文章目录
一、List 类型介绍
list 列表类型是用来存储多个有序的字符串,列表中的每个字符串称为元素(element),一个列表最多可以存储 2^32 - 1 个元素。在 Redis 中,可以对列表两端插人(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是⼀种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。
列表两端插入和弹出操作:

列表的获取、删除等操作:

列表类型的特点:
- 列表中的元素是有序的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表;
- 区分获取和删除的区别,例上图 中的
lrem 1 b是从列表中把从左数遇到的前 1 个 b 元素删除,这个操作会导致列表的长度从 5 变成 4;但是执行lindex 4只会获取元素,但列表长度不会变化。 - 列表中的元素是允许重复的,例如下图中的列表中是包含了两个 a 元素的。

二、List 类型相关命令
2.1 LPUSH 和 RPUSH、LPUSHX 和 RPUSHX
LPUSH和RPUSH
LPUSH 命令的作用是将一个或多个元素从左侧(头插)插入到 list 中;而 RPUSH 命令的作用则是将一个或多个元素从右侧(尾插)插入到 list 中。
语法:
LPUSH key element [element ...]
RPUSH key element [element ...]
LPUSHX和RPUSHX
LPUSHX 命令的作用是当 key 存在时,将⼀个或者多个元素从左侧放⼊(头插)到 list 中,不存在则直接返回;而 RPUSHX 命令的作用是是当 key 存在时,将⼀个或者多个元素从右侧放⼊(头插)到 list 中,不存在则直接返回。
语法:
LPUSHX key element [element ...]
RPUSHX key element [element ...]
2.2 LPOP 和 RPOP、BLPOP 和 BRPOP
LPOP和RPOP
LPOP 命令的作用是从左侧删除一个元素(头删),并返回删除的值;而 RPOP 则是从右侧删除(尾删),然后返回删除的值。
语法:
LPOP key
RPOP key
BLPOP和BRPOP
BLPOP 和 BRPOP 命令的作用和LPOP 、 RPOP 一样,只是需要指定一个超时时间,如果没有元素可以删除的时候,会进行阻塞,如果在设定的超时时间内向 Redis 中插入元素,则会立即执行;否则超时则之间退出。
语法:
BLPOP key [key ...] timeout
BRPOP key [key ...] timeout
另外,BLPOP 和 BRPOP 可以同时指定多个 key 进行删除。
2.3 LRANGE、LINDEX、LINSERT、LLEN
LRANGE
LRANGE命令的作用是获取从 start 到 stop 区间的所有元素,区间左闭右闭,并且指定的位置可以是负数,表示倒数第几个。
语法:
LRANGE key start stop
LINDEX
LINDEX 命令的作用是获取从左边开始第 index 位置的元素。
语法:
LINDEX key index
LINSERT
LINSERT 命令的作用是在特定的位置插入元素。
语法:
LINSERT key BEFORE|AFTER pivot element
说明:
BEFORE表示插入到 pivot 元素之前;AFTER表示插入到 pivot 元素之后。
LLEN
LLEN 命令的作用是 获取 list 长度。
语法:
LLEN key
2.4 列表相关命令总结
以下是关于 Redis List 相关命令的总结,包括命令、作用以及时间复杂度:
| 命令 | 作用 | 时间复杂度 |
|---|---|---|
LPUSH |
从列表左侧插入一个或多个元素 | O(N) (N 为插入元素数量) |
RPUSH |
从列表右侧插入一个或多个元素 | O(N) (N 为插入元素数量) |
LPUSHX |
如果列表存在,从左侧插入一个或多个元素,否则不执行操作 | O(1) |
RPUSHX |
如果列表存在,从右侧插入一个或多个元素,否则不执行操作 | O(1) |
LPOP |
从列表左侧删除并返回一个元素 | O(1) |
RPOP |
从列表右侧删除并返回一个元素 | O(1) |
BLPOP |
从左侧删除并返回元素,如果列表为空则阻塞,带有超时参数 | O(1) 或阻塞等待 |
BRPOP |
从右侧删除并返回元素,如果列表为空则阻塞,带有超时参数 | O(1) 或阻塞等待 |
LRANGE |
获取指定范围内的元素列表 | O(Slice Size) |
LINDEX |
获取指定位置的元素 | O(N) (N 为索引位置) |
LINSERT |
在指定元素前或后插入新元素 | O(N) (N 为列表长度) |
LLEN |
获取列表的长度 | O(1) |
注意:时间复杂度中的 “N” 表示操作的复杂度与列表的长度或插入元素的数量成线性关系,而不是固定的常数时间。在实际使用中,需要根据数据规模和性能要求选择适当的命令。
三、List 类型内部编码
Redis 中的 List 数据类型在内部可以使用不同的编码方式来存储数据,具体的编码方式取决于列表的大小和元素的大小。下面将介绍两种常见的 List 内部编码方式:
3.1 压缩列表(ziplist)
压缩列表(ziplist)是 Redis 中一种紧凑的、内存优化的列表编码方式,适用于存储较小的列表,或者列表中的元素都是较小的整数或字符串。压缩列表以连续的内存块的形式存储数据,每个节点可以包含一个或多个元素,这使得压缩列表在内存使用效率上有一定优势。
特点:
- 压缩列表可以保存多个元素在一个节点中,因此在元素较小的情况下,它可以节省内存。
- 压缩列表支持快速的元素访问,因为可以通过索引直接访问元素。
- 压缩列表适用于列表较小且元素较小的情况。
3.2 链表(linkedlist)
链表(linkedlist)是 Redis 中另一种列表的内部编码方式,它更适合存储大型列表或者元素大小不一致的列表。链表中的每个节点包含一个元素以及指向前一个节点和后一个节点的指针,这种结构使得链表在插入和删除元素时具有较高的效率。
特点:
- 链表适用于列表较大或元素较大的情况,因为它不需要连续的内存块,可以更好地处理大型数据。
- 链表对于插入和删除元素的操作更加高效,因为只需要调整节点的指针而不需要移动大量数据。
- 链表相对于压缩列表占用更多的内存,因为需要额外的指针来维护节点之间的链接。
总之,Redis 根据列表的大小和元素的大小自动选择使用压缩列表或链表来进行编码,以平衡内存使用和操作效率。在选择数据结构和命令时,需要考虑数据的规模和操作的性能需求。
示例:
1)当元素个数较少且没有大元素时,内部编码为 ziplist:
127.0.0.1:6379> rpush listkey e1 e2 e3
OK
127.0.0.1:6379> object encoding listkey
"ziplist"
2)当元素个数超过 512 时,内部编码为 linkedlist:
127.0.0.1:6379> rpush listkey e1 e2 e3 ... 省略 e512 e513
OK
127.0.0.1:6379> object encoding listkey
"linkedlist"
3)当某个元素的长度超过 64 字节时,内部编码为 linkedlist:
127.0.0.1:6379> rpush listkey "one string is bigger than 64 bytes ... 省略 ..."
OK
127.0.0.1:6379> object encoding listkey
"linkedlist"
四、List 类型的应用场景
4.1 消息队列
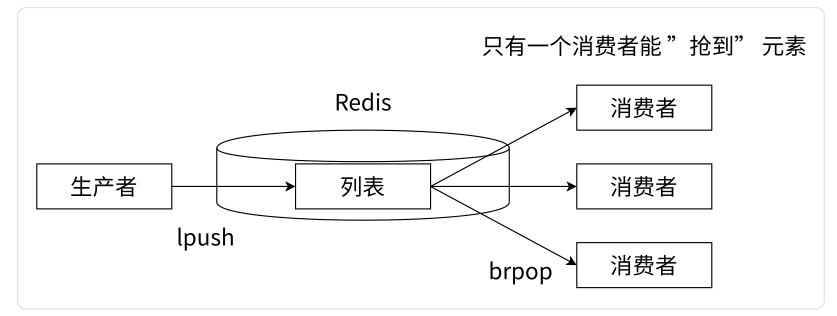
Redis 可以使用 lpush + brpop 命令组合实现经典的阻塞式生产者-消费者模型队列,生产者客户端使用 lpush 从列表左侧插入元素,多个消费者客户端使用 brpop命令阻塞式地从队列中 “争抢” 队首元素。通过多个客户端来保证消费的负载均衡和高可用性。
Redis 阻塞消息队列模型:
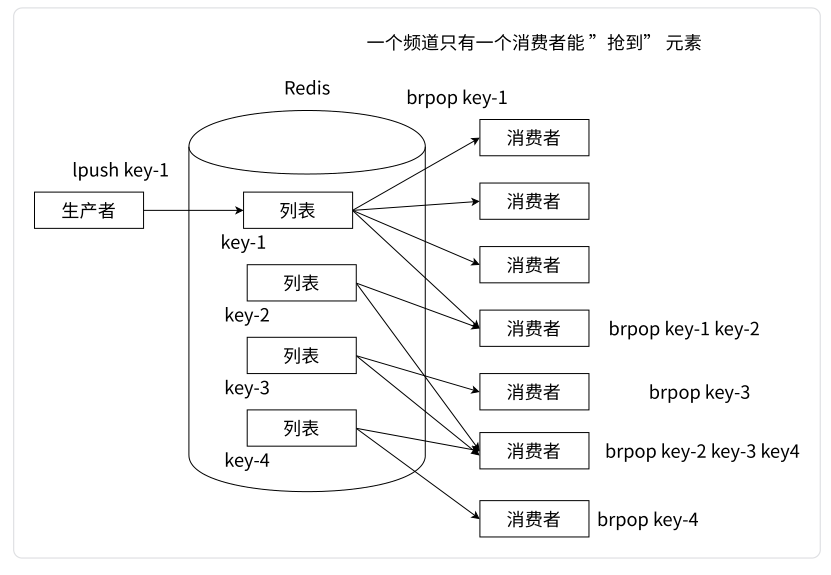
分频道的消息队列:
Redis 可以同样使用 lpush + brpop 命令,但通过不同的键模拟频道的概念,不同的消费者可以通过 brpop 不同的键值,实现订阅不同频道的理念。
4.2 微博列表
每个用户都有属于自己的微博列表 ,现需要分页展示文章列表。此时可以考虑使用列表类型,因为列表不但是有序的,同时支持按照索引范围获取元素。
1)每篇微博使用哈希结构存储,例如微博中 3 个属性:title、timestamp、content:
hmset mblog:1 title xx timestamp 1476536196 content xxxxx
...
hmset mblog:n title xx timestamp 1476536196 content xxxxx
2)向用户 的微博列表中添加微博,使用 user:<uid>:mblogs 作为微博的键:
lpush user:1:mblogs mblog:1 mblog:3
...
lpush user:k:mblogs mblog:9
3)分页获取用户的微博列表,例如获取用户1 的前 10 篇微博:
keylist = lrange user:1:mblogs 0 9
for key in keylist {
hgetall key
}
此外,此方案在实际中可能存在两个问题:
- 1 + n 问题。即如果每次分页获取的微博个数较多,需要执行多次
hgetall操作,此时可以考虑使用pipeline(流水线)模式批量提交命令,或者微博不采用哈希类型,而是使用序列化的字符串类型,使用 mget 获取。 - 分页获取文章时,
lrange在列表两端表现较好,获取列表中间的元素表现较差,此时可以考虑将列表做拆分。