篇章三:TensorRT模型部署及优化
目录
PS:纯粹为学习分享经验,不参与商用价值运作,若有侵权请及时联系!!!
下一篇内容预告:深度学习模型部署TensorRT加速(四):TensorRT的应用场景及部署流程
前言:
温馨提示:文章很长!!!涵盖内容很丰富,包括原理,封装过程,实际操作,请耐心学完!!!相信认真学习后,一定会对该体系知识有一个深刻的认识,甚至能依靠经验进行实际项目直接上手操作!!!
TensorRT安装配置流程:【模型部署】TensorRT的安装与使用_tensorrt部署_只搬烫手的砖的博客-CSDN博客
TensorRT安装指南_Christo3的博客-CSDN博客
一、TensorRT简介
1.1 前言

TensorRT是NVIDIA开发的一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
从 TensorRT 3 开始,提供C++ API和Python API。可为深度学习推理应用进行加速。在推理期间,基于 TensorRT 的应用甚至比仅 CPU 平台的执行速度快 40 倍!!!TensorRT 本质只是推理优化器。网络训练完之后,可以将训练模型文件直接丢进 TensorRT中,而不再需要依赖深度学习框架。
·TensorRT 部署流程主要有以下五步:
1.训练模型
2.导出模型为 ONNX 格式
3.选择精度
4.转化成 TensorRT 模型
5.部署模型
(下文将对这五个板块的内容进行详细的介绍和扩展!!!)
1.2 TensorRT对象
TensorRT 的 API 是基于类的。 TensorRT是一个用于高性能深度学习推理的优化器和运行时库。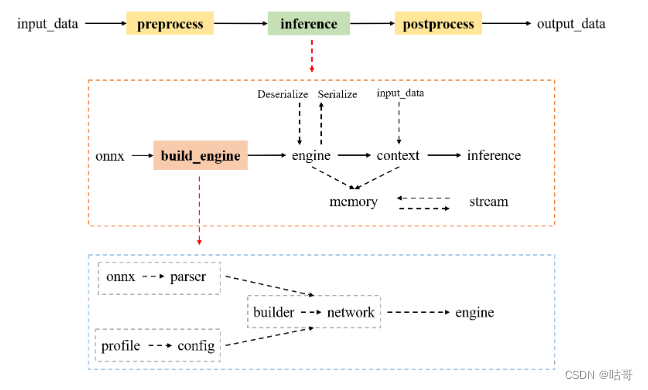
流程图参考来源:TensorRT学习笔记--基本概念和推理流程_tensorrt推理流程_晓晓纳兰容若的博客-CSDN博客
在TensorRT中,对象的生命周期可以概括为以下几个主要阶段:
-
创建对象:在TensorRT中,可以创建多种不同类型的对象,例如
IBuilder、INetworkDefinition、ICudaEngine等。这些对象用于构建、定义和优化神经网络模型。 -
构建网络:在创建
INetworkDefinition对象后,可以使用TensorRT提供的API来构建神经网络。这包括添加输入和输出层,定义中间层和操作,设置张量的维度和数据类型等。 -
优化网络:在构建网络后,可以通过调用
IBuilder对象的方法来优化网络。这些方法包括执行层次融合、内存优化、精度校准等技术,以减少推理时间和内存占用。 -
构建引擎:在优化网络后,可以使用
IBuilder对象的buildCudaEngine方法来构建ICudaEngine对象。这是TensorRT运行时使用的引擎对象,它包含了优化后的网络和执行推理所需的GPU代码。 -
序列化引擎:构建引擎后,可以将
ICudaEngine对象序列化为一个文件,以便以后加载和重用。这可以通过调用ICudaEngine对象的serialize方法来完成。 -
加载引擎:当需要执行推理时,可以通过反序列化引擎文件来加载
ICudaEngine对象。这将创建一个可以执行推理的运行时环境。 -
执行推理:一旦引擎加载完成,可以使用
ICudaEngine对象的方法将输入数据提供给模型,并获取输出结果。推理过程在TensorRT的运行时环境中进行,利用GPU的并行计算能力来加速推理速度。 -
释放资源:在完成推理任务或不再需要TensorRT对象时,应该显式地释放和销毁TensorRT对象。这可以通过调用相应对象的析构函数或销毁方法来完成。
其流程可以用以下代码表示:
- C++代码:
#include <iostream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
int main() {
// 创建TensorRT的Builder对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
// 创建TensorRT的网络定义对象
nvinfer1::INetworkDefinition* network = builder->createNetwork();
// 构建网络结构,例如添加输入和输出层、定义操作等
nvinfer1::ITensor* input = network->addInput("input", nvinfer1::DataType::kFLOAT, nvinfer1::Dims{1, 3, 224, 224});
// 添加中间层和操作
// 优化网络,执行层次融合、内存优化等
builder->setMaxWorkspaceSize(1 << 20); // 设置工作空间大小
builder->setFp16Mode(true); // 启用FP16精度
// 构建Cuda引擎
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// 序列化引擎以保存到文件
nvinfer1::IHostMemory* serializedEngine = engine->serialize();
std::ofstream engineFile("model.engine", std::ios::binary);
engineFile.write((const char*)serializedEngine->data(), serializedEngine->size());
engineFile.close();
// 释放资源
engine->destroy();
network->destroy();
builder->destroy();
return 0;
}
- Python代码:
import tensorrt as trt import pycuda.driver as cuda # 创建TensorRT的Builder对象 builder = trt.Builder(trt.Logger(trt.Logger.WARNING)) # 创建TensorRT的网络定义对象 network = builder.create_network() # 构建网络结构,例如添加输入和输出层、定义操作等 input_tensor = network.add_input("input", trt.DataType.FLOAT, (1, 3, 224, 224)) # 添加中间层和操作 # 优化网络,执行层次融合、内存优化等 builder.max_workspace_size = 1 << 20 # 设置工作空间大小 builder.fp16_mode = True # 启用FP16精度 # 构建Cuda引擎 engine = builder.build_cuda_engine(network) # 序列化引擎以保存到文件 with open("model.engine", "wb") as f: f.write(engine.serialize()) # 释放资源 engine.destroy() network.destroy() builder.destroy()
1.3 TensorRT的优化极限
TensorRT通过使用各种优化技术和算法,以及针对特定硬件的优化,可以在深度学习推理任务中实现高度的性能提升。然而,优化的极限是由多个因素决定的,包括以下几个主要方面:
-
网络结构和模型复杂性:模型的结构和复杂性对TensorRT的优化极限有一定的影响。通常情况下,TensorRT在具有较大推理负载和复杂层次结构的模型中表现得更好。一些简单的模型可能无法获得显著的优化收益。
-
硬件平台:TensorRT的性能优化是通过利用特定硬件的特性来实现的。因此,硬件平台的选择和性能特点将对TensorRT的优化极限产生影响。不同的GPU架构和型号可能会对TensorRT的性能提升程度有所差异。
-
优化技术和配置:TensorRT提供了多种优化技术和配置选项,可以根据不同的需求进行调整。这些技术包括层次融合、内存优化、精度校准等。选择和配置这些优化技术将对TensorRT的性能产生影响,但也需要权衡模型准确性和推理速度之间的平衡。
-
数据类型和精度:TensorRT支持不同的数据类型和精度设置,包括浮点数、半精度浮点数等。通常情况下,较低精度的数据类型可以提供更高的推理性能,但会牺牲一定的模型准确性。因此,选择合适的数据类型和精度设置也会影响TensorRT的优化极限。
1.4 DNN优化编译器
DNN(Deep Neural Network)优化编译器是专门设计用于将深度神经网络模型转换为高效的计算图或代码的工具。这些编译器利用各种优化技术和算法,对神经网络进行静态分析和转换,以提高模型的推理性能和效率。
以下是一些常见的DNN优化编译器:
PS:上述代码无需运行,只是简单阐述这些优化编译器的大体构建流程。
这些DNN优化编译器可以根据具体的模型和硬件目标进行配置和调优,以实现更高的推理性能和效率。它们在深度学习推理的加速和优化方面发挥着重要作用,并广泛应用于深度学习框架和推理引擎中。
需要注意的是,TensorRT的优化极限是一个相对概念,它取决于具体的应用场景、硬件配置和模型特性。在实践中,通过对模型和TensorRT进行适当的调优和配置,可以实现显著的性能提升。但在达到硬件极限和模型复杂性的情况下,进一步的优化收益可能会受到限制。因此,在使用TensorRT进行优化时,需要进行实际测试和评估,以确定最佳的性能和准确性平衡点。
-
TensorFlow XLA(Accelerated Linear Algebra):XLA是TensorFlow的一个组件,用于针对特定硬件生成高效的计算图。它通过图优化、内存管理、算子融合和编译技术,提供了高性能的深度学习推理。
#include <iostream> #include "tensorflow/compiler/xla/client/xla_builder.h" int main() { // 创建XLA计算图 xla::XlaBuilder xla_builder("XLA"); xla::XlaOp input = xla_builder.Parameter(0, xla::ShapeUtil::MakeShape(xla::F32, {1, 3, 224, 224}, {})); xla::XlaOp output = xla_builder.Mul(input, input); xla::XlaComputation computation -
TVM(Tensor Virtual Machine):TVM是一个端到端的深度学习编译器堆栈,支持多种深度学习框架,并提供了图优化、算子融合、自动调度和代码生成等功能。TVM通过自动调度技术,为不同硬件生成高度优化的代码。
#include <iostream> #include "tvm/tvm.h" #include "tvm/runtime/module.h" int main() { // 创建TVM Relay模块和目标硬件 tvm::relay::Module relay_module = ...; // 构建 Relay 模块 tvm::Target target = tvm::Target("llvm"); // 选择目标硬件 tvm::TargetHost target_host = tvm::TargetHost("llvm"); tvm::BuildConfig config = tvm::BuildConfig::Create(); tvm::runtime::Module tvm_module = tvm::relay::CreateExeModuleFromRelay(relay_module, target, config); // 执行TVM模块 // ... return 0; } -
Glow:Glow是一个用于优化深度学习推理的开源框架,它通过图优化、内存优化、算子融合和低级代码生成等技术,生成高效的机器代码。Glow支持多种硬件平台,并提供了与各种深度学习框架的集成接口。
#include <iostream> #include "glow/Runtime/HostManager/HostManager.h" int main() { // 创建Glow模块和HostManager glow::HostConfig host_config; glow::HostManager host_manager(host_config); glow::Module glow_module; glow::Function *F = glow_module.createFunction("glow_function"); // 构建 Glow 模块 // ... host_manager.addNetwork(glow_module); // 执行Glow模块 // ... return 0; } -
ONNX(Open Neural Network Exchange):ONNX是一个开放的深度学习模型表示格式和推理引擎中立的中间表示。ONNX优化编译器可以将ONNX格式的模型转换为针对特定硬件优化的计算图或代码。
#include <iostream> #include "onnx/onnx_pb.h" #include "onnx/optimizer/optimize.h" int main() { // 创建ONNX模型和优化编译器 onnx::ModelProto onnx_model = ...; // 构建ONNX模型 onnx::GraphOptimizationLevel level = onnx::GraphOptimizationLevel::ORT_ENABLE_ALL; OrtEnv* env; OrtCreateEnv(ORT_LOGGING_LEVEL_WARNING, "ONNX_Runtime", &env); OrtStatus* status = OrtSessionOptionsAppendGraphOptimizationLevel( session_options, level); OrtSession* session; OrtCreateSession(env, model_path.c_str(), session_options, &session); // 执行ONNX模型 // ... return 0; }