。。。。。。。。。。。。。。。。。。。。。。
1.网页请求一下内容
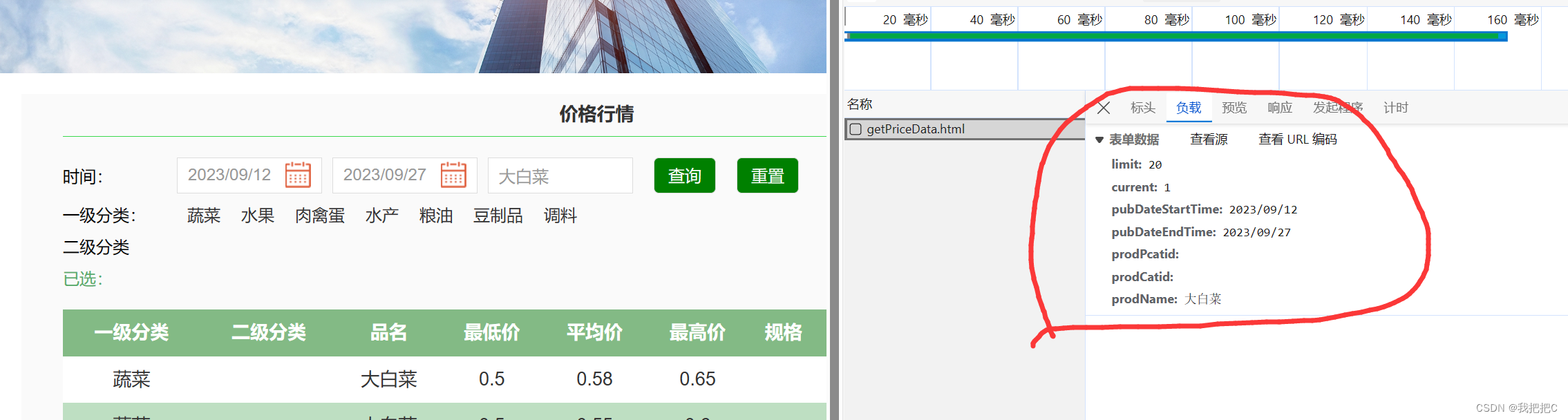
通过抓包我们发现一共七个参数
limit: 20 # 一页多少数据
current: 1 #第几页
pubDateStartTime: 2023/09/12 # 开始时间
pubDateEndTime: 2023/09/27 #结束时间
prodPcatid:
prodCatid:
prodName: 大白菜 #名称
2.通过爬虫进行请求
首先我们获取十五天里这个货物一共有多少件
#name是由商品名-规格-产地组合而成
def xlx(name): #用来获取名字为name的商品十五天内该货物共有多少条数据
#name='白虾(精品)-21到24头并且活-'
data = {
'limit': '1',
'current': '1',
'pubDateStartTime': f'{
s15}',#自定义的时间
'pubDateEndTime': f'{
end}',#自定义的时间
'prodPcatid': '',
'prodCatid': '',
'prodName': name.split('-')[0],
}
count=requests.post(url, data=data).json()['count']
p(name,count)#将名称和数量传入p函数
3.获取商品十五天详细数据并绘制折线图
def p(name,count):
data = {
'limit': f'{
count}',
'current': '1',
'pubDateStartTime': f'{
s15}',
'pubDateEndTime': f'{
end}',
'prodPcatid': '',
'prodCatid': '',
'prodName': '',
}
data['prodName']=name.split('-')[0]
res=requests.post(url='http://www.xinfadi.com.cn/getPriceData.html',data=data).json()
class_=res['list'][0]['prodCat']
res=res['list']
pricelow=[]
pricemax=[]
time_list=[]
for i in res:
if i['prodName']==name.split('-')[0]:
#sg=i['specInfo']
s = i['specInfo'].replace('<', '小于')#对字符串进行处理替换特殊字符
s = s.replace('>', '大于')
s = s.replace('/', '并且')
s = s.replace('-', '到')
s = s.replace('\\', '或者')
if s==name.split('-')[1]:
#画图
if i['place']==name.split('-')[2]:
pricemax.append(i['highPrice'])
pricelow.append(i['lowPrice'])
n=str(i['pubDate']).split(' ')[0].split('-')[1:]
time_list.append(n[0]+'.'+n[1])
pricelow.reverse()
pricemax.reverse()
time_list.reverse()
print(name)
plt.figure(figsize=(20, 10), dpi=100)
plt.plot(time_list, pricelow)
plt.savefig(fr'./类别/{
class_}/价格趋势图/{
name}.jpg')
plt.close()
with open(f'./类别/{
class_}/价格文档/{
name}.txt', 'w') as fp:
fp.write(' '.join(time_list)+'\n'+' '.join(pricemax)+'\n'+' '.join(pricelow))
time.sleep(1)
4.项目详细代码
import matplotlib
import requests
import datetime
from multiprocessing.dummy import Pool
from matplotlib import pyplot as plt
import os
import shutil
import time
matplotlib.use('agg')
def RemoveDir(filepath): #用来删除文件夹中的所有内容
'''
如果文件夹不存在就创建,如果文件存在就清空!
'''
if not os.path.exists(filepath):
os.mkdir(filepath)
else:
shutil.rmtree(filepath)
os.mkdir(filepath)
def count(url,data):
res = requests.post(url, data=data)
num = res.json()['count']
return num
def xlx(name): #用来获取名字为name的商品十五天内该货物共有多少条数据
#name='白虾(精品)-21到24头并且活-'
data = {
'limit': '1',
'current': '1',
'pubDateStartTime': f'{
s15}',
'pubDateEndTime': f'{
end}',
'prodPcatid': '',
'prodCatid': '',
'prodName': name.split('-')[0],
}
count=requests.post(url, data=data).json()['count']
p(name,count)
#print(name)
#print(count)#将名称和数据的数量传给p函数
def p(name,count):
data = {
'limit': f'{
count}',
'current': '1',
'pubDateStartTime': f'{
s15}',
'pubDateEndTime': f'{
end}',
'prodPcatid': '',
'prodCatid': '',
'prodName': '',
}
data['prodName']=name.split('-')[0]
res=requests.post(url='http://www.xinfadi.com.cn/getPriceData.html',data=data).json()
class_=res['list'][0]['prodCat']
res=res['list']
pricelow=[]
pricemax=[]
time_list=[]
for i in res:
if i['prodName']==name.split('-')[0]:
#sg=i['specInfo']
s = i['specInfo'].replace('<', '小于')
s = s.replace('>', '大于')
s = s.replace('/', '并且')
s = s.replace('-', '到')
s = s.replace('\\', '或者')
if s==name.split('-')[1]:
if i['place']==name.split('-')[2]:
pricemax.append(i['highPrice'])
pricelow.append(i['lowPrice'])
n=str(i['pubDate']).split(' ')[0].split('-')[1:]
time_list.append(n[0]+'.'+n[1])
pricelow.reverse()
pricemax.reverse()
time_list.reverse()
print(name)
plt.figure(figsize=(20, 10), dpi=100)
plt.plot(time_list, pricelow)
plt.savefig(fr'./类别/{
class_}/价格趋势图/{
name}.jpg')
plt.close()
with open(f'./类别/{
class_}/价格文档/{
name}.txt', 'w') as fp:
fp.write(' '.join(time_list)+'\n'+' '.join(pricemax)+'\n'+' '.join(pricelow))
time.sleep(1)
def filetxt(filename):
namelist=[]
file = open(filename, "r", encoding="GBK")
file = file.readlines()
for line in file:
line = line.strip('\n')
namelist.append(line)
return namelist
class_list=['水产','水果','粮油','肉禽蛋','蔬菜','调料','豆制品'] #所有的主类别
for i in class_list: #重置类别文件
with open(f'./类别/{
i}/今日类别.txt', 'w') as fp:
fp.write('')
RemoveDir(f'./类别/{
i}/价格文档')
RemoveDir(f'./类别/{
i}/价格趋势图')
url='http://www.xinfadi.com.cn/getPriceData.html' #主页面url
today = datetime.date.today() #获取当前日期
yesterday = str(today - datetime.timedelta(days=1)) #获取今天往前十五天的日期 吧
s15=str(today - datetime.timedelta(days=15))
today=str(today)
enddata_list=today.split('-')
start_list=yesterday.split('-') #去掉日期后面的时分秒
s15=s15.split('-')
end=enddata_list[0]+'/'+enddata_list[1]+'/'+enddata_list[2]#将日期格式转换为我们data需要的格式
start=start_list[0]+'/'+start_list[1]+'/'+start_list[2]
s15=s15[0]+'/'+s15[1]+'/'+s15[2]
data={
'limit': '1',
'current': '1',
'pubDateStartTime': start,
'pubDateEndTime': end,
'prodPcatid':'' ,
'prodCatid': '',
'prodName':'' ,
} #获取当天所有交易货物的data
res = requests.post(url, data=data) #发送post请求
#提取出共有多少种货物
data['limit']=res.json()['count'] #将data中的limit设置为货物总数就可以一次请求全部获取
res=requests.post(url,data=data).json() #获取到当天所有货物的产地型号等详细数据
data=res['list']
for i in data: #循环便利每一种货物
prodCat=i['prodCat']#提取出当前货物的类别
s=i['specInfo'].replace('<','小于')
s=s.replace('>','大于')
s=s.replace('/','并且')
s = s.replace('-', '到')
s = s.replace('\\', '或者')
name=i['prodName']+'-'+s+'-'+i['place'] #将货物的名字定为 物品名-型号-产地
with open(f'./类别/{
prodCat}/今日类别.txt', 'a+') as fp: #按照类别将其保存到所属的主类文件夹中
fp.write(name+'\n') #写入数据每个数据一行
for i in class_list: #循环所有主类取出其中所有的货物名称
filename=f'./类别/{
i}/今日类别.txt'
name_list=filetxt(filename)
if name_list!=[]:
#判断是否为空
pool = Pool(3) #开启线程池
# 定义循环数
origin_num = [x for x in name_list] #每一个货物开启一个线程
# 利用map让线程池中的所有线程‘同时’执行calc_power2函数
pool.map(xlx, origin_num)