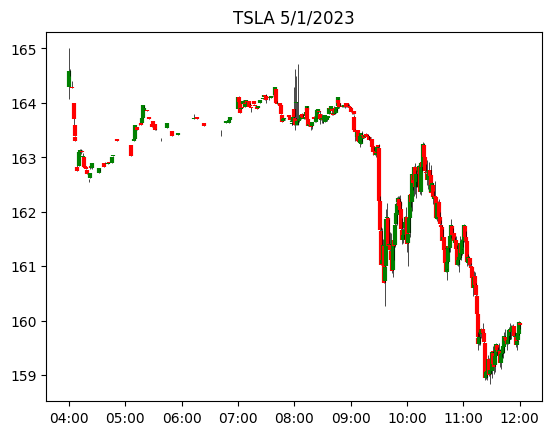
2023 年 5 月 1 日开盘时 TSLA 的市场反应。股价暴跌,这与上图中 ChatGPT 给出的持续负面新闻情绪评分一致
代码实现
我们使用 BeautifulSoup 作为网络抓取工具,使用 finviz.com 作为新闻网站。我们使用 finviz.com 作为新闻网站的原因是,它已被编程为包含股票代码下的所有相关行业新闻,这样我们就不需要四处搜索其他相关行业新闻。我无法评论他们的头条新闻发布的速度。然而,正如您在 Starship 示例中看到的那样,无论标题发布的速度有多快,它都已经晚了。在这个例子中,如果你盲目跟随新闻并做空股票,你将不得不在价格盘整区遭受一小时的痛苦。只要该项目能够建议您形成一种不按照情绪分数显示的情况进行交易的偏见,我就会说这是一个巨大的成功。
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from urllib.request import Request, urlopen
import datetime as dt
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import openai
import finnhub
openai.api_key = 'REPLACE THIS WITH YOUR KEY' # REPLACE WITH THIS YOUR KEY
finnhub_api_key = 'replace this with your key' # replace this with your key
ticker = 'TSLA'
res = Request(f'https://finviz.com/quote.ashx?t={ticker}&p=d', headers={'User-Agent': 'Safari/602.1'})
webpage = urlopen(res).read()
html = BeautifulSoup(webpage, "html.parser")
df = pd.read_html(str(html), attrs = {'class': 'fullview-news-outer'})[0]
df.columns = ['Date', 'Headline']
for i,r in df.iterrows():
if len(r.Date)<10:
r.Date = df.loc[i-1,'Date'].split(' ')[0] + ' ' + r.Date
df.Date = pd.to_datetime(df.Date)
current = dt.datetime.now()
if current.weekday() == 0:
start_time = dt.datetime.now()-dt.timedelta(days=3)
else:
start_time = dt.datetime.now()-dt.timedelta(days=1)
timestamp = dt.datetime(start_time.year,start_time.month,start_time.day,20,0,0)
latest = df[df.Date>timestamp].set_index('Date').sort_index(ascending=True)
latest
finviz.com 于 2023 年 5 月 1 日抓取 TSLA 时生成的“最新”数据框
我更喜欢使用 Finnhub 检索包含上市前数据的实时财务数据。您可以在https://finnhub.io申请免费的 API 密钥。
由于我使用 OpenAI 的 ChatGPT 作为 LLM,为了重现我在本文中演示的内容,您可以通过https://platform.openai.com/account/api-keys向 OpenAI 请求 API 密钥。
ChatGPT 需要进行适当的提示设计,以便为我们提供理想的情绪分数输出。随着gpt的快速发展,即时工程是一个新兴领域。DeepLearning.AI 开发了关于 ChatGPT 即时工程的免费短期课程,由 Andrew Ng 教授授课。链接是https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/。我花了大约一个小时左右的时间才完成了短期课程。我强烈建议您也参加该课程,以便您可以开发自己的提示,这些提示比我在这里演示的更有创意。
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # this is the degree of randomness of the model's output
)
# print(str(response.choices[0].message))
return response.choices[0].message["content"]
headline = latest.Headline.iloc[0]
messages = [
{'role':'system', 'content':'You are an analyst of the stock market. Given the headlines of a stock, you rate the overall sentiment of the stock in an integer score between -10 and 10. -10 means very negative. 0 means neutral, 10 means very positive.'},
{'role':'user', 'content':headline} ]
response = get_completion_from_messages(messages, temperature=0)
print(headline)
print(response)
我在这里所做的事情非常简单。我在 ChatGPT 耳边低声说道:“你是股市分析师。给定股票的头条新闻,您可以用 -10 到 10 之间的整数来评价该股票的整体情绪。-10 表示非常负面。0 表示中立,10 表示非常积极。” 我将 ChatGPT 的温度设置为零,这意味着输出更可预测。如果将温度设置为更接近 1,输出将会更有创意。由于我需要的是一致性,所以这条路线不是我想要的。当然,在最终确定这样的代码之前,我已经做了一些实验来探索输出是什么。如果您提出自己的提示,您也应该这样做。输出对我来说看起来非常合理。
x = latest.index.to_numpy()
y = np.zeros(len(x))
headlines = ''
for i in range(len(latest)):
headlines = headlines + latest.Headline.iloc[i] + '; '
messages = [
{'role':'system', 'content':'You are an analyst of the stock market. Given the headlines of a stock delimited by \;, you rate the overall sentiment of the stock in an integer score between -10 and 10. -10 means very negative. 0 means neutral, 10 means very positive. Limit your answer to one number. '},
{'role':'user', 'content':headlines},
]
response = get_completion_from_messages(messages, temperature=0)
if len(str(response))>3:
score = 0
else:
score = int(response)
y[i] = score
plt.plot(x,y,'k-')
dtFmt = mdates.DateFormatter('%m/%d %H:%M')
plt.gca().xaxis.set_major_formatter(dtFmt)
plt.ylabel('News Score')
plt.tick_params(axis='x', rotation=30)
plt.title('TSLA 5/1/2023')
plt.show()我记录了输出并绘制了分数与时间的关系图。
上一个代码块的输出(作者提供的图片)
由于整体新闻情绪持续负面,我们可能将其与该股 2023 年 5 月 1 日的下跌趋势联系起来。
ticker = 'TSLA'
start = dt.datetime(2023,5,1,0,0,0)
end = dt.datetime(2023,5,1,12,0,0)
def get_1m_data(ticker,start,end,finnhub_api_key):
finnhub_client = finnhub.Client(api_key=finnhub_api_key)
res = finnhub_client.stock_candles(ticker, '1', int(start.timestamp()), int(end.timestamp()))
df = pd.DataFrame(res)
df['t'] = [dt.datetime.fromtimestamp(df['t'][ind]) for ind,_ in df.iterrows()]
df.set_index('t',inplace=True)
df = df[['o','h','l','c','v']]
return df
df = get_1m_data(ticker,start,end,finnhub_api_key)
for ind in df.index:
plt.vlines(x = ind, ymin = df.loc[ind,'l'], ymax = df.loc[ind,'h'], color = 'black', linewidth = 0.5)
if df.loc[ind,'o'] > df.loc[ind,'c']:
plt.vlines(x = ind, ymin = df.loc[ind,'c'], ymax = df.loc[ind,'o'], color = 'red', linewidth = 3)
elif df.loc[ind,'o'] < df.loc[ind,'c']:
plt.vlines(x = ind, ymin = df.loc[ind,'o'], ymax = df.loc[ind,'c'], color = 'green', linewidth = 3)
else:
plt.vlines(x = ind, ymin = df.loc[ind,'o'], ymax = df.loc[ind,'c'], color = 'black', linewidth = 3)
dtFmt = mdates.DateFormatter('%H:%M')
plt.gca().xaxis.set_major_formatter(dtFmt)
plt.title('TSLA 5/1/2023')
plt.show()
上一个代码块的输出
请注意,在此演示中,我并没有尝试重复从 finviz.com 抓取数据并无休止地运行 ChatGPT。这是因为如果您查询过于频繁,我担心 finviz.com 可能会禁止您的 IP,并且出于同样的原因使用 ChatGPT 可能会产生费用。因此,使用上述代码编写循环时要小心。
结束语
将网络抓取和gpt相结合进行新闻监控和情绪分析可以使个人在股市实时交易时成为消息灵通的人。本文展示了如何使用 BeautifulSoup 和 ChatGPT 来完成此操作。请记住,消息灵通并不一定意味着能够盈利,正如您从 Starship 的例子中可以看出的那样。交易技巧和心理打磨对于应对压力和风险仍然至关重要。这就是为什么有些日内交易者根本不根据新闻进行交易的原因。相反,他们试图对新闻一无所知,以免形成偏见,以便他们能够严格根据市场情绪进行交易。