1.VOC格式标注文件转换成Yolo格式标注文件
Yolo标注的格式与VOC格式不同之处在于:
(1)Yolo格式下的每张图片的所有包含的目标的标注信息,都统一以txt文件的形式储存。一张图片对应一个与其相同名称的txt文件。在txt文件中,每一行对应图片中一个目标的信息,用一个数字指代种类编号,剩下四个数字代表坐标信息。
VOC格式则是每张图片对应一个与其相同名称的xml格式文件。
(2)Yolo格式的数据集,是将训练数据和验证(测试)数据分成两个文件夹,例如训练数据文件夹下包括:训练图片文件夹、训练图片对应的标注文件(txt格式)的文件夹。
VOC格式则是将所有图片(无论是训练图片还是测试图片)都放在一个文件夹下、将所有标注文件(无论是训练的还是测试的)也都放在一个文件夹下,最后用两个txt格式的文件来指定那些是训练数据,哪些是测试数据:例如,train.txt中将所有训练数据(训练图片的名称,去掉.jpg后缀)按每行对应一个的方式储存,test.txt则将所有测试数据的名称(去掉后缀)储存起来。
由此,我们在将Yolo格式的数据集转换成voc格式的数据集时,主要有两部分工作:
(1)将所有的txt标注文件转化成xml标注文件。(2)将yolo数据集的整理形式转化成voc的整理形式:包括将分成train和val(test)两个部分的图片、标注文件合到一起,同时将所有训练集数据名称(去掉后缀)写入到train.txt、将所有测试集数据名称(去掉后缀)写入到test.txt。
以上介绍的转换工作对应的代码均在下面列出。
# 将VOC格式标注文件(xml文件)转换成Yolo格式标注文件(txt文件)
import xml.etree.ElementTree as ET
import os
voc_folder = r"datasets\Annotations" #储存voc格式的标注文件的文件夹,相对路径
yolo_folder = r"yolo_datasets\Annotations" #转换后的yolo格式标注文件的储存文件夹,相对路径
class_id = ["pig","stand","lie","eat"] #储存数据集中目标种类名称的列表,接下来的转换函数中会将该列表中种类名称对应的列表索引号作为写入yolo标注文件中该类目标的种类序号
#voc标注的目标框坐标值转换到yolo标注的目标框坐标值的函数
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
#对单个voc标注文件进行转换成其对应的yolo文件的函数
def convert_annotation(xml_file):
file_name = xml_file.strip(".xml") # 这一步将所有voc格式标注文件取出后缀名“.xml”,方便接下来作为yolo格式标注文件的名称
in_file = open(os.path.join(voc_folder,xml_file)) #打开当前转换的voc标注文件
out_file = open(os.path.join(yolo_folder,file_name + ".txt",),'w') #创建并打开要转换成的yolo格式标注文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
cls_id = class_id.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_fileList = os.listdir(voc_folder) #将所有voc格式的标注文件的名称取出存放到列表xml_fileList中
for xml_file in xml_fileList: #这里的for循环开始依次对所有voc格式标注文件生成其对应的yolo格式的标注文件
convert_annotation(xml_file)
print("success!")
运行结果。
根据VOC格式中的train.txt和test.txt文件来将数据集图片和标注归类到Yolo格式下的train和val文件夹中。
因为Yolo格式的数据集是将训练数据和验证(测试)数据分成两个文件夹,
而VOC格式是将所有图片放在一个图片文件夹、所有标注文件放在一个标注文件夹中。
所有在上面的转换步骤完成后,我们还需要将训练数据和验证(测试)数据分别存放。
2.YOLO数据集划分
分析:
划分数据集主要的步骤就是,首先要将数据集打乱顺序,然后按照一定的比例将其分为训练集,验证集和测试集。
这里我定的比例是7:1:2。
步骤:
1、将数据集打乱顺序
数据集有图片和标注文件,我们需要把两种文件绑定然后将其打乱顺序。
首先读取数据后,将两种文件通过zip函数绑定。
然后打乱顺序,再将两个列表分开。
2、按照确定好的比例将两个列表元素分割
分别用三个列表储存一下图片和标注文件的元素
3、在本地生成文件夹,将划分好的数据集分别保存
这样就保存好了。
4.生成 train_list.txt和val_list.txt。train_list.txt存放了所有训练图片的路径,val_list.txt则是存放了所有验证图片的路径
import os
import shutil
import random
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
each_class_image.sort()
each_class_label.sort()
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
for image in train_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
print("success!")
if __name__ == '__main__':
file_path = "datasets\JPEGlmages" #图片所在路径
xml_path = 'yolo_datasets\Annotations' #YOLO数据集标签所在路径,相对路径
new_file_path = "yolo_datasets" #划分后,yolo数据集所在路径,相对路径
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)
dataset_path = 'yolo_datasets' # 数据集路径
train_list_file = 'yolo_datasets/train_list.txt' # 保存训练集图像路径的文件 此处要用/
val_list_file = 'yolo_datasets/val_list.txt' # 保存验证集图像路径的文件 此处要用/
train_dir = os.path.join(dataset_path, 'train\images') # 训练集文件夹路径
val_dir = os.path.join(dataset_path, 'val\images') # 验证集文件夹路径
# 获取训练集图像文件列表
train_image_files = [f for f in os.listdir(train_dir) if f.endswith('.jpg')]
# 获取验证集图像文件列表
val_image_files = [f for f in os.listdir(val_dir) if f.endswith('.jpg')]
# 将训练集图像路径写入文件
with open(train_list_file, 'w') as f:
for file in train_image_files:
image_path = os.path.join('train', file)
f.write(image_path + '\n')
# 将验证集图像路径写入文件
with open(val_list_file, 'w') as f:
for file in val_image_files:
image_path = os.path.join('val', file)
f.write(image_path + '\n')
print("train_list.txt and val_list.txt generated successfully.")运行完毕。图片和标注文件乱序,且一一对应。(Annotations是voc转YOLO后,标注文件所在的文件夹)
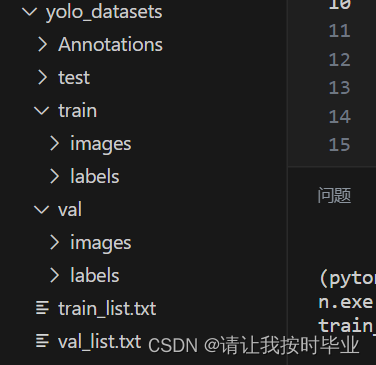

3.VOC数据集划分
import os
import random
import shutil
# 数据集文件夹路径,相对路径
dataset_dir = "datasets\JPEGlmages"
# 训练集和验证集比例
train_ratio = 0.7
# 指定保存train_list.txt和val_list.txt的文件夹路径,相对路径
output_dir = "datasets"
# 获取数据集中的图像文件列表
image_files = [file for file in os.listdir(dataset_dir) if file.endswith(".jpg")]
# 随机打乱图像文件列表
random.shuffle(image_files)
# 计算训练集和验证集的分割索引
split_index = int(len(image_files) * train_ratio)
# 分割图像文件列表为训练集和验证集
train_files = image_files[:split_index]
val_files = image_files[split_index:]
# 生成train_list.txt文件
train_list_path = os.path.join(output_dir, "train_list.txt")
with open(train_list_path, "w") as train_list_file:
for file in train_files:
train_list_file.write(os.path.join(dataset_dir, file) + "\n")
# 生成val_list.txt文件
val_list_path = os.path.join(output_dir, "val_list.txt")
with open(val_list_path, "w") as val_list_file:
for file in val_files:
val_list_file.write(os.path.join(dataset_dir, file) + "\n")
# 移动train_list.txt和val_list.txt到指定文件夹
shutil.move(train_list_path, os.path.join(output_dir, "train_list.txt"))
shutil.move(val_list_path, os.path.join(output_dir, "val_list.txt"))
print("success!")
运行结果。

PS:
做完以上步骤,若直接开始训练,会报错:

解决方法:
找到 utils/dataset.py 文件,搜索框搜索 Define label,然后修改代码。
亦或者重新划分数据集,可参考我这篇文章:https://blog.csdn.net/weixin_45819759/article/details/131211495
参考文章:
将VOC格式标注文件转换为Yolo格式_voc转yolo格式_WentingDu的博客-CSDN博客
【yolov5】将标注好的数据集进行划分(附完整可运行python代码)_yolov5数据集划分_freezing?的博客-CSDN博客