-
-
-
2.1 SVM算法简介
学习目标
- 了解SVM算法的定义
- 知道软间隔和硬间隔
1 SVM算法导入
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:
“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
于是大侠这样放,干的不错?
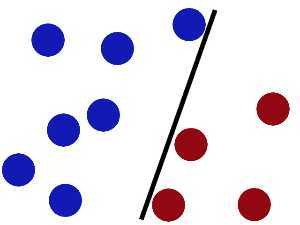
然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
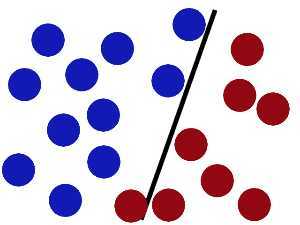
怎么办??
把分解的小棍儿变粗。
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
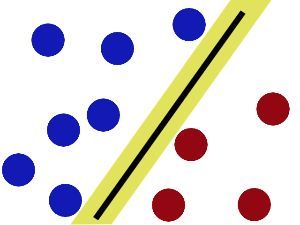
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。
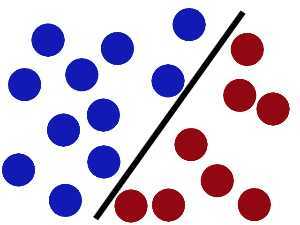
然后,在SVM 工具箱中有另一个更加重要的技巧( trick)。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。
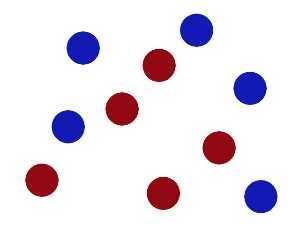
现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?
当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
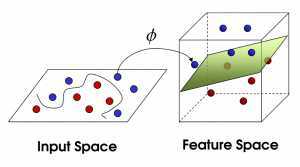
再之后,无聊的大人们,把上面的物体起了别名:
球—— 「data」数据
棍子—— 「classifier」分类
最大间隙——「optimization」最优化
拍桌子——「kernelling」核方法
纸——「hyperplane」超平面
2 SVM算法定义
2.1 定义
SVM:SVM全称是supported vector machine(支持向量机),即寻找到一个超平面使样本分成两类,并且间隔最大。
SVM能够执行线性或非线性分类、回归,甚至是异常值检测任务。它是机器学习领域最受欢迎的模型之一。SVM特别适用于中小型复杂数据集的分类。
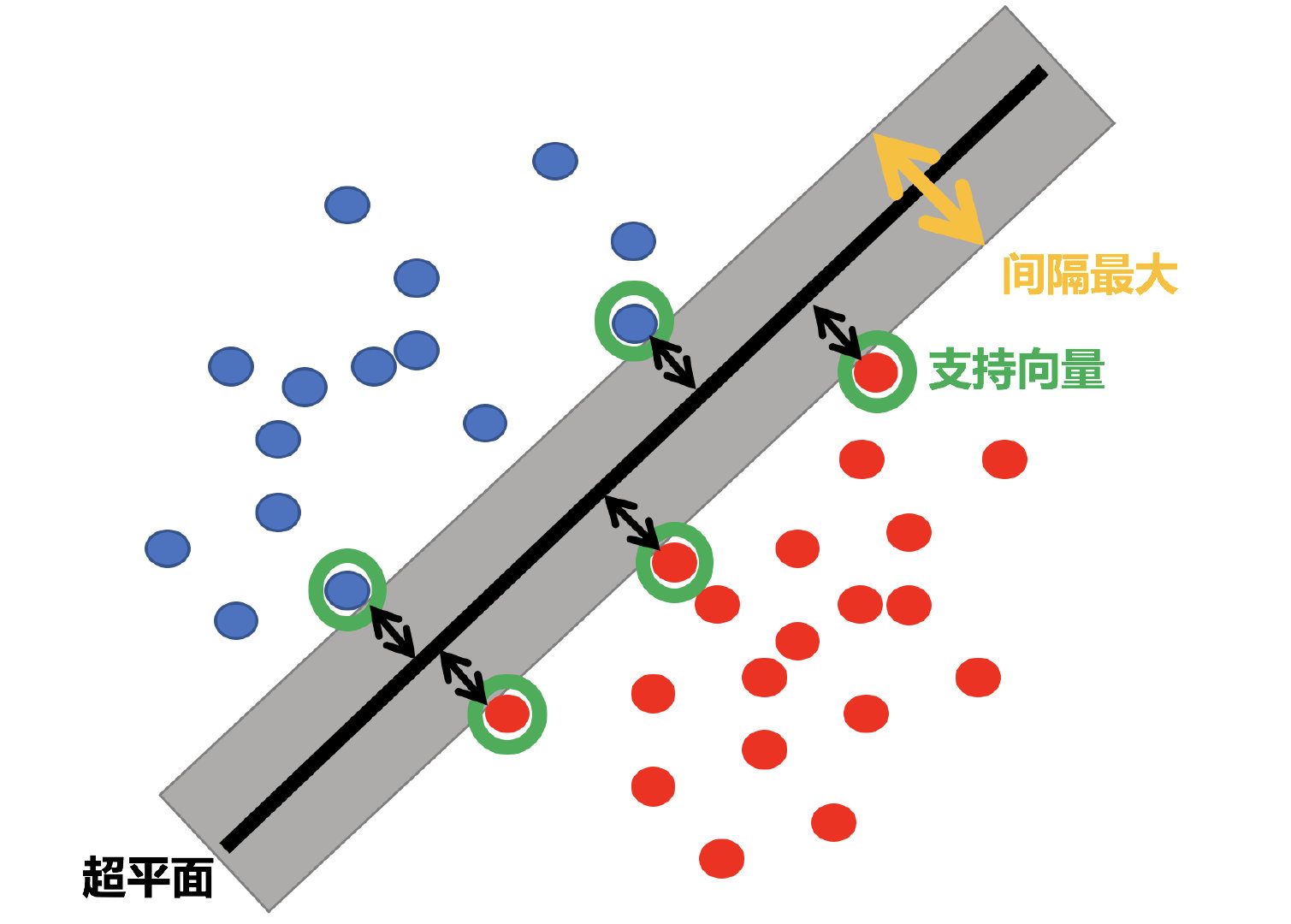
2.2 超平面最大间隔介绍
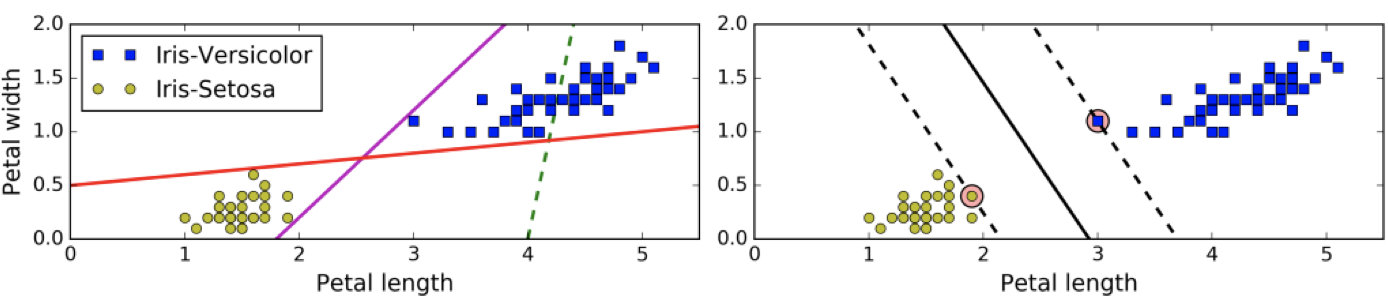
上左图显示了三种可能的线性分类器的决策边界:
虚线所代表的模型表现非常糟糕,甚至都无法正确实现分类。其余两个模型在这个训练集上表现堪称完美,但是它们的决策边界与实例过于接近,导致在面对新实例时,表现可能不会太好。
右图中的实线代表SVM分类器的决策边界,不仅分离了两个类别,且尽可能远离最近的训练实例。
2.3 硬间隔和软间隔
2.3.1 硬间隔分类
在上面我们使用超平面进行分割数据的过程中,如果我们严格地让所有实例都不在最大间隔之间,并且位于正确的一边,这就是硬间隔分类。
硬间隔分类有两个问题,首先,它只在数据是线性可分离的时候才有效;其次,它对异常值非常敏感。
当有一个额外异常值的鸢尾花数据:左图的数据根本找不出硬间隔,而右图最终显示的决策边界与我们之前所看到的无异常值时的决策边界也大不相同,可能无法很好地泛化。
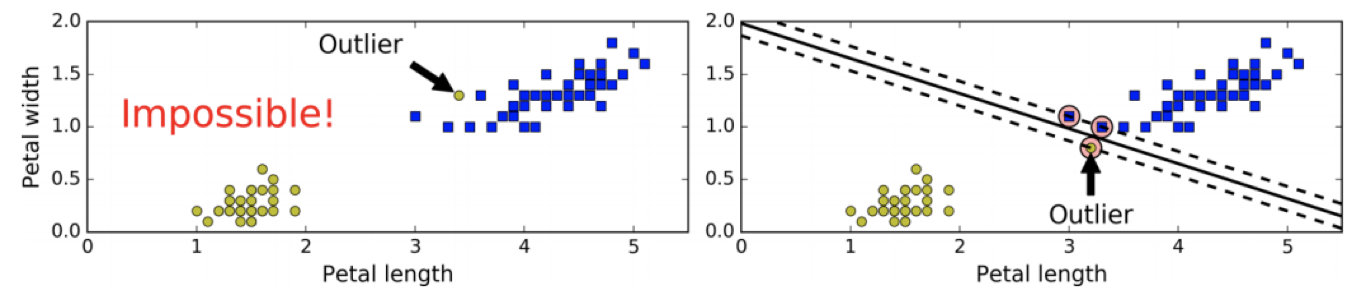
2.3.2 软间隔分类
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持最大间隔和不错误分类数据之间找到良好的平衡,这就是软间隔分类。
3 小结
- SVM算法定义【了解】
- 寻找到一个超平面使样本分成两类,并且间隔最大。
- 硬间隔和软间隔【知道】
- 硬间隔
- 只有在数据是线性可分离的时候才有效
- 对异常值非常敏感
- 软间隔
- 目标是尽可能在保持最大间隔和不错误分类数据之间找到良好的平衡
- 硬间隔
-
-
2.2 SVM算法api初步使用
学习目标
- 知道SVM算法API的用法
- SVC (Support Vector Classifier) ,svm模型用于分类时的名字
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
在拟合后, 这个模型可以用来预测新的值:
clf.predict([[2., 2.]])
2.3 SVM算法原理
学习目标
- 知道SVM中线性可分支持向量机
- 知道SVM中目标函数的推导过程
1 定义输入数据
假设给定一个特征空间上的训练集为:
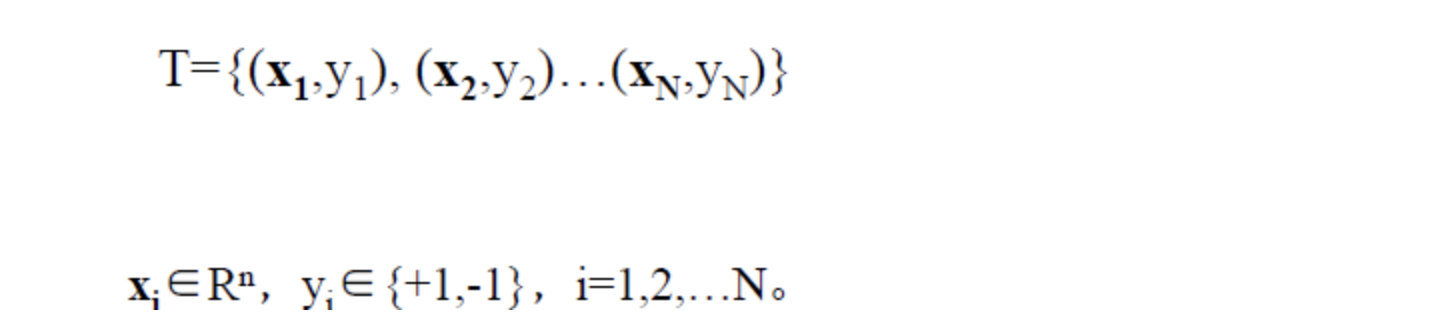
其中, ( x i , y i ) (x_i,y_i) (xi,yi)称为样本点。
- x i x_i xi为第i个实例(样本),
- y i y_i yi为 x i x_i xi的标记(标签):
- 当 y i = 1 y_i=1 yi=1时, x i x_i xi为正例
- 当 y i = − 1 y_i=-1 yi=−1时, x i x_i xi为负例
至于为什么正负用(-1,1)表示呢?
这里这样标记是为了简化运算
2 线性可分支持向量机
给定了上面提出的线性可分训练数据集,通过间隔最大化得到分离超平面为 : y ( x ) = w T Φ ( x ) + b y(x)=w^T\Phi(x)+b y(x)=wTΦ(x)+b
相应的分类决策函数为: f ( x ) = s i g n ( w T Φ ( x ) + b ) f(x)=sign(w^T\Phi(x)+b) f(x)=sign(wTΦ(x)+b)
以上决策函数就称为线性可分支持向量机。
这里解释一下 Φ ( x ) \Phi(x) Φ(x)这个东东。
这是某个确定的特征空间转换函数,它的作用是将x映射到更高的维度,它有一个以后我们经常会见到的专有称号**”核函数“**。
比如我们看到的特征有2个:
x1,x2组成最先见到的线性函数可以是 w 1 x 1 + w 2 x 2 w_1x_1+w_2x_2 w1x1+w2x2
但也许这两个特征并不能很好地描述数据(只有这两个特征我们无法把数据分开),于是我们进行维度的转化,变成了 w 1 x 1 + w 2 x 2 + w 3 x 1 x 2 + w 4 x 1 2 + w 5 x 2 2 w_1x_1+w_2x_2+w_3x_1x_2+w_4x_1^2+w_5x_2^2 w1x1+w2x2+w3x1x2+w4x12+w5x22
于是我们多了三个特征。而这个就是笼统地描述x的映射的。
最简单直接映射的就是: Φ ( x ) = x \Phi(x)=x Φ(x)=x
以上就是线性可分支持向量机的模型表达式。我们要去求出这样一个模型,或者说这样一个超平面y(x),它能够最优地分离两个集合。
其实也就是我们要去求一组参数(w,b),使其构建的超平面函数能够最优地分离两个集合。
如下就是一个最优超平面:
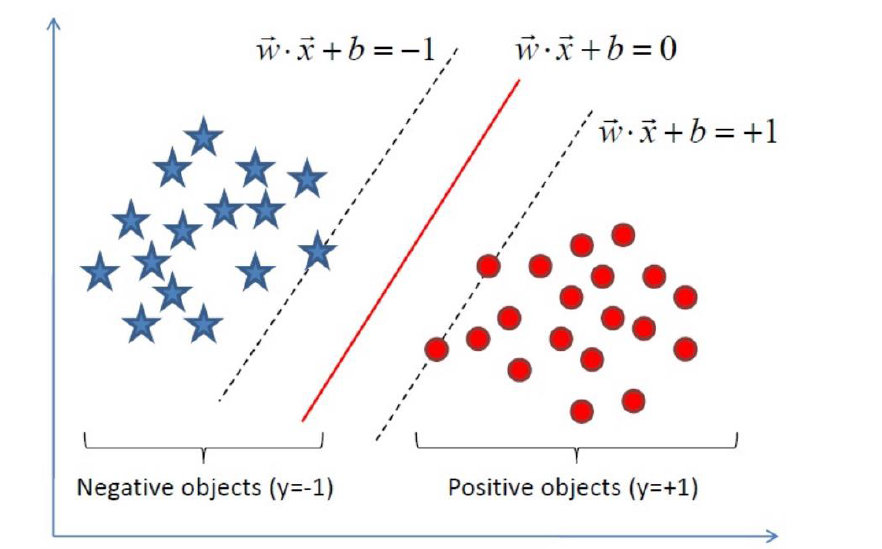
有同学可能认为实线wx+b=0时,虚线不一定是wx+b=±1?
3 SVM的计算过程与算法步骤
3.1 推导目标函数
我们知道了支持向量机是个什么东西了。现在我们要去寻找这个支持向量机,也就是寻找一个最优的超平面。
于是我们要建立一个目标函数。那么如何建立呢?
再来看一下我们的超平面表达式: y ( x ) = w T Φ ( x ) + b y(x)=w^T\Phi(x)+b y(x)=wTΦ(x)+b
为了方便我们让: Φ ( x ) = x \Phi(x)=x Φ(x)=x
则在样本空间中,划分超平面可通过如下线性方程来描述: w T x + b = 0 w^Tx+b=0 wTx+b=0
样本空间中任意点x到超平面(w,b)的距离可写成
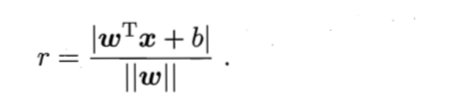
假设超平面(w, b)能将训练样本正确分类,则对于 ( x i , y i ) ∈ D (x_i, y_i)\in D (xi,yi)∈D
- 若 y i = + 1 y_i=+1 yi=+1,则有 w T x i + b > 0 w^Tx_i+b>0 wTxi+b>0
- 若 y i = − 1 y_i=-1 yi=−1,则有 w T x i + b < 0 w^Tx_i+b<0 wTxi+b<0
令
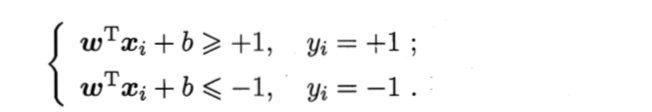
如图所示,距离超平面最近的几个训练样本点使上式等号成立,他们被称为“支持向量",
两个异类支持向量到超平面的距离之和为: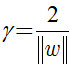 ;
;
它被称为“”间隔“”。
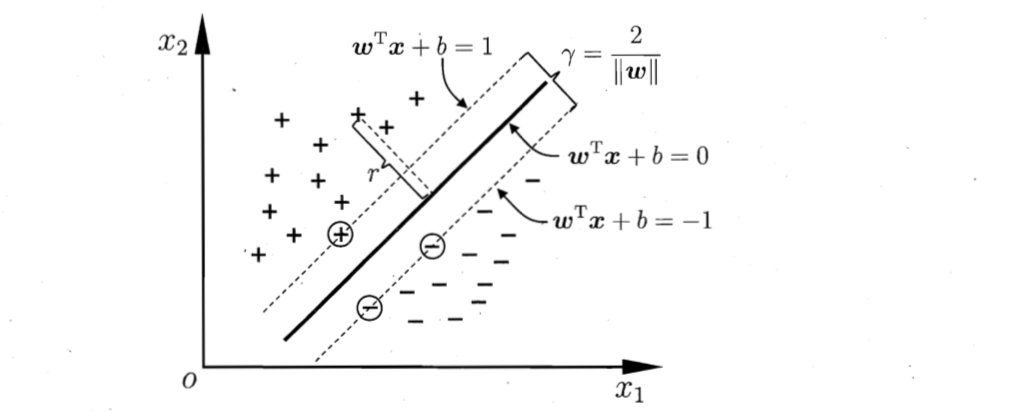
欲找到具有最大间隔的划分超平面,也就是要找到能满足下式中约束的参数w和b,使得 γ \gamma γ最大。
即:
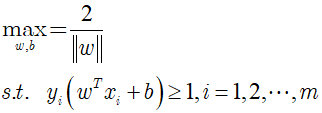
显然,为了最大化间隔,仅需要最大化[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hS2Qaf0z-1668817748533)(https://yuchen-1313787112.cos.ap-nanjing.myqcloud.com/20180607123253872)],这等价于最小化[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M5LUNU9o-1668817748534)(https://yuchen-1313787112.cos.ap-nanjing.myqcloud.com/20180607123313992)]。于是上式可以重写为:
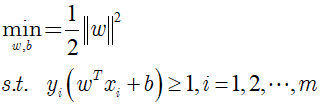
这就是支持向量机的基本型。
3.2 目标函数的求解(了解)
到这一步,终于把目标函数给建立起来了。
那么下一步自然是去求目标函数的最优值.
因为目标函数带有一个约束条件,所以我们可以用拉格朗日乘子法求解。
3.2.1 朗格朗日乘子法
啥是拉格朗日乘子法呢?
拉格朗日乘子法 (Lagrange multipliers)是一种寻找多元函数在一组约束下的极值的方法.
通过引入拉格朗日乘子,可将有 d 个变量与 k 个约束条件的最优化问题转化为具有 d + k 个变量的无约束优化问题求解。
经过朗格朗日乘子法,我们可以把目标函数转换为:
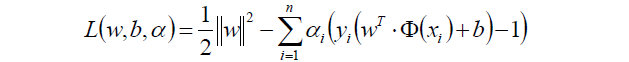
其中,上式后半部分:
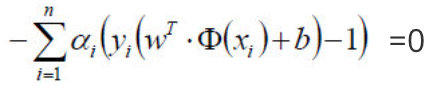
走到这一步,这个目标函数还是不能开始求解,现在我们的问题是极小极大值问题
3.2.2 对偶问题
我们要将其转换为对偶问题,变成极大极小值问题:
从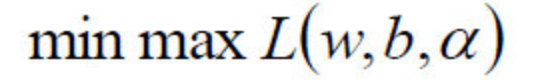 变为:
变为: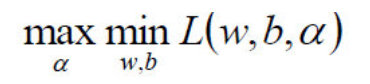
如何获取对偶函数?
-
首先我们对原目标函数的w和b分别求导:
- 原目标函数:
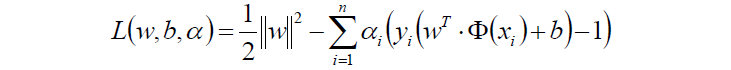
- 对w求偏导:
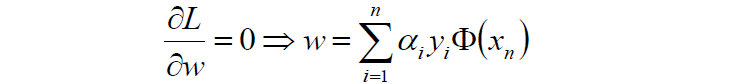
- 对b求偏导:
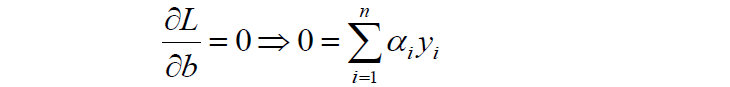
- 原目标函数:
-
然后将以上w和b的求导函数重新代入原目标函数的w和b中,得到的就是原函数的对偶函数:
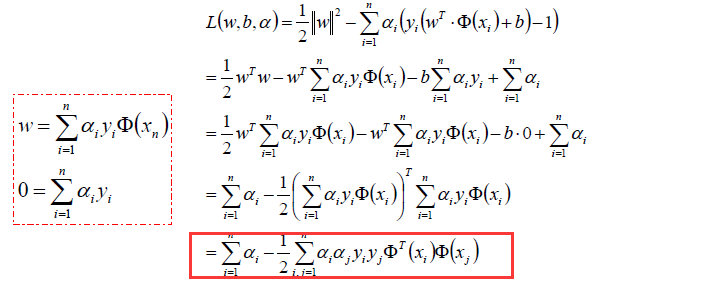
- 这个对偶函数其实求的是:
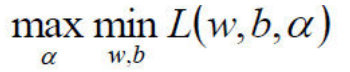 中的minL(w,b)min**L(w,b)部分(因为对w,b求了偏导)。
中的minL(w,b)min**L(w,b)部分(因为对w,b求了偏导)。 - 于是现在要求的是这个函数的极大值max(a),写成公式就是:
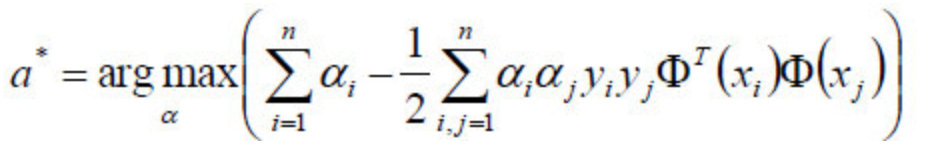
- 好了,现在我们只需要对上式求出极大值\alphaα,然后将\alphaα代入w求偏导的那个公式:
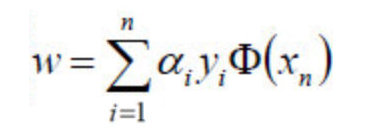
- 从而求出w.
- 将w代入超平面的表达式,计算b值;
- 现在的w,b就是我们要寻找的最优超平面的参数。
3.2.3 整体流程确定
我们用数学表达式来说明上面的过程:
-
1)给出模型的数学公式
-
2)求解的参数w和b
-
3)求得超平面:
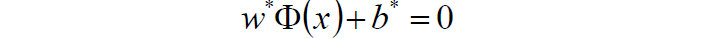
- 4)求得分类决策函数:
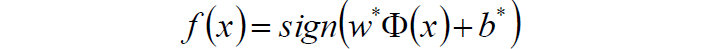
2.4 SVM的核方法
学习目标
- 知道SVM的核方法
- 了解常见的核函数
【SVM + 核函数】 具有极大威力。
核函数并不是SVM特有的,核函数可以和其他算法也进行结合,只是核函数与SVM结合的优势非常大。
1 什么是核函数
1.1 核函数概念
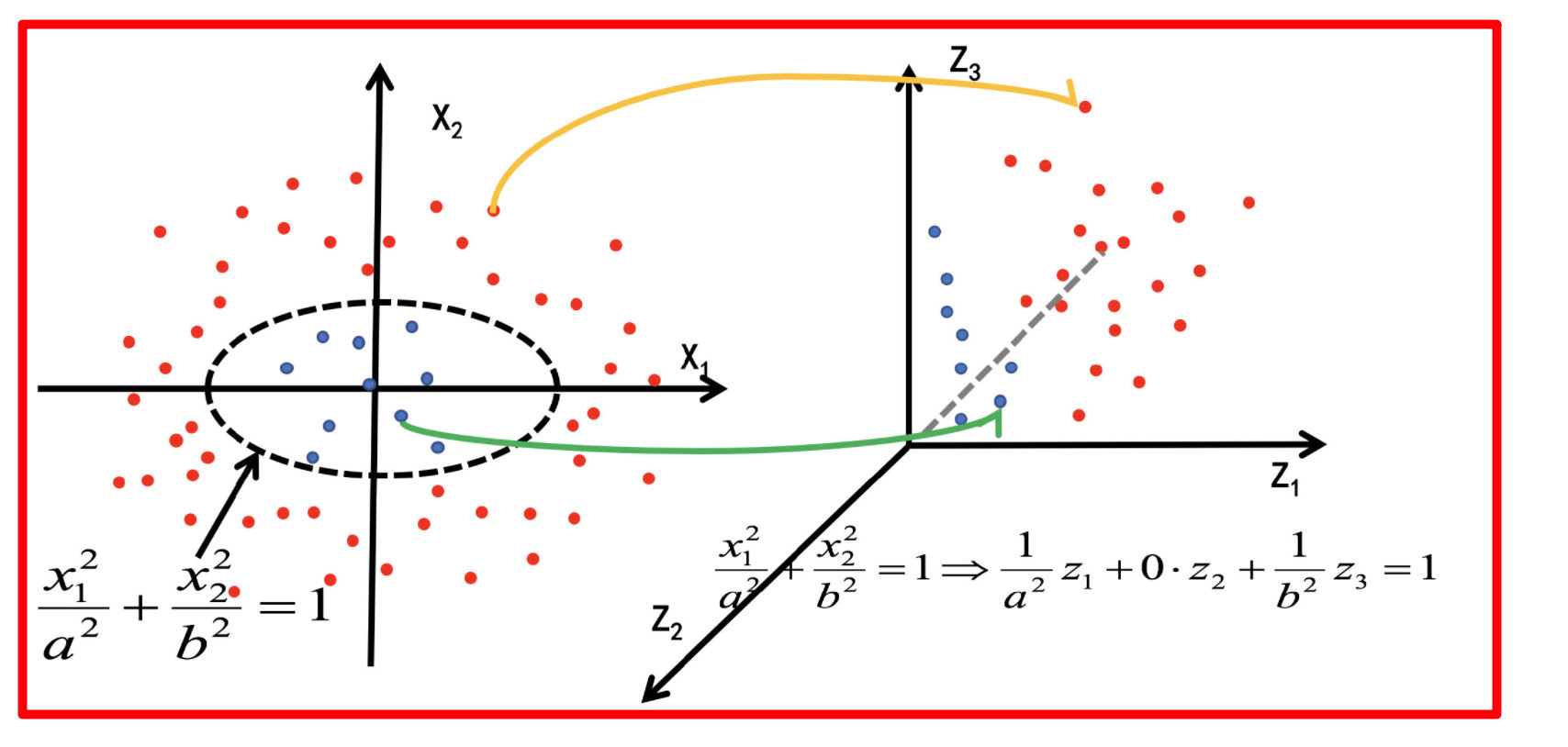
核函数,是将原始输入空间映射到新的特征空间,从而,使得原本线性不可分的样本可能在核空间可分。
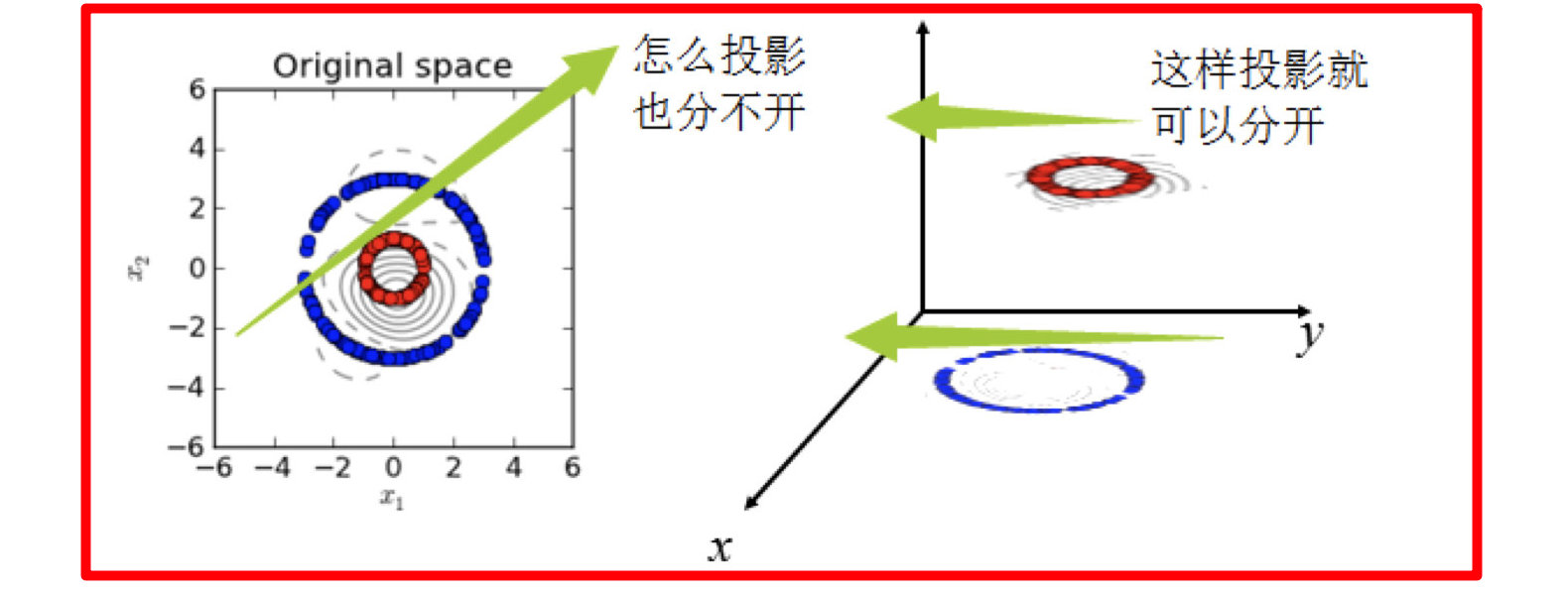
- 假设X是输入空间,
- H是特征空间,
- 存在一个映射ϕ使得X中的点x能够计算得到H空间中的点h,
- 对于所有的X中的点都成立:
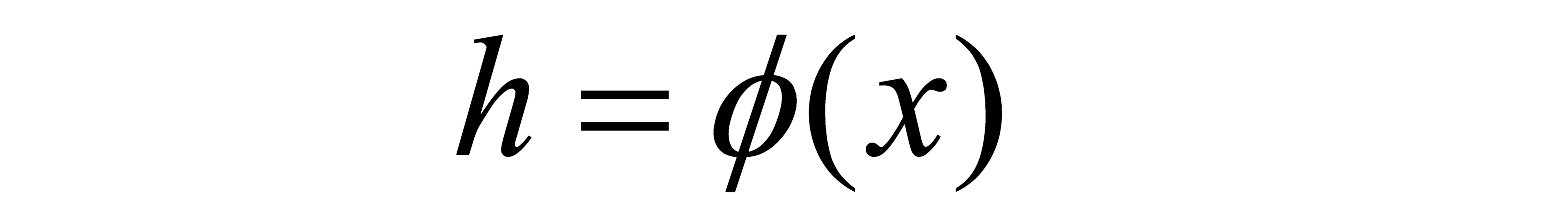
若x,z是空间中的点,函数k(x,z)满足下述条件,那么都成立,则称k为核函数,而ϕ为映射函数,点表示点积:
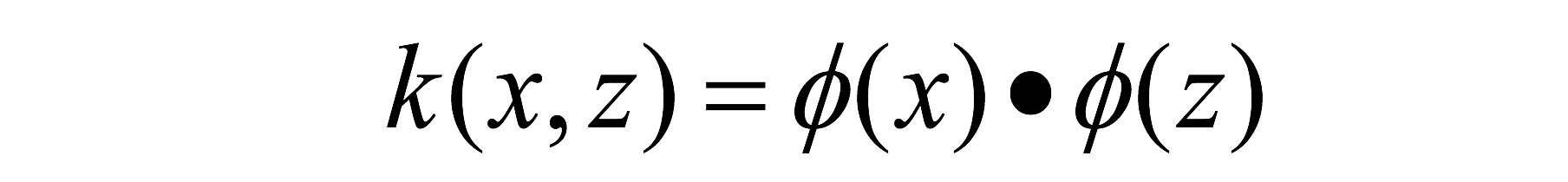
核函数之所以定义成点积的形式,是因为我们在求解svm的模型的参数w和b时会用到两个数据的点积,定义成这种形式可以简化运算。
1.2 核函数举例
1.2.1 核方法举例1:
我们的数据是一个二维的,我们的映射函数是,对数据的第一个值平方作为第一个特征,对数据的第一个值和第二个值的乘积的根号2倍作为第二个特征,对数据的第二个值的平方作为数据的第三个特征。
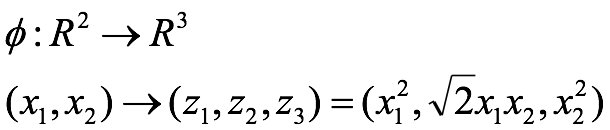
则我们的核函数就是 k ( v 1 , v 2 ) = ( v 1. T ⋅ v 2 ) 2 k(v1,v2) =(v1.T·v2 )^2 k(v1,v2)=(v1.T⋅v2)2,即数据v1和数据v2的点积的平方。

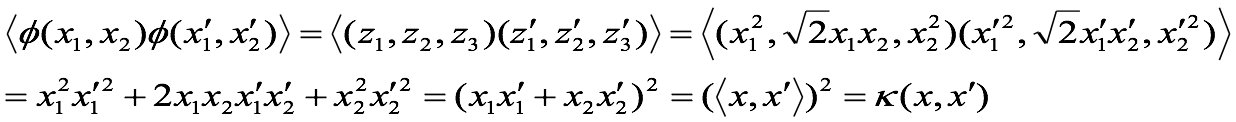
(尖括号表示点积)
经过上面公式,具体变换过过程为:
-
v1=(x_1, x_2)=(1,1)
-
v2=(y_1, y_2)=(2,2)
-
Φ(v1) = (1, 2 \sqrt{2} 2, 1)
-
Φ(v2) = (4, 4 2 4\sqrt{2} 42, 4)
-
<Φ(v1),fΦ(v2)>=4+8+4=16
-
K(v1,v2)=(v1.T**·**v2 )^2 = (2+2)^2 = 16
这里<>和**·**表示点积
链接:https://zhuanlan.zhihu.com/p/261061617
2 常见核函数

2.5 案例:数字识别器
学习目标
- 应用SVM算法实现数字识别器
1 案例背景介绍

MNIST(“修改后的国家标准与技术研究所”)是计算机视觉事实上的“hello world”数据集。自1999年发布以来,这一经典的手写图像数据集已成为分类算法基准测试的基础。随着新的机器学习技术的出现,MNIST仍然是研究人员和学习者的可靠资源。
本次案例中,我们的目标是从数万个手写图像的数据集中正确识别数字。
2 数据介绍
数据文件train.csv和test.csv包含从0到9的手绘数字的灰度图像。
每个图像的高度为28个像素,宽度为28个像素,总共为784个像素。
每个像素具有与其相关联的单个像素值,指示该像素的亮度或暗度,较高的数字意味着较暗。该像素值是0到255之间的整数,包括0和255。
训练数据集(train.csv)有785列。第一列称为“标签”,是用户绘制的数字。其余列包含关联图像的像素值。
训练集中的每个像素列都具有像pixelx这样的名称,其中x是0到783之间的整数,包括0和783。为了在图像上定位该像素,假设我们已经将x分解为x = i * 28 + j,其中i和j是0到27之间的整数,包括0和27。然后,pixelx位于28 x 28矩阵的第i行和第j列上(索引为零)。
例如,pixel31表示从左边开始的第四列中的像素,以及从顶部开始的第二行,如下面的ascii图中所示。
在视觉上,如果我们省略“像素”前缀,像素组成图像如下:
000 001 002 003 ... 026 027
028 029 030 031 ... 054 055
056 057 058 059 ... 082 083
| | | | ...... | |
728 729 730 731 ... 754 755
756 757 758 759 ... 782 783
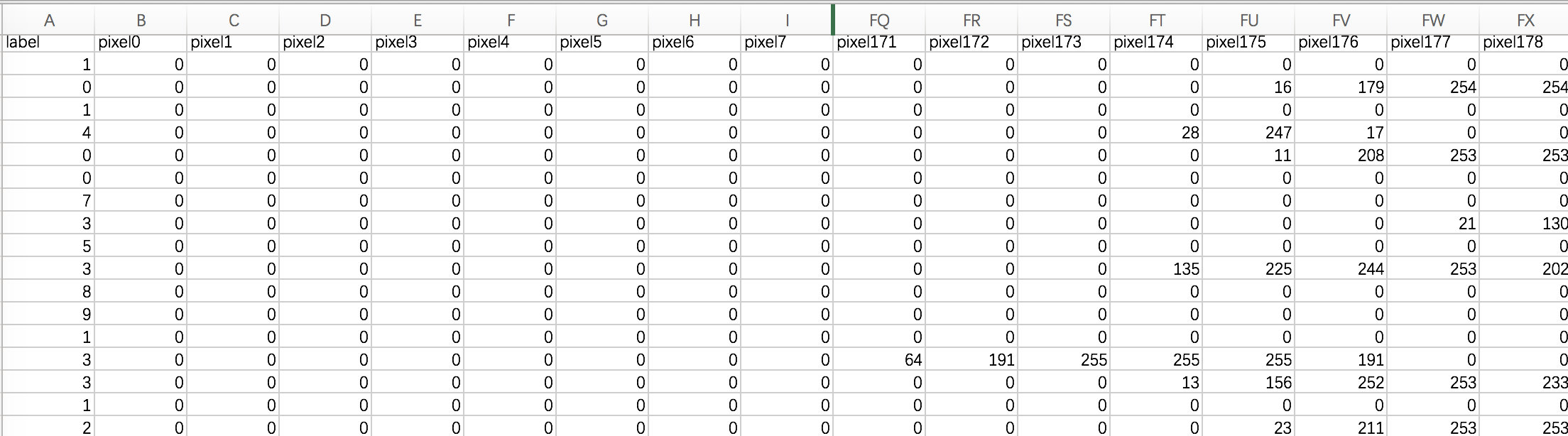
测试数据集(test.csv)与训练集相同,只是它不包含“标签”列。
3 案例实现
参考:案例_手写数字分类.ipynb
i * 28 + j,其中i和j是0到27之间的整数,包括0和27。然后,pixelx位于28 x 28矩阵的第i行和第j列上(索引为零)。
例如,pixel31表示从左边开始的第四列中的像素,以及从顶部开始的第二行,如下面的ascii图中所示。
在视觉上,如果我们省略“像素”前缀,像素组成图像如下:
000 001 002 003 ... 026 027
028 029 030 031 ... 054 055
056 057 058 059 ... 082 083
| | | | ...... | |
728 729 730 731 ... 754 755
756 757 758 759 ... 782 783
[外链图片转存中…(img-Uuc7hMMI-1668817748544)]
测试数据集(test.csv)与训练集相同,只是它不包含“标签”列。
3 案例实现
参考:案例_手写数字分类.ipynb