前言
图像文字识别是替代键盘输入的方式之一,可以使用户获得更好的信息输入体验。但有别于一般性的光学字符识别(OCR)过程,我们今天要讨论的算法,其图像来源相对复杂——多样的拍摄角度;多样的光照条件;多样的印刷背景;多样的拍照设备。为了能让文字识别达到预期效果,你必须首先能从前景与背景混杂的图像中提取到有用的文字图像数据,那么可以姑且把这一过程称之为“图像内文字定位算法“。
在此之前,先简略介绍一下OPENCV。这是一款开源的跨平台计算机视觉库,应用领域为机器图像视觉以及在此基础上延伸的人工智能。Intel公司是这个项目的最大赞助商。其中的神经网络算法(基于人工神经网络理论的实现),可以训练程序如何从纷杂的数据中自动收集预定的数据特征,从而实现对大批量原始数据的筛选与匹配。例如从视频存储资料中定位某个物体或者是具有某种自我学习能力的人机交互。
应用场景
以手机相机或其他拍摄设备所拍摄的图像作为输入源,识别其图像内标识性字符串。(由字母和数字构成,并拥有特殊定义结构,不需要进行词汇联想)
算法概述
首先对文件进行裁剪、灰度与滤波处理,在此基础上使用Canny算法进行多轮边缘查找,再将其查找结果(阈化图像)进行像素邻域计算以得到分布在图像内大大小小多个像素连通区域,然后将这些以矩形标识的分散区域根据识别对象字符横向等距分布的特性进行多次区域兼并运算,之后将多轮处理后得到的多个兼并对象作整体布局上的比较分析,从而淘汰不良结果。最后根据最优兼并结果内字符单元区域集合提取图像内待识别文字。
实现步骤(代码将采用java语言来展示)
注:
1、注释中出现注重符“•”表示其所针对的代码行中出现的常量及其计算表达式在实际应用中应取自或依赖于预设的配置文件,因为这些定义都是根据当前应用场景得到的试验结果,为了程序能够适应不同的需求或拥有良好扩展特性,比较好的方式便是做到运行参数可配置。
2、“…”符号表示代码有某些细节被省略(代码来源于真实项目)
import org.opencv.highgui.Highgui;
import org.opencv.imgproc.*;
import java.awt.image.BufferedImage;
import java.awt.image.DataBufferByte;
import javax.imageio.ImageIO;
import org.opencv.core.CvException;
import org.opencv.core.CvType;
import org.opencv.core.Mat;
...
//本文后续所介绍的主要方法都在此类中定义
public class MrzOcrIdentify {
...
private static boolean isLibraryLoaded = true;
//加载opencv库文件,在这里此文件应位于JVM执行目录下。
static{
try{
System.loadLibrary("opencv_java248");
}catch(Exception e){
e.printStackTrace();
isLibraryLoaded = false;
}
}
//区域计算时高度和宽度的参考上限
private int maxh, maxw;
//原始图像裁剪后区域
private MrzOcrRect scanRect;
//类似于point结构,在计算像素连通区域时用到
static class Pair{
public int first, second;
public Pair(){}
public Pair(int first, int second){
this.first = first;
this.second = second;
}
}
...
}步骤1:适度缩放和裁剪图像。这是为了让程序对于文字区域有一个更好的预判,以减少不必要的运行消耗。
private Mat processSrcImage(InputStream ins){
//将位图转换为Mat对象,ins为字节流对象,是主方法的输入参数。
Mat matSrc = bmp2Mat(ins, CvType.CV_8UC3);
//得到原始图像的宽度和高度
int srcWidth = matSrc.width();
int srcHeight = matSrc.height();
//默认缩放图像与原始图像一致
Mat matDest = matSrc;
//•设定缩放目标值为1200•
Size size = new Size();
if(Math.max(srcWidth, srcHeight) > 1200){
if(srcWidth > srcHeight){
size.width = 1200;
size.height = srcHeight * (1200 / srcWidth);
}else{
size.height = 1200;
size.width = srcWidth * (1200 / srcHeight);
}
//缩放图像
matDest = new Mat((int)size.height, (int)size.width, matSrc.type());
Imgproc.resize(matSrc, matDest, size, 0, 0, Imgproc.INTER_AREA);
}
//•裁剪图像,设定文字的大致区域在图像底部1/3区域•
//尽量保证所要提取的字符串在这一区域拥有明显的识别特征
int cutHeight = (int)(size.width * 0.3333);
Mat matCut = matDest.submat(new Rect(0, size.height - cutHeight, size.width, cutHeight));
//•设定字符单元高度上限为裁剪高度的1/4,宽度上限为原始宽度的1/3•
//字符在横向排列上可能间距很小,定位出来的字符单元可能包含多个文字
maxh = (int)(cutHeight * 0.25);
maxw = (int)(oriWidth * 0.3333);
//scanRect为Class的成员变量,区域越界校验时使用。
scanRect = new MrzOcrRect(0, 0, oriWidth, cutHeight);
...
}
//将原始图像数据流转换为Mat结构(Mat是opencv库中主要的图像数据结构,也可称为矩阵)。
private static Mat bmp2Mat(InputStream ins, int type) throws MrzOcrException{
Mat matSrc = null;
BufferedImage imgbuf = null;
try {
imgbuf = ImageIO.read(ins);
byte[] data = ((DataBufferByte)imgbuf.getRaster().getDataBuffer()).getData();
matSrc = new Mat(imgbuf.getHeight(), imgbuf.getWidth(), type);
matSrc.put(0, 0, data);
} catch (IOException e) {
e.printStackTrace();
}
return matSrc;
}步骤2:图像灰度化和滤波处理。一般情况下,我们得到的是一个彩色的点阵图像,图像中的每一个点通常由R、G、B三种颜色分量构成。但对于程序来说,这会成为其查找单个物体边界时沉重的程序消耗,图像灰度化处理就是为了让图像有更为简洁的数据结构。灰度图像的像素只要一个灰度值来表示,既不妨碍识别物体边缘,也可大大优化搜索效率。由于图像在拍摄过程中会产生大量随机分布的噪点(就如同声音在传播过程中产生的噪音,噪点则是违背了图像自然原貌,呈现异常颜色的像素点),进行滤波是为了像素之间的颜色过渡更为柔和,以最大程度的消除噪点对于查找物体边界的影响。
原始图像 
灰度图像 
滤波图像

public synchronized String identify(InputStream ins){
...
matCut = processSrcImage(ins);
//灰度处理
matGray = new Mat();
Imgproc.cvtColor(matCut, matGray, Imgproc.COLOR_BGR2GRAY);
//滤波处理
matFilter = new Mat();
Imgproc.blur(matGray, matFilter, new Size(3, 3));
//边缘查找与定位
List<MrzOcrMerger> mrzRegions = position(matFilter);
...
}步骤3:边缘查找。这里将使用经典的Canny算法。在此之前,必须确定阈值的上限与下限,如果一个像素的梯度大于上限,则被认为是边缘像素,如果低于下限则被抛弃,如果介于两者之间,只有当其与高于上限阈值的像素连接时才会被接受。由于每张图像的前景与背景的颜色分界线(阈值)是不同的,那么还必须在外围设定逐次递增的阈值搜索区间,以便在多次的边缘查找结果中寻找到最佳结果。
第一次边缘查找结果 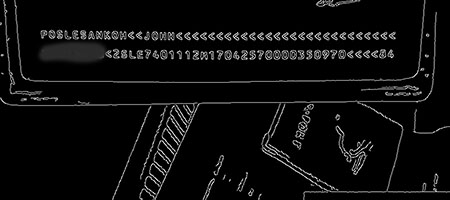
最后一次边缘查找结果
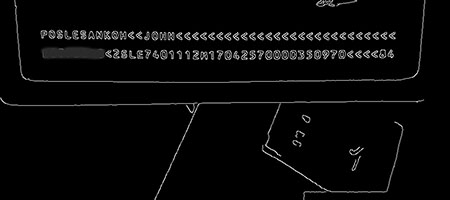
//返回的是一个字符兼并对象集合。
private List<MrzOcrMerger> position(Mat matGray){
...
List<MrzOcrMerger> result = null;
Mat matCanny = new Mat();
//•设定搜索阈值的初始下限值为30,搜索次数为7次,递增值为10,阈值上限系数为3•
int t = 30;
for(int i=0; i<7; i++, t+=10){
double t1 = t;
double t2 = t1 * 3;
Imgproc.Canny(matGray, matCanny, t1, t2);
//根据边缘检测结果获取像素连通区域并进行字符单元兼并计算,后续会详细介绍getValidAreas方法。
List<MrzOcrMerger> areas = getValidAreas(matCanny);
matCanny.release();
if(areas == null || areas.size() != ls){
continue;
}else{
//装入第一个字符定位结果
if(result == null){
result = new ArrayList<MrzOcrMerger>();
for(int n=0; n<ls; n++){
result.add(areas.get(n));
}
}else{
//设定识别字符行数为2
for(int j=0; j<2; j++){
//获取当前搜索结果中字符串兼并区域的宽度
int w1 = areas.get(j).rctotal.getWidth();
//获取前次搜索结果中字符串兼并区域的宽度
int w2 = result.get(j).rctotal.getWidth();
/*随着阈值区间的向上位移,图像物体边缘细节将愈来愈多被忽略,
可被查找到的字符区域个数将呈下降趋势。也就是说违背这个规律将被视为异常情况而抛弃*/
if(w1 <= w2){
int l1 = areas.get(j).areas.size();
int l2 = result.get(j).areas.size();
//•每行字符数设定为44•
//如果当前集合内字符区域个数更接近44,将覆盖前一次搜索结果。
if(l1 <= 44 && l1 > l2){
result.set(j, areas.get(j));
}
}
}
}
}
}
return result;
}步骤4:计算像素连通区域。值得注意的是,边缘查找后得到的图像已被二值化(图像中只存在黑色与白色两种颜色,也可称之为阈化图像),这是像素连通区域计算的前提。
//递归调用的优化方案就是使用栈结构来进行迭代搜索
private List<MrzOcrMerger> getValidAreas(Mat matBin){
//源图像的颜色深度必须为8位
if(matBin.empty() || matBin.type() != CvType.CV_8UC1){
return null;
}
int rows = matBin.rows();
int cols = matBin.cols();
List<MrzOcrRect> tempList = new ArrayList<MrzOcrRect>();
byte[] data = new byte[rows * cols];
matBin.get(0, 0, data);
//•设定中心点与紧邻点的水平与纵向搜索范围大小同时为2(实际上是个5*5矩阵)•
//由于噪点的存在,在计算连通区域时,边缘中出现一个像素大小的中断时应该同样视为一个有效的连通。
int dx = 2, dy = 2;
for(int i=dy; i<rows-dy; i++){
for(int j=dx; j<cols-dx; j++){
//将二维坐标转换为线性数组索引
int index = i * cols + j;
//判断是否是有效中心点(排除黑色像素点)
if(data[index] != 0){
//将首次获取到的中心点压入栈中
Stack<Pair> pixs = new Stack<Pair>();
pixs.push(new Pair(i, j));
//防止重复计算
data[index] = 0;
//初始化连通区域
MrzOcrRect rect = new MrzOcrRect(j, i, j, i);
while(!pixs.empty()){
//从栈中弹出中心点
Pair pix = pixs.pop();
int y = pix.first;
int x = pix.second;
//合并中心点与前次搜索区域构成的连通区域
if(x < rect.left) rect.left = x;
if(x > rect.right) rect.right = x;
if(y < rect.top) rect.top = y;
if(y > rect.bottom) rect.bottom = y;
//获取像素相邻区域。
MrzOcrPoint ptc = new MrzOcrPoint(x, y);
MrzOcrRect resRect = getNeighbor(ptc);
//对相邻区域进行连通判定,并压入栈内,以便迭代搜索
for(int n=resRect.left; n<resRect.right; n++){
for(int m=resRect.top; m<resRect.bottom; m++){
index = m * cols + n;
if(data[index] != 0){
pixs.push(new Pair(m, n));
data[index] = 0;
}
}
}
}
//以插入排序方式将搜索到的连通区域插入临时集合
sortInsert(tempList, rect);
}
}
}
//横向兼并连通区域(在下一章节会详细说明)
return searchAreas(tempList);
}
//根据中心点计算像素相邻区域
private MrzOcrRect getNeighbor(MrzOcrPoint ptc){
MrzOcrRect result = new MrzOcrRect();
//•设定像素邻域横向与纵向搜索范围为2个单位•
int dx = 2, dy = 2;
result.left = ptc.x - dx;
result.top = ptc.y - dy;
//考虑到运算速度,频繁调用的算式中应避免使用乘除法运算符。
result.right = result.left + dx + dx + 1;
result.bottom = result.top + dy + dy + 1;
//区域越界修正
if(result.left < 0) result.left = 0;
if(result.top < 0) result.top = 0;
if(result.right > scanRect.right) result.right = scanRect.right;
if(result.bottom > scanRect.bottom) result.bottom = scanRect.bottom;
return result;
}
//以插入排序的方式收集像素连通区域
private void sortInsert(List<MrzOcrRect> list, MrzOcrRect rect){
int h = rect.getHeight();
int w = rect.getWidth();
//•设定最小高度为10,最小宽度为3(例如“1”的宽度)•
//过滤掉不符合上述规则的矩形
if(h < 10 || h > maxh || w < 3 || w > maxw){
return;
}
//以x坐标值进行升序排序是为了自左向右依次兼并,确保字符的正确排列。
for(int i=0; i<list.size(); i++){
if(rect.left < list.get(i).left){
//该集合内区间[i,n]将向后位移。
list.add(i, rect);
return;
}
}
list.add(rect);
}
----------
//自定义的矩形对象
public class MrzOcrRect {
int left, top, right, bottom;
public MrzOcrRect(){
}
public MrzOcrRect(int left, int top, int right, int bottom){
this.left = left;
this.top = top;
this.right = right;
this.bottom = bottom;
}
public void setRect(int left, int top, int right, int bottom){
this.left = left;
this.top = top;
this.right = right;
this.bottom = bottom;
}
public void setRect(final MrzOcrRect rect){
left = rect.left;
top = rect.top;
right = rect.right;
bottom = rect.bottom;
}
//在对输入的矩形进行边缘修正后(正数为收缩,负数为扩展),计算两个矩形是否存在交集
//rh为横向修正量,rv为纵向修正量
public boolean isIntersect(final MrzOcrRect rect, int rh, int rv){
if(left > rect.right - rh) return false;
if(right < rect.left + rh) return false;
if(top > rect.bottom - rv) return false;
if(bottom < rect.top + rv) return false;
return true;
}
//合并矩形
public void union(final MrzOcrRect rect){
if(left > rect.left) left = rect.left;
if(top > rect.top) top = rect.top;
if(right < rect.right) right = rect.right;
if(bottom < rect.bottom) bottom = rect.bottom;
}
//重载的区域交集运算方法1
public boolean isIntersect(final MrzOcrRect rect, int rh){
return isIntersect(rect, rh, 0);
}
//重载的区域交集运算方法1
public boolean isIntersect(final MrzOcrRect rect){
//•设定横向修正值为3是为了忽略边缘重叠的情况•
return isIntersect(rect, 3, 0);
}
//克隆矩形对象
public MrzOcrRect clone(){
return new MrzOcrRect(left, top, right, bottom);
}
public int getHeight(){
return bottom - top;
}
public int getWidth(){
return right - left;
}
//获取横向中心点
public double getHCenter(){
return (left + right) * 0.5;
}
//获取纵向中心点
public double getVCenter(){
return (top + bottom) * 0.5;
}
}
----------
//自定义坐标点对象
public class MrzOcrPoint {
int x, y;
public MrzOcrPoint(int x, int y){
this.x = x;
this.y = y;
}
public MrzOcrPoint(){
this(0, 0);
}
}步骤5:兼并字符单元。根据字符串具有趋于横向等距排列,字符大小大致相等的特性,对散布的字符单元进行横向兼并运算,在构建应用所需要识别的字符串的同时排除掉其他不符合排列规则的像素连通区域。需要注意的是,由于拍摄角度和场景的不同,图像往往会出现倾斜和平面偏转的情况(文字出现了变形或字符行基线倾斜),那么在设定兼并规则时条件要相对宽松,而且要兼顾整体与局部的对比分析。
//横向兼并字符单元
private List<MrzOcrMerger> searchAreas(List<MrzOcrRect> srcList){
List<MrzOcrMerger> transList = new ArrayList<MrzOcrMerger>();
//第一轮兼并,判断待兼并区域与兼并连接点是否符合一定的兼并条件。
int i = 0;
LINE1:
for(; i<srcList.size(); i++){
MrzOcrRect rect = srcList.get(i);
for(int j=0; j<transList.size(); j++){
//获取兼并对象内字符单元集合的尾部元素
//在这里将兼并对象内字符单元集合中的最后一个元素称为兼并连接点
MrzOcrRect lastRect = transList.get(j).getLastArea();
//获取当前兼并对象内字符单元集合的平均宽度
double avgw = transList.get(j).getAvgWidth();
//兼并连接点与待兼并区域水平中心线不得出现一个字符高度的偏离(假定这些已定位区域为一个字符)
//这里使用连接点与待兼并区域进行比较是考虑到图像出现倾斜与平面偏转的情况。
//因为这两个区域在对比上波幅会相对趋缓,也符合逐次递增或递减的特性。
if(Math.abs(rect.getVCenter() - lastRect.getVCenter())
< Math.min(rect.getHeight(), lastRect.getHeight())
//•设定字符间隔距离系数为1.5•
//字符间隔不得超过平均字符宽度的1.5倍
&& rect.left - lastRect.right <= (avgw + rect.getWidth()) * 0.5 * 1.5
//•设定字符高度差异系数为0.5•
//字符高度不得出现0.5倍高度差距
&& Math.abs((double)rect.getHeight() / lastRect.getHeight() - 1) < 0.5
//不得出现区域相交(允许边缘重叠3个像素)
&& !rect.isIntersect(lastRect)){
//将符合兼并规则的区域插入到兼并对象中
transList.get(j).add(rect);
//在执行兼并操作后跳转到外层循环,以避免重复兼并
//注意下标i不是在循环内部定义的
continue LINE1;
}
}
//当兼并对象集合为空时或没有可加入的兼并对象时直接插入当前区域。
//可视为一个新的兼并起点
MrzOcrMerger merger = new MrzOcrMerger();
merger.add(rect);
transList.add(merger);
}
//对第一次兼并后的兼并结果总区域做图像比例的比较,
//以使其更符合应用需求中识别区域所呈现的图像比例特征
List<MrzOcrMerger> filterList = new ArrayList<MrzOcrMerger>();
i = 0;
LINE2:
for(; i<transList.size(); i++){
//获取兼并对象内字符单元集合的宽高比例(一行字符串)
double ration = transList.get(i).getRatio();
int length = transList.get(i).areas.size();
//•设定每行文字区域的宽度和高度之比为24:1,字符个数为44•
//如果假定单个字符区域为一个正方形,且字符之间存在间距,那么理想的结果应该大于44:1,
//但如果假定图像倾斜夹角存在正负15度的浮动,那么44:1的比例就不合适了
//图像倾斜的后果就是每行文字总区域的高度大大超过预期
//判定总区域比例大于24:1
//兼并对象内字符单元个数不得大于44
if(ration > 24 && length <= 44){
//对符合规则的兼并对象按字符个数降序排序
for(int j=0; j<filterList.size(); j++){
if(length > filterList.get(j).areas.size()){
filterList.add(j, transList.get(i));
continue LINE2;
}
}
filterList.add(transList.get(i));
}
}
//•设定文字行数为2•
//由于设定识别对象为两行长度相等的字符,所以有必要比较一下两行文字宽度差异是否在预定的范围内
if(filterList.size() >= 2){
double[] params = new double[2];
for(int k=0; k<2; k++){
params[k] = filterList.get(k).rctotal.getWidth();
}
//•设定多行区域最大宽度与最小宽度差异不得大于100•
if(max(params) - min(params) <= 100){
List<MrzOcrMerger> subList = filterList.subList(0, 2);
List<MrzOcrMerger> resList = new ArrayList<MrzOcrMerger>();
//对兼并对象集合内元素按y坐标升序排序,以确定文字行的次序
i = 0;
LINE3:
for(; i<subList.size(); i++){
for(int j=0; j<resList.size(); j++){
if(subList.get(i).rctotal.top < resList.get(j).rctotal.top){
resList.add(j, subList.get(i));
continue LINE3;
}
}
resList.add(subList.get(i));
}
return resList;
}
}
return null;
}
----------
//字符单元兼并对象
public class MrzOcrMerger {
//兼并的字符单元集合
List<MrzOcrRect> areas;
MrzOcrRect rctotal;
private int htotal, wtotal;
public MrzOcrMerger(){
areas = new ArrayList<MrzOcrRect>();
rctotal = new MrzOcrRect();
}
//获取平均高度
public double getAvgHeight(){
return (double)htotal / areas.size();
}
//获取平均宽度
public double getAvgWidth(){
return (double)wtotal / areas.size();
}
//获取兼并总区域宽度与高度的比例值
public double getRatio(){
return (double)rctotal.getWidth() / getAvgHeight();
}
//获取字符兼并内字符单元集合尾部元素,也可认为是获取可兼并连接点
public MrzOcrRect getLastArea(){
if(areas.size() > 0)
return areas.get(areas.size() - 1);
return null;
}
//兼并字符单元
public void add(MrzOcrRect rect){
areas.add(rect);
htotal += rect.getHeight();
wtotal += rect.getWidth();
//在兼并时计算总区域大小
if(areas.size() == 1){
rctotal.setRect(rect);
}else{
rctotal.union(rect);
}
}
}步骤6: 根据兼并结果内字符单元集合逐个截取文字图像。这些文字图像在提交到Tesseract模块进行识别之前,还需要进行一些处理。首先使用大津算法对文字图像进行阈化,然后对阈化结果进行画布拉伸(将文字图像置于一个更大的白色画布中,这样可以使Tesseract得到更为丰富的字符边缘信息),之后进行图像形态处理(腐蚀与膨胀),以得到三种形态的文字图像(正常、纤细、加粗),而Tesseract模块在识别图像文字的同时还会返回一个识别评分,将三种形态图像经过三次识别后再根据识别评分择优选取,可以很大程度上提升识别率。由于这一节与算法主题已经偏离,不再作代码展示。
public synchronized String identify(InputStream ins){
...
List<MrzOcrMerger> mrzRegions = position(matFilter);
for(MrzOcrMerger merger : mrzRegions){
for(MrzOcrRect rect : merger.areas){
//使用灰度图像作为截取源图像
Mat matSub = matGray.submat(new Rect(rect.left, rect.top,
rect.getWidth(), rect.getHeight()));
...
}
}
...
}